【精彩内容分享】SoCC 2022 | 大规模云系统自动化容量评估的探索与落地 – DeepScaling
以下内容来自公众号【蚂蚁技术风险TRaaS】
1.前言
在线服务提供商比如Google、Facebook、蚂蚁、腾讯等为了保证自身服务的SLO,在进行资源配置时通常会采取“保守”策略:即配置相对较低的目标CPU利用率,以预防峰值流量带来的冲击,即使这将导致潜在的资源浪费。
但研究表明,服务器集群长期处于较低的CPU利用率,除了物理资源的浪费,能源消耗(电力)同样会大幅增长[12, 18, 19]。针对这个问题,直觉上可以将低负载服务的物理资源腾挪给高负载服务,来提高低负载服务的资源利用率,减少资源浪费和能源消耗,另一方面,更能够有效提升高负载服务的业务体验(例如降低RT、减少error)。
为此,蚂蚁一直在试图寻找一种自动化容量评估系统来使系统的CPU利用率能够被稳定在所需的目标水位,并能够保障我们的服务SLO得到满足。
这项工作在耗时敏感的金融支付服务中,挑战更为严峻:
●首先需要确保以及时、反应迅速的服务来保证用户的体验质量(稳定性)
●其次应当确保适当的资源供应,而不会出现明显的过度供应(有效性)
●并能够适应连续、显著的负载变化(灵活性)
为此,我们结合蚂蚁自身的基础设施架构、线上业务诉求,设计开发了这一套名为DeepScaling的自动化容量评估系统,在减少线上服务器集群资源消耗低同时,保障线上业务SLO不被打破。即通过深度学习方法寻找能够保障服务SLO的最大CPU利用率,并将线上服务CPU利用率稳定在这一水位,以实现资源节省,如下图1所示:
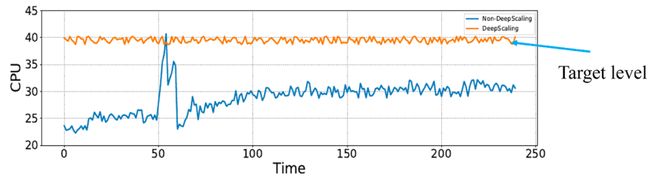
图1.DeepScaling的达成目标示例
这套系统于2020年底开展规划,于2021年上半年完成开发,2021年中投入使用。基于该工作沉淀出的学术论文《DeepScaling: Microservices AutoScaling for Stable CPU Utilization in Large Scale Cloud Systems》[0] 已发表于云计算领域唯一顶会ACM Symposium on Cloud Computing(SoCC) 2022。该工作由蚂蚁集团、重庆大学、加州大学河滨分校(UC Riverside)合作完成。
SoCC 2022从数百篇投稿中仅仅接收了38篇论文,来自世界著名大学如MIT,UCBerkeley,Stanford,UIUC等以及云计算大厂Microsoft,Amazon,Google,IBM等。来自国内企业界的论文包含华为参与的有4篇,阿里巴巴参与的有5篇(恭喜阿里云),来自蚂蚁的只有我们这一篇。
2.背景和现状
2.1 蚂蚁背景
当前蚂蚁拥有超过大量在线应用部署单元,资源规模庞大,虽然部分应用的峰值CPU利用率较高,但在线应用的平均CPU利用率长期处于低水位,存在大量波谷资源的优化空间。
一个典型的微服务系统如下图2所示,通常以用户请求开始,以对数据的操作结束,且系统中每个微服务节点,由其所在链路层级决定,各自承载不同的业务量,如PV、rpc、msg、dal、cal等,由此导致每个app都具有不同的workload特性。

图2.一个简单的拥有5个微服务的系统架构
另一方面,即使是同一workload类型主导的应用,由于上下游链路承载业务的差异性,波峰波谷周期的差异性,以及系统内部定时任务的差异性,真正建模时也拥有着各种各样的特性。
因此,我们需要一套适合蚂蚁在线应用的全局容量自动化评估体系,满足线上如此复杂业务特性的业务高稳定性和千人千面的需求。
2.2. 业界现状
过往,工业界和学术界对于自动化容量评估的研究,主要可以划分为两大类:
●rule based schemes [2, 3, 7]
●learning-based schemes [4, 8, 10, 13, 14, 15]
Rule based方法通常采取对系统性能指标(如CPU利用率,内存利用率等)/业务指标(如RT、error等)设置阈值的方式,当观测指标上涨超过上界时进行扩容,当观测指标下降低于下界时触发缩容。Rule based方法的主要限制在于,它们需要大量的专家经验/领域知识来为不同的服务设置适当的阈值。此外,为每个微服务设置阈值需要大量人力投入(该成本可能接近甚至超过资源节省的收益),因为大规模工业系统通常有超过数千个微服务,且由于不同的微服务特性不尽相同(如计算密集型和数据密集型等),不同服务的阈值必须以不同的方式进行设置。这在大规模云服务系统中是难以实现,且成本巨大的。
Learning-based方法可以有效地减少人力投入,这在大规模云服务系统中是至关重要的,但目前的研究很少兼顾资源浪费(由于服务负载的变化)和SLO的保证 [14]。而这在生产云环境中却十分常见,例如蚂蚁自身的在线支付系统需要数以万计的容器以满足一天中某些时段的峰值需求,而在其余时间只需要几千个容器,在夜间可能需求更少。但资源管理员倾向于过度提供服务资源以满足高峰期的SLO,导致各种资源的长期处于低利用率状态(平均意义上)。
当前业界公开的learning-based方案主要以减少系统异常为目标,这些异常通常包括服务RT达到某一临界值,CPU利用率过高,或者出现内存溢出等,此类框架主要以FIRM和Autopilot为代表,分别来自学术界UIUC和Google工业界实践。
●FIRM使用机器学习技术检测服务性能异常(例如,微服务的RT异常升高),以便在发生此类异常时,可以通过添加更多的pod或计算资源来扩容。FIRM最主要的限制在于,只有在性能异常发生后才会进行自动缩放,这有可能使服务异常持续一段较长的时间。大规模的自动缩放可能需要几分钟的冷启动,或者至少几秒钟的热启动。FIRM的另一个限制是,由于通过系统异常进行触发,当分配给微服务的资源超过必要时,它无法提供缩小规模的策略。
●Autopilot将微服务的CPU利用率的时间序列作为输入,通过启发式机制输出目标CPU利用率,然后使用此目标CPU利用率以线性函数折比的形式计算所需的pod数。Autopilot的优势在于设计简洁,但根据我们对Autopilot的实现和实验,Autopilot仍然面临比较严峻的系统稳定性问题,因为对所需pod数量的估计常常不够精确。这主要由如下两个原因导致:(1)CPU利用率和计算资源之间的关系通常是非线性的,而Autopilot则使用完全的线性假设;(2) 不同的微服务对计算和I/O资源的需求通常存在差异,不应简单视为一致。
此外,也有很多工作负载驱动的自动缩放方法。例如,[1]使用回归树来建模pod数量和RT之间的关系,然后生成建议的pod数量,以避免服务RT超时。[13]利用工作负载的当前状态、微服务调用链数据来建模微服务,以及使用图形神经网络(GNN)表示调用结构,其专注于预测尾部延迟,寻求主动优化每个微服务可用的总CPU资源,同时满足延迟SLO。这些基于RT的方法虽然直接对SLO进行优化,但通常难以精确建模,原因在于RT的分布和状态转移比起CPU利用率的刻画,是十分困难的。
由此,一个简单的想法是规避SLO的直接建模,通过一个性能模型来描述服务CPU利用率或内存利用率的变化,来间接反应。例如,[6]建议对每个pod实例的个体性能进行基准测试,并预测工作负载。[17]提出了一种方法,可以自动识别需要扩展的服务,并对其进行扩展以满足SLA,同时为系统提供最佳成本。然而,这些方法在维护SLO之外,对于节省服务资源并未能取得显著成效。
3.DeepScaling详解
DeepScaling提出了一个新的容量评估目标,旨在从一个最初的粗略的目标CPU水位出发,通过机器学习方法,最大化目标CPU利用率(即自动寻找能够保障服务SLO的最大CPU利用率,规避专家经验/领域知识),并将线上服务CPU利用率稳定在这一水位(以实现资源节省)。整体架构如图3所示。

图3.DeepScaling系统架构
3.1 DeepScaling整体架构
整体的系统架构如图3所示,包含如下模块:
●Load Balancer:每个服务的负载均衡强制执行一个策略,将请求公平地分发到为相应服务提供的pods。服务在同一数据中心部署和自动扩展,该区域通常具有相同的硬件配置,以便服务的每个实例,承载大致相同的工作负载,并具有相同的CPU利用率。
●Service Monitor:服务监控侧重于实时收集所有服务的指标,包括七个工作负载指标、CPU利用率、有关实现SLO的信息(RT、error等)以及实例数,收集的数据被聚合到分钟粒度。对所有工作负载度量数据进行汇总,并对每个服务的所有实例的CPU利用率数据进行平均。
●Workload Forecaster:我们分析每个微服务的调用图和主要工作负载指标,然后使用时空图网络(STGNN)预测每个微服务的工作负载。调用图有助于建模服务之间的流量关系。因此,STGNN对每个时间段(例如30分钟)的工作负载指标进行了高度准确的预测,预测的工作负载将被反馈到CPU Utilization Estimator。
●CPU Utilization Estimator:此模块基于7个工作负载指标以及3个特定的辅助变量(服务ID、时间戳和实例计数)估算CPU消耗。这10个(=7+3)指标与CPU利用率之间的非线性关系由深度概率回归网络建模。依据Scaling Decider给出的最新实例数作为输入,本模块输出CPU利用率的估计。
●Scaling Decider:在本模块中,采用强化学习(RL)模型生成自动缩放策略。详细来说,model based DQN模型与CPU Utilization Estimator一起工作,以快速确定最佳服务实例数。为了允许共享策略生成模型中包含多个服务,我们将服务ID包含在DQN模型的经验池中。
●Target level Controller:CPU目标水位( ) 是DeepScaling的核心参数, 的初始值是过去正常执行服务的最大CPU利用率。DeepScaling会提供一定的缓冲( = 5%),以考虑可能的模型误差和其他噪声。当服务在目标水位附近( ± )运行时,将获取建议的实例个数, 不打破SLO。对于目标水位,此缓冲值还可以应对轻微的负载均衡变化、预测或估计的错误以及非均匀的CPU特性。急剧的变化或者较大的估计错误将触发SLO违规,此时将降低目标CPU水位 , 以使服务达到新的稳定值。
●SLO Monitor:SLO监控通过观测微服务响应时间(RT)、GC(垃圾收集)时间、I/O RT等指标来确定核心微服务是否违反其SLO。当SLO监控检测到核心微服务的度量值异常时,它会通知Target level Controller降低该服务的目标CPU水位。
●Instance Controller:作为整体自动缩放任务的一部分,Instance Controller实时完成服务停用(关闭实例)任务,并通过热启动所需数量的实例(在15秒内)或冷启动(在5分钟内)来完成服务部署任务。Instance Controller通过增加或减少pod的数量来调整每个微服务的服务资源。
●Vertical Pod Autoscaler (VPA) Controller:DeepScaling原则上使用标准容器(Kubernetes 4C8G-4 CPU内核,8 GB RAM)来实现服务的水平自动伸缩(HPA)。而为了支持不同类型服务的特定资源需求,系统支持VPA控制器,用于在部署之前对每个服务的pod配置进行全局设置。这意味着,在水平扩展期间,每个服务实例共享相同的pod配置。对于大多数服务,VPA控制器不被激活,仅对少量特殊需求的服务开启。例如,对于某些内存敏感服务,资源管理员调用VPA控制器将默认的配置修改为比如4C16G。VPA通常配置为在部署前进行优化,而DeepScaling考虑在部署后通过自动缩放pod副本数目进行集群级别的资源管理。
3.2 DeepScaling模型介绍
DeepScaling包含三个主要算法模块:流量预测模型(Workload Forecaster),CPU估计模型(CPU Utilization Estimator),容量决策模型(Scaling Decider)。三者均有其自身的挑战。3个算法模块的示意图如图4所示。下面我们分别介绍3个算法模块。
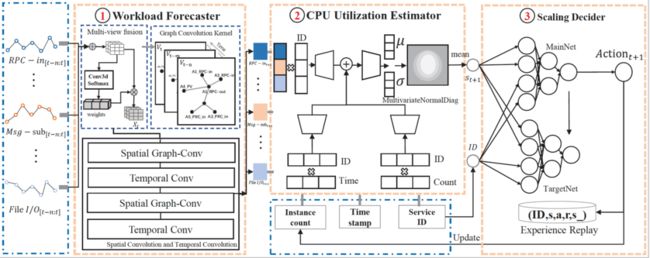
图4.DeepScaling的3个算法模块示意图
A. 流量预测模型
大规模微服务系统在调用链路上通常存在广泛的关联性,业界普遍采用的基于单时序的自回归预测模型 [1, 9] 很难刻画出不同微服务间流量的相互影响,也就很难做出准确的预测。针对流量预测,算法团队提供了一系列不同的算法来支持不同需求,包括Pyraformer处理长程依赖, 以及基于时空图网络(Spatio-temporal graph neural networks, STGNN)来捕获这种空间上的广泛关联。STGNN通过建模服务调用图的相互作用,以及流量负载指标之间的多变量关系(包括RPC、MSG、PV等各种流量负载),使我们的流量预测模型能够提供更大的时间跨度来进行资源规模的调整。


B. CPU估计模型
在流量预测模型的基础上,CPU估计模型将会构建流量负载到CPU利用率的映射,当然也包括一些后台任务对服务器的影响。业界公开的容量评估系统通常采用RPC刻画服务器CPU利用率,但这在系统架构可能是不完备的,原因在于不同微服务/不同请求的性质可能截然不同,有些是计算密集型,有些是I/O密集型等等。为了解决这个问题,我们收集了每个服务的多维工作负载,包括RPC请求、文件I/O、DB 访问、消息请求、HTTP请求,以及特定的辅助特征(实例数、服务ID、时间戳等),以全面描述服务的工作负载,使模型能够准确估计服务器的CPU利用率。所有这些特征将通过一个我们设计的基于深度概率网络的模型作用于CPU利用率的估计,以准确估计CPU消耗,即使在特殊条件下,例如在周期性任务和内部系统事件的影响下,模型预测仍然准确有效。

C. 容量决策模型
最后,我们需要在模型估计的CPU利用率基础上,进一步给出每个服务所需的最合适的资源配置,这是自动化容量评估的最终目的。一个服务所需的资源与其CPU消耗的关系通常十分复杂,特别是当其CPU利用率接近某些临界水位时(性能衰减),为此我们提出了一个改进的DQN模型,该模型以一个基于目标CPU水平的专用损失函数进行优化,使我们能够快速找到最佳资源需求。
每个服务都与 DQN模型中的一个唯一ID相关联,这使得用一个共享模型对多个服务进行建模成为可能。对于DQN模型,我们从一下几个方面描述:


●Action Space:动作空间包括三种不同的操作:增加、减少和不变。
○增加: 此操作增加实例数,通过两种方式实现:按比例增加实例数(例如,5%)或按一定的数字(例如,10)增加实例数。
○减少: 此操作减少实例数。同样,它也通过两种方式实现:按比例减少实例数(例如,5%)或按一定数量减少实例数(例如,10)。
○不变: 此操作将保持服务的实例数不变。

4.模型效果
下面对三个模型的效果进行详细的分析:
4.1 流量预测模型
为了全面评估流量预测模型,我们训练了不同的模型,包括N-beats[11]和Transformer[16]。N-beats是一种最先进的预测模型,它是一种基于前向和后向残差连接以及非常深的全连接层的深度神经网络架构。Transformer是另一种流行的预测模型。图5展示了流量指标在不同预测模型的归一化平均绝对误差(MAE)和均方误差(RMSE)[5]。与N-beats和Transformer相比,DeepScaling将MAE降低了35.66%和25.26%,RMSE也分别降低了36.80%和28.51%。
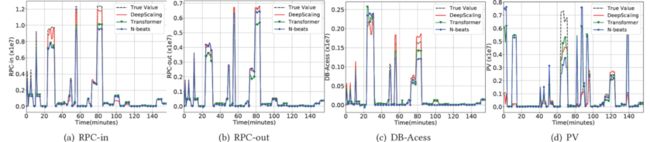
图5.不同流量预测模型的效果对比
4.2 CPU估计模型

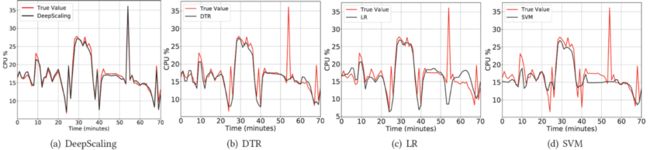
图6.不同CPU估计模型的效果对比
4.3 容量决策模型
我们将DeepScaling与其它三种SOTA方案进行了比较:Autopilot、FIRM和基于规则的方法。
●基于工作负载的自动缩放方法(Autopilot):谷歌的自动缩放方式,名为Autopilot[15],通过寻找与当前窗口最匹配的历史时间窗口来构建最佳资源配置。
●基于SLO的自动缩放方法(FIRM):FIRM[14]是一种基于RL的自动缩放方式,它通过异常检测算法查找具有异常响应时间(RT)的服务,并通过RL迭代调整服务资源。
●基于规则的自动缩放方法:它根据监控的性能指标并使用SRE专家经验制定的规则动态缩放微服务的实例数。


图7.DeepScaling与其他SOTA方法在两个典型微服务上
执行效果对比
对于服务A1,如图7(左)所示,基于规则的自动缩放方法无法准确估计服务所需的资源,这会导致每个周期的CPU利用率大幅波动。对于FIRM,CPU利用率在第二天超过70%,尽管此时目标水平设定为55%,SLO监控检测到异常响应时间。最终,FIRM的目标水位设置为50%,以保证它不会出现太多SLO违规。Autopilot的目标水位为80%,实现了62%的最大服务CPU利用率,即使在七天后也有很大的波动。此时,DeepScaling十分接近所需的SLO,将最终目标CPU利用率设置为65%。服务A2也存在类似情况,如图7(右)所示。FIRM的目标水位最终设定为42%。相比之下,DeepScaling在第三天达到了接近预期的SLO,最终目标水位设定为55%。Autopilot的目标水位设置为77%,但CPU利用率的最大值仅达到55%。
与其他业界公开方案相比,对于服务A1和服务A2,DeepScaling使服务运行更接近所需的SLO界限。

在这两个指标上,如图8所示,DeepScaling比业界SOTA方案(FIRM)分别领先了24.6%和14.0%。

图8.DeepScaling与其他SOTA方法的RCS 和 RRU
5.线上收益
对于蚂蚁自身,自2021年中投入使用,如图9所示,平均可产生3w core/day的CPU资源,6w GB/day的内存资源节省(1core/day=24core/hour = 1440core/mintue)。


图9.每天资源节省情况统计数据
6.总结和展望
目前业界公开的云服务自动缩放方法很难平衡最小化资源分配,同时避免RT异常和SLO违规,从而导致过度供应和资源浪费。为了克服这一挑战,我们开发了DeepScaling,这是一种基于深度学习的自动缩放方法,强调将CPU利用率稳定在期望的目标水位。DeepScaling由三个主要组件组成:流量预测模型、CPU估计模型和容量决策模型。我们使用目蚂蚁可观测性平台AntMonitor监控可采集的最全面的多维指标来描述微服务的负载。全面的工作负载特性帮助我们实现了准确的CPU利用率估计,以便DeepScaling实现稳定的容量决策。
另一方面,目前蚂蚁线上集群所部署的机型逐渐增多,各种机型间的性能差异对模型准确性的考验也越发严峻,未来我们将深入展开机型建模相关的探索,以求在进行自动化容量评估时,除了推荐期望的pod数目,能够更进一步实现所需机型配置的推荐,使线上服务的运行更为稳定高效。
以上,就是DeepScaling方法的主要内容。更多详细的内容和实验分析大家可以参考我们的论文,论文《DeepScaling: Microservices AutoScaling for Stable CPU Utilization in Large Scale Cloud Systems》[0] 已发表于ACM SoCC 2022,欢迎大家的批评指正。
致谢
感谢蚂蚁集团各合作团队,及重庆大学、加州大学河滨分校各位老师、教授在机制理论方面及学术化过程中提供的帮助。
参考文献
[0] ZiliangWang, Shiyi Zhu, Jianguo Li,Wei Jiang, K. K. Ramakrishnan,Yangfei Zheng, Meng Yan, Xiaohong Zhang, and Alex X Liu. 2022. DeepScaling: Microservices AutoScaling for Stable CPU Utilization in Large Scale Cloud Systems. In Proceedings of Proceedings of the 13th ACM Symposium on Cloud Computing (SoCC ’22).
[1] Muhammad Abdullah, Waheed Iqbal, Josep Lluis Berral, et al. 2020. Burst-aware predictive autoscaling for containerized microservices.IEEE Transactions on Services Computing (2020). [2] AWS. 2022. AWS auto scaling documentation. Retrieved June, 2022 from https://docs.aws.amazon.com/autoscaling/index.html
[3] Azure. 2022. Azure autoscale. Retrieved June, 2022 from https: //azure.microsoft.com/en-us/features/autoscale/
[4] Xiangping Bu, Jia Rao, and Cheng-Zhong Xu. 2009. A reinforcement learning approach to online web systems auto-configuration. In IEEE International Conference on Distributed Computing Systems (ICDCS). [5] Tianfeng Chai and Roland Draxler. 2014. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geoscientific model development 7, 3 (2014), 1247–1250.
[6] Jiang Dejun, Guillaume Pierre, and Chi-Hung Chi. 2011. Resource provisioning of web applications in heterogeneous clouds. In USENIX conference on Web application development.
[7] Google. 2022. Google cloud load balancing and scaling. Retrieved June, 2022 from https://cloud.google.com/compute/docs/loadbalancing-and-autoscaling.
[8] Waheed Iqbal, Mathew N Dailey, and David Carrera. 2015. Unsupervised learning of dynamic resource provisioning policies for cloudhosted multitier web applications. IEEE Systems Journal 10, 4 (2015), 1435–1446.
[9] Waheed Iqbal, Matthew N Dailey, David Carrera, et al. 2011. Adaptive resource provisioning for read intensive multi-tier applications in the cloud. Future Generation Computer Systems 27 (2011), 871–879. [10] Rafael Moreno-Vozmediano, Rubén S Montero, Eduardo Huedo, et al. 2019. Efficient resource provisioning for elastic Cloud services based on machine learning techniques. Journal of Cloud Computing 8,1 (2019), 1–18. [11] Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, et al. 2020. NBEATS: Neural basis expansion analysis for interpretable time series forecasting. In International Conference on Learning Representations (ICLR). [12] Sourav Panda, K. K. Ramakrishnan, and Laxmi N Bhuyan. 2021. pMACH: Power and Migration Aware Container scHeduling. In IEEE International Conference on Network Protocols (ICNP). 1–12. [13] Jinwoo Park, Byungkwon Choi, Chunghan Lee, et al. 2021. GRAF: a graph neural network based proactive resource allocation framework for SLO-oriented microservices. In International Conference on emerging Networking EXperiments and Technologies. 154–167. [14] Haoran Qiu, Subho S Banerjee, Saurabh Jha, et al. 2020. FIRM: An Intelligent Fine-grained Resource Management Framework for SLOOriented Microservices. In USENIX Symposium on Operating Systems Design and Implementation (OSDI). 805–825. [15] Krzysztof Rzadca, Pawel Findeisen, Jacek Swiderski, et al. 2020. Autopilot: workload autoscaling at Google. In European Conference on Computer Systems (EuroSys). 1–16. [16] Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. 2017. Attention is all you need. In Advances in neural information processing systems (NeurIPS). 5998–6008.
[17] Guangba Yu, Pengfei Chen, and Zibin Zheng. 2019. Microscaler: Automatic scaling for microservices with an online learning approach. In IEEE International Conference on Web Services (ICWS). 68–75.
[18] Liang Zhou, Laxmi N Bhuyan, and K. K. Ramakrishnan. 2019. Goldilocks: Adaptive resource provisioning in containerized data centers. In IEEE International Conference on Distributed Computing Systems (ICDCS).
[19] Liang Zhou, Laxmi N Bhuyan, and K. K. Ramakrishnan. 2020. Gemini: Learning to Manage CPU Power for Latency-Critical Search Engines. In IEEE/ACM International Symposium on Microarchitecture (MICRO).