极客时间&马哥教育-云原生训练营第一周作业-20221016
一、本课知识点和技能点
1、了解namespace技术,并学习常见的namespace技术的分类和作用
2、二进制方式安装docker
3、熟悉使用docker数据卷
4、熟悉使用docker几种网络模式
5、了解docker的架构,熟悉使用常用的docker命令(补充作业)
6、了解什么是容器(补充作业)
7、理解什么是镜像(补充作业)
8、了解什么是运行时(补充作业)
9、了解docker存储引擎(补充作业)
二、namespace技术的分类和作用
我们了解了docker可以提供一个隔离环境,同时可以运用namespace、cgroups、chroot技术实现资源隔离和资源限制,那具体资源隔离是怎么实现的呢,包括哪些namepace呢,以及他们分别是什么作用
1、常见的namespace分类
容器技术是在一个进程内实现运行指定服务的运行环境,并且还可以保护宿主机内核不受其他进程的干扰和影响,如文件系统空间、网络空间、进程空间等,那是怎么实现的呢,主要是通过namespace技术实现的,目前namespace主要包括以下几种

注:前6中比较常用
2、namepace技术的实现

3、MNT Namespace
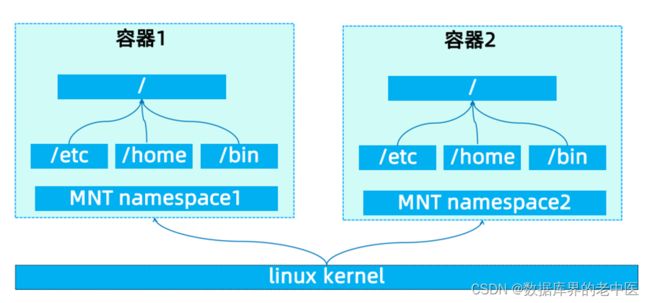
- 作用:提供磁盘挂载点和文件系统的隔离
- 每个容器都要有独立的根文件系统有独立的用户空间,以实现在容器里面启动服务并且使用容器的运行环境,即一个宿主机是ubuntu的服务器,可以在里面启动一个centos运行环境的容器并且在容器里面启动一个Nginx服务,此Nginx运行时使用的运行环境就是centos系统目录的运行环境,即在容器里面是不能直接访问宿主机的文件系统。(提供文件系统的隔离)
- 宿主机是使用了chroot技术把容器锁定到一个指定的运行目录里面并作为容器的根运行环境(这个使用chroot技术把容器锁定到一个指定的运行目录里面并作为容器的根运行环境提供磁盘挂载点)
4、IPC Namespace

- 作用提供进程间通信的隔离
- IPC namespce隔离进程间通信资源(同一个IPC namespace的进程可实现内存等资源共享,但是不同的IPC namespace则严格隔离)
5、UTS Namespace

- 作用:提供主机名隔离
- UTS namespace(UNIXTimesharing System包含了运行内核的名称、版本、底层体系结构类型等信息)用于系统标识,其中包含了hostname 和域名domainname ,它使得一个容器拥有属于自己hostname标识,这个主机名标识独立于宿主机系统和其上的其他容器。
6、PID Namespace

- 作用:提供进程隔离
- 每一个容器都类似于虚拟机一样有自己的网卡、监听端口、TCP/IP协议栈等,docker使用network namespace启动一个vethX接口,这样你的容器将拥有它自己的桥接ip地址,通常是docker0,而docker0实质就是Linux的虚拟网桥,网桥是在OSI七层模型的数据链路层的网络设备,通过mac地址对网络进行划分,并且在不同网络直接传递数据。
7、User Namespace

- 提供用户隔离
- 各个容器内可能会出现重名的用户和用户组名称,或重复的用户UID或者GID,那么怎么隔离各个容器内的用户空间呢?
- User Namespace允许在各个宿主机的各个容器空间内创建相同的用户名以及相同的用户UID和GID,只是会把用户的作用范围限制在每个容器内,即A容器和B容器可以有相同的用户名称和ID的账户,但是此用户的有效范围仅是当前容器内,不能访问另外一个容器内的文件系统,即相互隔离、互不影响
二、ubuntu 22.04.01二进制方式安装docker
1、下载软件并解压
mkdir /soft
tar xvf docker-20.10.16.tgz
cp /soft/docker/* /usr/bin



2、创建systemd unit文件
1)docker.service
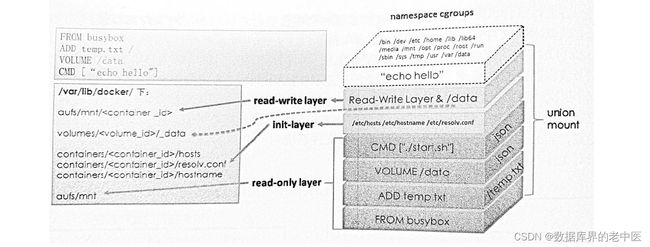
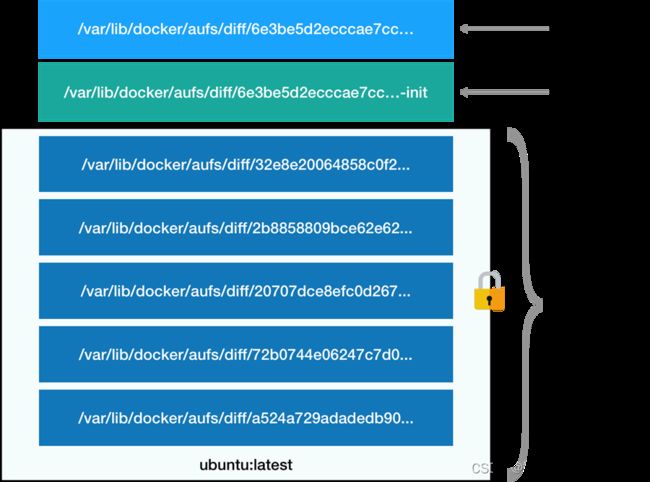
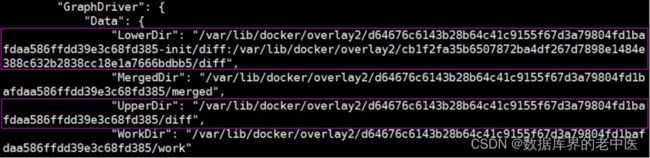
cat > /usr/lib/systemd/system/docker.service < [Unit] Description=Docker Application Container Engine Documentation=https://docs.docker.com After=network-online.target docker.socket firewalld.service containerd.service Wants=network-online.target Requires=docker.socket containerd.service [Service] Type=notify # the default is not to use systemd for cgroups because the delegate issues still # exists and systemd currently does not support the cgroup feature set required # for containers run by docker ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock ExecReload=/bin/kill -s HUP $MAINPID TimeoutSec=0 RestartSec=2 Restart=always # Note that StartLimit* options were moved from "Service" to "Unit" in systemd 229. # Both the old, and new location are accepted by systemd 229 and up, so using the old location # to make them work for either version of systemd. StartLimitBurst=3 # Note that StartLimitInterval was renamed to StartLimitIntervalSec in systemd 230. # Both the old, and new name are accepted by systemd 230 and up, so using the old name to make # this option work for either version of systemd. StartLimitInterval=60s # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNOFILE=infinity LimitNPROC=infinity LimitCORE=infinity # Comment TasksMax if your systemd version does not support it. # Only systemd 226 and above support this option. TasksMax=infinity # set delegate yes so that systemd does not reset the cgroups of docker containers Delegate=yes # kill only the docker process, not all processes in the cgroup KillMode=process OOMScoreAdjust=-500 [Install] WantedBy=multi-user.target EOF cat >/usr/lib/systemd/system/docker.socket < [Unit] Description=Docker Socket for the API [Socket] ListenStream=/var/run/docker.sock SocketMode=0660 SocketUser=root SocketGroup=docker [Install] WantedBy=sockets.target EOF cat > /usr/lib/systemd/system/containerd.service < [Unit] Description=containerd container runtime Documentation=https://containerd.io After=network.target local-fs.target [Service] ExecStartPre=-/sbin/modprobe overlay ExecStart=/usr/bin/containerd Type=notify Delegate=yes KillMode=process Restart=always RestartSec=5 # Having non-zero Limit*s causes performance problems due to accounting overhead # in the kernel. We recommend using cgroups to do container-local accounting. LimitNPROC=infinity LimitCORE=infinity LimitNOFILE=infinity # Comment TasksMax if your systemd version does not supports it. # Only systemd 226 and above support this version. TasksMax=infinity OOMScoreAdjust=-999 [Install] WantedBy=multi-user.target EOF groupadd docker #添加docker组,否则docker.socket启动会报错 systemctl start containerd.service && systemctl enable containerd.service systemctl start docker.socket && systemctl enable docker.socket systemctl start docker.service && systemctl enable docker.service docker info #输出结果正常代表安装成功 如果正在运行中的容器,生成了新的数据或者修改了现有的一个已经存在的文件内容,那么新产生的数据将会被复制到读写层进行持久化保存,这个读写层也就是容器的工作目录,此即“写时复制(COW) copy on write”机制。 如下图是将对根的数据写入到了容器的可写层,但是把/data中的数据写入到了一个另外的volume中用于数据持久化 1) Lower Dir:image镜像层(镜像本身,只读) 2) Upper Dir:容器的上层(读写) 3) Merged Dir:容器的文件系统,使用Union FS(联合文件系统)将lowerdir和upper Dir:合并给容器使用。 4) Work Dir:容器在 宿主机的工作目录 Docker的镜像是分层设计的,镜像层是只读的,通过镜像启动的容器添加了一层可读写的文件系统,用户写入的数据都保存在这一层当中。 如果要将写入到容器的数据永久保存,则需要将容器中的数据保存到宿主机的指定目录,目前Docker的数据类型分为两种: //创建nginx-data卷 # docker volume create nginx-data //查看已创建的卷 # docker volume ls DRIVER VOLUME NAME local nginx-data //查看容器镜像 #docker images REPOSITORY TAG IMAGE ID CREATED SIZE nginx latest 5d58c024174d 41 hours ago 142MB busybox latest ff4a8eb070e1 2 weeks ago 1.24MB nginx 1.20.2 0584b370e957 5 months ago 141MB //后台方式运行容器 # docker run -it -d -p 80:80 -v nginx-data:/data nginx:1.20.2 // 进入到容器,并写入一些数据到/data/index.html文件中 # docker exec -it 2e0b6b1f753f bash root@2e0b6b1f753f:/# echo "nginx web" > /data/index.html root@2e0b6b1f753f:/# exit root@ubuntu01:/# cd /var/lib/docker/volumes/nginx-data/_data/ root@ubuntu01:/var/lib/docker/volumes/nginx-data/_data# pwd /var/lib/docker/volumes/nginx-data/_data root@ubuntu01:/var/lib/docker/volumes/nginx-data/_data# ls index.html root@ubuntu01:/var/lib/docker/volumes/nginx-data/_data# cat index.html nginx web root@ubuntu01:/var/lib/docker/volumes/nginx-data/_data# //删除容器,发现数据在宿主机目录还是存在的 root@ubuntu01:/# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2e0b6b1f753f nginx:1.20.2 "/docker-entrypoint.…" 9 minutes ago Up 9 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp upbeat_visvesvaraya root@ubuntu01:/# docker rm -f 2e0b6b1f753f 2e0b6b1f753f root@ubuntu01:/# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES root@ubuntu01:/# 以数据卷的方式,将自定义的宿主机目录或文件提供给容器使用,比如容器可以直接挂载宿主机本地的数据目录(如mysql容器的数据持久化)、配置文件(如nginx的配置文件)、静态文件(如web服务的图片或js文件)等,只需要在创建容器的时候指定挂载即可 //创建数据目录 # mkdir -p /data/testapp # echo "testapp web page" > /data/testapp/index.html # cat /data/testapp/index.html //数据卷方式运行容器 启动两个测试容器,web1容器和web2容器,分别测试能否访问到宿主机的数据,注意使用-v参数,将宿主机目录映射到容器内部,web2的ro表示在容器内对该目录只读,默认的权限是可读写的: //启动两个测试容器 # docker run -d --name web1 -v /data/testapp:/usr/share/nginx/html/testapp -p 80:80 nginx:1.20.2 # docker run -d --name web2 -v /data/testapp:/usr/share/nginx/html/testapp:ro -p 81:80 nginx:1.20.2 //进行访问测试 http://192.168.100.200:80/testapp/ http://192.168.100.200:81/testapp/ //外面追加数据后,再进行访问测试 root@ubuntu01:/# echo "v222" >> /data/testapp/index.html http://192.168.100.200:80/testapp/ http://192.168.100.200:81/testapp/ 容器里面修改数据后,再进行访问测试,可以发现一个容器的文件可以修改,一个不能修改 http://192.168.100.200:80/testapp/ http://192.168.100.200:81/testapp/ nginx多卷挂载: # mkdir -p /data/nginx/conf # docker cp web1:/etc/nginx/nginx.conf /data/nginx/conf/ //运行容器,并查看数据卷的内容 # docker run -d --name web3 -v /data/testapp:/usr/share/nginx/html/testapp -v /data/nginx/conf/nginx.conf:/etc/nginx/nginx.conf:ro nginx:1.20.2 # docker pull mysql:5.7.38 # docker run -it -d -p 3306:3306 -v /data/mysql:/var/lib/mysql -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7.38 1、Docker服务安装完成之后,默认在每个宿主机会生成一个名称为docker0的网卡其IP地址都是172.17.0.1/16,并且会生成三种不同类型的网络 2、创建的三个默认网络,用于不同的使用场景: root@docker-server1:~# docker network list NETWORK ID NAME DRIVER SCOPE 438a9be14ef8 bridge bridge local #桥接网络,默认使用的模式,容器基于SNAT进行地址转换访问宿主机以外的环境 4c026356e4d1 host host local #host网络,直接使用宿主机的网络( 不创建net namespace),性能最好,但是容器端口不能冲突 8d70da095b8e none null local #空网络,容器不会分配有效的IP地址(只有一个回环网卡用于内部通信),用于离线数据处理等场 1、docker的默认模式即不指定任何模式就是bridge模式,也是目前使用比较多的网络模式,此模式创建的容器会为每一个容器分配自己的网络IP等信息,并将容器连接到一个虚拟网桥与外界通信。 2、查看bridge网络的详细信息 # docker network inspect bridge 3、以bridge网络运行容器 # docker run -it -d --name nginx-web1-bridge-test-container -p 80:80 --net=bridge nginx:1.20.2 4、查看容器的网络映射信息,可以发现容器跟外界通信是通过iptables转发的 #iptables -t nat -vnL 1、host模式就是直接使用宿主机的IP地址,创建的容器如果指定了使用host模式,那么新创建的容器不会创建自己的虚拟网卡,而是直接使用宿主机的网卡和IP地址,因此在容器里面查看到的IP信息就是宿主机的信息,访问容器的时候直接使用宿主机IP+容器端口即可,而且某一个端口一旦被其中一个容器占用那么其它容器就不能再监听此端口,不过容器的其它资源比如容器的文件系统、容器系统进程等还是基于namespace相互隔离 2、此模式的网络性能最高,但是各容器之间端口不能相同,适用于运行容器端口比较固定的业务。 3、host网络模式实验 # docker run -it -d --name nginx-web2-host-test-container --net=host nginx:1.20.2 root@docker-server1:~# docker exec -it 77a4e1ca90fa bash root@docker-server1:/# apt update && apt install net-tools root@docker-server1:/# ifconfig root@docker-server1:/# netstat -tanlp 1、none模式就是无IP模式,在使用none 模式后,docker 容器不会进行任何网络配置,其没有网卡、没有IP也没有路由,因此默认无法与外界通信,需要手动添加网卡配置IP等,所以极少使用 2、docker-none网络模式实验 # docker run -it -d --name nginx-web1-none-test-container -p 91:80 --net=none busybox sleep 10000000 # docker exec -it 3c54e90c209a sh 1、Container模式即容器模式,使用参数 --net=container:目标容器名称/ID 指定,使用此模式创建的容器需指定和一个已经存在的容器共享一个网络namespace,而不会创建独立的namespace,即新创建的容器不会创建自己的网卡也不会配置自己的IP,而是和一个已经存在的被指定的目标容器共享对方的IP和端口范围,因此这个容器的端口不能和被指定的目标容器端口冲突,除了网络之外的文件系统、用户信息、进程信息等仍然保持相互隔离,两个容器的进程可以通过lo网卡及容器IP进行通信 2、container模式实验,可以看到container模式,不同的容器用的同一个namespace # docker run -it -d --name nginx-container -p 100:80 --net=bridge nginx:1.22.0-alpine # docker run -it -d --name php-container --net=container:nginx-container php:7.4.30-fpm-alpine 验证net namesapce: # ls /var/run/netns/netns # ln -s /var/run/docker/netns/* /var/run/netns/ # ip netns list default # ip netns exec a9a81e7bc743 ip a Docker Engine 是典型的客户端 / 服务器(C/S)架构,命令行工具 Docker 直接面对用户,后面的 Docker daemon 和 Registry 协作完成各种功能 所以,在 Docker Engine 里,真正干活的其实是默默运行在后台的 Docker daemon,而我们实际操作的命令行工具“docker”只是个“传声筒”的角色。 docker build | Docker Documentationdocker build | Docker Documentationdocker build: The `docker build` command builds Docker images from a Dockerfile and a "context". A build's context is the set of files located in the specified `PATH` or `URL`.... 1、从字面上来看,容器就是 Container,一般把它形象地比喻成现实世界里的集装箱,它也正好和 Docker 的现实含义相对应,因为码头工人(那只可爱的小鲸鱼)就是不停地在搬运集装箱。 2、容器,就是一个特殊的隔离环境,它能够让进程只看到这个环境里的有限信息,不能对外界环境施加影响。通俗讲容器提供一个隔离环境 3、容器技术的另一个本领就是为应用程序加上资源隔离,在系统里切分出一部分资源,让它只能使用指定的配额。容器技术另外一个作用就是资源隔离和资源限制,资源隔离是通过namespace技术实现的,资源限制是通过cgroup技术实现的 4、容器,提供一个系统中被隔离的特殊环境,进程可以在其中不受干扰地运行。描述再简化一点:容器就是被隔离的进程。 1、从实现的角度来看,虚拟机虚拟化出来的是硬件,需要在上面再安装一个操作系统后才能够运行应用程序,而硬件虚拟化和操作系统都比较“重”,会消耗大量的 CPU、内存、硬盘等系统资源,但这些消耗其实并没有带来什么价值,属于“重复劳动”和“无用功”,不过好处就是隔离程度非常高,每个虚拟机之间可以做到完全无干扰。 2、容器(即图中的 Docker),它直接利用了下层的计算机硬件和操作系统,因为比虚拟机少了一层,所以自然就会节约 CPU 和内存,显得非常轻量级,能够更高效地利用硬件资源。不过,因为多个容器共用操作系统内核,应用程序的隔离程度就没有虚拟机那么高了。 3、容器vs虚拟机 1、镜像就是把运行进程所需要的文件系统、依赖库、环境变量、启动参数等所有信息打包整合到了一起。之后镜像文件无论放在哪里,操作系统都能根据这个镜像快速重建容器,应用程序看到的就会是一致的运行环境了。 2、理解了镜像,再看看docker pull命令和docker run命令 1) docker pull busybox ,就是获取了一个打包了 busybox 应用的镜像,里面固化了 busybox 程序和它所需的完整运行环境。 2) docker run busybox echo hello world ,就是提取镜像里的各种信息,运用 namespace、cgroup、chroot 技术创建出隔离环境,然后再运行 busybox 的 echo 命令,输出 hello world 的字符串。 这两个步骤,由于是基于标准的 Linux 系统调用和只读的镜像文件,所以,无论是在哪种操作系统上,或者是使用哪种容器实现技术,都会得到完全一致的结果。 3、所谓的“容器化的应用”,或者“应用的容器化”,就是指应用程序不再直接和操作系统打交道,而是封装成镜像,再交给容器环境去运行。 4、镜像就是静态的应用容器,容器就是动态的应用镜像,两者互相依存,互相转化,密不可分。 5、镜像的完整名字由两个部分组成,名字和标签,中间用 : 连接起来。 6、docker images 1)“latest”,它是默认的标签,如果只提供名字没有附带标签,那么就会使用这个默认的“latest”标签。 2)“IMAGE ID” 镜像唯一的标识,就好像是身份证号一样。比如这里我们可以用“ubuntu:jammy”来表示 Ubuntu 22.04 镜像,同样也可以用它的 ID“d4c2c……”来表示。 3)截图里的两个镜像“nginx:1.21-alpine”和“nginx:alpine”的 IMAGE ID 是一样的,都是“a63aa……”。这其实也很好理解,这就像是人的身份证号码是唯一的,但可以有大名、小名、昵称、绰号,同一个镜像也可以打上不同的标签,这样应用在不同的场合就更容易理解 4)IMAGE ID 还有一个好处,因为它是十六进制形式且唯一,Docker 特意为它提供了“短路”操作,在本地使用镜像的时候,我们不用像名字那样要完全写出来这一长串数字,通常只需要写出前三位就能够快速定位,在镜像数量比较少的时候用两位甚至一位数字也许就可以了。 7、镜像管理的流程 8、生产环境镜像分发案例 1、容器技术除了的docker之外,还有其它不同的容器技术,为了保证容器生态的标准性和健康可持续发展,包括Linux 基金会、Docker、微软、红帽谷歌和、IBM、华为等公司在2015年6月共同成立了一个叫open container(OCI)的组织,其目的就是制定开放的标准的容器规范,目前OCI发布了runtime spec(运行时规范)、image format spec(镜像格式规范)、distribution-spec(镜像分发规范),这样不同的容器公司开发的容器只要兼容以上规范,就可以保证容器的可移植性和相互可操作性。 2、常见的runtime: 1)runc:目前Docker和containerd默认的runtime,基于go语言开发,遵循OCI规范。 2)crun: redhat推出的运行时,基于c语言开发,集成在podman内部,遵循OCI规范。 3)gVisor:google推出的运行时,基于go语言开发,遵循OCI规范。 1、unionfs或者叫rootfs UnionFS是文件级的存储驱动,实现方式是把位于不同位置的目录或文件合并 mount到同一个目的目录中,简单来说就是支持将不同目录挂载到同一个虚拟文件系统下的文件系统,这种文件系统可以一层一层地叠加修改文件,无论底下有多少层都是只读的,只有最上层的文件系统是可写的 2、rootfs分层结构说明 容器的 rootfs 由如下图所示的三部分组成 a、第一部分,只读层。这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout) b、第二部分,可读写层。它是这个容器的 rootfs 最上面的一层(6e3be5d2ecccae7cc),它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。 c、第三部分,Init 层。它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。 3、python app.py从存储角度解析 这个容器进程“python app.py”,运行在由 Linux Namespace 和 Cgroups 构成的隔离环境里;而它运行所需要的各种文件,比如 python,app.py,以及整个操作系统文件,则由多个联合挂载在一起的 rootfs 层提供。2)docker.socket
3) containerd.service
3、启动docker,并配置开机自启动
4、查看docker信息

四、熟练使用docker数据卷
1、docker数据管理-写时复制(COW)
2、docker数据管理-数据持久化

3、Docker 数据管理-分层管理
4、docker数据持久化的两种类型

5、docker数据持久化实验(数据卷的方式)
1)docker创建数据卷


2)使用数据卷







3)数据目录挂载实验



![]()
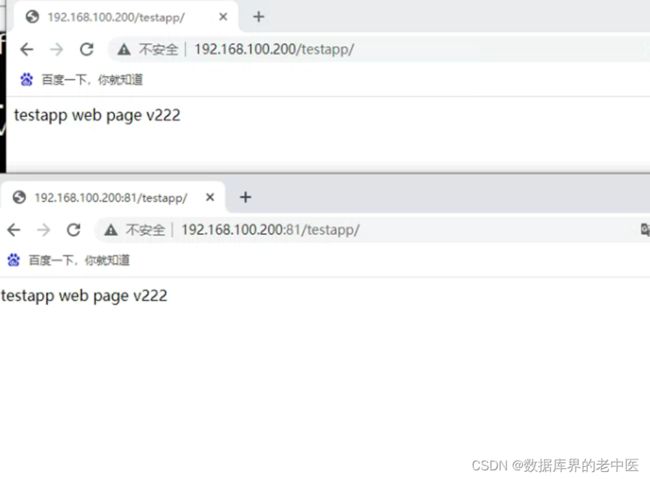

![]()
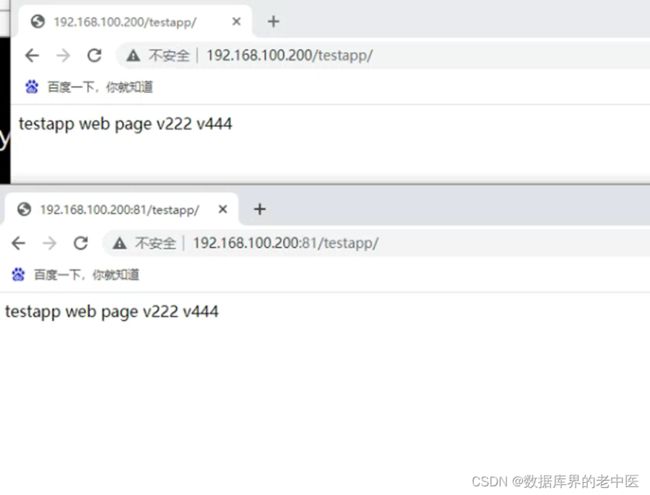
4)数据目录及配置多卷挂载:
![]()


5)mysql数据库数据卷持久化实验




五、熟练使用docker的bridge和container模式网络

1、Docker网络-bridge模式


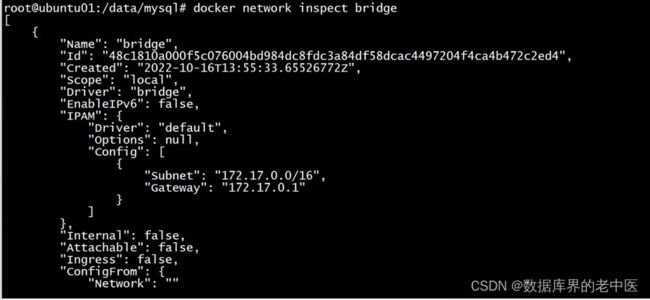



2、Docker网络-host模式
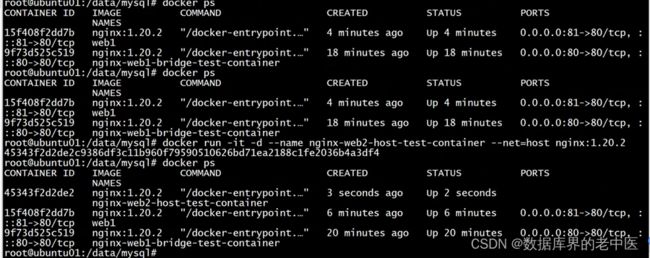
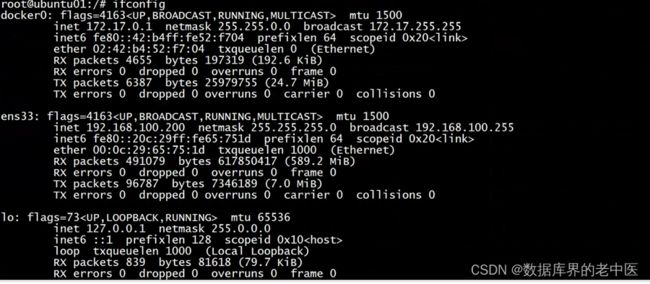

3、Docker网络-none模式

4、Docker网络-container模式




六、补充作业:docker的架构和命令图
1、docker架构图

2、docker命令图

3、docker命令官网链接
 https://docs.docker.com/engine/reference/commandline/build/docker build | Docker Documentation
https://docs.docker.com/engine/reference/commandline/build/docker build | Docker Documentation 七、补充作业:什么是容器

八、补充作业:容器与虚拟机的区别是什么


九、补充作业:什么是镜像



十、补充作业:运行时简介
十一:补充作业:docker存储引擎