简历问题总结
熟练掌握java相关知识,如IO流、集合框架、多线程等知识点。
- ConcurrentHashMap中大量使用了CAS、多线程分步扩容,红黑树提高了并发情况下的访问速度。 put()操作先初始化Node[]数组table,默认容量是16。初始化Node[]数组前会使用Unsafe类的cas操作把volatile修饰的SIZECTL属性修改为-1,表示正在进行扩容或初始化。然后根据key的hash值找到Node[]中对应的元素f,如果是f为null则同样通过Unsafe类以CAS的方式把值放到table中f的位置。如果f.hash=-1说明这个位置正在扩容,则该线程帮助扩容。如果f.hash>=0,则说明这个元素是一个正常的元素,可以进行追加新元素。f.hash=-2则说明这个节点是红黑树的头节点,则按把值添加到红黑树中。添加完之后判断下当前桶的链表的长度是否超过了8,如果超过了则把链表转换成红黑树。然后计算当前map中元素的个数,判断是否需要扩容。如果超过容量的0.75倍,则进行扩容。扩容是创建一个容量为原来 2 倍大小的桶数组,然后将原桶数组的元素迁移到新的桶数组上,迁移的最小单位是桶。由于数组可能比较大,这个搬迁的过程不是一蹴而就的,需要多个线程共同努力完成,前面put()方法中的helpTransfer()加入到扩容的工作中来,每个线程负责数组的一部分,这样就不会冲突。
在扩容的过程中可能出现一部分节点在旧的数组中,一部分节点在新的数组中,为了确保能够获取到数据,当把一个桶的节点迁移之后,会在旧桶的对应位置留下一个哨兵节点,如果碰到这个节点,就知道要去新的数组中查询。 - ArrayList源码: 初始容量为0,当第一次添加元素是会创建一个初始容量为10的数组,后面添加到11个元素的时候,扩展为原来的1.5倍,依次类推。扩容时创建一个新数组,并且使用Arrays.copy()方法,把旧数据拷贝到新的数组中。
- 线程的状态有new runnable waiting timed_waiting blocked terminated
- wait()方法和sleep方法的区别
wait方法是Object的方法, sleep是Thread的方法。wait()方法执行需要持有锁,因为调用wait()方法时需要把当前线程放到ObjectMonitor中的一个waitSet集合中,后面notify时可以被唤醒,而ObjectMonitor就是锁资源,需要操作锁资源,当然要获取到锁。wait()方法执行后会释放锁资源,也就是把ObjectMonitor的owner属性置为null。这样别的线程才可以获得这个锁。sleep()方法会自动唤醒,执行时不需要锁。wait()方法需要调用notify()方法才可以被唤醒。 - 集合框架
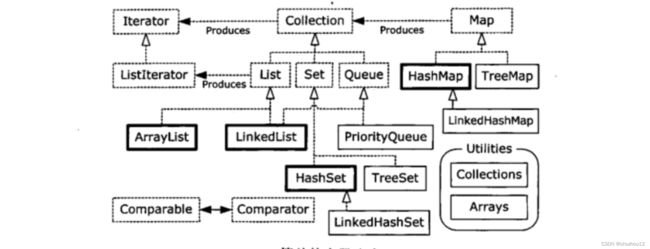
Queue接口方法: offer()方法插入元素, element()和peek()方法取出元素但不移除, remove()和poll()方法移除并取出元素。LinkedList实现了Dequeue接口,可以把它当做一个双端队列使用。


熟练掌握java的并发编程。如线程池原理及使用、各种锁的原理及使用、synchronized和volatile关键字的原理、JUC包下的常见类。
-
Thread相关方法
static sleep()方法: 线程进入休眠,时间到了自动唤醒
static yield()方法: 告诉cpu可以调度其它的线程执行了,但是只是建议,并不保证。
join()方法: 在当前线程中调用别的线程的join()方法,阻塞等待别的线程执行完之后,自己才能继续执行。 -
如何中断一个线程
分两种情况,线程逻辑中存在阻塞的情况和不存在阻塞的情况。
存在阻塞的情况: 线程有四种情况会进入阻塞状态,调用sleep()方法,调用wait()、sleep()、join()等方法,等待某个输入/输出完成,等待syncronized,Condition等锁。其中前面两种阻塞情况调用interrupt()方法设置线程的中断标记位,并且会抛出InterruptedException异常并重置中断标记位,应用程序可以捕获这个异常,处理后结束任务。但是普通的输入输出流以及synchronize阻塞时调用interrupt()方法时只会设置线程的中断标记位,不会抛出异常。就没办法中断了。不过后面NIO中的类如SocketChannel支持了中断响应,调用read()或write()方法阻塞时可以被中断。juc包中提供的ReentrantLock的lockInterruptibly()方法也支持中断,可以替代syncronized。
不存在阻塞的情况: 由于执行interrupt()方法,中断只会发生在线程已经阻塞了或者调用阻塞方法的时候,如果任务中没有发生阻塞的情况,那么while判断条件中就要通过调用Thread的staitc interrupted()方法判断线程是否被设置过中断位。并且调用这个方法还会重置中断标记位。另外还可以调用Thread的实例方法isInterrupted()判断中断标记位,区别是这个方法不会重置标记位。 -
并发编程的三大特性
原子性: 整个操作不能被其它线程打断。保证原子性的方式: syncronized、CAS、Lock锁、ThreadLocal
可见性: 别的线程修改的值对其它线程可见。保证可见性的方式: volatile、syncronized、Lock、final(final修饰的变量值不能改)。syncronized实现可见性的原理时,对一个变量lock之后会清空线程内存中该变量的值,对一个变量unlock之前必须从线程内存同步到主内存。
有序性:防止指令重排。java中天然的有序性是指在线程内所有操作都是有序的,但是一个线程观察另一个线程,所有操作都是无序的。保证有序性的方式: volatile、syncronized。syncronized保证有序性的原理是同一个锁的两个同步块只能串行的进入。 -
锁的类型
可重入锁和不可重入锁
公平锁和非公平锁
乐观锁和悲观锁
共享锁和排他锁: 读锁是共享锁,写锁是排他锁。读锁要在写锁释放之后才能被获取,读锁是共享锁。写锁也要在读锁都释放之后才能被获取,写锁是排他锁。 -
syncronized原理
synchronized是基于对象的markWord实现的。markword的后三位标记了当前对象是处于无锁态还是偏向锁还是轻量级锁还是重量级锁。并且偏向锁时会记录哪个线程持有锁。

synchronized使用的注意点: 使用new的对象当锁,synchronized(o), 当做锁的对象需要用final修饰,否则如果引用指向了别的对象,那么锁就失效了 -
syncronized jdk1.6优化
锁膨胀: 如果在一个循环中一直获取syncronized,会syncronized锁的范围扩大。
锁升级:
jdk1.5之前syncronized是重量级锁,也就是说线程遇到syncronized等待锁时会从用户态转换为内核态,这个是比较费时间的。jdk1.5之后优化了syncronized,引入了锁升级机制。一个线程第一次获取到锁的时候,会在对象头也就是markword中记录获取锁的线程id,此时的锁是偏向锁,顾名思义就是偏向这个线程的锁,后续如果还是这个线程来获取锁,直接获得即可,如果没有并发的情况下,偏向锁效率很高。如果出现并发情况,有别的线程来获取锁,此时锁就会升级为轻量级锁。此时别的线程就会通过CAS的方式自旋获取锁,采用自适应自旋获取锁,自旋了一定次数还没拿到锁,就继续升级为重量级锁。锁只能升级不能降级。 -
volatile的作用 保证线程间的可见性、防止指令重排序
jvm内存模型特殊处理了volatile修饰的变量,强制规定了volatile修饰的变量在使用之前要先从主内存读取到线程内存中,在线程内存修改后要马上同步到主内存。
多线程环境下指令重排的影响:

-
java内存模型

java内存模型做的就是定义如何把一个变量从工作内存拷贝到主内存,以及从主内存拷贝到工作内存。定义了八种操作来完成这几个操作:锁定、解锁、读取、载入、使用、赋值、存储、写入。并且定义了这些操作的一些规则,比如一个变量同一时刻只能被一个线程lock成功,并且可以被同一个线程多次lock,但是lock几次就要unlock几次。如果对一个变量lock,那么会清空工作内存中此变量的值。对一个变量unlock之前,必须把变量的值同步回主内存中。 -
JUC包下的常见类
-
Atomic类,juc包里提供了一系列的Atomic开头的类,这些类的操作都是原子性的。
使用Atomic类型的变量的话,就不用考虑加锁了,因为它的方法本身就是原子性的。同时也不用考虑可见性的问题,即不用加volatile修饰,因为Atomic类型内部实际的变量已经加了volatile关键字。Automic底层都是使用CAS操作实现的,底层使用的是Unsafe类的对象操作的,Unsafe类可以直接操作内存,直接生成类实例,直接操作类或实例变量。 -
ReentrantLock
ReentrantLock的语义和synchronized一样,但是ReentrantLock扩展了一些其它的功能,比如支持公平锁。可以替换synchronized。常用api:lock()方法,tryLock()方法,tryLock(5, TimeUnit.SECONDS),lockInterruptibly()方法,newCondition(), -
CountDownLatch 倒数门栓
CountDownLatch的countDown()方法执行一次就减1, 直到减到0, CountDownLatch.await()方法就继续往下执行 -
CyclicBarrier 循环屏障
每个线程执行CyclicBarrier的await()方法都会阻塞,直到调用await()方法的线程阻塞的线程达到指定的数量,所有线程就会开始执行,如果实例化CyclicBarrier的时候指定了runnable对象,会先执行里面的逻辑,然后其它被CyclicBarrier阻塞的方法才开始运行。之所以称为循环屏障,是因为等待屏障的线程被释放后,这个屏障是可以重复使用的。 -
Phaser
Phaser是一个可复用的同步栅栏,功能和CyclicBarrier和CountDownLatch类似,但是更加灵活。可以注册多个线程,每当所有注册者都到达后,阶段会加1。依次类推。

-
ReentrantReadWriteLock 读写锁
ReentrantReadWriteLock内部持有一对锁,一个是读锁,一个是写锁。在访问一个共享数据时,读写锁允许同一时间有多个线程同时读或者只能一个线程写。读锁是共享的,但是获取读锁之前,写锁要先被释放。也就是说读的时候不能写。写锁是排他的,获取写锁之前,读锁也要释放,也就是说写的时候不能读。读写锁使用场景是读多写少的场景。 -
Semaphore 信号量
这个信号量持有一组许可,调用acquire方法会阻塞,直到有许可可以使用,线程会取出一个许可。release()方法会添加一个许可。所以信号量可以控制最多同时有N个线程可以获得许可,一般用于限制同时访问资源的线程数量。当信号量只有一个许可时,它的作用和锁一样,只能有一个线程在运行。和Lock接口提供的方法类似,Semaphore提供了acquire和tryAcquire方法获取许可,提供了release()方法释放许可。并且还支持fair参数,该参数为true,则等待acquire的线程队列按FIFO的规则选择线程。否则新到的线程比队列中的线程先获得许可。 -
Exchanger 交换器
交换器可以在两个线程间交换数据。线程调用Exchanger.exchange()方法时,需要把自己需要交换的数据传给参数,然后线程会阻塞,直到另外一个线程调用Exchanger.exchange()方法时,该方法就会返回另外一个参与者线程提供的数据。 -
LockSupport
LockSupport的park方法可以使线程阻塞,unPark方法可以唤醒线程,并且可以指定唤醒哪个线程。并且执行之前不用获取锁,直接就可以执行,而且unPark方法还可以先于park方法执行。而Object的wait()方法和notify()方法,执行之前必须先获取锁,并且notify方法必须要在wait方法之后执行
-
-
AQS
AQS是AbstractQueuedSynchronizer的简称。它提供了一个volatile state属性以及一个类型为Node的等待队列。state属性的意义由子类定义。
ReentrantLock就是通过AQS实现的。它把state属性当做同一个线程持有该锁的次数。state=0表示没有线程持有锁,state=1表示线程持有该锁一次,state=2表示重入两次。- ReentrantLock 非公平锁加锁的过程
- 上来就先通过CAS设置state,期望值是0, 修改值是1。所以是非公平锁
- 如果修改成功,则直接返回,说明获得锁了。如果修改失败则说明锁已经被别的线程持有,则调用AQS的acquire(1)方法尝试获取锁。
- 再次判断state是否为0,如果为0,说明别的线程把锁释放了,则再次cas设置state的值。如果不为0,接着判断持有锁的线程是否是当前线程,如果是当前线程则把state的值加1。如果以上两种情况都不满足,则尝试获取锁失败,把当前线程加到等待队列中。加到等待队列的逻辑AQS已经实现了。
- 加入到等待队列以后,无限循环以下逻辑: 判断当前节点的前一个节点是head节点,如果是说明前面没有线程在等待锁,那么就尝试获取锁,如果获取锁成功就把当前节点的信息清空,并置为head节点,结束循环。如果前一个节点不是head节点或者尝试获取锁的时候失败了,则调用 LockSupport.park(this)阻塞等待。
- ReentrantLock 非公平锁解锁的过程
- 把state的值减1,注意如果当前线程重入了n次,那么即使减1,state的值也不是0.所以ReentrantLock是可冲入锁。
- 然后取head节点的next节点,调用LockSupport.unpark(s.thread)唤醒等待队列中的第一个等待线程。
-
ReentrantLock和syncronized的区别
ReentrantLock获取锁支持超时,支持公平锁。实现原理不一样ReentrantLock是基于AQS、CAS实现的,没有锁升级的概念,syncronized是基于ObjectMonitor实现的。ReentrantLock可以通过Condition精确控制唤醒哪个线程。ReentrantLock更灵活。 -
BlockingQueue
这个接口继承Queue接口,提供了额外的两个操作,一个是提取元素时如果queue空了,则wait等待queue非空。一个是添加元素时如果queue满了则等待queue有空间。BlockingQueue的方法有四种形式,如下所示

BlockingQueue实现主要被设计用于生产者-消费者队列,但是它也支持Collection操作,例如可以使用remove(x)方法删除队列中的任何一个元素,但是这些操作效率不高,不能频繁使用,比如队列中的消息被取消时可以调下这个方法。
BlockingQueue实现类- LinkedBlockingQueue,无界的阻塞队列,用链表实现,链表是无界的.如果构造器不指定容量,则默认容量是 Integer.MAX_VALUE。排序规则是先进先出
- ArrayBlockingQueue,有界的阻塞队列,内部是一个容量固定的数组保存元素,并且容量一旦确定就不能改变了。构造器支持fairness参数,默认为false,不保证FIFO,指定为true才能保证FIFO.
- TransferQueue
调用transfer()方法producers会wait直到有消费者调用take或poll方法取元素。这个队列还提供了Non-blocking 和time-out版本的transfer()方法,Non-blocking的transfer()方法如果没有消费者等着取元素的话,就会返回false,元素也不会添加到队列中。time-out版本的transfer()方法,如果指定时间内没有消费者来取元素的话,就会返回false.还提供了一个hasWaitingConsumer()方法,查询是否有在wait的消费者。 - SynchronousQueue,每一个插入操作必须wait另外一个线程的取出操作。这个队列的容量是0.只有已经有一个线程准备消费元素时,才可以插入元素。如果没有消费者等待,则多个线程调用put方法都会阻塞,来一个消费者线程,才能放行一个生产者线程。
构造器支持fairness参数,默认为false,不保证FIFO,指定为true才能保证FIFO. - DelayQueue,过期的元素才会被取出来。
持有Delayed元素的无界队列,里面的元素必须实现Delayed接口。只有元素的延迟已经过期了才能被取出。队列的head节点元素,是过期时间最久的元素。过期发生的时间是元素的getDelay()方法返回0或者负数。 - BlockingPriorityQueue
-
线程池
- 核心线程数
- 阻塞队列
- 最大线程数
- 线程工厂
- 拒绝策略
- 存活时间
线程池 核心线程数 任务队列(BlockingQueue) 拒绝策略 最大线程数 keepAliveTime
当一个新任务通过execute()方法提交到线程池的时候,如果核心线程数比corePoolSize少,那么即使有空闲的线程,也会新建一个核心线程。如果线程数大于corePoolSize但是小于maximumPoolSize,那么任务会先放进任务队列中,如果任务队列满的时候,并且线程还没有达到maximumPoolSize,那么就会创建新的线程。如果队列已经满了并且线程也已经达到了maximumPoolSize的数量,那么就会根据拒绝策略处理任务。
默认情况下核心线程是不会提前创建的,只有有任务来的时候才会提前创建。可以使prestartCoreThread()或者prestartAllCoreThreads()方法,修改这个行为。
有三种常用的队列策略:
1. 直接交给线程处理,不存放在队列,如果没有线程可以处理就会阻塞。这种策略一般需要有一个无界的maximumPoolSizes。
2. 无界队列,例如使用LinkedBlockingQueue,不指定capacity。
3. 有界队列,例如使用ArrayBlockingQueue
Keep-alive times:
如果线程池中的线程数超过corePoolSize,那么这部分线程空闲超过keepAliveTime时间后会被销毁,这个时间可以用
getKeepAliveTime方法获取,也可以用setKeepAliveTime方法设置。如果想要核心线程也被销毁可以调用allowCoreThreadTimeOut()方法。
拒绝任务:
当Executor被shutDown了,或者任务队列满了并且线程数也达到maximumPoolSize了,新提交的任务会被拒绝。有四种默认支持的拒绝策略分别是:ThreadPoolExecutor.AbortPolicy,ThreadPoolExecutor.CallerRunsPolicy,
ThreadPoolExecutor.DiscardPolicy,ThreadPoolExecutor.DiscardOldestPolicy
钩子方法:
ThreadPoolExecutor类提供了beforeExecute和afterExecute方法,子类可以覆盖这个方法。这两个方法会在每个任务开始和结束的时候执行。使用场景举个例子,重新初始化ThreadLocals,收集统计数据,或者添加日志元素。
另外terminated方法也可以被覆写,这个方法会在Executor完全停止后执行。如果钩子方法抛出异常,内部的工作线程也会失败并且突然停止。
Finalization:
线程池如果没有被引用了并且也没有线程了将会自动shutdown。如果你想确保未引用的线程池会被shutdown,就必须确保线程
最终会死掉,可以通过设置合适的keep-alive,core threads设置为0,或者allowCoreThreadTimeOut允许核心线程
自动销毁。也可以手动调用shutDown()方法,然后调用awaitTermination方法,等待所有剩余线程执行完成。
熟练掌握JVM知识。如类加载过程、JVM Agent机制、JVM运行时内存、各种垃圾回收器及其垃圾回收算法,能够定位线上OOM、CPU飙高等问题。
- java中的四种引用类型
强:对象不会被回收,这会造成内存泄漏。
软:只有当内存空间不够时才会被回收。可以作为缓存对象使用。
弱: 只要垃圾回收机制运行,就会被回收。
虚:如果 GC 在某个时间点确定虚引用的所指对象只有虚引用可达,届时或稍后将其加入引用队列。和软引用以及虚引用不同,在其加入引用队列时,不会自动被 GC 清除。虚引用所引用对象不会被被释放直到所有指向该对象的虚引用被清除,想要显式的移除虚引用的话,只需要将其从引用队列中取出然后扔掉(置为null)即可。 所以虚引用通常用来跟踪对象被垃圾回收的活动。比如,虚引用可用于在某些对象超出范围以执行某些资源清理时通知您。
虚引用应用场景: ThreadLocal就是基于弱引用解决内存泄漏的问题。ThreadLocal中的数据其实是存储在每个Thread的ThreadLocal.ThreadLocalMap类型的属性中的,key是ThreadLocal对象自身,value是对应的值。有个问题,ThreadLocal对象实例有两个引用,一个是应用代码中自己声明的引用,一个是ThreadLocal.ThreadLocalMap中的key引用。即使应用中的引用置为null,ThreadLocal对象也不会被回收,所以key要使用弱引用。那么value引用的对象怎么回收呢?这就要在使用过后手动调用ThreadLocal.remove()方法了。
虚引用应用场景: WeakHashMap中的Entry继承了WeakReference,Entry中的key会和WeakHashMap中的ReferenceQueue queue属性一起构建一个WeakReference。这样当key对应的引用被垃圾回收前就会放到queue中。WeakHashMap的几乎所有方法如get,put,size等等都会遍历queue,把queue中对应的key取出来,并且把对应key的Entry从map中移除,并且把value置为null。通过这个机制实现了map中entry的自动清除。适合做缓存,Spring中就有很多地方使用WeakHashMap做缓存的场景。
- Class文件结构
类基本信息: 魔数、次要版本号、主要版本号、access_flag、父类class_info在常量池的位置、父接口class_info在常量池的位置、类的全类名在常量池的位置、接口个数、方法个数、字段个数等。
其它信息: 常量池、field列表(包含名称、描述符(其实就是全类名)、访问标志、属性列表)、method列表(包含方法的名称、描述符(返回值(param1,param2))、访问标记、属性列表)、接口列表、attribute列表
解释下属性这个名词,属性有三个地方会出现,类、字段、方法。出现在类中的属性有SourceFile(类文件-源文件的名称)、InnerClasses(内部类列表)、EnclosingMethod(局部类或匿名类的外部封装方法)、Deprecated(是否被标记为过时)。出现在方法中的属性有Code(表示该方法编译成的字节码指令)、Exceptions(方法抛出的异常列表),Deprecated(是否被标记为过时),Code属性又有两个子属性分别是LineNumberTable(java源码的行号与字节码指令的对应关系)、LocalVariableTable(方法的局部变量表)。出现在字段中的属性有ConstantValue(final关键字定义的常量值)。
这些信息会映射到运行时内存的方法区中,了解这些,可以知道通过反射可以拿到哪些信息。 - 类加载
- 双亲委派机制

如何自定义类加载器:通过分析源码,自定义类加载器只需要继承ClassLoader类,然后覆写findClass()方法即可。
如何打破双亲委派机制:自定义类加载器直接覆写loadClass()方法。这个破坏的样例有没有什么实际价值意义呢?还真有,后来Tomcat就使用这种方式对双亲委派进行破坏,来达到使用一个web容器部署两个或者多个应用程序,不同的应用程序,可能会依赖同一个第三方类库的不同版本,还要能保证每一个应用程序的类库都是独立、相互隔离的效果。tomcat自定义了类加载器,重写loadClass方法使其优先加载自己目录下的class文件,来达到class私有的效果。不过咱们现在流行使用的都是嵌入式的web容器了,将来更多的场景还是一个应用程序使用一个单独的web容器。所以这种破坏双亲委派的价值在降低。 - 类加载过程
- 加载:加载阶段完成下面三件事。通过一个类的全限定名来获取定义此类的二进制字节流。将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。在内存中生成一个代表这个类的Class对象,作为方法区这个类的各种数据的访问入口。Class对象比较特殊,它虽然是对象,但是存放在方法区里面。
- 验证: 文件格式验证(比如是否已魔数0xCAFEBABE开头,主次版本号是否在当前虚拟机处理范围内),元数据验证(这个类的父类是否继承了不允许被继承的final类等),字节码验证(主要目的是通过数据流和控制流分析,确定程序语义是合法的符合逻辑的),符号引用验证(验证常量池中的符号引用能够找到等)
- 准备:为静态变量分配内存,并设置初始值。静态变量是分配在方法区中的。
- 解析:解析符号引用为直接引用。解析的时候会触发别的类的加载过程。
- 初始化: 执行静态代码块及静态变量赋值
- 运行
- 卸载
jvm规定初始化之前,要先依次执行加载、验证、准备。 解析阶段可以在后面调用实例方法的时候再执行。触发初始化的四种情况分别是: new对象、调用静态方法或获取静态属性、使用反射、程序执行需要指定一个入口类,jvm会优先初始化这个入口类。
- 双亲委派机制
- GC Roots 到底是什么东西呢,哪些对象可以作为 GC Root 呢?
虚拟机栈(栈帧中的本地变量表)中引用的对象
本地方法栈中 JNI(即一般说的 Native 方法)引用的对象
方法区中类静态属性引用的对象
方法区中常量引用的对象 - jvm对象的内存布局
markword, class指针,对象数据(基本类型属性值或引用类型属性值)、padding(字节补齐)。 - javaagent
代理类的应用场景: 监控代理, 分析工具, 代码覆盖率分析, event loggers。
有两种方式启动javaagent
当启动jvm时指定了agent class,则jvm会把Instrumentation的实例传给agent class的premain()方法的参数中,jvm会在启动时加载加载代理类,并调用premain()方法。
当jvm提供了jvm启动之后再启动agent的机制时, Instrumentation的实例会传给agent的agentmain()方法中,猜测arthas就是使用这种方式在jvm启动以后绑定代理程序的。这种情况下agent类在手动加载到jvm中时,jvm会调用agentmain()方法。
这两种机制在jvm规范中有描述。
agent类需要打到jar包中才能使用,并且在agent jar的manifest中必须包含Premain-Class或者Agent-Class,这个属性的值是agent class的类名。
agent对应的类的premain()方法或者agentmain()方法中拿到Instrumentation后,就可以添加自定义的ClassFileTransformer类了,这个类的transfrom()方法可以在classLoader load之后但是生成Class对象之前,对字节码进行修改。 - jvm运行时数据区
共享空间: 堆、方法区(包含了运行时常量池、Class的其它信息。jdk1.8以后叫meta space,full GC会回收这部分空间, jdk1.8以前叫perm space,full GC不会回收这部分空间)
线程独享空间: 程序计数器(记录了栈帧执行的方法的字节码位置),本地方法栈、虚拟机栈。栈中包含了一个一个的栈帧,一个栈帧对应一个方法,栈帧中包含三部分:本地变量表、操作数栈、动态链接(对类的运行时常量池的引用) - jvm垃圾收集器
- 垃圾收集器类型: 串行收集器(serial serial-old)、并行收集器(吞吐量优先,parallel-new parallel-old)、CMS(响应时间优先)、G1(吞吐量和响应时间都会尽量满足)。这几种收集器都是使用的分代收集模型。
- 垃圾标记算法: 根可达算法和引用计数法(无法解决循环依赖问题)
- 垃圾收集算法: 标记-清除(会产生碎片,垃圾少的时候适合,因为需要清除的对象少) 拷贝 (适合存活对象少的区域,因为需要拷贝的对象少,拷贝对象会比较费时间) 标记-压缩(没有碎片,指针需要调整)。 serial和parallel-scavenge和parNew都是使用的拷贝算法,parallel-old使用的是标记-压缩算法,serial-old使用的是标记-清除-压缩算法。CMS使用的是标记-清除算法。
- YGC
当对象在Eden区分配不下的时候会触发YGC。YGC会首先把from survivor区域中未达到晋升年龄并且活着的对象放到to survivor区域,并且年龄加1。 然后把Eden中存活的小对象放到to survivor区域,to survivor区域存放不下的对象或者Eden中的大对象会直接放到老年代。 - Major GC 或 Full GC
只有CMS会单独回收老年代。其它垃圾回收都是老年代和年轻代一起回收。所以major GC只有在CMS中才代表是老年代垃圾回收,其它情况和Full GC意义相同。当年轻代的对象放到老年代的时候,如果老年代的空间不够了,就会触发Full GC。 - CMS垃圾收集过程: 初始标记(STW) -> 并发标记 -> 重新标记(STW) -> 并发清理。
- CMS的标记算法: 三色标记 + Incremental Update
- CMS的缺点: 会产生浮动垃圾,因为垃圾收集时没有压缩的步骤。因为垃圾收集和应用程序有并行运行的步骤,如果在垃圾收集过程中发现老年代没有空间容纳新生代晋升的对象或者大对象,则会触发full GC, full GC会使用serial-old垃圾收集器收集整个堆,这个过程会非常慢。
- 垃圾收集的区域: 堆、方法区。 新生代使用新生代算法,老年代和方法区使用老年代回收算法。
- JVM常用的参数:
-XX:+UseG1GC 使用G1垃圾收集器
-Xloggc:filename, 设置verbose GC events信息存放的日志文件的名称
-Xmn256m: 设置新生代的初始值和最大值
-Xms6144k: 设置jvm堆的最小值和初始值
-Xmx81920k: 设置jvm堆的最大值
-XX:+PrintCommandLineFlags, 打印出jvm自动配置的参数,如堆空间大小,选择的垃圾回收器等。
-XX:MaxGCPauseMillis=time,设置最大GC停顿时间,jvm垃圾回收器会努力实现这个目标
-XX:G1ReservePercent=percent,设置保留堆空间大小的百分比,用于减少G1垃圾回收器promotion failure 的可能性,这个百分比在1-50之间,默认是10
-XX:MaxTenuringThreshold=threshold,设置晋升老年代的年龄大小,最大值是15,对于parallel(吞吐量)收集器来说,默认值是15,对CMS来说默认值是6
-XX:NewRatio=ratio,年轻代和老年代的比值,默认值是2,一般会使用Xmn256m设置大小会比这个参数更灵活。
-XX:+PrintGC,打印每次GC的信息
-XX:+PrintGCDetails,打印每次GC的详细信息
-XX:+PrintGCTimeStamps,打印每次GC的时间戳
-XX:SurvivorRatio=ratio, eden和survivor的比值,默认值是8 - G1垃圾收集器
参考链接
G1垃圾收集器的基本概念:- Region(每个 Region 分区只能是一种角色,Eden区、S区、老年代O区的其中一个,空白区域代表的是未分配的内存,每个region的大小必须在1M - 32M 之间,且为2的N次幂,这个大小可以通过参数设定)、
- Cset(每次垃圾收集的region集合)、
- Rset(每个region都有一个Rset用于记录老年代对新生代的引用,这样每次YGC时就不用扫描老年代了,只需要扫描region就可以了)、
- H区(Humongous,专门用于存放巨型对象,如果一个对象的大小超过Region容量的50%以上,G1 就认为这是个巨型对象,在其他垃圾收集器中,这些巨型对象默认会被分配在老年代,但如果它是一个短期存活的巨型对象,放入老年代就会对垃圾收集器造成负面影响,触发老年代频繁GC。为了解决这个问题,G1划分了一个H区专门存放巨型对象,如果一个H区装不下巨型对象,那么G1会寻找连续的H分区来存储,如果寻找不到连续的H区的话,就不得不启动 Full GC 了)
G1垃圾收集器如何达到最大暂停时间目标: G1收集器通过跟踪Region中的垃圾堆积情况,每次根据设置的垃圾回收时间,回收优先级最高的区域,避免整个新生代或整个老年代的垃圾回收,使得stop the world的时间更短、更可控,同时在有限的时间内可以获得最高的回收效率。通过区域划分和优先级区域回收机制,确保G1收集器可以在有限时间获得最高的垃圾收集效率。
G1的YGC和Mixed-GC的垃圾收集算法并没有明显不同,采用的是标记-整理的算法,都是针对Cset中的Region进行回收,只是触发的条件不同。YGC时,Cset中只有年轻代的Regions。而Mixed GC时,Cset中就包含了所有的年轻代Region以及一些回收收益高的老年代Region。每次垃圾回收完成后,都会清空Cset,并且把Cset中存活的对象拷贝到。下次垃圾回收前会选择Region重新放入Cset中。
YGC的过程:当Eden区已满,JVM分配对象到Eden区失败时,便会触发一次STW式的年轻代收集young GC,将 Eden 区存活的对象将被拷贝到 to survivor 区;from survivor 区存活的对象则根据存活次数阈值分别晋升到 PLAB、to survivor 区和老年代中;如果 survivor 空间不够,Eden区的部分数据会直接晋升到年老代空间。最终Eden空间的数据为空,GC停止工作,应用线程继续执行。
G1 Mixed GC: 年轻代不断进行垃圾回收活动后,为了避免老年代的空间被耗尽。当老年代占用空间超过整堆比 IHOP 阈值 -XX:InitiatingHeapOccupancyPercent(默认45%)时,G1就会启动一次混合垃圾回收Mixed GC,Mixed GC不仅进行正常的新生代垃圾收集,同时也回收部分后台扫描线程标记的老年代分区。这里需要特别注意的是 Mixed GC 并不是 Full GC,只有当 Mixed GC 来不及回收old region,也就说在需要分配老年代的对象时,但发现没有足够的空间,这个时候就会触发一次 Full GC。Mixed GC步骤主要分为两步:
(1)全局并发标记(global concurrent marking)
全局并发标记分为四个阶段 :初始标记、并发标记、重新标记、清除。初始标记会STW。事实上,当达到 IHOP 阈值时,G1并不会立即发起并发标记周期,而是等待下一次年轻代收集,利用年轻代收集的STW时间段,完成初始标记,这种方式称为借道。
该阶段主要是排序各个 Region 的回收价值和成本,并根据用户所期望的GC停顿时间来制定回收计划。(这个阶段并不会实际去做垃圾的回收,也不会执行存活对象的拷贝)
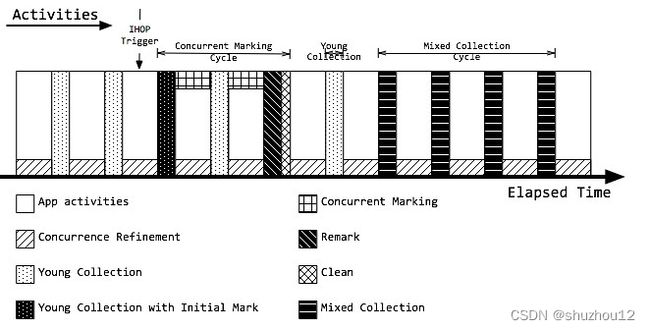
(2)拷贝存活对象到空闲的region(evacuation)
当G1发起全局并发标记之后,并不会马上开始混合收集,G1会先等待下一次年轻代收集,然后在该 young gc 收集阶段中,确定下次混合收集的CSet。
全局标记完成后,G1 就知道哪些 old region 的可回收垃圾最多了,只需等待合适的时机就可以开始混合回收了,而混合回收除了回收这个young region,还会回收部分 old region(不需要回收全部 old region)。根据停顿目标,G1 可能没法一次回收掉所有的old region 候选分区,只能选择优先级高的若干个 region 进行回收,所以G1可能会产生连续多次的混合收集与应用线程交替执行,而这些被选中的 region 就是 CSet 了,而单次的混合回收的算法与上文的 Young GC 算法完全一样,只不过回收集CSet 中多了老年代的内存分段;而第二个步骤就是将这些 region 中存活的对象复制到空间 region 中去,同时把这些已经被回收的 region 放到空闲 region 列表中。
G1会计算每次加入到CSet中的分区数量、混合收集进行次数,并且在上次的年轻代收集、以及接下来的混合收集中,G1会确定下次加入CSet的分区集(Choose CSet),并且确定是否结束混合收集周期。
(1)并发标记结束以后,老年代中100%为垃圾的 region 就直接被回收了,仅部分为垃圾的region会被分成8次回收(可以通过 -XX:G1MixedGCCountTarget 设置,默认阈值8),所以 Mixed GC 的回收集(CSet)包括八分之一的老年代内存分段、Eden 区内存分段、Survivor 区内存分段。
(2)由于老年代的内存分段默认分8次回收,G1会优先回收垃圾多的内存分段。垃圾占内存分段比例越高的,越会被先回收。并且由一个阈值决定内存分段是否被回收 -XX:G1MixedGCLiveThresholdPercent,默认为 65%,意思是垃圾占内存分段比例要达到 65% 才会被回收。如果垃圾占比太低,意味着存活的对象占比高,在复制的时候会花费更多的时间。
(3)混合回收并不一定要进行8次,有一个阈值 -XX:G1HeapWastePercent,默认值 10%,意思是允许整个堆内存有 10% 的空间浪费,意味着如果发现可以回收的垃圾占堆内存的比例低于10%,则不再进行混合回收,因为 GC 会花费很多的时间,但是回收到的内存却很少
G1 垃圾回收流程小结:Young CG 和 Mixed GC,是G1回收空间的主要活动。当应用开始运行时,堆内存可用空间还比较大,只会在年轻代满时,触发年轻代收集;随着老年代内存增长,当到达 IHOP 阈值 -XX:InitiatingHeapOccupancyPercent(老年代占整堆比,默认45%) 时,G1开始着手准备收集老年代空间。首先经历并发标记周期,识别出高收益的老年代分区。但随后G1并不会马上开启一次混合收集,而是让应用线程先运行一段时间,等待触发一次年轻代收集,在这次STW中,G1将开始整理混合收集周期。接着再次让应用线程运行,当接下来的几次年轻代收集时,将会有老年代分区加入到CSet中,即触发混合收集,这些连续多次的混合收集称为混合收集。
Full GC:
当 G1 无法在堆空间中申请新的分区时,G1便会触发担保机制,执行一次STW式的、单线程的 Full GC,Full GC会对整堆做标记清除和压缩,最后将只包含纯粹的存活对象。参数-XX:G1ReservePercent(默认10%)可以保留空间,来应对晋升模式下的异常情况,最大占用整堆50%,更大也无意义。
G1在以下场景中会触发 Full GC,同时会在日志中记录to-space-exhausted以及Evacuation Failure:
(1)从年轻代分区拷贝存活对象时,无法找到可用的空闲分区
(2)从老年代分区转移存活对象时,无法找到可用的空闲分区
(3)分配巨型对象时在老年代无法找到足够的连续分区
由于G1的应用场合往往堆内存都比较大,所以Full GC的收集代价非常昂贵,应该避免Full GC的发生。
- JVM调优
- G1通用配置参数
-Xms8g -Xmx8g -Xss1m -XX:+UseG1GC -XX:MaxGCPauseMillis=150 -XX:InitiatingHeapOccupancyPercent=40-XX:+HeapDumpOnOutOfMemoryError-verbose:gc-XX:+PrintGCDetails-XX:+PrintGCDateStamps-XX:+PrintGCTimeStamps-Xloggc:gc.log
精读Spring源码。深入理解IOC、AOP、IOC中的三级缓存、Spring事务的实现、如何基于Spring进行扩展。
-
Spring中的设计模式
- 模板方法设计模式: AbstractApplicationContext的refresh()方法中刷新上下文有十三个步骤,其中postProcessBeanFactory(),onRefresh()方法等子类都可以进行覆写。AbstractBeanFactory的子类需要实现模板方法createBean()和getBeanDefinition()方法。
- 原型设计模式和单例设计模式: 从beanFactory中获取对象时,根据beanDefinition的定义,每次获取时可能会返回一个新的对象(原型设计模式)也可能返回同一个对象(单例设计模式)
-
Spring IOC中一个bean创建过程中的扩展点
- InstantiationAwareBeanPostProcessor的postProcessBeforeInstantiation()方法。这个回调方法在目标bean实例化之前执行。返回的bean对象可能是代理对象,而不是目标bean,从而有效地抑制了目标bean的默认实例化。如果此方法返回了非空对象,则bean创建过程就结束了。后续唯一会执行的处理是BeanPostProcessors的postProcessAfterInitialization回调。
- MergedBeanDefinitionPostProcessor的postProcessMergedBeanDefinition()方法。在实例化之前调用,可以修改RootBeanDefinition中的信息。如AutowiredAnnotationBeanPostProcessor就实现了这个方法,解析带@Autowired的构造函数、方法、字段放到RootBeanDefinition中以及@Value注解的字段,并且会在后面调用postProcessProperties()方法的时候填充属性。InitDestroyAnnotationBeanPostProcessor实现了这个方法解析@Init注解和@Destroy注解,并且把解析出来的方法集合添加到RootBeanDefinition中。其中@Init方法后续会在postProcessBeforeInitialization()方法中执行,而@Destroy方法后续会在postProcessBeforeDestruction()中执行。
- InstantiationAwareBeanPostProcessor的postProcessAfterInstantiation() 方法。这个回调方法在bean实例化后,但在Spring属性填充(从explicit properties或autowiring)发生之前执行。这是对给定bean实例执行自定义字段注入的理想回调,正好在Spring的autowiring开始之前。
- InstantiationAwareBeanPostProcessor的postProcessProperties(pvs)方法。这个回调方法在bean factory将参数中的pvs属性值应用于参数中的的bean之前,修改RootBeanDefinition中的pvs。
- 调用执行invokeAwareMethods(beanName, bean)方法,处理实现了BeanNameAware,BeanClassLoaderAware,BeanFactoryAware接口的bean。其它Aware接口实现bean的处理在ApplicationContextAwareProcessor中处理。
- BeanPostProcessor的postProcessBeforeInitialization()方法。这个方法在初始化之前执行。执行之前bean的属性值已经填充好了。如ApplicationContextAwareProcessor就实现了这个方法,并且会注入Environment,
EmbeddedValueResolverAware,ResourceLoader,ApplicationEventPublisher,MessageSourceAwareApplicationContext。ServletContextAwareProcessor实现了这个方法会注入ServletContext。另一种方式是实现InitializingBean接口的afterPropertiesSet()方法。 - BeanPostProcessor的postProcessAfterInitialization()方法。这个方法在任何bean初始化回调(如InitializingBean的afterPropertiesSet()或自定义init方法)之后执行。执行之前bean的属性值已经填充好了。
- 所有的bean创建完成后,会遍历所有的bean,会判断每个bean是否是SmartInitializingSingleton类型,如果是则执行这些bean的afterSingletonsInstantiated()方法。这个方法在singleton pre-instantiation阶段结束时调用,并保证已经创建了所有常规singleton beans。由于在这个阶段,所有的bean已经创建完成,所以在此方法中调用ListableBeanFactory.getBeanOfType()时不会有提前初始化bean的影响。
- 在finishRefresh()方法中会获取beanFactory中所有实现了SmartLifecycle接口的bean,然后遍历这些bean,按照int getPhase()方法的返回值排序,按从小到大的顺序执行这些bean的start()方法,每个bean执行start()之前,会通过getBeanFactory().getDependenciesForBean(beanName)方法获取依赖的beans,先把依赖的beans的start()方法执行了。一般用于组件的自动启动场景。Lifecycle接口的实现类也会执行,只不过phase默认是0。如kafka和spring集成时,kafka的消费线程就是通过这种方式启动的。
- 在ApplicationContext shutdown时,会按phase从大到小的顺序调用stop()方法。
- DestructionAwareBeanPostProcessor的postProcessBeforeDestruction()方法。另一种方式是实现DisposableBean的destroy()方法。ApplicationContext shutdown时会调用这个方法。
-
BeanDefinitionRegistryPostProcessor(BDRPP)和BeanFactoryPostProcessor(BFPP)执行顺序
- 执行实现了PriorityOrdered接口的BDRPP的postProcessBeanDefinitionRegistry()方法
- 执行实现了Ordered接口的BDRPP的postProcessBeanDefinitionRegistry()方法
- 执行剩下的BDRPP的postProcessBeanDefinitionRegistry()方法
- 按前面的顺序执行BDRPP的postProcessBeanFactory()方法
- 执行通过AbstractApplicationContext的addBeanFactoryPostProcessor()方法添加的BFPP
- 执行实现了PriorityOrdered接口的BFPP
- 执行实现了Ordered接口的BFPP
-
BPP的执行顺序
- 先执行实现了PriorityOrdered接口的BPP
- 然后执行实现了Ordered接口的BPP
- 然后执行普通的BPP
- 然后执行实现了MergedBeanDefinitionPostProcessor接口的BPP
-
ConfigurationClassPostProcessor执行过程
ConfigurationClassPostProcessor中获取类上的注解元数据是通过ASM技术实现的,可以做到不加载Class的情况下得到注解信息,是通过解析字节码得到的。- 先遍历所有的beanDefinition找到有@Configuration注解,或者带有Component注解,ComponentScan注解,Import注解,ImportResource注解,或者带有@Bean方法的类
- 解析上一步得到的配置类封装成ConfigurationClass实例的集合。解析之前会先处理下@Conditional注解,如果不符合则不处理此配置类。解析的过程如下:
- 先处理@PropertySources或@PropertySource注解,向Environment中添加一个PropertySource。
- 处理配置类上的@ComponentScan注解,这一步会理解注册对应的beanDefinitions。如果扫描到的beanDefinition中仍然有配置类,则会递归处理配置类。
- 处理配置类上的@Import注解。如果@Import注解的value配置的是DeferredImportSelector实现类,则先加到一个集合中等所有的配置类都解析完成后但是在loadBeanDefinitions之前再处理。如果value配置的是一个ImportSelector类,则调用它的selectImport()方法返回的class名称列表,然后递归处理这些class name上的@Import注解。如果value是一个普通的配置类,则递归按配置类处理。
- 处理配置类上的@ImportResource注解。把该注解中指定的locations属性值添加到ConfigurationClass实例的importedResources属性中,后续loadBeanDefinitions的时候再处理。一般用于导入额外的xml配置文件
- 处理配置类中的@Bean方法,拿到配置类中所有的@Bean方法的MethodMetadata集合,并且设置到配置类的beanMethods集合属性中。
- 以上都处理完之后,会继续处理配置类的父类。
- 根据上一步得到的ConfigurationClass的集合加载beanDefinitions。
- 先把import进来的类注册到beanFactory中
- 把@Bean注解的类注册到beanFactory中
- 把@ImportResource配置的路径的配置文件,加载到beanFactory中
- 把@Import注解中配置的ImportBeanDefinitionRegistrar类型的类,调用它的registerBeanDefinitions()方法注册beanDefinitions。
-
bean创建过程
- 先到缓存中获取bean。先到一级缓存中获取bean,一级缓存中存储的都是已经完全初始化完成的bean。如果一级缓存中没有并且当前bean正在创建中则到二级缓存中查找,如果二级缓存中没有则继续到三级缓存中查找,三级缓存中存储的是beanName和创建bean的lambda表达式的映射关系,如果三级缓存中有,则创建一个bean,并放到二级缓存中,然后删除三级缓存。
- 如果缓存中获取不到bean,则开始创建bean。
- 实例化bean之前先执行Bpp的postProcessBeforeInstance()方法。
- 实例化bean。
- postProcessMergedBeanDefinition()方法,修改beanDefinition。如解析@Autowired、@Value、@Init、 @Destroy、@PostConstruct、@PreDestroy、@Resource注解。
- 添加三级缓存,移除二级缓存。此时bean已经实例化,但是还没有填充属性和初始化,但是为了防止填充这个bean的属性时,在实例化某个属性时,依赖了这个bean,所以先把这个bean暴露出去,添加到三级缓存中。为了兼容AOP,三级缓存中取对象的时候回执行SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference()方法,有机会返回一个代理对象。
- 在实例化bean之后但是填充属性值之前,先调用执行postProcessAfterInstantiation()方法,然后调用postProcessProperties(pvs)方法,修改或添加pvs中的属性。如@Autowired、@Value、@Resource注解对应的属性值注入到bean中。
- 执行invokeAwareMethods(beanName, bean)方法,处理实现了BeanNameAware,BeanClassLoaderAware,BeanFactoryAware接口的bean。其它Aware接口实现bean的处理在ApplicationContextAwareProcessor中处理。
- 开始初始化bean。先调用postProcessorsBeforeInitialization()方法,在这个方法中会执行之前解析出来的@Init方法。然后调用InitializingBean的afterPropertiesSet()方法或者@InitMethod方法进行初始化。然后调用beanPostProcessorsAfterInitialization()方法。
- 所有的bean创建完成后,会遍历所有的bean,会判断每个bean是否是SmartInitializingSingleton类型,如果是则执行这些bean的afterSingletonsInstantiated()方法。这个方法在singleton pre-instantiation阶段结束时调用,并保证已经创建了所有常规singleton beans。由于在这个阶段,所有的bean已经创建完成,所以在此方法中调用ListableBeanFactory.getBeanOfType()时不会有提前初始化bean的影响。
- 在finishRefresh()方法中会获取beanFactory中所有实现了SmartLifecycle接口的bean,然后遍历这些bean,按照int getPhase()方法的返回值排序,按从小到大的顺序执行这些bean的start()方法,每个bean执行start()之前,会通过getBeanFactory().getDependenciesForBean(beanName)方法获取依赖的beans,先把依赖的beans的start()方法执行了。一般用于组件的自动启动场景。Lifecycle接口的实现类也会执行,只不过phase默认是0。如kafka和spring集成时,kafka的消费线程就是通过这种方式启动的。
Spring AOP
概述
SpringAop的实现方式是通过一个bpp生成代理类,代理类中的方法会调用一个DynamicAdvisedInterceptor的intecept()方法。而DynamicAdvisedInterceptor中具有Aop代理的拦截器链,会依次执行拦截器链,最后执行实际的方法逻辑,然后返回。
SpringAop的流程
- AnnotationAwareAspectJAutoProxyCreator这个BPP的postProcessAfterInitialization(Object bean, String beanName)方法会生成代理类。
- 首先初始化容器中所有注册的Advisor类型的bean。Advisor是在解析aop:before这类的标签时注册的,Advisor中包含了Advice属性和Pointcut属性。然后通过解析Advisor中的Pointcut的ClassFilter的逻辑和MethodMatcher的逻辑,筛选判断Advisor是否可以应用到这个beanClass。最终得到一个Advisor列表。对Advisor列表进行排序。然后在Advisor列表的第一个位置放一个new DefaultPointcutAdvisor(ExposeInvocationInterceptor),ExposeInvocationInterceptor必须放到第一个位置执行,它会把MethodInvocation放到ThreadLocal中,这样在拦截器链执行的过程中,其它的拦截器链才可以获得MethodInvocation。如果没有可用的Advisor则直接返回。
- 组装生成代理类的配置信息类。设置要代理的接口列表,如果有接口可以代理则使用jdk动态代理,否则使用cglib代理。设置targetClass。设置前面得到的Advisor列表。
- 通过代理的配置信息类生成代理类。根据上一步的配置决定是使用jdk动态代理还是cglib代理。jdk动态代理是通过InvocationHandler的invoke()方法实现的。cglib动态代理是通过Enhancer类实现的,Enhancer中设置代理类要实现的接口以及Callback数组,其中最重要的一个CallBack就是DynamicAdvisedInterceptor。其实InvocationHandler的invoke()方法和DynamicAdvisedInterceptor的intercept()方法逻辑是一样的,并且他们俩都持有代理配置类的实例,也就拥有了前面获取的Advisor拦截器链和targetClass信息。
- 代理类的代理方法逻辑如下:先从Advisor链中通过Advisor中的Pointcut对象筛选出可以应用到这个方法的Advisor链。其实拦截器链中不一定都是Advisor类型,也有可能是Advice类型,也有可能是MethodInteceptor。只是经过AnnotationAwareAspectJAutoProxyCreator生成的代理类中的都是Advisor类型。不过这里会通过适配器的设计模式统一把任何类型的拦截器都转换成MethodInteceptor类型。
- 然后new一个MethodInvocation的实例,并且MethodInvocation实例持有了拦截器链。然后调用proceed()方法。这个方法会把拦截器链中的每一个拦截器都执行一遍,最终通过反射调用实际的方法,然后返回值。执行拦截器链的时候第一个执行的就是ExposeInvocationInterceptor,它会把MethodInvocation对象放到ThreadLocal中,这样后续的拦截器也就是MethodInterceptor执行的时候就可以通过调用MethodInvocation对象的proceed()方法递归调用后面的拦截器链。
- 下面是ReflectiveMethodInvocation的代码
public Object proceed() throws Throwable {
//interceptorsAndDynamicMethodMatchers集合中存放的就是拦截器链,拦截器的类型是MethodInterceptor和InterceptorAndDynamicMethodMatcher
//currentInterceptorIndex表示当前执行到拦截器链中的位置,从-1开始
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size() - 1) {
//通过反射调用目标类的目标方法
return invokeJoinpoint();
}
//获取要执行的拦截器
Object interceptorOrInterceptionAdvice = this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex);
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher) {
InterceptorAndDynamicMethodMatcher dm (InterceptorAndDynamicMethodMatcher) interceptorOrInterceptionAdvice;
Class<?> targetClass = (this.targetClass != null ? this.targetClass : this.method.getDeclaringClass());
//如果InterceptorAndDynamicMethodMatcher中的methodMatcher.matches()方法返回true,说明这个方法应该被拦截器拦截。调用拦截器的invoke()方法。如果拦截器的invoke()方法内部调用了MethodInvocation的proceed()方法,那就会又回到这个方法,那么这个拦截器链的就可以继续执行,否则剩下的拦截器就执行不了了。所以拦截器链的执行,其实是从连接点发起的
if (dm.methodMatcher.matches(this.method, targetClass, this.arguments)) {
return dm.interceptor.invoke(this);
}
else {
//跳过这个拦截器,继续执行下个拦截器
return proceed();
}
}
else {
//直接调用拦截器的invoke()方法,如果invoke()内部调用了MethodInvocation的proceed()方法,那么就会又回到这个方法,继续执行后面的拦截器。
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this);
}
}
spring事务的实现方式
- @EnableTransactionManagement注解会注册InfrastructureAdvisorAutoProxyCreator,这是一个BPP,它和AnnotationAwareAspectJAutoProxyCreator一样都是用于生成代理对象的,唯一的区别就是InfrastructureAdvisorAutoProxyCreator再查找一个类的Advisor列表时只会考虑beanDefinition.getRole() == BeanDefinition.ROLE_INFRASTRUCTURE的基础设施beanDefinition,用户自己声明的Advisor不会考虑。还会注册BeanFactoryTransactionAttributeSourceAdvisor,Advisor中的Advice就是TransactionInterceptor,而Pointcut就是TransactionAttributeSourcePointcut。
- AnnotationAwareAspectJAutoProxyCreator在查找Advisor链时,就找到了BeanFactoryTransactionAttributeSourceAdvisor,TransactionAttributeSourcePointcut判断逻辑是查找Class上或者方法上是否有@Transactional注解。
- 生成代理类的逻辑和Spring Aop中的逻辑一样。生成的代理类,就会调用TransactionInterceptor的invoke()方法进行拦截,实现事务。
精读SpringMVC源码,。
- 概览
springmvc概览,springmvc是spring的扩展模块,启动springmvc的时候会创建两个ApplicationContext,一个是spring本身,是父上下文,一个是springmvc,是子上下文。
web项目是运行在tomcat中的, tomcat识别的配置文件是web.xml,web.xml中需要配置spring容器本身的xml配置文件以及springmvc的xml配置文件。思考:为什么要有两个上下文呢,因为mvc中的很多类是web专用的,而spring上下文是一个基础的上下文,如果把mvc中的类也放到spring上下文中,那么结构就不清晰了。本来很多类只在自己的上下文就能找到了,速度也会快一些,找不到才需要到父上下文中找。如果所有框架的的类都加到spring上下文中,那么查找bean的性能肯定就不好了。 - 如何从tomcat启动Spring容器的
先启动Spring上下文。tomcat启动会加载web.xml文件,并且把web.xml配置文件中除了标签外的其它配置封装到servletContext中。tomcat加载完web.xml文件后会调用标签配置了一个监听器,这个监听器需要实现Servlet中的ServletContextListener接口,并且实现contextInitialized(ServletContextEvent event)方法。监听器根据web.xml中配置的contextConfigLocation属性的Spring配置文件的位置,创建Spring root上下文。并且会把servletContext中的属性值添加到Environment中。并且把spring root context设置到servletContext的属性中,同时也会把servletContext设置到Spring context中。
然后启动Spring mvc上下文。tomcat会调用DispatcherServlet的init()方法完成。根据web.xml中标签中配置的属性值会封装到servletConfig对象中用于初始化mvc上下文。创建mvc上下文时会从servletContext中获取spring上下文并设置为mvc的父上下文。mvc上下文创建完成后,也会设置到servletContext中。并且会把servletConfig和servletContext设置到mvc上下文中。刷新上下文之前会添加一个监听器ContextRefreshListener,这个监听器是DispatcherServlet的父类的一个内部类。会在mvc上下文refresh完成时被执行,这个监听器执行的逻辑,也就是mvc的核心逻辑了。 - ContextRefreshListener的核心逻辑,就做了一件事就是初始化mvc的九大组件
1. initMultipartResolver(context)
2. initLocaleResolver(context);
3. initThemeResolver(context);
4. initHandlerMappings(context);
从spring容器中获取如果没有则从DispatcherServlet.properties配置文件中获取,配置文件中配置了三个分别是BeanNameUrlHandlerMapping,RequestMappingHandlerMapping,RouterFunctionMapping,然后会创建这三个bean. BeanNameUrlHandlerMapping用于处理beanName是/开头的handler,RequestMappingHandlerMapping用于处理@Controller注解和@RequestMapping注解的handlerMethod, RouterFunctionMapping是为了支持RouterFunctions,是spring5.2以后才出现的,一般用不到,可以忽略。这个接口只有一个方法,HandlerExecutionChain getHandler(HttpServletRequest request),根据request匹配到对应的Handler, 但是不会直接返回的Handler,而是会和HandlerInterceptors一起封装HandlerExecutionChain对象返回,执行请求时DispatcherServlet会先执行所有的HandlerInterceptor的preHandle()方法,然后才会执行Handler。-
RequestMappingHandlerMapping不仅实现了ApplicationContextAware接口还实现了InitializingBean接口,不仅会执行setApplicationContext()方法还会执行afterPropertiesSet()方法,会做以下事情:
1 扫描容器中所有的HandlerInterceptor添加到adaptedInterceptors属性中,包含父容器中的HandlerInterceptor
2 处理springmvc容器中带有@Controller或@RequestMapping注解的bean,处理这些bean以及它的父类和父接口的带有@RequestMapping注解的方法, 把方法上的@RequestMapping注解的属性值封装到RequestMappingInfo对象中,bean上的@RequestMapping注解的属性值也封装到RequestMappingInfo对象中,这两个对象合并成一个对象,然后把bean,method封装成HandlerMethod对象,然后把HandlerMthod对象和requestMappingInfo对象注册到RequestMappingHandlerMapping的mappingRegistry属性中,用于后续处理请求时匹配handler使用。
5. initHandlerAdapters(context);
HandlerAdapter使用了适配器模式。
从spring容器中获取,如果没有则从DispatcherServlet.properties配置文件中获取,配置文件中配置了四个分别是HttpRequestHandlerAdapter,SimpleControllerHandlerAdapter,RequestMappingHandlerAdapter,HandlerFunctionAdapter。
DispatcherServlet不会直接访问Handler,而是会通过HandlerAdapter访问,这个接口有两个方法boolean supports(Object handler)和ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)。
需要注意的是Handler可以是任何类,这些类可以是实现了Contrller接口的类,也可以是实现了HttpRequestHandler接口的类。也可以是其他的类。所以需要HandlerAdapter统一一下处理调用Handler的方式,每一个类型的Handler都需要有一个对应的HandlerAdapter实现,所以springmvc可以支持其他框架的Handler,只要实现对应的HandlerAdapter即可。 -
RequestMappingHandlerAdapter创建bean的流程:
- 查找上下文中所有带有@ControllerAdvice注解的类,遍历这些类,分别收集类中带有@ModelAttribute注解、@InitBinder注解的方法。并且还会收集实现了RequestBodyAdvice或者ResponseBodyAdvice接口的@ControllerAdvice类。
- 初始化参数处理器,参数处理器接口有两个方法,一个是判断是否支持这种类型的参数,一个是解析参数的方法。如RequestParamMethodArgumentResolver参数解析器是用于处理@RequestParam注解的参数的,并且会处理注解中的${}占位符和spel表达式。
- 初始化返回结果处理器。如处理ModelAndView返回值的,处理@ResponseBody返回值的,有的解析器既可以处理请求参数也可以处理返回值,这里返回的解析器放在returnValueHandlers中,则只用于处理返回值. 处理@ResponseBody的解析器名称是RequestResponseBodyMethodProcessor。创建RequestResponseBodyMethodProcessor对象时调用的构造函数是new RequestResponseBodyMethodProcessor(getMessageConverters(),this.contentNegotiationManager, this.requestResponseBodyAdvice),所以会把handlerAdapter中的messageConverters,requestResponseBodyAdvice,contentNegotiationManager都放进去,后面解析返回值的时候都会用到。
- initHandlerExceptionResolvers(context);
- initRequestToViewNameTranslator(context);
- initViewResolvers(context);
- initFlashMapManager(context);
-
- DispacherServlet的service()方法执行流程
- 根据request,遍历九大组件中的handlerMappings,查找满足条件的handler。查找到的handler会和符合条件的HandlerInterceptor一起封装成HandlerExecutionChain对象返回。
- 遍历九大组件中的handlerAdapters,查找handler对应的handlerAdapter
- 遍历执行HandlerExecutionChain对象中的拦截器集合interceptorList,执行拦截器的preHandle()方法,如果任何一个拦截器的这个方法返回false,则停止执行,并且按刚刚拦截器执行的顺序倒序执行拦截器的afterCompletion()方法。
- 调用handlerAdapter.handle()方法处理请求。这里面在调用实际handler方法前会调用参数处理器解析参数,参数解析器解析完参数名并从request得到参数值后还会用@InitBinder注解方法把String类型的值转换成对象。在得到返回值返回之前,会调用返回值解析器处理返回值。
- 遍历执行HandlerExecutionChain对象中的拦截器集合interceptorList,执行拦截器的postHandle()方法
- 如果有异常则调用九大组件中的exceptionResolvers处理异常
- 调用九大组件中的viewResolvers,根据方法的返回值返回View对象。
- Spring mvc的设计模式
适配器模式: 因为handler类有不同的实现形式,如@Controller类、实现了Controller接口的类、实现了HttpRequestHandler的类等等。为了统一调用handler的方式,使用了适配器模式,每个handler都有一个对应的handlerAdapter,通过handlerAdapter调用handler。
精读SpringBoot源码。深入理解SpringBoot的自动配置原理、@SpringBootConfiguration注解自动配置的原理、@ConditionalOnBean等相关注解的原理、@EnableConfigurationProperties注解的原理、各种starter自动配置的原理。
精读mybatis源码。深入理解Mybatis的核心组件、插件机制、Mapper接口方法到sql语句的映射机制、mybatis的日志机制、mybatis的事务机制、mybatis如何与SpringBoot进行整合的。
熟练掌握Mysql。深刻理解Mysql的索引原理及索引的使用场景、注意事项。具有sql优化的经验。
熟练使用ES,熟悉ES的数据类型、常见的QueryDSL语法、倒排索引的结构。
熟练使用SpringCloud、Eureka。
熟练掌握Redis。非常熟悉redis的数据类型、redis的高级特性、redis的使用场景,并能在工作中合理使用redis。
熟练掌握Kafka,并阅读过spring-kafka客户端的源码,了解kafka是如何与spring整合的。
熟练掌握zookeeper。
熟练掌握Seata。深入理解Seata的分布式事务执行流程、@GlobalTransactional和@GlobalLock的区别、如何防止脏读和脏写等细节。
精读canal的源码。深入理解canal的各个细节。如canal的各个组件及其功能、启动流程、canal的常用配置、canal如何保证消息顺序性、canal启动时如何查找binlog的start position、canal是如何记录消费位点的。能在工作中熟练使用canal并解决binlog位点不存在等问题。
熟练掌握Apollo配置中心。深入理解Apollo的整体架构、配置实时推送原理、apollo整合Spring的Environment原理。
熟练使用linux常见命令,熟练使用k8s常见命令,熟练使用arthas定位并解决线上问题。
熟悉IDEA插件开发,能够对已有的IDEA插件进行二次开发。
云MES生产管理系统-用户自定义字段模块
- 监控报警查询物料接口超时两秒的比例上升,使用arthas定位问题
通过arthas-tunnal连上对应的服务,调用trace demo.MathGame query -n 20 ‘#cost > 2000’ 打印出query方法内每部分的耗时、依次向下追查。最后查到是因为查数据库的时候慢。
然后去看数据库的慢日志,发现没有相关的数据库慢日志,数据库负载也正常。
然后执行dashboard命令查看机器负载,发现cpu使用率很高,jvm内存使用率正常。
然后调用thread -n 3,打印出占用cpu前三名的线程堆栈。通过查看线程堆栈,发现是forEach标签和pageHelper插件的问题,因为sql查询语句中使用了forEach标签,myBatis在处理的时候,会把sql语句组装成一个对象,每一个forEach都需要创建一个对象的对象。查询出了十万个id的时候,mybatis处理sql就会花费很多时间。并且PageHelper当调用startpage()方法的时候如果传了order by参数,就会需要处理sql语句为了去掉sql语句中带的order by关键字,这一步和mybatis类似,也会花费很多时间。
解决办法就是把forEach标签换成调用java方法,使用Collections.join(),方法把idList转成逗号分隔的字符串。还有调用PageHelper.startPage()时不要带orderBy参数。
- 定位canal消费时报binlog字段数量和TSDB数据库中的存储的字段数量对不上的问题
首先讲一下canal的TSDB原理,canal启动时会启动一个24h执行一次的定时任务,定时任务的任务是把内存中存储的每张表的ddl语句、destination、canal当前消费的位点信息(binlog和offset)、binlogTimestamp存储到meta-snapshot表中,并且删除15天之前的快照。相当于存储当前binlog消费位点时刻,每张表ddl语句的一个快照。中间如果有新的ddl语句执行了,就会存储到meta-history表中。每次当canal重新启动时会先查找startPosition,然后会根据startPosition的时刻,到meta-snapshot表中查找到在startPosition的时刻之前最近的一条记录再追加上meta-history表中在startPosition时刻之前的所有记录。然后在memoryTableMeta中回放。
按照以上的原理,那么15天之内的binlog,字段都是可以正常对的上的。但是我们的canal刚开始使用的是h2数据库而不是mysql。所以一旦重启canal整个服务,其实meta-snapshot中就是最新的ddl语句了。在发布的时候,canal重启以后,meat-snapshot中肯定就是最新的ddl语句了,如果某张表执行了ddl语句,那么在解析执行ddl语句之前的binlog都会有问题。当时的解决方案就是在h2数据中的meta-snapshot表手动插入一条之前的快照。
解决方案是使用mysql存储metatsdb。
-
开发环境定位canal启动时报binlog文件不存在的问题
canal可能有段时间没重启,重启的时候会从zk中查找开始消费的位点。zk中存储的binlog 名称对应的binlog可能已经被删除了导致找不到binlog。解决方案就是删除zk的节点,canal就会从数据库最新的位置开始消费。 -
线上cpu高报警解决
通过threadcpu高的线程是垃圾回收线程,然后查看