ICASSP2023 | TEA-PSE 3.0: 深度噪声抑制(DNS)竞赛个性化语音增强冠军方案解读
实时通信 (RTC) 在我们的日常生活中变得不可或缺,诸如腾讯会议在内的语音RTC应用已经成为我们日常使用的在线交流工具。然而在通话过程中,语音质量受到背景噪声、混响、干扰说话人等多种干扰的显著影响。因此语音增强技术在 RTC 链路中起着至关重要的作用。典型的语音增强方案主要侧重于去除噪声和混响,无法过滤干扰人声。为此,个性化语音增强(Personalized Speech Enhancement, PSE)技术应运而生,该技术旨在根据目标说话人注册的语音片段作为先验,从带有干扰(包括噪声、干扰人声等)的语音中提取目标说话人的语音,因此该技术又称为目标说话人提取(Target Speaker Extraction)。
由微软发起的深度噪声抑制(Deep Noise Suppression Challenge)竞赛已经连续举办了五届,在ICASSP 2023上举办的最新一届竞赛[1]旨在促进全频带(48 kHz)实时个性化语音增强,赛道一围绕头戴麦克风(headset)语音增强,赛道二围绕扬声器麦克风(speakerphone)语音增强。竞赛一方面采用ITU-T P.835[2]框架对增强后的音频进行主观打分,另一方面也采用了词准确率(WAcc)作为对后端语音识别系统的评价指标,即语音增强系统要同时兼顾听感和语音识别性能,同时竞赛严格要求系统延时小于20ms且处理一帧的时间要小于帧移。
在此次竞赛上,由西工大音频语音与语言处理研究组(ASLP@NPU)与腾讯天籁实验室(TEA Lab)合作提交的系统获得双赛道冠军的优异成绩,这是继上届DNS竞赛取得个性化语音增强赛道冠军后,再一次蝉联冠军。相关系统描述论文“ TEA-PSE 3.0: TENCENT-ETHEREAL-AUDIO-LAB PERSONALIZED SPEECH ENHANCEMENT SYSTEM FOR ICASSP 2023 DNS-CHALLENGE”被ICASSP2023同时接收,将在竞赛Session进行宣读。
本文简要介绍冠军系统。提交系统在之前 TEA-PSE[3]的基础上, 扩展到其升级版本——TEA-PSE 3.0。继续延续两阶段增强方案,TEA-PSE 3.0 在压缩时间卷积网络 (S-TCN) 之后加入了一个残差 LSTM[4],以增强序列建模能力。此外,引入局部-全局表示(LGR)结构[5]来促进说话人信息提取,并使用多 STFT 分辨率损失[6]来有效捕获语音信号的时频特性。此外,采用基于冻结训练策略的再训练方法对系统进行微调。根据官方成绩,TEA-PSE 3.0在ICASSP 2023 DNS 竞赛赛道1和2均排名第一。

图1:ICASSP 2023 DNS Challenge Track1官方公布的最终成绩
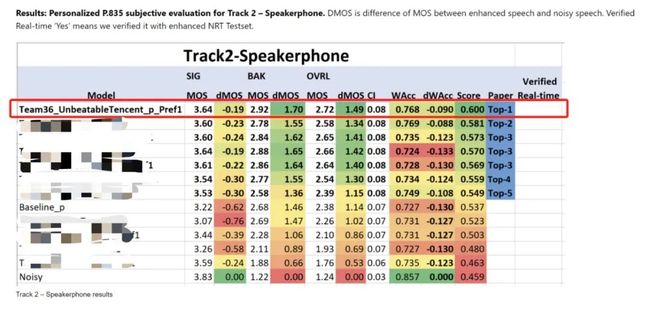
图2:ICASSP 2023 DNS Challenge Track2官方公布的最终成绩
论文题目:TEA-PSE 3.0: TENCENT-ETHEREAL-AUDIO-LAB PERSONALIZED SPEECH ENHANCEMENT SYSTEM FOR ICASSP 2023 DNS-CHALLENGE
作者列表:琚雨恺,陈鋆,张是民,何树林,饶为,朱唯鑫,王燕南,余涛,商世东
论文原文:https://arxiv.org/abs/2303.07704

图3:发表论文截图
1. 提出的方案
模型保持了TEA-PSE1.0的两阶段框架,由 MAG-Net 和 COM-Net 组成,分别处理幅度域和复数域特征。图 5(a) 详细描述了 MAG-Net,其中 E 表示从预训练的 ECAPA-TDNN 网络获得的说话人嵌入。
TEA-PSE 1.0系统
琚雨恺,公众号:语音之家论文推介:腾讯天籁实验室-西工大ICASSP2022 DNS竞赛两阶段个性化语音增强系统

图5:(a) MAG-Net 结构;(b) S-TCN&L结构;(c) S-TCM 结构。
编码器和解码器。编码器由多个频率下采样 (FD) 层组成,而解码器由多个频率上采样 (FU) 层堆叠而成。每个 FD 层都以门控卷积层 (GConv) 开始,以对输入频谱进行下采样,然后是累积层范数 (cLN) 和 PReLU。FU层几乎与FD层相同,而用转置门控卷积层(TrGConv)代替GConv来进行上采样。
序列建模结构。S-TCN 由多个压缩时间卷积模块 (S-TCM) 组成,如图 5(c) 所示。为了进一步增强模型的序列建模能力,我们在每个 S-TCN 模块之后添加了一个残差 LSTM(称为 S-TCN&L),受到 [4] 的启发。图 5(b) 显示了修改后的 S-TCN&L 结构。说话人嵌入仅在 S-TCN 模块的第一个 S-TCM 层中使用乘法运算与潜在特征相结合。
局部-全局表征。由于说话人注册语音的局部和全局特征对于目标说话人提取都是必不可少的,因此我们将 LGR 结构 [5] 合并到模型中,如图 5(a) 所示。说话人编码器由一个双向 LSTM (BLSTM) 和几个 FD 层组成,以注册语音的幅度作为输入。值得注意的是,在 BLSTM 之后有一个额外的全连接层以保持其维度与输入一致,并且沿时间维度应用平均池化操作。说话人编码器(Speaker Encoder)的输出与编码器中前面 FD layer 的输出拼接在一起,对应于 说话人信息的进一步融合。

2. 实验验证
我们使用 ICASSP 2022 DNS-Challenge 全频带数据集 [8] 进行实验。噪声数据来自 DEMAND、Freesound 和 AudioSet。我们基于镜像方法 [9] 生成10万个房间脉冲响应 (RIR),其中 RT60 ∈ [0.1, 1.0]s。
训练设置。窗长和帧移分别为 20 毫秒和 10 毫秒。对于多 STFT 分辨率损失,我们使用 3 个不同的组,FFT 长度∈{512,1024,2048},窗长∈{480,960,1920},帧移∈{240,480,960}。我们使用 FFT 长度 1024、窗长 960 和帧移480 来处理单 STFT 分辨率损失。Adam 优化器用于优化模型,初始学习率为 1e−3。如果验证损失在 2 个 epoch 内没有减少,学习率将减半。我们动态生成数据来增加训练数据的多样性并节省存储空间,与 TEA-PSE 保持相同的设置。编码器和解码器分别由 6 个 FD 层和 6 个 FU 层组成。编码器和解码器中的 GConv 和 TrGConv 在时间轴和频率轴上的内核大小和步长分别为 (2, 3) 和 (1, 2)。所有 GConv 和 TrGConv 层的通道都设置为 64。S-TCN&L 模块有 4 个 S-TCM 层,内核大小为 5,用于膨胀Conv (DConv),膨胀率为 {1, 2, 5, 9}, LSTM 的隐藏大小为 512。除了最后一个逐点卷积 (PConv) 层外,S-TCN&L 中的所有卷积通道都设置为 64。我们堆叠 4 个 S-TCN&L 组用来在连续帧之间建立长时关系并组合说话人嵌入。对于说话人编码器,我们使用隐层大小为 512 的 BLSTM 和 5 个 FD 层,说话人编码器中所有 GConv 层的通道都设置为 1。
结果与分析。根据表 1 中的竞赛盲测集PDNSMOS P.835结果可以得出几个结论。首先,在每个 S-TCN 模块之后添加一个残差 LSTM 可以提高性能。其次,事实证明LGR 结构在促进说话人信息提取方面是有效的。第三,通过使用多 STFT 分辨率损失函数,所提出的方法在赛道 1 和赛道 2 的 OVRL分数分别实现了 0.015 和 0.042 的显著提升。最后,使用预训练模型重新训练双阶段网络可提供额外的性能收益。表 2 展示了竞赛盲测集的平均意见得分 (MOS) 和词准确度 (WAcc) 结果。TEA-PSE 3.0 具有最高的 BAK 和 OVRL。此外,与未处理的语音相比,提交模型的 SIG 和 WAcc 有所降低,这是合理的,因为该模型对提取的语音引入了轻微的失真。
参数量和RTF。TEA-PSE 3.0 共有 22.24 百万个可训练参数。TEA-PSE 3.0 的乘法加法操作数 (MAC) 为每秒 19.66G。在主频为 2.4 GHz 的英特尔(R) 至强(R) CPU E5-2678 v3 上,ONNX 导出的提交系统的每帧平均实时因子 (RTF) 为 0.46。
表1:DNS 2023 盲测集上的PDNSMOS P.835结果。

表2:DNS 2023 盲测集上的 MOS 和 WAcc 结果。

3. 样例展示
第一组
Noisy

noisy1音频
Enhanced

enh1音频
第二组
Noisy
noisy2音频
Enhanced

enh2音频
第三组
Noisy
noisy3音频
Enhanced

enh3音频
参考文献
[1] H. Dubey, A. Aazami, V. Gopal, B. Naderi, S. Braun, R. Cutler, H. Gamper, M. Golestaneh, and R. Aichner, “Deep Speech Enhancement Challenge at ICASSP 2023,” in ICASSP, 2023.
[2] B. Naderi and R. Cutler, “Subjective evaluation of noise suppression algorithms in crowdsourcing,” arXiv preprint arXiv:2010.13200, 2020.
[3] Y. Ju, W. Rao, X. Yan, Y. Fu, S. Lv, L. Cheng, Y. Wang, L. Xie, and S. Shang, “TEA-PSE: Tencent-ethereal-audio-lab Personalized Speech Enhancement System for ICASSP 2022 DNS CHALLENGE,” in ICASSP. IEEE, 2022, pp. 9291–9295.
[4] A. Li, G. Yu, C. Zheng, W. Liu, and X. Li, “A General Deep Learning Speech Enhancement Framework Motivated by Taylor’s Theorem,” arXiv preprint arXiv:2211.16764, 2022.
[5] S. He, W. Rao, K. Zhang, Y. Ju, Y. Yang, X. Zhang, Y. Wang, and S. Shang, “Local-global speaker representation for target speaker extraction,” arXiv preprint arXiv:2210.15849, 2022.
[6] R. Yamamoto, E. Song, and J. Kim, “Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in ICASSP. IEEE, 2020, pp. 6199–6203.
[7] Y. Ju, S. Zhang, W. Rao, Y. Wang, T. Yu, L. Xie, and S. Shang, “TEAPSE 2.0: Sub-Band Network for Real-Time Personalized Speech Enhancement,” in SLT. IEEE, 2023, pp. 472–479.
[8] H. Dubey, V. Gopal, R. Cutler, A. Aazami, S. Matusevych, S. Braun, S. E. Eskimez, M. Thakker, T. Yoshioka, H. Gamper, et al., “ICASSP 2022 deep noise suppression challenge,” in ICASSP. IEEE, 2022, pp. 9271–9275.
[9] Jont B Allen and David A Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979.