row_number 和 cte 使用实例:分组轮流排班
row_number 和 cte 使用实例:分组轮流排班
- 分组轮流排班
-
- 需求小分析
-
- 使用 cte 模拟临时数据
- 使用 row_number 分组编号
- 使用聚合函数得到各组最大值
- 使用日期差函数计算轮班天数
- 使用求余运算完成排班
- 使用列转行完成当日排班表
- 小结
分组轮流排班
问题出自问答区某个小伙伴的问题,原地址:https://ask.csdn.net/questions/7910424
小伙伴的问题描述的稍微有些不那么清晰,老顾重新描述一遍
有某工厂,多个车间,每个车间中工人数量不同,每天需要所有车间都派出一个人进行值班,在该车间所有人都进行完值班前,不重复安排值班。
在实现这个问题之前,还是按照老顾的习惯,先进行一下分析,我们需要哪些步骤,如何实施我们的需求?
需求小分析
1、我们需要对每个车间的人员进行一个编号,按照编号顺序值班
2、我们需要知道从哪一天开始值班,这一天,所有值班人员的编号都是1,即第一个人
3、我们需要知道每个车间有多少人,可以计算该车间多少天轮流一轮
4、我们需要知道从开始值班那一天到指定日期的时间差
5、在非必要情况下,没有人员变动,比如新入职或离职或请假等问题
那么,分析结束后,我们的实现逻辑也就出来了,第一步,给所有人员按车间分组进行编号,一个大家都很熟悉的开窗函数 row_number 就此闪亮登场。
使用 cte 模拟临时数据
嗯,先用 cte 模拟一些数据出来,就不建立临时表了
with t as ( -- 原始数据
select 1 as id,'aaa' name,'A' job
union all select 2,'aba','A'
union all select 3,'xxz','A'
union all select 4,'fee','B'
union all select 5,'3fee','B'
union all select 6,'f5ee','B'
union all select 7,'f4ee','B'
union all select 8,'fe8e','B'
union all select 9,'fe0e','B'
union all select 16,'tte','Bc'
union all select 17,'xtxt','Bc'
union all select 18,'uyuy','Bc'
union all select 19,'zzz','Bc'
)
select * from t

这里使用了 cte 表作为数据来源了,关于 cte 表的使用,大家可以自行百度一下,大部分数据库现在都是支持 cte 使用的。
不过,作为微软系软件的使用者,老顾推荐看 msdn 的原文:https://learn.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms190766(v=sql.105)?redirectedfrom=MSDN,https://learn.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008-r2/ms175972(v=sql.105),这里有简单的示例和完整的语法说明。
老顾使用 cte 不喜欢先定义字段名,因为这种用法是针对已有现成数据的情况下,不需要定义数据类型,而老顾做模拟数据,一般喜欢直接用第一行数据来定义字段名和数据类型。
使用 row_number 分组编号
在使用 cte 的时候,大部分数据库是支持连环使用多次调用的,否则也没法做 cte 递归查询了,当然递归不是这个需求的重点,老顾想说的是 cte 支持连续多次书写
with cte1 as (),cte2 as (),cte3 as ()
所以,我们接着上边的内容书写
with t as ( -- 原始数据
select 1 as id,'aaa' name,'A' job
union all select 2,'aba','A'
union all select 3,'xxz','A'
union all select 4,'fee','B'
union all select 5,'3fee','B'
union all select 6,'f5ee','B'
union all select 7,'f4ee','B'
union all select 8,'fe8e','B'
union all select 9,'fe0e','B'
union all select 16,'tte','Bc'
union all select 17,'xtxt','Bc'
union all select 18,'uyuy','Bc'
union all select 19,'zzz','Bc'
),t1 as ( -- 按job划分每个人需要的值班序号
select *,row_number() over(partition by job order by id) wid from t
)
select * from t1
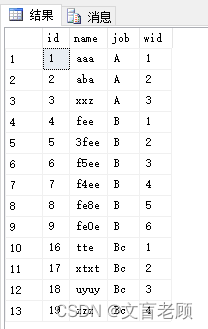
可以看到,使用了 row_number 后,根据 partition 分组,每个相同的 job 的人员都有不同的编号了,需要注意的是,不管是 row_number 也好,rank也好,都是从数字1开始分配序号的,而不是大家编程时习惯的下标0开始的索引。
使用聚合函数得到各组最大值
再接着前边的 cte 指令续写,直接引用 t1 的数据,使用 max 聚合函数得到最大的序号,就是这个组内的人数了。
with t as ( -- 原始数据
select 1 as id,'aaa' name,'A' job
union all select 2,'aba','A'
union all select 3,'xxz','A'
union all select 4,'fee','B'
union all select 5,'3fee','B'
union all select 6,'f5ee','B'
union all select 7,'f4ee','B'
union all select 8,'fe8e','B'
union all select 9,'fe0e','B'
union all select 16,'tte','Bc'
union all select 17,'xtxt','Bc'
union all select 18,'uyuy','Bc'
union all select 19,'zzz','Bc'
),t1 as ( -- 按job划分每个人需要的值班序号
select *,row_number() over(partition by job order by id) wid from t
),t2 as ( -- 获得每个班有多少人进行轮班
select job,max(wid) nums from t1 group by job
)
select * from t2
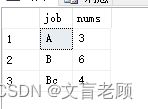
使用日期差函数计算轮班天数
假定我们从2023年1月1日起开始实施这个排班计划,那么我们就需要指定开始日期为 2023-1-1 了,然后使用时间差函数 datediff 来计算我们需要排版的天数。
select datediff(d,'2023-1-1',getdate()) -- 今天是2023年4月3日,所以日期差为92天
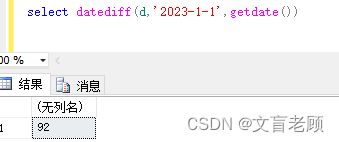
这里需要注意了,日期差的索引是从0开始的。。。。即2023-1-1是第 0 天!
使用求余运算完成排班
有了天数差之后,我们就可以和各组的人数进行求余,余 0 的为第一个人,余 1 的为第二个人,以此类推,所以最后的指令就出来了。
with t as ( -- 原始数据
select 1 as id,'aaa' name,'A' job
union all select 2,'aba','A'
union all select 3,'xxz','A'
union all select 4,'fee','B'
union all select 5,'3fee','B'
union all select 6,'f5ee','B'
union all select 7,'f4ee','B'
union all select 8,'fe8e','B'
union all select 9,'fe0e','B'
union all select 16,'tte','Bc'
union all select 17,'xtxt','Bc'
union all select 18,'uyuy','Bc'
union all select 19,'zzz','Bc'
),t1 as ( -- 按job划分每个人需要的值班序号
select *,row_number() over(partition by job order by id) wid from t
),t2 as ( -- 获得每个班有多少人进行轮班
select job,max(wid) nums from t1 group by job
)
select *,datediff(d,'2023-1-1',getdate()) % nums
from t1 a
left join t2 b on a.job=b.job
-- 获得自2023年1月1日开始排版后,今天需要排班的人员
where datediff(d,'2023-1-1',getdate()) % nums = wid - 1

这里使用了关联查询,将最大人数和排班组合起来了,然后根据日期求余结果筛选出符合的人员。嗯,刚才提醒过了 wid 是从1开始的,日期差求余是从 0 开始的,所以我们这里 wid - 1。
使用列转行完成当日排班表
最后的最后,就是如问答题主的要求一样了,使用列转行,只列当天每个车间需要值班的人员名单。pivot 是 mssql 特有的一个指令,非常实用哦。mysql 在进行行转列,列转行时就废了老劲了。
with t as ( -- 原始数据
select 1 as id,'aaa' name,'A' job
union all select 2,'aba','A'
union all select 3,'xxz','A'
union all select 4,'fee','B'
union all select 5,'3fee','B'
union all select 6,'f5ee','B'
union all select 7,'f4ee','B'
union all select 8,'fe8e','B'
union all select 9,'fe0e','B'
union all select 16,'tte','Bc'
union all select 17,'xtxt','Bc'
union all select 18,'uyuy','Bc'
union all select 19,'zzz','Bc'
),t1 as ( -- 按job划分每个人需要的值班序号
select *,row_number() over(partition by job order by id) wid from t
),t2 as ( -- 获得每个班有多少人进行轮班
select job,max(wid) nums from t1 group by job
)
select * -- 最后按照班列出今天需要排班的人
from (
select name,a.job
from t1 a
left join t2 b on a.job=b.job
-- 获得自2023年3月1日开始排版后,今天需要排班的人员
where datediff(d,'2023-1-1',getdate()) % nums = wid - 1
) a
pivot(max(name) for job in (A,B,Bc)) p -- 这里需要把所有的班名都列出
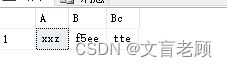
最后的结果出来了,4月3日需要值班的分别是A车间的xxx,B车间的f5ee,Bc车间的tte。
列转行有一个需要注意的地方,那就是不要出现多余的字段,如果有多余字段且数据不重复的话,那么会分成多行,无法合并到一行上。
小结
这次我们使用了不少基础内容,灵活运用已经学会的内容,进行个性化组合,就可以完成从未设想过的功能了。cte,row_number,日期计算,列转行,这几项内容,大家如果想要深入学习,自行百度即可,虽然同质化比较严重,但好文章还是不少的。愿大家都能做一匹千里好马,驰骋万里。