Spark SQL解析json文件
Spark SQL解析json文件
- 一、get_json_object
- 二、from_json
- 三、explode
- 四、案例:解析json格式日志
-
- 数据
- 数据处理
先介绍一下会用到的三个函数:get_json_object、from_json、explode
一、get_json_object
从一个json 字符串中根据指定的json 路径抽取一个json 对象
def get_json_object(e: org.apache.spark.sql.Column,path: String): org.apache.spark.sql.Column
- 第一个参数为column名,用$"column_name"表示
- 第二个参数为要取的json字段名,"$.字段名"表示
例子:df是一个DataFrame,其中字段value为json格式,内容为{“name”:“张三”,“age”:“20”},现在想要分别取出name和age,可以用如下方式
// alias用于修改名字
df.select(get_json_object($"value","$.name").alias("name"),get_json_object($"value","$.age").alias("age")).show

二、from_json
从一个json 字符串中按照指定的schema格式抽取出来作为DataFrame的列
def from_json(e: org.apache.spark.sql.Column,schema: org.apache.spark.sql.types.StructType): org.apache.spark.sql.Column
- 第一个参数为列名,以$"column_name"表示
- 第二个参数为定义的数据结构
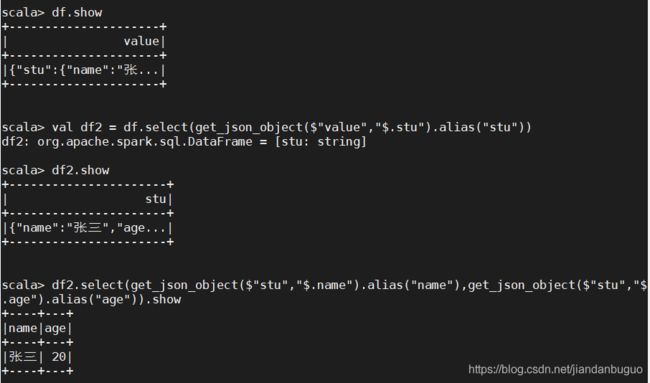
例:df是一个DataFrame,其中字段value为json格式内容为{“stu”:{“name”:“张三”,“age”:“20”}},想要获取name和age字段
①直接使用get_json_object
val df2 = df.select(get_json_object($"value","$.stu").alias("stu"))
df2.select(get_json_object($"stu","$.name").alias("name"),get_json_object($"stu","$.age").alias("age")).show
②使用from_json
val df2 = df.select(get_json_object($"value","$.stu").alias("stu"))
val df3 = df2.select(from_json($"stu",ArrayType(StructType(StructField("name",StrigType)::StructField("age",StringType)::Nil))).alias("stuInfo"))
df3.select($"stuInfo.name".alias("name"),$"stuInfo.age".alias("age")).show

三、explode
利用explode函数,把数组数据进行展开
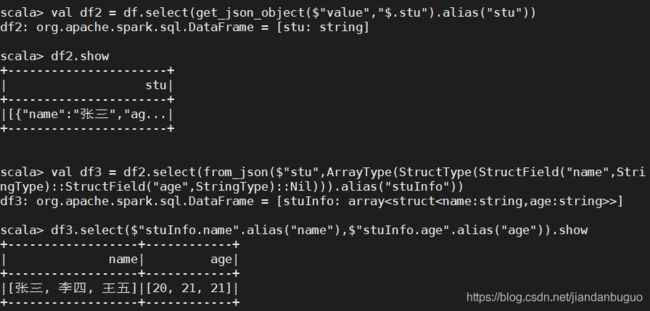
例:df是一个DataFrame,其中字段value为json格式内容为{“stu”:[{“name”:“张三”,“age”:“20”},{“name”:“李四”,“age”:“21”},{“name”:“王五”,“age”:“21”}]},想要获取name和age字段
若是向上面一样直接去取name和age字段,如下述代码
val df2 = df.select(get_json_object($"value","$.stu").alias("stu"))
val df3 = df2.select(from_json($"stu",ArrayType(StructType(StructField("name",StrigType)::StructField("age",StringType)::Nil))).alias("stuInfo"))
df3.select($"stuInfo.name".alias("name"),$"stuInfo.age".alias("age")).show
则出现这种情况:
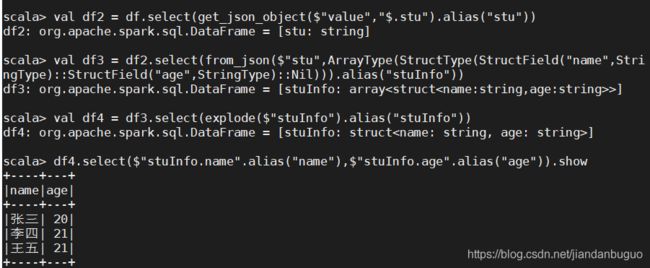
想要解决上问题,可以使用explode
val df2 = df.select(get_json_object($"value","$.stu").alias("stu"))
val df3 = df2.select(from_json($"stu",ArrayType(StructType(StructField("name",StringType)::StructField("age",StringType)::Nil))).alias("stuInfo"))
val df4 = df3.select(explode($"stuInfo").alias("stuInfo"))
df4.select($"stuInfo.name".alias("name"),$"stuInfo.age".alias("age")).show
四、案例:解析json格式日志
数据
使用的数据如下,一同两条数据,数据的组成为:用户编号和json格式的日志信息,二者以"|"号拼接
1593136280858|{"cm":{"ln":"-55.0","sv":"V2.9.6","os":"8.0.4","g":"[email protected]","mid":"489","nw":"3G","l":"es","vc":"4","hw":"640*960","ar":"MX","uid":"489","t":"1593123253541","la":"5.2","md":"sumsung-18","vn":"1.3.4","ba":"Sumsung","sr":"I"},"ap":"app","et":[{"ett":"1593050051366","en":"loading","kv":{"extend2":"","loading_time":"14","action":"3","extend1":"","type":"2","type1":"201","loading_way":"1"}},{"ett":"1593108791764","en":"ad","kv":{"activityId":"1","displayMills":"78522","entry":"1","action":"1","contentType":"0"}},{"ett":"1593111271266","en":"notification","kv":{"ap_time":"1593097087883","action":"1","type":"1","content":""}},{"ett":"1593066033562","en":"active_background","kv":{"active_source":"3"}},{"ett":"1593135644347","en":"comment","kv":{"p_comment_id":1,"addtime":"1593097573725","praise_count":973,"other_id":5,"comment_id":9,"reply_count":40,"userid":7,"content":"辑赤蹲慰鸽抿肘捎"}}]}
1593136280858|{"cm":{"ln":"-114.9","sv":"V2.7.8","os":"8.0.4","g":"[email protected]","mid":"490","nw":"3G","l":"pt","vc":"8","hw":"640*1136","ar":"MX","uid":"490","t":"1593121224789","la":"-44.4","md":"Huawei-8","vn":"1.0.1","ba":"Huawei","sr":"O"},"ap":"app","et":[{"ett":"1593063223807","en":"loading","kv":{"extend2":"","loading_time":"0","action":"3","extend1":"","type":"1","type1":"102","loading_way":"1"}},{"ett":"1593095105466","en":"ad","kv":{"activityId":"1","displayMills":"1966","entry":"3","action":"2","contentType":"0"}},{"ett":"1593051718208","en":"notification","kv":{"ap_time":"1593095336265","action":"2","type":"3","content":""}},{"ett":"1593100021275","en":"comment","kv":{"p_comment_id":4,"addtime":"1593098946009","praise_count":220,"other_id":4,"comment_id":9,"reply_count":151,"userid":4,"content":"抄应螟皮釉倔掉汉蛋蕾街羡晶"}},{"ett":"1593105344120","en":"praise","kv":{"target_id":9,"id":7,"type":1,"add_time":"1593098545976","userid":8}}]}
数据处理
- 由于拼接了用户的编号,故需要将用户编号分割才能都到json格式的数据,为了不丢失用户编号,可以将用户编号也添加到json格式的信息中,操作如下:
// 从hdfs上读取数据(spark默认读取hdfs上的数据,若从本地读取,路径要以"file:///路径"格式)
val fileRDD = sc.textFile("hdfs://hadoop4:9000/kb09file/op.log")
// 将数据以|分割,并将用户编号id,拼接到json串中
val jsonStrRDD = fileRDD.map(_.split("\\|")).jsonRDD2.map(x=>x(1).substring(0,x(1).size-1)+",\"id\":\""+x(0)+"\"}")
// 将rdd转为DataFrame
val jsonDF = jsonStrRDD.toDF
- 取出json字段的第一层
可以用json格式的解析器看一下我们处理后的json数据,由于字段过多,我下图值罗列第一层,至于里面还有内嵌的我们稍后再看
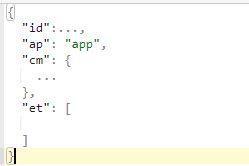
根据上图我们可以使用get_json_object取出上述字段
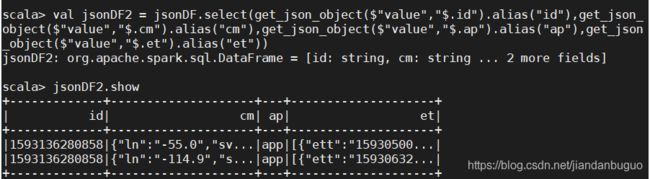
val jsonDF2 = jsonDF.select(get_json_object($"value","$.id").alias("id"),get_json_object($"value","$.cm").alias("cm"),get_json_object($"value","$.ap").alias("ap"),get_json_object($"value","$.et").alias("et"))
jsonDF2.show
- 解析cm字段中的json数据
val jsonDF3 = jsonDF2.select($"id",$"ap",get_json_object($"cm","$.ln").alias("ln"),get_json_object($"cm","$.sv").alias("sv"),get_json_object($"cm","$.os").alias("os"),get_json_object($"cm","$.g").alias("g"),get_json_object($"cm","$.mid").alias("mid"),get_json_object($"cm","$.nw").alias("nw"),get_json_object($"cm","$.l").alias("l"),get_json_object($"cm","$.vc").alias("vc"),get_json_object($"cm","$.hw").alias("hw"),get_json_object($"cm","$.ar").alias("ar"),get_json_object($"cm","$.uid").alias("uid"),get_json_object($"cm","$.t").alias("t"),get_json_object($"cm","$.la").alias("la"),get_json_object($"cm","$.md").alias("md"),get_json_object($"cm","$.vn").alias("vn"),get_json_object($"cm","$.ba").alias("ba"),get_json_object($"cm","$.sr").alias("sr"),$"et")

- 解析et中的json字段
查看et字段的格式,因此可以使用from_json先为个字段指定数据结构,再用explode行转列

// 使用from_json函数,为et中的个字段指定数据结构
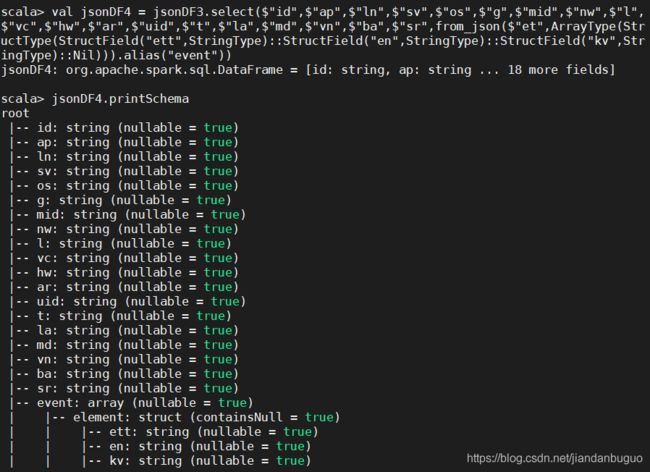
val jsonDF4 = jsonDF3.select($"id",$"ap",$"ln",$"sv",$"os",$"g",$"mid",$"nw",$"l",$"vc",$"hw",$"ar",$"uid",$"t",$"la",$"md",$"vn",$"ba",$"sr",from_json($"et",ArrayType(StructType(StructField("ett",StringType)::StructField("en",StringType)::StructField("kv",StringType)::Nil))).alias("event"))
jsonDF4.printSchema
// explode行转列
val jsonDF5 = jsonDF4.select($"id",$"ap",$"ln",$"sv",$"os",$"g",$"mid",$"nw",$"l",$"vc",$"hw",$"ar",$"uid",$"t",$"la",$"md",$"vn",$"ba",$"sr",explode($"event").alias("event"))
jsonDF5.show

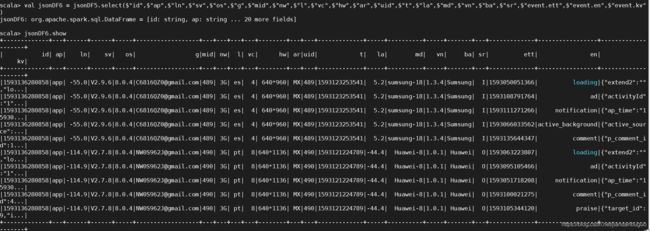
// 取出个字段
val jsonDF6 = jsonDF5.select($"id",$"ap",$"ln",$"sv",$"os",$"g",$"mid",$"nw",$"l",$"vc",$"hw",$"ar",$"uid",$"t",$"la",$"md",$"vn",$"ba",$"sr",$"event.ett",$"event.en",$"event.kv")
- 通过指定条件,分情况解析kv字段
en的值不同,kv的json格式数据字段也不同,因此需要针对不同情况对kv进行解析
// en值为ad的情况
jsonDF6.filter(x=>x.getAs("en")=="ad").select($"en",get_json_object($"kv","$.activityId").alias("activityId"),get_json_object($"kv","$.displayMills").alias("displayMills"),get_json_object($"kv","$.entry").alias("entry"),get_json_object($"kv","$.action").alias("action"),get_json_object($"kv","$.contentType").alias("contentType")).show

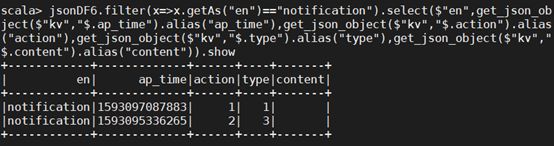
// en值为notification
jsonDF6.filter(x=>x.getAs("en")=="notification").select($"en",get_json_object($"kv","$.ap_time").alias("ap_time"),get_json_object($"kv","$.action").alias("action"),get_json_object($"kv","$.type").alias("type"),get_json_object($"kv","$.content").alias("content")).show
其他情况类似,可仿照写