机器学习之卷积神经网络:日撸Java三百行day71-80
1、什么是卷积神经网络
在神经网络那一篇中,对ANN有了初步的了解。本文介绍的是卷积神经网络(Convolutional Neural Networks, CNN),这是深度学习(deep learning)的代表算法之一,是一类包含卷积计算且具有深度结构的前馈神经网络,该算法在图像领域取得了非常好的实际效果。在神经网络的文章中已经介绍过了何为前馈神经网络,但我们有必要了解一下“深度学习”与“卷积”。
·深度学习
人们常常将机器学习与深度学习拿来对比。本质上,如果将两种学习视为集合的话,那么深度学习就是机器学习的子集。机器学习的概念我们已经很熟悉了,就是让计算机算法从数据中找到信息、学习规律。
深度学习是机器学习的一种,是为了缓解训练低效性、降低过拟合风险等问题的一种解决方案。深度学习模型一般较为复杂,典型的深度学习模型就是很深层的神经网络。
对于神经网络模型,可以通过增加隐含层数目来提高“容量”(capacity)。容量越大,神经网络也就能够完成越复杂的学习任务。
深度学习就是通过多隐层堆叠、每层对上一层的输出进行处理的机制,来对输入信号进行逐层加工,从而把初始的、与输出目标之间联系不太密切的输入表示转换成与输出目标联系更加密切的表示。
·卷积
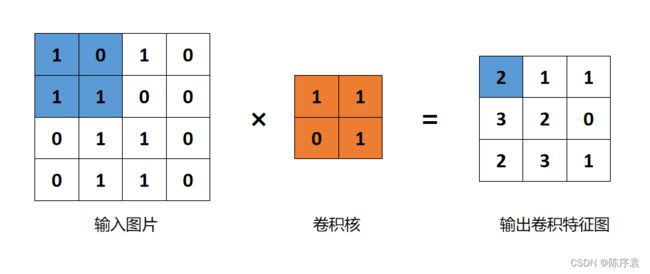
卷积(Convolution)的本质:加权叠加,我们可以将它视为“滤镜”。卷积公式为 ∫ − ∞ + ∞ f ( τ ) g ( x − τ ) d τ \int_{-\infty }^{+\infty} f(\tau )g(x-\tau )d\tau ∫−∞+∞f(τ)g(x−τ)dτ。其中, f ( x ) f(x) f(x)就是输入图片, g ( x ) g(x) g(x)称为作用点。所有作用点合起来我们称为卷积核(Convolution kernel),就像“滤镜”一样。
通过这个“滤镜”,将原图的图片的每一个部分都滤一遍,并且线性叠加结果称为输出结果。卷积核上所有作用点依次作用于原始像素点,输出卷积结果。
2、卷积神经网络算法思想
卷积神经网络复合了多个“卷积层”和“池化层”对输入图片进行加工,然后再连接层实现与输出目标之间的映射。这两层都离不开同一个操作:“特征提取”。
·卷积层
卷积层(Convolution layer)是负责提取图片中的局部特征,即:过滤。每个卷积层都包含多个特征映射(feature map),每个特征映射是一个由多个神经元构成的“平面”,通过卷积“滤镜”提取输入的特征。将“滤镜”扫描图像的每一个小区域,从而得到各个小区域的特征值。最终,将每个区域的特征值分布在各自区域,输出卷积结果。随着卷积操作的不断进行,从局部特征过渡到全局特征。
例如:图像数据通过RGB形式进行处理,大小为 28 ∗ 28 ∗ 1 28*28*1 28∗28∗1,通过 5 ∗ 5 5*5 5∗5的卷积核处理之后,得到的特征图像为 24 ∗ 24 ∗ 1 24*24*1 24∗24∗1。将上一层输出的结果交给下一个卷积层进行处理,也就得到了 20 ∗ 20 ∗ 1 20*20*1 20∗20∗1的特征图像。
·池化层
池化层(Pooling layer)是来大幅降低参数量级,即:降维。 如输入为 1000 ∗ 1000 1000*1000 1000∗1000,每次每个卷积层都用 5 ∗ 5 5*5 5∗5进行卷积,那么每次只能让图片的size减去 4 4 4,速度过慢。因此就需要池化来进行数据降维。池化就是对图像进行采样,常见的采样方式有:上、下、平均采样。其作用是基于局部相关性原理进行采样,从而在减少数据量的同时保留有用信息。
例如:RGB图像规模为 28 ∗ 28 ∗ 1 28*28*1 28∗28∗1,通过池化后得到的图像规模为 14 ∗ 14 ∗ 1 14*14*1 14∗14∗1。

通过以上两层的处理后,最终将数据输入到全连接层,得到最终的结果。其中,只有这两层的处理与神经网络有些不同,其他的都是类似的。
深度学习,就是要够“深”,因此CNN是多层结构,应用于数据量大的情景中。因此这些大量的数据只有通过中间多层的卷积层与池化层降维后,在全连接层才能“跑起来”。
卷积神经网络终归也是神经网络,因此也是通过forward来进行预测与、backPropagation进行惩罚信息更新。正向与反向传播过程与BP神经网络的操作类似,区别也只是在于数据集合的形式不同。
三、算法的基本流程及操作
3.1、数据集读取与存储
该类主要负责读取数据文件生成实例集、获取实例、获取属性、获取标签。
package machinelearning.cnn;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import weka.core.Instance;
public class Dataset {
private List<Instance> instances;//将实例存于一个列表中
private int labelIndex;//标签索引
private double maxLabel=-1;//用于存储票数最多的标签索引号
public Dataset() {
labelIndex=-1;//初始化标签索引
instances = new ArrayList<Instance>();//初始化实例空间
}
public Dataset(String paraFilename, String paraSplitSign, int paraLabelIndex) {
instances=new ArrayList<Instance>();//初始化实例
labelIndex=paraLabelIndex;//初始化标签索引
File tempFile=new File(paraFilename);//读取数据文件
try {
BufferedReader tempReader= new BufferedReader(new FileReader(tempFile));//读取
String tempLine;
while((tempLine=tempReader.readLine())!=null) {
String[] tempDatum=tempLine.split(paraSplitSign);
if(tempDatum.length==0) {
continue;
}
double[] tempData=new double[tempDatum.length];
for(int i=0;i<tempDatum.length;i++) {
tempData[i]=Double.parseDouble(tempDatum[i]);
}
Instance tempInstance = new Instance(tempData);
append(tempInstance);//将该实例加在实例列表后
}
}catch (Exception e) {//读取失败
e.printStackTrace();
System.out.println("Unable to load " + paraFilename);
System.exit(0);
// TODO: handle exception
}
}
public void append(Instance paraInstance) {
instances.add(paraInstance);//将新的实例加在实例列表后
}
public void append(double[] paraAttributes, Double paraLabel) {
instances.add(new Instance(paraAttributes,paraLabel));
}
public Instance getInstance(int paraIndex) {
return instances.get(paraIndex);//获取索引指定的实例
}
public int size() {
return instances.size();//返回实例的大小
}
public double[] getAttributes(int paraIndex) {
return instances.get(paraIndex).getAttributes();//获取索引指定实例的属性
}
public Double getLabel(int paraIndex) {
return instances.get(paraIndex).getLabel();//获取索引指定实例的标签
}
public static void main(String args[]) {
Dataset tempData=new Dataset("",",",784);//读取数据文件,以,分割开
Instance tempInstance = tempData.getInstance(0);//用于临时存储实例,此时读取第1个实例
System.out.println("The first Instance is: " + tempInstance);//输出第一个实例
}
public class Instance{
private double[] attributes;//存储属性
private Double label;//存储标签
private Instance(double[] paraAttrs, Double paraLabel) {
attributes=paraAttrs;//初始化属性
label=paraLabel;//初始化标签
}
public Instance(double[] paraData) {
if(labelIndex==-1) {//若没有标签
attributes=paraData;
}
else {
label=paraData[labelIndex];//读取索引指定数据作为标签
if(label>maxLabel) {//若该标签超出最大标签
maxLabel=label;//将该标签作为最大标签
}//of if
if(labelIndex==0) {
attributes=Arrays.copyOfRange(paraData, 1, paraData.length);
}else {
attributes=Arrays.copyOfRange(paraData, 0, paraData.length-1);
}
}
}
public double[] getAttributes() {
return attributes;//返回属性
}
public Double getLabel() {
if(labelIndex==-1) {//若标签索引非法
return null;
}
return label;
}
public String toString() {
return Arrays.toString(attributes) + ", " + label;
}
}
}
3.2、管理卷积核尺寸
主要是对数据规模进行除或减操作,将尺寸缩小。
package machinelearning.cnn;
import javax.management.RuntimeErrorException;
public class Size {
public final int width;
public final int height;
public Size(int paraWidth, int paraHeight) {
width=paraWidth;//初始化宽度
height=paraHeight;//初始化高度
}
//除操作:(4,12)/(2,3)=(2,4)
public Size divide(Size paraScaleSize) {
int resultWidth = width / paraScaleSize.width;//计算获得最终宽度
int resultHeight= height / paraScaleSize.height;//计算获得最终高度
if(resultWidth * paraScaleSize.width != width || resultHeight * paraScaleSize.height != height)//如果除操作后,乘回去对不上
throw new RuntimeException("Unable to divide" + this + " with " + paraScaleSize);
return new Size(resultWidth,resultHeight);//重新返回新的size
}
public Size subtract(Size paraScaleSize, int paraAppend) {
int resultWidth= width - paraScaleSize.width + paraAppend;
int resultHeight = height - paraScaleSize.height + paraAppend;
return new Size(resultWidth, resultHeight);//重新返回新的size
}
public String toString() {
String resultString = "( " + width + ", " + height + ")";//以字符串形式输出size
return resultString;//返回
}
public static void main(String[] args) {
Size tempSize1 = new Size(4, 6);
Size tempSize2 = new Size(2, 2);
System.out.println(
"" + tempSize1 +" divide " + tempSize2 + " = " + tempSize1.divide(tempSize2));//输出size1除以size2后的结果
System.out.println("a");
try {
System.out.println(
"" + tempSize2 +" divide " + tempSize1 + " = " + tempSize2.divide(tempSize1));//输出size2除以size1后的结果
}catch (Exception ee) {
System.out.print(ee);
// TODO: handle exception
}
System.out.println(
"" + tempSize1 + " - " + tempSize2 +" + 1 = " + tempSize1.subtract(tempSize2, 1));
}
}
3.3、MathUtils数学操作
主要内容为矩阵操作。其中,one_value操作是为了获得 1 − A 1-A 1−A这种矩阵;sigmoid操作是与BP神经网络中作用类似,将数据映射到(0,1)区间内;OperatorOnTwo_plus、OperatorOnTwo_multiply、OperatorOnTwo_minus操作分别是为了将两个矩阵相加、相乘与相减;
package machinelearning.cnn;
import java.io.Serializable;
import java.rmi.server.Operation;
import java.util.Arrays;
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.PrimitiveIterator.OfDouble;
public class MathUtils {
public interface Operator extends Serializable{
public double process(double value);
}//接口
public static final Operator one_value = new Operator() {
private static final long serialVersionUID = 3752139491940330714L;
@Override
public double process(double value) {
return 1-value;
}//of process
};//1-A
public static final Operator sigmoid = new Operator() {
private static final long serialVersionUID=-1952718905019847589L;
@Override
public double process(double value) {
return 1/(1+Math.pow(Math.E, -value));
}
};//S型函数
interface OperatorOnTwo extends Serializable{
public double process(double a, double b);
}
public static final OperatorOnTwo plus = new OperatorOnTwo() {
private static final long serialVersionUID= -6298144029766839945L;
@Override
public double process(double a, double b) {
return a+b;
}
};//相加
public static OperatorOnTwo multiply = new OperatorOnTwo() {
private static final long serialVersionUID=-7053767821858820698L;
@Override
public double process(double a, double b) {
return a*b;
}
};//相乘
public static OperatorOnTwo minus = new OperatorOnTwo() {
private static final long serialVersionUID=7346065545555093912L;
@Override
public double process(double a, double b) {
return a-b;
}
};//相减
此外,rot180操作是将矩阵进行翻转180度。该操作是反向传播是需要的一个步骤。反池化传播是需要将矩阵反转,因此需要进行两次翻转180度。
public static double[][] rot180(double[][] matrix){
matrix = cloneMatrix(matrix);
int m=matrix.length;//长度
int n=matrix[0].length;//宽度
for(int i=0;i<m;i++) {
for(int j=0;j<n/2;j++) {
double tmp=matrix[i][j];
matrix[i][j]=matrix[i][n-1-j];
matrix[i][n-1-j]=tmp;
}
}
for(int j=0;j<n;j++) {
for(int i=0;i<m/2;i++) {
double tmp=matrix[i][j];
matrix[i][j]=matrix[m-1-i][j];
matrix[m-1-i][j]=tmp;
}
}
return matrix;
}
随机初始化矩阵以及矩阵克隆。
private static Random myRandom=new Random(2);
public static double[][] cloneMatrix(final double[][] matrix){
final int m=matrix.length;//长度
int n=matrix[0].length;//宽度
final double[][] outMatrix = new double[m][n];
for(int i=0;i<m;i++) {
for(int j=0;j<n;j++) {
outMatrix[i][j]=matrix[i][j];
}//of for j
}//of for i
return outMatrix;
}