机器学习之决策树:日撸Java三百行day61-62
一、什么是决策树
要了解决策树,先了解“决策”。决策(decision)是指决定的策略或办法,是为人们为各自事件出主意、做决定的过程。我们每天都在决策,如:今晚吃什么、明天穿什么。
了解了“决策”以后,再了解一下“树”。树(tree)是数据结构中的一种,是由 n n n个有限节点组成一个具有层次关系的集合。之所以称其为树,是因为它看起来像一棵倒挂的树。
了解好以上两个概念以后,理解决策树就非常容易了。决策树(decision tree)是一类常见的机器学习方法,是为基于树结构来进行决策的方法。以二分类问题为例,我们要对“今天是否适合出门打球?”这样的问题进行决策时,通常会进行一系列的判断或“子决策”:我们先看“今天天气如何?”,如果是晴天,则我们再看“今天温度如何?”;如果是雨天,则我们再看“今天风大吗?”。最后通过决策得出结果。
一棵决策树包含一个根结点、若干个内部结点和若干个叶结点;所有叶节点都对应一个决策结果,其他每一个结点则对应于一个属性测试。
同时,决策树使用了分治法来处理决策,是一个递归的过程。可以将一个大型决策划分为若干个“子决策”进行处理,最终将“子决策”合并,最终得出决策结果。
二、决策树基本思想
决策树生成算法的关键在于:确定当前数据使用哪个属性来分割,即:selectBestAttribute()。对于不同的算法,可能会选择不同的属性。
如何找到最佳的分割属性,就要通过判别哪个属性能够将数据划分的更“纯”一些。所谓的“纯”,就代表着划分出的一整块数据,它们的属性值一致,划分地更纯粹、更彻底。若划分出的一块数据除了一种属性值,还有其他的属性值,那么这块数据就“不纯”。
为了更好地划分出“纯”的数据块,我们就需要引入三个新的概念:信息增益、信息增益率、基尼指数。
·信息增益
在了解信息增益之前,先了解信息熵(information entropy)。信息熵是度量样本集合纯度最常用的一种指标。假定当前样本集合 D D D中第 k k k类样本所占比例为 p k ( k = 1 , 2 , . . . , ∣ Y ∣ ) p_{k}(k=1,2,...,|Y|) pk(k=1,2,...,∣Y∣),则 D D D的信息熵定义为:
E n t ( D ) = − ∑ k = 1 ∣ Y ∣ p k log 2 p k (1-1) Ent(D)=-\sum_{k=1}^{|Y|} p_{k}\log_{2}{p_{k}} \tag{1-1} Ent(D)=−k=1∑∣Y∣pklog2pk(1-1)
E n t ( D ) Ent(D) Ent(D)的值越小,则 D D D的纯度越高。反之,熵值越高,纯度越低,样本集合越不稳定。 E n t ( D ) Ent(D) Ent(D)的最小值为0,最大值为 l o g 2 ∣ Y ∣ log_{2}{|Y|} log2∣Y∣。
假设属性 a a a有 V V V个可能的取值 { a 1 , a 2 , a 3 , . . . , a V } \left \{ a^{1},a^{2},a^{3},...,a^{V} \right \} {a1,a2,a3,...,aV},若使用属性 a a a来对样本集 D D D进行划分,则会产生 V V V个分支结点,其中第 v v v个分支结点包含了 D D D中属性 a a a中所有取值为 a v a^{v} av的样本,记为 D v D^{v} Dv。根据公式(1-1)计算 D v D^{v} Dv的信息熵 E n t ( D v ) Ent(D^{v}) Ent(Dv)。考虑到不同的分支结点所包含的样本数不同,给分支结点赋予权重 ∣ D v ∣ / ∣ D ∣ |D^{v}|/|D| ∣Dv∣/∣D∣,即:样本数越多的分支结点影响越大。于是就可以计算出用属性 a a a对样本集 D D D进行划分所获得的信息增益(information gain)
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ E n t ( D v ) (1-2) Gain(D,a)=Ent(D)-\sum_{v=1}^{V}\frac{|D^{v}|}{|D|}Ent(D^{v}) \tag{1-2} Gain(D,a)=Ent(D)−v=1∑V∣D∣∣Dv∣Ent(Dv)(1-2)
信息增益越大,代表使用属性 a a a来对样本集进行划分获得的“纯度提升”越大。因此,我们利用信息增益来进行决策树的划分属性选择。
·信息增益率
信息增益更偏向于选择取值数目较多的属性,为了减少这种偏好对划分样本集带来不利影响,我们可以选择信息增益率(information entropy ratio)来选择最优属性。增益率定义为:
G a i n r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) (2-1) Gainratio(D,a)=\frac{Gain(D,a)}{IV(a)} \tag{2-1} Gainratio(D,a)=IV(a)Gain(D,a)(2-1)
其中, I V ( a ) IV(a) IV(a)定义为:
I V ( a ) = − ∑ v = 1 V ∣ D v ∣ ∣ D ∣ l o g 2 ∣ D v ∣ ∣ D ∣ (2-2) IV(a)=-\sum_{v=1}^{V}\frac{|D^{v}|}{|D|}log_{2}{\frac{|D^{v}|}{|D|} } \tag{2-2} IV(a)=−v=1∑V∣D∣∣Dv∣log2∣D∣∣Dv∣(2-2)
·基尼指数
除了以上两种方式,也可以通过计算属性的基尼指数(Gini index)来选择划分属性。样本集 D D D的纯度可用基尼值来度量。基尼指数定义为:
G i n i ( D ) = ∑ k = 1 ∣ Y ∣ ∑ k ′ ≠ k p k p k ′ = 1 − ∑ k = 1 ∣ Y ∣ p k 2 (3-1) Gini(D)=\sum_{k=1}^{|Y|}\sum_{{k}'≠k }^{}p_{k}p_{{k}'} =1-\sum_{k=1}^{|Y|}p_{k}^{2} \tag{3-1} Gini(D)=k=1∑∣Y∣k′=k∑pkpk′=1−k=1∑∣Y∣pk2(3-1)
基尼指数反映了从样本集 D D D中随机抽取两个样本标签不同的概率。因此, G i n i ( D ) Gini(D) Gini(D)越小,样本集 D D D的纯度越高。
样本集 D D D中属性 a a a的基尼指数定义为:
G i n i I n d e x ( D , a ) = ∑ v = 1 V ∣ D v ∣ ∣ D ∣ G i n i ( D v ) (3-2) GiniIndex(D,a)=\sum_{v=1}^{V} \frac{|D^{v}|}{|D|}Gini(D^{v}) \tag{3-2} GiniIndex(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)(3-2)
在样本集中,选择能够使基尼指数最小的属性作为最佳划分属性。
由于当数据较少、属性值较少时,信息增益选择的属性划分数据的效果最佳,因此本次实验也采用了信息增益的方式来选择最佳划分属性。找到第一个最佳划分属性之后,进行第一个决策。决策树是一个递归的处理过程,因此在本次决策结束以后,就继续之前的操作,在剩余属性中选择一个最佳划分属性进行决策,以此类推。为了便于理解,直接上图。

通过计算数据集的信息增益,获得第一个最佳划分属性Outlook,将数据划分为三个结点。
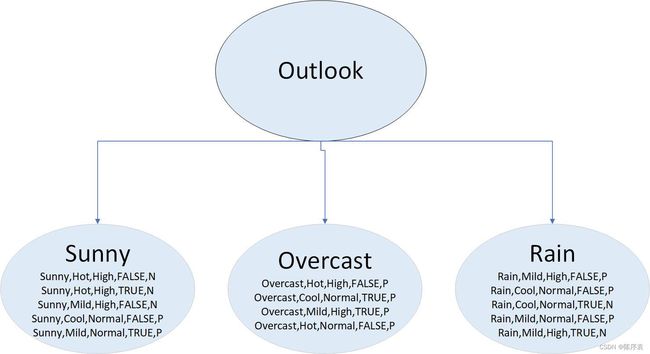
接着检查划分数据块的纯度,发现Outlook=Overcast的这块数据已经是纯的了,因此直接决策Play=P。其他两个属性还不是纯的,因此需要继续寻找最佳划分属性。此时就开始递归,Outlook=Sunny这块数据的最佳划分属性为Humidity,而Outlook=Rain的这块属性的最佳划分属性为Windy。
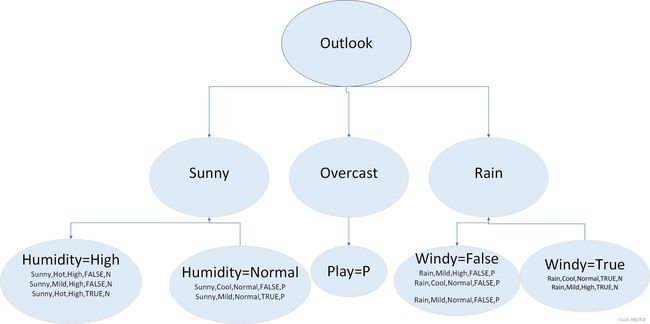
检查划分的数据块纯度,发现每一块都是纯的。由此可以得出最终决策结果。(Outlook=Sunny)∧(Humidity=High)=(Play=N);(Outlook=Sunny)∧(Humidity=Normal)=(Play=P);(Outlook=overcast)=(Play=P);(Outlook=Rain)∧(Windy=False)=(Play=P);(Outlook=Rain)∧(Windy=True)=(Play=N)。
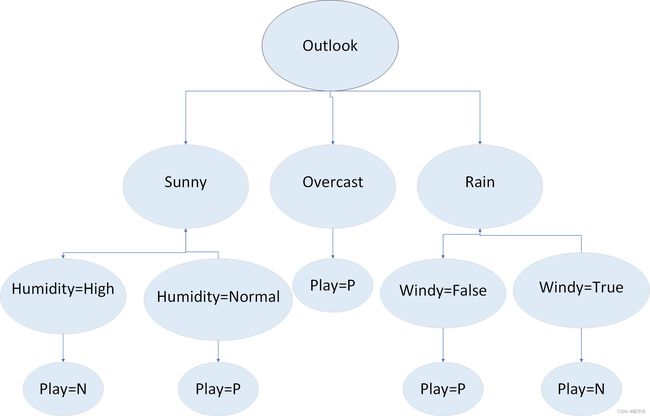
三、算法的基本流程及操作
数据集跟上面图示里的一致,也是weather.arff。下载地址在此。为了方便,依然贴出数据:
@relation weather
@attribute Outlook {Sunny, Overcast, Rain}
@attribute Temperature {Hot, Mild, Cool}
@attribute Humidity {High, Normal, Low}
@attribute Windy {FALSE, TRUE}
@attribute Play {N, P}
@data
Sunny,Hot,High,FALSE,N
Sunny,Hot,High,TRUE,N
Overcast,Hot,High,FALSE,P
Rain,Mild,High,FALSE,P
Rain,Cool,Normal,FALSE,P
Rain,Cool,Normal,TRUE,N
Overcast,Cool,Normal,TRUE,P
Sunny,Mild,High,FALSE,N
Sunny,Cool,Normal,FALSE,P
Rain,Mild,Normal,FALSE,P
Sunny,Mild,Normal,TRUE,P
Overcast,Mild,High,TRUE,P
Overcast,Hot,Normal,FALSE,P
Rain,Mild,High,TRUE,N
基本流程在上面的图示中已经阐述过了,在这里就直接贴出代码与注释。
①初始化全局变量,读取数据文件。
Instances dataset;//数据集
boolean pure;//纯度,指的是:是否全票通过
int numClasses;//分类类型数量
int[] avaiableInstances;//可用的实例,即一行行数据
int[] avaiableAttribute;//可用的属性,即一列列数据
int splitAttribute;//分割属性位置
ID3[] children;//决策树的孩子
int label;//标签
int[] predicts;//预测数组
static int smallBlockThreshold=3;//阈值
public ID3(String paraFilename) {
dataset=null;//设置数据集
try {
FileReader fileReader=new FileReader(paraFilename);//读取数据文件
dataset=new Instances(fileReader);//数据导入数据集中
fileReader.close();//关闭文件
}catch (Exception ee) {
System.out.println("Cannot read the file: " + paraFilename + "\r\n" + ee);
System.exit(0);
// TODO: handle exception
}
dataset.setClassIndex(dataset.numAttributes()-1);//设置要决策的属性,即最后一个:去不去打球
numClasses=dataset.classAttribute().numValues();//决策的属性个数,即:去、不去共两个
avaiableInstances=new int[dataset.numInstances()];//可用实例数量,即:数据集中数据条数
for(int i=0;i<avaiableInstances.length;i++) {
avaiableInstances[i]=i;//存入数组中
}
avaiableAttribute=new int[dataset.numAttributes()-1];//可用属性个数,即:除了最后一个以外,其他的所有属性
for(int i=0;i<avaiableAttribute.length;i++) {
avaiableAttribute[i]=i;
}
//初始化
children=null;//孩子节点初始为空
label=getMajorityClass(avaiableInstances);//找出类型作为标签
pure=pureJudge(avaiableInstances);//判断纯度
}
public ID3(Instances paraDataset,int[] paraAvailableInstances,int[] paraAvailableAttributes) {//用于构建一个决策树结点,输入参数为:数据集、可用实例、可用属性
dataset=paraDataset;
avaiableInstances=paraAvailableInstances;
avaiableAttribute=paraAvailableAttributes;
//初始化
children=null;
//通过简单投票,选择标签
label=getMajorityClass(avaiableInstances);//从可用实例中找出最重要的属性进行决策
//检查其纯度
pure=pureJudge(avaiableInstances);
}
②通过计算条件属性的信息熵,寻找最佳划分属性。
public double conditionalEntropy(int paraAttribute) {
//第一步,初始化各种变量
int tempNumClasses=dataset.numClasses();//决策类型数量
int tempNumValues=dataset.attribute(paraAttribute).numValues();//决策值数量
int tempNumInstances=avaiableInstances.length;//可用实例数量
double[] tempValueCounts=new double[tempNumValues];//记录决策值
double[][] tempCountMatrix=new double[tempNumValues][tempNumClasses];//将实例用矩阵表示
int tempClass,tempValue;
for(int i=0;i<tempNumInstances;i++) {
tempClass=(int)dataset.instance(avaiableInstances[i]).classValue();//记录实例的类型
tempValue=(int)dataset.instance(avaiableInstances[i]).value(paraAttribute);//记录实例的属性值
tempValueCounts[tempValue]++;
tempCountMatrix[tempValue][tempClass]++;
}//of for i
//第二步
double resultEntropy=0;
double tempEntropy,tempFraction;
for(int i=0;i<tempNumValues;i++) {
if(tempValueCounts[i]==0) {
continue;//忽略
}
tempEntropy=0;
for(int j=0;j<tempNumClasses;j++) {
tempFraction=tempCountMatrix[i][j]/tempValueCounts[i];
if(tempFraction==0) {
continue;
}//of if
tempEntropy+=-tempFraction*Math.log(tempFraction);
}//of for j
resultEntropy+=tempValueCounts[i]/tempNumInstances*tempEntropy;
}
return resultEntropy;
}
public int getMajorityClass(int[] paraBlock) {//找到重要属性
int[] tempClassCounts=new int[dataset.numClasses()];
for(int i=0;i<paraBlock.length;i++) {
tempClassCounts[(int)dataset.instance(paraBlock[i]).classValue()]++;
}//of for i
int resultMajorityClass=-1;//暂存结果位置
int tempMaxCount=-1;//暂存结果值
for(int i=0;i<tempClassCounts.length;i++) {//依次寻找
if(tempMaxCount<tempClassCounts[i]) {//若找到更重要的
resultMajorityClass=i;//替换
tempMaxCount=tempClassCounts[i];//替换
}//of if
}//of for i
return resultMajorityClass;//返回
}
public int selectBestAttribute() {//找到最佳属性,并以此属性构建树或子树
//信息增益 = 信息熵 - 条件信息熵
//要找到最小的条件信息熵,才能得到最大的信息增益,并以此找到最佳属性进行处理
splitAttribute=-1;//划分位置初始化
double tempMinimalEntropy=10000;
double tempEntropy;
for(int i=0;i<avaiableAttribute.length;i++) {//将属性逐个判断
tempEntropy=conditionalEntropy(avaiableAttribute[i]);
if(tempMinimalEntropy>tempEntropy) {//若找到更小的条件信息熵
tempMinimalEntropy=tempEntropy;//替换
splitAttribute=i;//更新划分位置
}//of if
}//of for i
return splitAttribute;//返回划分位置
}
③利用选择的最佳划分属性,将数据集划分。
public int[][] splitData(int paraAttribute){//根据属性划分数据
// 如:将所有sunny整合在一起
// children[0]: [0, 1, 7, 8, 10]
// Sunny,Hot,High,FALSE,N
// Sunny,Hot,High,TRUE,N
// Sunny,Mild,High,FALSE,N
// Sunny,Cool,Normal,FALSE,P
// Sunny,Mild,Normal,TRUE,P
int tempNumValues=dataset.attribute(paraAttribute).numValues();
int[][] resultBlocks=new int[tempNumValues][];
int[] tempSizes=new int[tempNumValues];
//首先扫描每一块的大小
int tempValue;
for(int i=0;i<avaiableInstances.length;i++) {
tempValue=(int)dataset.instance(avaiableInstances[i]).value(paraAttribute);//取出第i个实例的属性值
tempSizes[tempValue]++;//该值的数组值+1
}//of for i
//然后分配空间
for(int i=0;i<tempNumValues;i++) {
resultBlocks[i]=new int[tempSizes[i]];
}
//扫描,并填充
Arrays.fill(tempSizes, 0);//以0将数组tempSize填充
for(int i=0;i<avaiableInstances.length;i++) {
tempValue=(int)dataset.instance(avaiableInstances[i]).value(paraAttribute);
//复制数据
resultBlocks[tempValue][tempSizes[tempValue]]=avaiableInstances[i];
tempSizes[tempValue]++;
}//of for i
return resultBlocks;
}
④判断划分后的数据集的纯度。
public boolean pureJudge(int[] paraBlock) {
pure=true;
for(int i=1;i<paraBlock.length;i++) {
if(dataset.instance(paraBlock[i]).classValue()!=dataset.instance(paraBlock[0]).classValue()) {//只要有一个属性值与第一个不同
pure=false;//不纯
break;//停止循环
}
}
return pure;
}
⑤构建子树。若该数据块是纯的,则不需要建立子树。否则,返回步骤②,进行递归操作。
public void buildTree() {
if(pureJudge(avaiableInstances)) {
return;//如果是纯的,就不需要建立子树
}
if(avaiableInstances.length<=smallBlockThreshold) {//若可用实例个数小于阈值
return;
}
selectBestAttribute();//找到最佳属性
int[][] tempSubBlocks=splitData(splitAttribute);//分割数据为几块
children=new ID3[tempSubBlocks.length];//初始化孩子节点
//依照属性创建
int[] tempRemainingAttributes=new int[avaiableAttribute.length-1];//除了最后一个决策属性以外,其他的都存入该属性数组中
for(int i=0;i<avaiableAttribute.length;i++) {
if(avaiableAttribute[i]<splitAttribute) {//小于在左边
tempRemainingAttributes[i]=avaiableAttribute[i];
}
else if(avaiableAttribute[i]>splitAttribute) {//大于在右边
tempRemainingAttributes[i-1]=avaiableAttribute[i];
}//of if
}//of for i
//创建孩子
for(int i=0;i<children.length;i++) {
if((tempSubBlocks[i]==null)||(tempSubBlocks[i].length==0)) {//当子块为空时
children[i]=null;
continue;
//孩子也为空
}
else {
children[i]=new ID3(dataset,tempSubBlocks[i],tempRemainingAttributes);//创建孩子节点
children[i].buildTree();//递归,孩子也创建其孩子节点
}//of if
}//of for i
}//of buildTree
⑥通过递归,对决策树中结点信息处理,进行决策。
public int classify(Instance paraInstance) {//分类预测方法
if(children==null) {
return label;//孩子为空,返回标签
}
ID3 tempChild=children[(int)paraInstance.value(splitAttribute)];//获取孩子
if(tempChild==null) {//若孩子为空
return label;//返回
}
return tempChild.classify(paraInstance);//递归,预测孩子
}
⑦定义一个字符串输出方法,用于输出决策结果。
public String toString() {//以字符串形式输出
String resultString="";
String tempAttributeName=dataset.attribute(splitAttribute).name();
if(children==null) {//没有孩子,无法决策
resultString+="class = "+label;//直接返回
}else {
for(int i=0;i<children.length;i++) {//每个孩子进行输出
if(children[i]==null) {
resultString+=tempAttributeName + " = " + dataset.attribute(splitAttribute).value(i) + ": " + "class = " + label +"\r\n";
}else {
resultString+=tempAttributeName + " = " + dataset.attribute(splitAttribute).value(i) + ": " + children[i] + "\r\n";
}
}//of for i
}//of else
return resultString;
}
⑧浅测一下。
public double test(Instances paraDataset) {
double tempCorrect=0;
for(int i=0;i<paraDataset.numInstances();i++) {
if(classify(paraDataset.instance(i))==(int)paraDataset.instance(i).classValue()) {//若预测成功
tempCorrect++;
}//of if
}//of for i
return tempCorrect/paraDataset.numInstances();//返回预测精度
}
public double selfTest() {//自我测试函数
return test(dataset);
}
public static void id3Test() {
ID3 tempID3=new ID3("C:/Users/11989/Desktop/sampledata-main/sampledata-main/weather.arff");//新建测试集,并读取数据
ID3.smallBlockThreshold=3;//阈值设置为3
tempID3.buildTree();//构造决策树
System.out.println("The tree is:\r\n" + tempID3);
double tempAccuracy=tempID3.selfTest();//浅测一下
System.out.println("The accuray is: " + tempAccuracy);//输出预测精度
}
public static void main(String args[]) {
id3Test();
}
四、一些问题
1、决策树的优缺点?
决策树原理简单,易于理解。且几乎不需要数据预处理。不仅能够处理二分类问题,也可以处理多分类问题,不过需要一些特殊处理。
但同时,决策树也有一些缺点。如:当数据出现差错或特殊数据等情况时,会产生一棵完全不同的树。
2、信息增益、信息增益率、基尼指数分别在哪些情况下使用呢?
信息增益在面对类别较少、数据较离散的情况下效果较好,如本文所使用的天气数据。但是属性值取值较多、数据量较多的情况时效果不尽人意。这时就可以使用信息增益率,来减少信息增益对取值数目较多属性的偏好所带来的影响。当数据集较整齐,可以使用基尼指数来选择一个最佳划分属性。当数据集数据越混乱,基尼指数对这种混乱的体现越不充分,此时我们就可以使用信息增益了。