Scala笔记
Scala第一章节
章节目标
- 理解Scala的相关概述
- 掌握Scala的环境搭建
- 掌握Scala小案例: 做最好的自己
1. Scala简介
1.1 概述
Scala(斯嘎拉)这个名字来源于"Scalable Language(可伸缩的语言)", 它是一门基于JVM的多范式编程语言, 通俗的说: Scala是一种运行在JVM上的函数式的面向对象语言. 它集成了面向对象编程和面向函数式编程的各种特性, 以及更高层的并发模型.
总而言之, Scala融汇了许多前所未有的特性, 而同时又运行于JVM之上
基于JVM解释:Scala的运行环境和Java类似, 也是依赖JVM的.
多范式解释: Scala支持多种编程风格
1.2 Scala之父
Scala之父是: Martin·Odersky(马丁·奥德斯基), 他在整个职业生涯中一直不断追求着一个目标:让写程序这样一个基础工作变得高效、简单、且令人愉悦

1.3 语言特点
-
Scala的兼容性
兼容Java,可以访问庞大的Java类库,例如:操作mysql、redis、freemarker、activemq等等 -
Scala的精简性
Scala表达能力强,一行代码抵得上多行Java代码,开发速度快 -
Scala的高级性
Scala可以让你的程序保持短小, 清晰, 看起来更简洁, 更优雅 -
Scala的静态类型
Scala拥有非常先进的静态类型系统, 支持: 类型推断和模式匹配等 -
Scala可以开发大数据应用程序
例如: Spark程序、Flink程序等等...
2. Scala程序和Java程序对比
2.1 程序的执行流程对比
Java程序编译执行流程
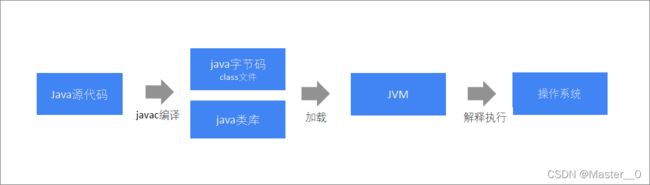
Scala程序编译执行流程

2.2 代码对比
**需求: **
定义一个学生类, 属性为: 姓名和年龄, 然后在测试类中创建对象并测试.
Java代码
//定义学生类
public class Student{
private String name; //姓名
private int age; //年龄
//空参和全参构造
public Student(){}
public Student(String name, int age){
this.name = name;
this.age = age;
}
//getXxx()和setXxx()方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
//测试类
public class StudentDemo {
public static void main(String[] args) {
Student s1 = new Student("张三", 23); //创建Student类型的对象s1, 并赋值
System.out.println(s1); //打印对象, 查看结果.
}
}
Scala代码
case class Student(var name:String, var age:Int) //定义一个Student样例类
val s1 = Student("张三", 23) //创建Student类型的对象s1, 并赋值
println(s1) //打印对象, 查看结果.
3. Scala环境搭建
3.1 概述
scala程序运行需要依赖于Java类库,那么必须要有Java运行环境,scala才能正确执行. 所以要编译运行scala程序,需要:
- JDK(JDK包含JVM)
- Scala编译器(Scala SDK)
接下来,需要依次安装以下内容:
- 安装JDK
- 安装Scala SDK
- 在IDEA中安装Scala插件
3.2 安装JDK
安装JDK 1.8 64位版本
3.3 安装Scala SDK
Scala SDK是scala语言的编译器,要开发scala程序,必须要先安装Scala SDK
步骤
-
下载Scala SDK.
官方下载地址: scala-lang.org/download/ -
安装Scala SDK.
2.1 双击scala-xxxx.msi,将scala安装在指定目录, 傻瓜式安装, 下一步下一步即可.
2.2 安装路径要合法, 不要出现中文, 空格等特殊符号. -
测试是否安装成功
打开控制台,输入: scala -version
3.4 安装IDEA scala插件
IDEA默认是不支持scala程序开发的,所以需要在IDEA中安装scala插件, 让它来支持scala语言。
4. Scala解释器
4.1 概述
scala解释器像Linux命令一样,执行一条代码,马上就可以让我们看到执行结果,用来测试比较方便。
我们接下来学习:
- 启动scala解释器
- 在scala解释器中执行scala代码
- 退出scala解释器
4.2 启动scala解释器
要启动scala解释器,只需要以下几步:
- 按住
windows键 + r - 输入
scala即可
4.3 执行scala代码
在scala的命令提示窗口中输入println("hello, world"),回车执行
4.4 退出解释器
方式一: 点击右上角的"×"
方式二: 输入:quit退出
5. 案例: 做最好的自己.
5.1 需求
提示用户录入他/她最想对自己说的一句话, 然后将这句话打印到控制台上.
5.2 目的
测试Scala和Java之间可以无缝互调(即: Scala兼容Java,可以访问庞大的Java类库).
5.3 思路分析
1. 因为涉及到键盘录入了, 所以先导包.
2. 提示用户录入他/她最想对自己说的一句话.
3. 接收用户录入的内容, 并打印.
5.4 参考代码
//1. 导入Java中的Scanner类. 引入Java类库
import java.util.Scanner
//2. 提示用户录入他/她最想对自己说的一句话. Scala代码
println("请录入一句您最想对自己说的一句话: ")
//3. 打印用户录入的内容. Scala代码 + Java类库
//不忘初心, 方得始终, 做最好的自己!
println("我最想对自己说: " + new Scanner(System.in).nextLine())
Scala第二章节
章节目标
- 掌握变量, 字符串的定义和使用
- 掌握数据类型的划分和数据类型转换的内容
- 掌握键盘录入功能
- 理解Scala中的常量, 标识符相关内容
1. 输出语句和分号
1.1 输出语句
方式一: 换行输出
格式: println(里边写你要打印到控制台的数据);
方式二: 不换行输出
格式: print(里边写你要打印到控制台的数据);
注意:
不管是println(), 还是print()语句, 都可以同时打印多个值.格式为: println(值1, 值2, 值3...)
1.2 分号
Scala语句中, 单行代码最后的分号可写可不写. 如果是多行代码写在一行, 则中间的分号不能省略, 最后一条代码的分号可省略不写.
示例:
println("Hello, Scala!") //最后的分号可写可不写
//如果多行代码写在一行, 则前边语句的分号必须写, 最后一条语句的分号可以省略不写.
println("Hello"); println("Scala")
2. Scala中的常量
2.1 概述
常量指的是: 在程序的运行过程中, 其值不能发生改变的量.
2.2 分类
- 字面值常量(常用的有以下几种)
- 整型常量
- 浮点型常量
- 字符常量
- 字符串常量
- 布尔常量
- 空常量
- 自定义常量(稍后解释)
2.3 代码演示
//整型常量
println(10)
//浮点型常量
println(10.3)
//字符常量, 值要用单引号括起来
println('a')
//字符串常量, 值要用双引号括起来
println("abc")
//布尔常量, 值只有true和false
println(true)
//空常量
println(null)
3. Scala中的变量
3.1 概述
我们将来每一天编写scala程序都会定义变量, 那什么是变量, 它又是如何定义的呢?
变量, 指的就是在程序的执行过程中, 其值可以发生改变的量. 定义格式如下:
3.2 语法格式
Java变量定义
int a = 0;
在scala中,可以使用val或者var来定义变量,语法格式如下:
val/var 变量名:变量类型 = 初始值
其中
val定义的是不可重新赋值的变量, 也就是自定义常量.var定义的是可重新赋值的变量
注意: scala中定义变量时, 类型写在变量名后面
3.3 示例
需求: 定义一个变量保存一个人的名字"tom"
步骤
- 打开scala解释器
- 定义一个字符串类型的变量用来保存名字
参考代码
scala> val name:String = "tom"
name: String = tom
3.4 val和var变量的区别
示例
给名字变量进行重新赋值为Jim,观察其运行结果
参考代码
scala> name = "Jim"
<console>:12: error: reassignment to val
name = "Jim"
示例
使用var重新定义变量来保存名字"tom",并尝试重新赋值为Jim,观察其运行结果
参考代码
scala> var name:String = "tom"
name: String = tom
scala> name = "Jim"
name: String = Jim
注意: 优先使用
val定义变量,如果变量需要被重新赋值,才使用var
3.5 使用类型推断来定义变量
scala的语法要比Java简洁,我们可以使用一种更简洁的方式来定义变量。
示例
使用更简洁的语法定义一个变量保存一个人的名字"tom"
参考代码
scala> val name = "tom"
name: String = tom
scala可以自动根据变量的值来自动推断变量的类型,这样编写代码更加简洁。
4. 字符串
scala提供多种定义字符串的方式,将来我们可以根据需要来选择最方便的定义方式。
- 使用双引号
- 使用插值表达式
- 使用三引号
4.1 使用双引号
语法
val/var 变量名 = “字符串”
示例
有一个人的名字叫"hadoop",请打印他的名字以及名字的长度。
参考代码
scala> println(name + name.length)
hadoop6
4.2 使用插值表达式
scala中,可以使用插值表达式来定义字符串,有效避免大量字符串的拼接。
语法
val/var 变量名 = s"${变量/表达式}字符串"
注意:
- 在定义字符串之前添加
s- 在字符串中,可以使用
${}来引用变量或者编写表达式
示例
请定义若干个变量,分别保存:“zhangsan”、23、“male”,定义一个字符串,保存这些信息。
打印输出:name=zhangsan, age=23, sex=male
参考代码
scala> val name = "zhangsan"
name: String = zhangsan
scala> val age = 23
age: Int = 23
scala> val sex = "male"
sex: String = male
scala> val result = s"name=${name}, age=${age}, sex=${sex}"
result: String = name=zhangsan, age=23, sex=male
scala> println(result)
name=zhangsan, age=23, sex=male
4.3 使用三引号
如果有大段的文本需要保存,就可以使用三引号来定义字符串。例如:保存一大段的SQL语句。三个引号中间的所有内容都将作为字符串的值。
语法
val/var 变量名 = """字符串1
字符串2"""
示例
定义一个字符串,保存以下SQL语句
select
*
from
t_user
where
name = "zhangsan"
打印该SQL语句
参考代码
val sql = """select
| *
| from
| t_user
| where
| name = "zhangsan""""
println(sql)
4.4 扩展: 惰性赋值
在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千行。这些SQL语句,如果直接加载到JVM中,会有很大的内存开销, 如何解决这个问题呢?
当有一些变量保存的数据较大时,而这些数据又不需要马上加载到JVM内存中。就可以使用惰性赋值来提高效率。
语法格式:
lazy val/var 变量名 = 表达式
示例
在程序中需要执行一条以下复杂的SQL语句,我们希望只有用到这个SQL语句才加载它。
"""insert overwrite table adm.itcast_adm_personas
select
a.user_id,
a.user_name,
a.user_sex,
a.user_birthday,
a.user_age,
a.constellation,
a.province,
a.city,
a.city_level,
a.hex_mail,
a.op_mail,
a.hex_phone,
a.fore_phone,
a.figure_model,
a.stature_model,
b.first_order_time,
b.last_order_time,
...
d.month1_hour025_cnt,
d.month1_hour627_cnt,
d.month1_hour829_cnt,
d.month1_hour10212_cnt,
d.month1_hour13214_cnt,
d.month1_hour15217_cnt,
d.month1_hour18219_cnt,
d.month1_hour20221_cnt,
d.month1_hour22223_cnt
from gdm.itcast_gdm_user_basic a
left join gdm.itcast_gdm_user_consume_order b on a.user_id=b.user_id
left join gdm.itcast_gdm_user_buy_category c on a.user_id=c.user_id
left join gdm.itcast_gdm_user_visit d on a.user_id=d.user_id;"""
参考代码
scala> lazy val sql = """insert overwrite table adm.itcast_adm_personas
| select
| a.user_id,
....
| left join gdm.itcast_gdm_user_buy_category c on a.user_id=c.user_id
| left join gdm.itcast_gdm_user_visit d on a.user_id=d.user_id;"""
sql: String = <lazy>
5. 标识符
5.1 概述
实际开发中, 我们会编写大量的代码, 这些代码中肯定会有变量, 方法, 类等. 那它们该如何命名呢? 这就需要用到标识符了. 标识符就是用来给变量, 方法, 类等起名字的. Scala中的标识符和Java中的标识符非常相似.
5.2 命名规则
- 必须由
大小写英文字母, 数字, 下划线_, 美元符$, 这四部分任意组合组成. - 数字不能开头.
- 不能和Scala中的关键字重名.
- 最好做到见名知意.
5.3 命名规范
-
变量或方法: 从第二个单词开始, 每个单词的首字母都大写, 其他字母全部小写(小驼峰命名法).
zhangSanAge, student_Country, getSum -
类或特质(Trait): 每个单词的首字母都大写, 其他所有字母全部小写(大驼峰命名法)
Person, StudentDemo, OrderItems -
包: 全部小写, 一般是公司的域名反写, 多级包之间用.隔开.
com.itheima.add, cn.itcast.update
6. 数据类型
6.1 简述
数据类型是用来约束变量(常量)的取值范围的. Scala也是一门强类型语言, 它里边的数据类型绝大多数和Java一样.我们主要来学习
- 与Java不一样的一些用法
- scala中数据类型的继承体系
6.2 数据类型
| 基础类型 | 类型说明 |
|---|---|
| Byte | 8位带符号整数 |
| Short | 16位带符号整数 |
| Int | 32位带符号整数 |
| Long | 64位带符号整数 |
| Char | 16位无符号Unicode字符 |
| String | Char类型的序列(字符串) |
| Float | 32位单精度浮点数 |
| Double | 64位双精度浮点数 |
| Boolean | true或false |
注意下 scala类型与Java的区别
[!NOTE]
- scala中所有的类型都使用大写字母开头
- 整形使用
Int而不是Integer- scala中定义变量可以不写类型,让scala编译器自动推断
- Scala中默认的整型是Int, 默认的浮点型是: Double
6.3 Scala类型层次结构

| 类型 | 说明 |
|---|---|
| Any | 所有类型的父类,它有两个子类AnyRef与AnyVal |
| AnyVal | 所有数值类型的父类 |
| AnyRef | **所有对象类型(引用类型)**的父类 |
| Unit | 表示空,Unit是AnyVal的子类,它只有一个的实例{% em %}() {% endem %} 它类似于Java中的void,但scala要比Java更加面向对象 |
| Null | Null是AnyRef的子类,也就是说它是所有引用类型的子类。它的实例是{% em %}null{% endem %} 可以将null赋值给任何对象类型 |
| Nothing | 所有类型的子类, 不能直接创建该类型实例,某个方法抛出异常时,返回的就是Nothing类型,因为Nothing是所有类的子类,那么它可以赋值为任何类型 |
6.4 思考题
以下代码是否有问题?
val b:Int = null
Scala会解释报错: Null类型并不能转换为Int类型,说明Null类型并不是Int类型的子类
7. 类型转换
7.1 概述
当Scala程序在进行运算或者赋值动作时, 范围小的数据类型值会自动转换为范围大的数据类型值, 然后再进行计算.例如: 1 + 1.1的运算结果就是一个Double类型的2.1. 而有些时候, 我们会涉及到一些类似于"四舍五入"的动作, 要把一个小数转换成整数再来计算. 这些内容就是Scala中的类型转换.
Scala中的类型转换分为
值类型的类型转换和引用类型的类型转换, 这里我们先重点介绍:值类型的类型转换.值类型的类型转换分为:
- 自动类型转换
- 强制类型转换
7.2 自动类型转换
-
解释
范围小的数据类型值会自动转换为范围大的数据类型值, 这个动作就叫: 自动类型转换.
自动类型转换从小到大分别为:Byte, Short, Char -> Int -> Long -> Float -> Double -
示例代码
val a:Int = 3 val b:Double = 3 + 2.21 //因为是int类型和double类型的值进行计算, 所以最终结果为: Double类型 val c:Byte = a + 1 //这样写会报错, 因为最终计算结果是Int类型的数据, 将其赋值Byte类型肯定不行.
7.3 强制类型转换
-
解释
范围大的数据类型值通过一定的格式(强制转换函数)可以将其转换成范围小的数据类型值, 这个动作就叫: 强制类型转换.
注意: 使用强制类型转换的时候可能会造成精度缺失问题! -
格式
val/var 变量名:数据类型 = 具体的值.toXxx //Xxx表示你要转换到的数据类型
- 参考代码
val a:Double = 5.21
val b:Int = a.toInt
7.4 值类型和String类型之间的相互转换
1. 值类型的数据转换成String类型
格式一:
val/var 变量名:String = 值类型数据 + ""
格式二:
val/var 变量名:String = 值类型数据.toString
示例
将Int, Double, Boolean类型的数据转换成其对应的字符串形式.
参考代码:
val a1:Int = 10
val b1:Double = 2.1
val c1:Boolean = true
//方式一: 通过和空字符串拼接的形式实现
val a2:String = a1 + ""
val b2:String = b1 + ""
val c2:String = c1 + ""
//方式二: 通过toString函数实现
val a3:String = a1.toString
val b3:String = b1.toString
val c3:String = c1.toString
2. String类型的数据转换成其对应的值类型
格式:
val/var 变量名:值类型 = 字符串值.toXxx //Xxx表示你要转换到的数据类型
注意:
- String类型的数据转成Char类型的数据, 方式有点特殊, 并不是调用toChar, 而是toCharArray
- 这点目前先了解即可, 后续我们详细解释
需求:
将字符串类型的整数, 浮点数, 布尔数据转成其对应的值类型数据.
参考代码:
val s1:String = "100"
val s2:String = "2.3"
val s3:String = "false"
//将字符串类型的数据转成其对应的: Int类型
val a:Int = s1.toInt
//将字符串类型的数据转成其对应的: Double类型
val b:Double = s2.toDouble
//将字符串类型的数据转成其对应的: Boolean类型
val c:Boolean = s3.toBoolean
8. 键盘录入
8.1 概述
前边我们涉及到的数据, 都是我们写"死"的, 固定的数据, 这样做用户体验并不是特别好. 那如果这些数据是由用户录入, 然后我们通过代码接收, 就非常好玩儿了. 这就是接下来我们要学习的Scala中的"键盘录入"功能.
8.2 使用步骤
-
导包
格式: import scala.io.StdIn
-
通过
StdIn.readXxx()来接收用户键盘录入的数据接收字符串数据: StdIn.readLine()
接收整数数据: StdIn.readInt()
8.3 示例
-
提示用户录入字符串, 并接收打印.
println("请录入一个字符串: ") val str = StdIn.readLine() println("您录入的字符串内容为: " + str) -
提示用户录入整数, 并接收打印.
println("请录入一个整数: ") val num = StdIn.readInt() println("您录入的数字为: " + num)
9. 案例: 打招呼
9.1 概述
需求: 提示用户录入他/她的姓名和年龄, 接收并打印.
9.2 具体步骤
- 提示用户录入姓名.
- 接收用户录入的姓名.
- 提示用户录入年龄.
- 接收用户录入的年龄.
- 将用户录入的数据(姓名和年龄)打印到控制台上.
9.3 参考代码
//1. 提示用户录入姓名.
println("请录入您的姓名: ")
//2. 接收用户录入的姓名.
val name = StdIn.readLine()
//3. 提示用户录入年龄.
println("请录入您的年龄: ")
//4. 接收用户录入的年龄.
val age = StdIn.readInt()
//5. 将用户录入的数据(姓名和年龄)打印到控制台上.
println(s"大家好, 我叫${name}, 我今年${age}岁了, 很高兴和大家一起学习Scala!")
Scala第三章节
章节目标
- 理解运算符的相关概述
- 掌握算术, 赋值, 关系, 逻辑运算符的用法
- 掌握交换变量案例
- 理解位运算符的用法
1. 算术运算符
1.1 运算符简介
用来拼接变量或者常量的符号就叫: 运算符, 而通过运算符连接起来的式子就叫: 表达式. 实际开发中, 我们会经常用到它.
例如:
10 + 3 这个就是一个表达式, 而+号, 就是一个运算符.
注意: 在Scala中, 运算符并不仅仅是运算符, 也是函数的一种
1.2 运算符的分类
-
算术运算符
-
赋值运算符
-
关系运算符
-
逻辑运算符
-
位运算符
注意: Scala中是没有三元运算符的, 被if-else给替代了.
1.3 算术运算符
算术运算符指的就是用来进行算术操作的符号, 常用的有以下几种:
| 运算符 | 功能解释 |
|---|---|
| + | 加号, 功能有3点. 1) 表示正数 2) 普通的加法操作 3) 字符串的拼接 |
| - | 减号, 功能有2点. 1) 表示负数 2) 普通的减法操作 |
| * | 乘号, 用于获取两个数据的乘积 |
| / | 除法, 用于获取两个数据的商 |
| % | 取余(也叫取模), 用于获取两个数据的余数 |
注意:
Scala中是没有++, --这两个算术运算符的, 这点和Java中不同.
整数相除的结果, 还是整数. 如果想获取到小数, 则必须有浮点型数据参与.
例如: 10 / 3 结果是3 10 / 3.0 结果是: 3.3333(无限循环)关于+号拼接字符串: 任意类型的数据和字符串拼接, 结果都将是一个新的字符串.
关于%操作, 假设求
a % b的值, 它的底层原理其实是:a - a/b * b
1.4 代码演示
需求: 演示算术运算符的常见操作.
参考代码:
//演示+号操作
println(+3)
println(10 + 3)
println("hello" + 10)
//演示-号操作
println(-5)
println(10 - 5)
//演示*号操作
println(5 * 3)
//演示/号操作
println(10 / 3)
println(10 / 3.0)
//演示%(取余)操作
println(10 % 3) //结果是1, 具体运算过程: 10 - 10/3 * 3 = 10 - 3 * 3 = 1
println(10 % -3) //结果是1, 具体运算过程: 10 - 10/-3 * -3 = 10 - -3 * -3 = 10 - 9 = 1
println(-10 % 3) //结果是-1, 具体运算过程: -10 - -10/3 * 3 = -10 - -3 * 3 = -10 + 9 = -1
2. 赋值运算符
2.1 概述
赋值运算符指的就是用来进行赋值操作的符号. 例如: 把一个常量值, 或者一个变量值甚至是某一段代码的执行结果赋值给变量, 这些都要用到赋值运算符.
2.2 分类
-
赋值运算符常用的有两类
-
基本赋值运算符
=就是基本的赋值运算符, 例如: var a:Int = 3, 就是把常量值3赋值给变量a -
扩展赋值运算符
+=, -=, *=, /=, %=
注意:
-
赋值运算符的左边必须是: 变量, 不能是常量. 例如: 3 = 5, 这种写法就是错误的.
-
关于扩展赋值运算符, 其实就是把左边的数据和右边的数据进行指定的操作, 然后把结果赋值给左边.
例如; a += 3 就是把变量a的值和常量3进行加法操作, 然后把结果赋值给变量a
-
2.3 代码演示
//将常量值1赋值给变量a
var a:Int = 1 //注意: 因为后续代码要修改变量a的值, 所以变量a要用var修饰
//对变量a进行加3操作, 然后把结果重新赋值给变量a
a += 3 //a的最终结果为: a = 4
//对变量a进行减2操作, 然后把结果重新赋值给变量a
a -= 2 //a的最终结果为: a = 2
//对变量a进行乘3操作, 然后把结果重新赋值给变量a
a *= 3 //a的最终结果为: a = 6
//对变量a进行除2操作, 然后把结果重新赋值给变量a
a /= 2 //a的最终结果为: a = 3
//对变量a和2进行取余操作, 然后把结果重新赋值给变量a
a %= 2 //a的最终结果为: a = 1
3. 关系运算符
3.1 概述
关系运算符指的就是用来进行比较操作的符号. 例如: 数据是否相等, 是否不等, 数据1大还是数据2大…等这些操作.
3.2 分类
| 运算符 | 功能解释 |
|---|---|
| > | 用来判断前边的数据是否大于后边的数据 |
| >= | 用来判断前边的数据是否大于或者等于后边的数据 |
| < | 用来判断前边的数据是否小于后边的数据 |
| <= | 用来判断前边的数据是否小于或者等于后边的数据 |
| == | 用来判断两个数据是否相等 |
| != | 用来判断两个数据是否不等 |
注意:
- 关系表达式不管简单还是复杂, 最终结果一定是Boolean类型的值, 要么是true, 要么是false.
- 千万不要把==写成=, 否则结果可能不是你想要的.
3.3 代码演示
//定义两个Int类型的变量a, b, 分别赋值为3, 5
var a:Int = 3
var b:Int = 5
//判断a是否大于b, 并打印结果
println(a > b) //false
//判断a是否大于等于b, 并打印结果
println(a >= 3) //true
//判断a是否小于b, 并打印结果
println(a < b) //true
//判断a是否小于等于b, 并打印结果
println(a <= 3) //true
//判断a和b是否不等, 并打印结果
println(a != b) //true
//判断a和b是否相等, 并打印结果
println(a == b) //false
//如果把==写成了=, 其实是把变量b的值赋值给变量a
println(a = b) //输出结果是一对小括号"()", 即: 没有打印值.
println(a) //再次打印变量a, 打印结果是:5
3.4 关系运算符延伸
与java不同的地方
| 需求描述 | Scala代码 | Java代码 |
|---|---|---|
| 比较数据值 | == 或者 != | equals()方法 |
| 比较引用值(地址值) | eq方法 | == 或者 != |
示例
有一个字符串"abc",再创建第二个字符串,值为:在第一个字符串后拼接一个空字符串。
然后使用比较这两个字符串是否相等、再查看它们的引用值是否相等。
参考代码
val s1 = "abc"
val s2 = s1 + ""
s1 == s2 //结果是: true, 因为比较的是 数据值
s1.eq(s2) //结果是: false, 因为比较的是 地址值
4. 逻辑运算符
4.1 概述
逻辑运算符指的就是用来进行逻辑操作的符号. 可以简单理解为它是: 组合判断. 例如: 判断多个条件是否都满足, 或者满足其中的某一个, 甚至还可以对某个判断结果进行取反操作.
4.2 分类
| 运算符 | 功能解释 |
|---|---|
| && | 逻辑与, 要求所有条件都满足(即: 结果为true), 简单记忆: 有false则整体为false. |
| || | 逻辑或, 要求只要满足任意一个条件即可, 简单记忆: 有true则整体为true. |
| ! | 逻辑非, 用来进行取反操作的. 即: 以前为true, 取反后为false, 以前为false, 取反后为true. |
注意:
- 逻辑表达式不管简单还是复杂, 最终结果一定是Boolean类型的值, 要么是true, 要么是false.
- 在Scala代码中, 不能对一个Boolean类型的数据进行连续取反操作, 但是在Java中是可以的.
- 即: !!false, 这样写会报错, 不支持这种写法.
4.3 代码演示
//相当于: false && true
println(3 > 5 && 2 < 3) //结果为: false
//我们可以简写代码为:
//逻辑与: 有false则整体为false.
println(false && true) //结果为: false
println(true && false) //结果为: false
println(false && false) //结果为: false
println(true && true) //结果为: true
println(false || true) //结果为: true
println(true || false) //结果为: true
println(false || false) //结果为: false
println(true || true) //结果为: true
println(!false) //结果为: true
println(!true) //结果为: false
println(!!true) //这样写会报错, Scala不支持这种写法, 但是Java代码支持这种写法.
5. 位运算符
5.1 铺垫知识
要想学好位运算符, 你必须得知道三个知识点:
- 什么是进制
- 什么是8421码
- 整数的原码, 反码, 补码计算规则
5.1.1 关于进制
通俗的讲, 逢几进一就是几进制, 例如: 逢二进一就是二进制, 逢十进一就是十进制, 常用的进制有以下几种:
| 进制名称 | 数据组成规则 | 示例 |
|---|---|---|
| 二进制 | 数据以0b(大小写均可)开头, 由数字0和1组成 | 0b10001001, 0b00101010 |
| 八进制 | 数据以0开头, 由数字0~7组成 | 064, 011 |
| 十进制 | 数据直接写即可, 无特殊开头, 由数字0~9组成 | 10, 20, 333 |
| 十六进制 | 数据以0x(大小写均可)开头, 由数字0~9, 字母A-F组成(大小写均可) | 0x123F, 0x66ABC |
注意:
关于二进制的数据, 最前边的那一位叫: 符号位, 0表示正数, 1表示负数. 其他位叫: 数值位.
例如: 0b10001001 结果就是一个: 负数, 0b00101010 结果就是一个: 正数.
5.1.2 关于8421码
8421码就是用来描述二进制位和十进制数据之间的关系的, 它可以帮助我们快速的计算数据的二进制或十进制形式.
8421码对应关系如下:
二进制位 0 0 0 0 0 0 0 0
对应的十进制数据 128 64 32 16 8 4 2 1
注意:
计算规则: 二进制位从右往左数, 每多一位, 对应的十进制数据 乘以2.
二进制和十进制相互转换的小技巧:
- 二进制转十进制: 获取该二进制位对应的十进制数据, 然后累加即可.
- 例如: 0b101对应的十进制数据计算步骤: 4 + 0 + 1 = 5
- 十进制转二进制: 对十进制数据进行拆解, 看哪些数字相加等于它, 然后标记成二进制即可.
- 例如: 10 对应的二进制数据计算步骤: 10 = 8 + 2 = 0b1010
5.1.3 关于整数的原反补码计算规则
所谓的原反补码, 其实指的都是二进制数据, 把十进制的数据转成其对应的二进制数据, 该二进制数据即为: 原码.
注意: 计算机底层存储, 操作和运算数据, 都是采用
数据的二进制补码形式来实现的.
- 正数
- 正数的原码, 反码, 补码都一样, 不需要特殊计算.
- 负数
- 负数的反码计算规则: 原码的符号位不变, 数值位按位取反(以前为0现在为1, 以前为1现在为0)
- 负数的补码计算规则: 反码 + 1
5.2 概述
位运算符指的就是按照位(Bit)来快速操作数据值, 它只针对于整型数据. 因为计算机底层存储, 操作, 运算采用的都是数据的二进制补码形式, 且以后我们要经常和海量的数据打交道, 为了提高计算效率, 我们就可以使用位运算符来实现快速修改数据值的操作.
5.3 分类
| 运算符 | 功能解释 |
|---|---|
| & | 按位与, 规则: 有0则0, 都为1则为1. |
| | | 按位或, 规则: 有1则1, 都为0则为0. |
| ^ | 按位异或, 规则: 相同为0, 不同为1. |
| ~ | 按位取反, 规则: 0变1, 1变0. |
| << | 按位左移, 规则: 每左移一位, 相当于该数据乘2, 例如: 2 << 1, 结果为4 |
| >> | 按位右移, 规则: 每右移一位, 相当于该数据除2, 例如: 6 >> 1, 结果为3 |
注意:
- 位运算符只针对于整型数据.
- 运算符操作的是数据的二进制补码形式.
- 小技巧: 一个数字被同一个数字位异或两次, 该数字值不变. 即: 10 ^ 20 ^ 20, 结果还是10
5.4 代码演示
//定义两个变量a和b, 初始化值分别为: 3, 5
val a = 3 //二进制数据: 0000 0011
val b = 5 //二进制数据: 0000 0101
//结果为: 0000 0001, 转化成十进制, 结果为: 1
println(a & b) //打印结果为: 1
//结果为: 0000 0111, 转化成十进制, 结果为: 7
println(a | b) //打印结果为: 7
//结果为: 0000 0110, 转换成十进制, 结果为: 6
println(a ^ b) //打印结果为: 6
//计算流程: 1111 1100(补码) -> 1111 1011(反码) -> 1000 0100(原码) -> 十进制数据: -4
println(~ a) //打印结果为: -4
//计算流程: 1000 0011(-3原码) -> 1111 1100(-3反码) -> 1111 1101(-3补码) -> 0000 0010(取反后新补码) -> 十进制数据: 2
println(~ -3) //打印结果为: 2
//计算流程: 0000 0011(3的补码) -> 0000 1100(新的补码) -> 十进制数据: 12
println(a << 2) //打印结果为: 12
//计算流程: 0000 0011(3的补码) -> 0000 0001(新的补码) -> 十进制数据: 1
println(a >> 1) //打印结果为: 1
println(a ^ b ^ b) //打印结果为: 3
6. 案例: 交换两个变量的值
6.1 需求
已知有两个Int类型的变量a和b, 初始化值分别为10和20, 请写代码实现变量a和变量b的值的交换.
即最终结果为: a=20, b=10.
注意: 不允许直接写
a=20, b=10这种代码.
6.2 参考代码
-
方式一: 通过算术运算符实现.
//定义两个Int类型的变量a和b, 初始化值分别为10和20 var a = 10 var b = 20 //将变量a和b的计算结果赋值给变量a a = a + b //a = 30, b = 20 //计算并赋值 b = a - b //a = 30, b = 10 a = a - b //a = 20, b = 10 //打印结果 println("a: " + a) //a: 20 println("b: " + b) //b: 10 -
方式二: 通过定义临时变量实现
//定义两个Int类型的变量a和b, 初始化值分别为10和20 var a = 10 var b = 20 //定义临时变量temp, 记录变量a的值 var temp = a //a = 10, b = 20, temp = 10 //把变量b的值赋值给a a = b //a = 20, b = 20, temp = 10 //把临时变量temp的值赋值给b b = temp //a = 20, b = 10, temp = 10 //打印结果 println("a: " + a) //a: 20 println("b: " + b) //b: 10 -
方式三: 通过位运算符实现
//定义两个Int类型的变量a和b, 初始化值分别为10和20 var a = 10 var b = 20 //定义临时变量temp, 记录变量a和b的位异或值(这个值不需要我们计算) var temp = a ^ b //即: temp = 10 ^ 20 //通过位异或进行交换变量值 a = a ^ temp //运算流程: = a ^ a ^ b = 10 ^ 10 ^ 20 = 20 b = b ^ temp //运算流程: = b ^ a ^ b = 20 ^ 10 ^ 20 = 10 //打印结果 println("a: " + a) //a: 20 println("b: " + b) //b: 10
Scala第四章节
章节目标
- 掌握分支结构的格式和用法
- 掌握for循环和while循环的格式和用法
- 掌握控制跳转语句的用法
- 掌握循环案例
- 理解do.while循环的格式和用法
1. 流程控制结构
1.1 概述
在实际开发中, 我们要编写成千上万行代码, 代码的顺序不同, 执行结果肯定也会受到一些影响, 并且有些代码是满足特定条件才能执行的, 有些代码是要重复执行的. 那如何合理规划这些代码呢? 这就需要用到: 流程控制结构了.
1.2 分类
-
顺序结构
-
选择(分支)结构
-
循环结构
注意: Scala和Java中的流程控制结构是基本一致的.
2. 顺序结构
2.1 概述
顺序结构是指: 程序是按照从上至下, 从左至右的顺序, 依次逐行执行的, 中间没有任何判断和跳转.
如图:
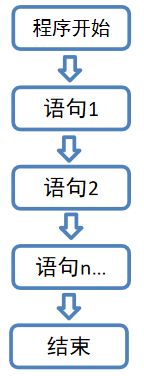
注意: 顺序结构是Scala代码的默认流程控制结构.
2.2 代码演示
val a = 10
println("a: " + a) //打印结果为10
println("键盘敲烂, ")
println("月薪过万! ")
2.3 思考题
下边这行代码的打印结果应该是什么呢?
println(10 + 10 + "Hello,Scala" + 10 + 10)
提示: 代码是按照从上至下, 从左至右的顺序, 依次逐行执行的.
3. 选择结构(if语句)
3.1 概述
选择结构是指: 某些代码的执行需要依赖于特定的判断条件, 如果判断条件成立, 则代码执行, 否则, 代码不执行.
3.2 分类
- 单分支
- 双分支
- 多分支
3.3 单分支
所谓的单分支是指: 只有一个判断条件的if语句.
3.3.1 格式
if(关系表达式) {
//具体的代码
}
注意: 关系表达式不管简单还是复杂, 结果必须是Boolean类型的值.
3.3.2 执行流程
-
先执行关系表达式, 看其结果是true还是false.
-
如果是true, 则执行具体的代码, 否则, 不执行.
-
如图:
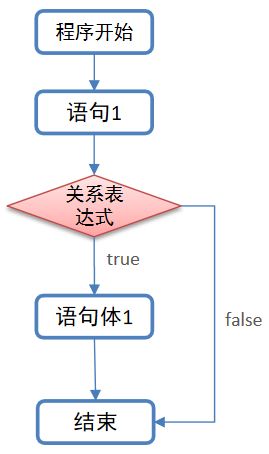
3.3.3 示例
需求:
定义一个变量记录某个学生的成绩, 如果成绩大于或者等于60分, 则打印: 分数及格.
参考代码
//定义变量, 记录成绩
val score = 61
//判断成绩是否不小于60分
if(score >= 60) {
println("成绩及格")
}
3.4 双分支
所谓的双分支是指: 只有两个判断条件的if语句.
3.4.1 格式
if(关系表达式) {
//代码1
} else {
//代码2
}
3.4.2 执行流程
- 先执行关系表达式, 看其结果是true还是false.
- 如果是true, 则执行代码1. 如果是false, 则执行代码2.
- 如图:

3.4.3 示例
需求:
定义一个变量记录某个学生的成绩, 如果成绩大于或者等于60分, 则打印: 分数及格, 否则打印分数不及格.
参考代码
//定义变量, 记录成绩
val score = 61
//判断成绩是否不小于60分
if(score >= 60) {
println("成绩及格")
} else {
println("成绩不及格")
}
3.5 多分支
所谓的多分支是指: 有多个判断条件的if语句.
3.5.1 格式
if(关系表达式1) {
//代码1
} else if(关系表达式2) {
//代码2
}else if(关系表达式n) { //else if可以有多组
//代码n
} else {
//代码n+1 //所有的关系表达式都不成立的时候, 执行这里的代码.
}
3.5.2 执行流程
- 先执行关系表达式1, 看其结果是true还是false.
- 如果是true, 则执行代码1, 分支语句结束. 如果是false, 则执行关系表达式2, 看其结果是true还是false.
- 如果是true, 则执行代码2. 分支语句结束. 如果是false, 则执行关系表达式3, 看其结果是true还是false.
- 以此类推, 直到所有的关系表达式都不满足, 执行最后一个else中的代码.
- 如图:
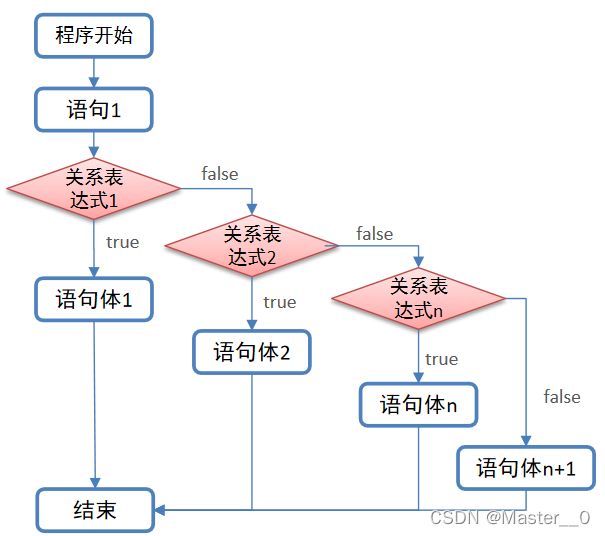
3.5.3 示例
需求:
定义一个变量记录某个学生的成绩, 根据成绩发放对应的奖励, 奖励机制如下:
[90, 100] -> VR设备一套
[80, 90) -> 考试卷一套
[0, 80) -> 组合拳一套
其他 -> 成绩无效
参考代码
//定义变量, 记录成绩
val score = 80
//根据成绩发放对应的奖励
if(score >= 90 && score <= 100) {
println("VR设备一套")
} else if(score >= 80 && score < 90) {
println("考试卷一套")
} else if(score >= 0 && score < 80) {
println("组合拳一套")
} else {
println("成绩无效")
}
3.6 注意事项
if语句在使用时, 要注意的事项有以下三点:
- 和Java一样, 在Scala中, 如果大括号{}内的逻辑代码只有一行, 则大括号可以省略.
- 在scala中,条件表达式也是有返回值的
- 在scala中,没有三元表达式,可以使用if表达式替代三元表达式
示例
定义一个变量sex,再定义一个result变量,如果sex等于"male",result等于1,否则result等于0
参考代码
//定义变量, 表示性别
val sex = "male"
//定义变量, 记录if语句的返回值结果
val result = if(sex == "male") 1 else 0
//打印结果为 result: 1
println("result: " + result)
3.7 嵌套分支
有些时候, 我们会涉及到"组合判断", 即一个分支结构中又嵌套了另一个分支结构, 这种写法就叫嵌套分支. 里边的那个分支结构叫: 内层分支, 外边的那个分支结构叫: 外层分支.
示例
定义三个变量a,b,c, 初始化值分别为: 10, 20, 30, 通过if分支语句, 获取其中的最大值.
思路分析
- 定义三个变量a, b, c, 分别记录要进行操作的值.
- 定义变量max, 用来记录获取到的最大值.
- 先判断a是否大于或者等于b.
- 条件成立, 说明 a大(或者等于b), 接着比较a和c的值, 获取最大值, 并将结果赋值给变量max
- 条件不成立, 说明 b大, 接着比较b和c的值, 获取最大值, 并将结果赋值给变量max
- 此时, max记录的就是a, b, c这三个变量的最大值, 打印即可.
参考代码
//1. 定义三个变量a, b, c, 分别记录要进行操作的值.
val a = 10
val b = 20
val c = 30
//2. 定义变量max, 用来记录获取到的最大值.
var max = 0
//3. 先判断a是否大于或者等于b.
if(a >= b) {
//4. 走这里说明a大(或者等于b), 接着比较a和c的值
max = if(a >= c) a else c
} else {
//5. 走这里说明b大, 接着比较b和c的值
max = if(b >= c) b else c
}
//6. 打印max的值
println("max: " + max)
注意: 嵌套一般不超过3层.
3.8 扩展: 块表达式
- scala中,使用{}表示一个块表达式
- 和if表达式一样,块表达式也是有值的
- 值就是最后一个表达式的值
问题
请问以下代码,变量a的值是什么?
val a = {
println("1 + 1")
1 + 1
}
println("a: " + a)
2
4. 循环结构
4.1 概述
循环,指的是事物周而复始的变化。而Scala中的循环结构,是指: 使一部分代码按照次数或一定的条件反复执行的一种代码结构。例如: 打印10次"Hello, Scala!", 如果纯写输出语句, 需要写10次, 而通过循环来实现的话, 输出语句只需要写1次, 这样就变得很简单了.
4.2 分类
- for循环
- while循环
- do.while循环
注意: 这三种循环推荐使用for循环, 因为它的语法更简洁, 更优雅.
4.3 for循环
在Scala中, for的格式和用法和Java中有些差异, Scala中的for表达式功能更加强大.
4.3.1 格式
for(i <- 表达式/数组/集合) {
//逻辑代码
}
注意: 执行流程和Java一致
4.3.2 简单循环
需求:
打印10次"Hello, Scala!"
参考代码:
//定义一个变量, 记录1到10的数字
val nums = 1 to 10 //to是Scala中的一个关键字
//通过for循环, 打印指定的内容
for(i <- nums) {
println("Hello, Scala! " + i)
}
上述代码可以简写成:
for(i <- 1 to 10) println("Hello, Scala! " + i)
4.3.3 嵌套循环
需求: 使用for表达式,打印以下字符, 每次只能输出一个"*"
*****
*****
*****
步骤
- 使用for表达式打印3行,5列星星
- 每打印5个星星,换行
参考代码
//写法一: 普通写法
for(i <- 1 to 3) { //外循环控制行数
for(j <- 1 to 5) { //内循环控制列数
print("*") //每次打印一个*
}
println() //打印完一行(5个*)之后, 记得换行
}
//写法二: 压缩版
for(i <- 1 to 3) {
//这是两行代码
for(j <- 1 to 5) if(j == 5) println("*") else print("*")
}
//写法三: 合并版
for(i <- 1 to 3; j <- 1 to 5) if(j == 5) println("*") else print("*")
4.3.4 守卫
for表达式中,可以添加if判断语句,这个if判断就称之为守卫。我们可以使用守卫让for表达式更简洁。
语法
for(i <- 表达式/数组/集合 if 表达式) {
//逻辑代码
}
示例
使用for表达式打印1-10之间能够整除3的数字
参考代码
// 添加守卫,打印能够整除3的数字
for(i <- 1 to 10 if i % 3 == 0) println(i)
4.4.5 for推导式
Scala中的for循环也是有返回值的, 在for循环体中,可以使用yield表达式构建出一个集合(可以简单理解为: 就是一组数据),我们把使用yield的for表达式称之为推导式.
示例
生成一个10、20、30…100的集合
参考代码
// for推导式:for表达式中以yield开始,该for表达式会构建出一个集合
val v = for(i <- 1 to 10) yield i * 10
println(v)
4.4 while循环
scala中while循环和Java中是一致的, 所以学起来非常简单.
4.4.1 格式
初始化条件
while(判断条件) {
//循环体
//控制条件
}
4.4.2 执行流程
- 执行初始化条件.
- 执行判断条件, 看其结果是true还是false.
- 如果是false则循环结束.
- 如果是true则执行循环体.
- 执行控制条件.
- 返回第二步, 重复执行.
4.4.3 示例
需求:
打印1-10的数字
参考代码
//初始化条件
var i = 1
//判断条件
while(i <= 10) {
//循环体
println(i)
//控制条件
i = i + 1
}
4.5 do.while循环
scala中do.while循环和Java中是一致的, 所以学起来非常简单.
4.4.1 格式
初始化条件
do{
//循环体
//控制条件
}while(判断条件)
4.4.2 执行流程
- 执行初始化条件.
- 执行循环体.
- 执行控制条件.
- 执行判断条件, 看其结果是true还是false.
- 如果是false则循环结束.
- 如果是true则返回第2步继续执行.
注意:
- do.while循环不管判断条件是否成立, 循环体都会执行一次.
- for循环, while循环都是如果判断条件不成立, 则循环体不执行.
4.4.3 示例
需求:
打印1-10的数字
参考代码
//初始化条件
var i = 1
do{
//循环体
println(i)
//控制条件
i = i + 1
}while(i <= 10) //判断条件
4.6 break和continue
- 在scala中,类似Java和C++的break/continue关键字被移除了
- 如果一定要使用break/continue,就需要使用scala.util.control包下的Breaks类的breable和break方法。
4.6.1 实现break
用法
-
导包.
import scala.util.control.Breaks._ -
使用breakable将for表达式包起来
-
for表达式中需要退出循环的地方,添加
break()方法调用
示例
使用for表达式打印1-10的数字,如果遇到数字5,则退出for表达式
参考代码
// 导入scala.util.control包下的Break
import scala.util.control.Breaks._
breakable{
for(i <- 1 to 10) {
if(i == 5) break() else println(i)
}
}
4.6.2 实现continue
用法
continue的实现与break类似,但有一点不同:
注意:
- 实现break是用breakable{}将整个for表达式包起来.
- 而实现continue是用breakable{}将for表达式的循环体包含起来就可以了.
示例
用for表达式打印1~10之间, 所有不能整除3的数字.
// 导入scala.util.control包下的Break
import scala.util.control.Breaks._
for(i <- 1 to 100 ) {
breakable{
if(i % 3 == 0) break()
else println(i)
}
}
5. 综合案例
5.1 九九乘法表
需求:
打印九九乘法表, 如下图:

步骤
-
通过外循环控制打印的行数.
-
通过内循环控制每行打印的列数.
注意: 因为列数是随着行数递增的, 即:
行数 该行的总列数 1 1 2 2 3 3 n n 结论: 如果用i表示行数, 那么该行的列数取值范围为: [1, i]
参考代码
- 方式一: 普通写法
//外循环控制行
for(i <- 1 to 9) {
//内循环控制列
for(j <- 1 to i) {
print(s"${i} * ${j} = ${i * j}\t")
}
println() //别忘了换行
}
- 方式二: 合并版写法
//外循环控制行
for(i <- 1 to 9; j <- 1 to i) {
print(s"${i} * ${j} = ${i * j}\t")
if(j == i) println() //别忘了换行
}
5.2 模拟登陆
需求:
老王要登陆黑马官网学习Scala, 假设老王的账号和密码分别为"itcast", “heima”, 且同一账号只有3次登陆机会, 如果3次都录入错误, 则提示账号被锁定. 请用所学模拟该场景.
步骤
- 导包
- scala.io.StdIn
- scala.util.control.Breaks._
- 定义变量, 记录用户录入的账号和密码.
- 因为涉及到break的动作, 所以要用breakable{}把整个for表达式包裹起来
- 因为只有3次登陆机会, 所以推荐使用for循环.
- 提示用户录入他/她的账号和密码, 并接收.
- 判断用户录入的账号和密码是否正确.
- 如果录入正确, 则提示"登陆成功, 开始学习Scala!", 循环结束.
- 如果录入错误, 则判断是否还有登陆机会
- 有, 则提示"用户名或者密码错误, 您还有*次机会", 然后返回第5步继续执行.
- 没有, 则提示"账号被锁定, 请与管理员联系", 循环结束.
参考代码
//1. 导包
import scala.io.StdIn
import scala.util.control.Breaks._
//2. 定义变量, 记录用户录入的账号和密码
var username = ""
var password = ""
//3. 因为涉及到break的动作, 所以要用breakable{}把整个for表达式包裹起来
breakable {
//4. 因为只有3次登陆机会, 所以推荐使用for循环.
for(i <- 1 to 3) {
//5. 提示用户录入他/她的账号和密码, 并接收.
println("请录入您的账号: ")
username = StdIn.readLine()
println("请录入您的密码: ")
password = StdIn.readLine()
//6. 判断用户录入的账号和密码是否正确.
if(username == "itcast" && password == "heima") {
//7. 走到这里, 说明登陆成功, 循环结束.
println("登陆成功, 开始学习Scala吧!")
break()
} else {
//8. 走到这里, 说明登陆失败. 则判断是否还有登陆机会
if(i == 3) println("账号被锁定, 请与管理员联系!")
else println(s"用户名或者密码错误, 您还有${3 - i}次机会")
}
}
}
Scala第五章节
章节目标
- 掌握方法的格式和用法
- 掌握函数的格式和用法
- 掌握九九乘法表案例
1. 方法
1.1 概述
实际开发中, 我们需要编写大量的逻辑代码, 这就势必会涉及到重复的需求. 例如: 求10和20的最大值, 求11和22的最大值, 像这样的需求, 用来进行比较的逻辑代码需要编写两次, 而如果把比较的逻辑代码放到方法中, 只需要编写一次就可以了, 这就是方法. scala中的方法和Java方法类似, 但scala与Java定义方法的语法是不一样的。
1.2 语法格式
def 方法名(参数名:参数类型, 参数名:参数类型) : [return type] = {
//方法体
}
注意:
- 参数列表的参数类型不能省略
- 返回值类型可以省略,由scala编译器自动推断
- 返回值可以不写return,默认就是{}块表达式的值
1.3 示例
需求:
- 定义一个方法getMax,用来获取两个整型数字的最大值, 并返回结果(最大值).
- 调用该方法获取最大值, 并将结果打印到控制台上.
参考代码
- 方式一: 标准写法
//1. 定义方法, 用来获取两个整数的最大值.
def getMax(a:Int, b:Int): Int = {
return if(a > b) a else b
}
//2. 调用方法, 获取最大值.
val max = getMax(10, 20)
//3. 打印结果.
println("max: " + max)
- 方式二: 优化版
//1. 定义方法, 用来获取两个整数的最大值.
def getMax(a:Int, b:Int) = if(a > b) a else b
//2. 调用方法, 获取最大值.
val max = getMax(22, 11)
//3. 打印结果.
println("max: " + max)
1.4 返回值类型推断
scala定义方法可以省略返回值的数据类型,由scala自动推断返回值类型。这样方法定义后更加简洁。
注意: 定义递归方法,不能省略返回值类型
示例
定义递归方法, 求5的阶乘.
步骤
-
定义方法factorial, 用来计算某个数字的阶乘
规律: 1的阶乘等于1, 其他数字的阶乘为: n! = n * (n - 1)!
-
调用方法, 获取5的阶乘, 并将结果打印到控制台上.
参考代码
//1. 定义方法factorial, 用来计算某个数字的阶乘
def factorial(n:Int):Int = if(n == 1) 1 else n * factorial(n - 1)
//2. 调用方法, 获取5的阶乘.
val result = factorial(5)
//3. 将结果打印到控制台上.
println("result: " + result)
1.5 惰性方法
当记录方法返回值的变量被声明为lazy时, 方法的执行将被推迟, 直到我们首次使用该值时, 方法才会执行, 像这样的方法, 就叫: 惰性方法.
注意:
- Java中并没有提供原生态的"惰性"技术, 但是可以通过特定的代码结构实现, 这种结构被称之为: 懒加载(也叫延迟加载)
- lazy不能修饰var类型的变量.
使用场景:
-
打开数据库连接
由于表达式执行代价昂贵, 因此我们希望能推迟该操作, 直到我们确实需要表达式结果值时才执行它 -
提升某些特定模块的启动时间.
为了缩短模块的启动时间, 可以将当前不需要的某些工作推迟执行 -
确保对象中的某些字段能优先初始化
为了确保对象中的某些字段能优先初始化, 我们需要对其他字段进行惰性化处理
需求
定义一个方法用来获取两个整数和, 通过"惰性"技术调用该方法, 然后打印结果.
参考代码
//1. 定义方法, 用来获取两个整数和
def getSum(a:Int, b:Int) = {
println("getSum方法被执行了...")
a + b
}
//2. 通过"惰性"方式调用该方法.
lazy val sum = getSum(1, 2) //此时我们发现getSum方法并没有执行, 说明它的执行被推迟了.
//3. 打印结果, 并观察
println("sum: " + sum) //打印结果为sum: 3, 说明首次使用方法返回值时, 方法才会加载执行.
1.6 方法参数
scala中的方法参数,使用比较灵活。它支持以下几种类型的参数:
- 默认参数
- 带名参数
- 变长参数
1.6.1 默认参数
在定义方法时可以给参数定义一个默认值。
示例
- 定义一个计算两个整数和的方法,这两个值分别默认为10和20
- 调用该方法,不传任何参数
参考代码
//1. 定义一个方法, 用来获取两个整数的和
// x,y的默认值分别为10和20
def getSum(x:Int = 10, y:Int = 20) = x + y
//2. 通过默认参数的形式, 调用方法
val sum = getSum()
//3. 打印结果
println("sum: " + sum)
1.6.2 带名参数
在调用方法时,可以指定参数的名称来进行调用。
示例
- 定义一个计算两个整数和的方法,这两个值分别默认为10和20
- 调用该方法,只设置第一个参数的值
参考代码
//1. 定义一个方法, 用来获取两个整数的和
def getSum(x:Int = 10, y:Int = 20) = x + y
//2. 通过默认参数的形式, 调用方法
val sum = getSum(x=1)
//3. 打印结果
println("sum: " + sum)
1.6.3 变长参数
如果方法的参数是不固定的,可以将该方法的参数定义成变长参数。
语法格式:
def 方法名(参数名:参数类型*):返回值类型 = {
//方法体
}
注意:
- 在参数类型后面加一个
*号,表示参数可以是0个或者多个- 一个方法有且只能有一个变长参数, 并且变长参数要放到参数列表的最后边.
示例一:
- 定义一个计算若干个值相加的方法
- 调用方法,传入以下数据:1,2,3,4,5
参考代码
//1. 定义一个计算若干个值相加的方法
def getSum(a:Int*) = a.sum
//2. 调用方法,传入一些整数, 并获取它们的和
val sum = getSum(1,2,3,4,5)
//3. 打印结果
println("sum: " + sum)
1.7 方法调用方式
在scala中,有以下几种方法调用方式:
- 后缀调用法
- 中缀调用法
- 花括号调用法
- 无括号调用法
注意: 在编写spark、flink程序时,会经常使用到这些方法调用方式。
1.7.1 后缀调用法
这种方法与Java没有区别, 非常简单.
语法
对象名.方法名(参数)
示例
使用后缀法调用Math.abs, 用来求绝对值
参考代码
//后缀调用法
Math.abs(-1) //结果为1
1.7.2 中缀调用法
语法
对象名 方法名 参数
例如:1 to 10
注意: 如果有多个参数,使用括号括起来
示例
使用中缀法调用Math.abs, 用来求绝对值
//中缀调用法
Math abs -1 //结果为1
扩展: 操作符即方法
来看一个表达式, 大家觉得这个表达式像不像方法调用?
1 + 1
在scala中,+ - * / %等这些操作符和Java一样,但在scala中,
- 所有的操作符都是方法
- 操作符是一个方法名字是符号的方法
1.7.3 花括号调用法
语法
Math.abs{
// 表达式1
// 表达式2
}
注意: 方法只有一个参数,才能使用花括号调用法
示例
使用花括号调用法Math.abs求绝对值
参考代码
//花括号调用法
Math.abs{-10} //结果为: 10
1.7.4 无括号调用法
如果方法没有参数,可以省略方法名后面的括号
示例
- 定义一个无参数的方法,打印"Hello, Scala!"
- 使用无括号调用法调用该方法
参考代码
//1. 定义一个无参数的方法,打印"Hello, Scala!"
def sayHello() = println("Hello, Scala!")
//2. 调用方法
sayHello
注意:
- 在Scala中, 如果方法的返回值类型是Unit类型, 这样的方法称之为过程(procedure)
- 过程的等号(=)可以省略不写. 例如:
def sayHello() = println("Hello, Scala!") //可以改写为 def sayHello() { println("Hello, Scala!") } //注意: 这个花括号{}不能省略
2. 函数
scala支持函数式编程,将来编写Spark/Flink程序会大量使用到函数, 目前, 我们先对函数做一个简单入门, 在后续的学习过程中, 我们会逐步重点讲解函数的用法.
2.1 定义函数
语法
val 函数变量名 = (参数名:参数类型, 参数名:参数类型....) => 函数体
注意:
- 在Scala中, 函数是一个对象(变量)
- 类似于方法,函数也有参数列表和返回值
- 函数定义不需要使用
def定义- 无需指定返回值类型
2.2 示例
需求:
- 定义一个计算两个整数和的函数
- 调用该函数
参考代码
//1. 定义一个用来计算两个整数和的函数, 并将其赋值给变量sum
val getSum = (x:Int, y:Int) => x + y
//2. 调用函数.
val result = getSum(1,2)
//3. 打印结果
println("result: " + result)
2.3 方法和函数的区别
在Java中, 方法和函数之间没有任何区别, 只是叫法不同. 但是在Scala中, 函数和方法就有区别了, 具体如下:
- 方法是隶属于类或者对象的,在运行时,它是加载到JVM的方法区中
- 可以将函数对象赋值给一个变量,在运行时,它是加载到JVM的堆内存中
- 函数是一个对象,继承自FunctionN,函数对象有apply,curried,toString,tupled这些方法。方法则没有
结论: 在Scala中, 函数是对象, 而方法是属于对象的, 所以可以理解为: 方法归属于函数.
示例
演示方法无法赋值给变量
//1. 定义方法
def add(x:Int,y:Int)= x + y
//2. 尝试将方法赋值给变量.
//val a = add(1, 2) //不要这样写, 这样写是在"调用方法", 而不是把方法赋值给变量
val a = add
//3. 上述代码会报错
<console>:12: error: missing argument list for method add
Unapplied methods are only converted to functions when a function type is expected.
You can make this conversion explicit by writing `add _` or `add(_,_)` instead of `add`.
val a = add
2.4 方法转换为函数
有时候需要将方法转换为函数. 例如: 作为变量传递,就需要将方法转换为函数
格式
val 变量名 = 方法名 _ //格式为: 方法名 + 空格 + 下划线
注意: 使用
_即可将方法转换为函数
示例
- 定义一个方法用来计算两个整数和
- 将该方法转换为一个函数,并赋值给变量
参考代码
//1. 定义一个方法用来计算两个整数和
def add(x:Int, y:Int)= x + y
//2. 将该方法转换为一个函数,并赋值给变量
val a = add _
//3. 调用函数, 用来获取两个整数的和.
val result = a(1, 2)
//4. 打印结果
println("result: " + result)
3. 案例: 打印nn乘法表
3.1 需求
定义方法实现, 根据用户录入的整数, 打印对应的乘法表。
例如: 用户录入5,则打印55乘法表,用户录入9,则打印99乘法表。
3.2 目的
- 考察
键盘录入和方法, 函数的综合运用. - 体会方法和函数的不同.
3.3 步骤
- 定义方法(或者函数), 接收一个整型参数.
- 通过for循环嵌套实现, 根据传入的整数, 打印对应的乘法表.
- 调用方法(函数), 输出结果.
3.4 参考代码
- 方式一: 通过方法实现
//1. 定义一个方法, 接收一个整型参数.
def printMT(n:Int) = { //Multiplication Table(乘法表)
//2. 通过for循环嵌套实现, 根据传入的整数, 打印对应的乘法表.
for(i <- 1 to n; j <- 1 to i) {
print(s"${j} * ${i} = ${j * i}\t");
if(j==i) println()
}
}
//3. 调用方法
printMT(5)
//优化版: 上述定义方法的代码可以合并为一行(目前只要能看懂即可)
/*def printMT(n:Int) = for(i <- 1 to n; j <- 1 to i) print(s"${j} * ${i} = ${j * i}" + (if(j==i) "\r\n" else "\t"))*/
- 方式二: 通过函数实现
//1. 定义一个函数, 接收一个整型参数.
val printMT = (n:Int) => {
//2. 通过for循环嵌套实现, 根据传入的整数, 打印对应的乘法表.
for(i <- 1 to n; j <- 1 to i) {
print(s"${j} * ${i} = ${j * i}\t");
if(j==i) println()
}
}
//3. 调用函数
printMT(9)
//优化版: 上述定义函数的代码可以合并为一行(目前只要能看懂即可)
/*val printMT = (n:Int) => for(i <- 1 to n; j <- 1 to i) print(s"${j} * ${i} = ${j * i}" + (if(j==i) "\r\n" else "\t"))*/
Scala第六章节
章节目标
- 掌握类和对象的定义
- 掌握访问修饰符和构造器的用法
- 掌握main方法的实现形式
- 掌握伴生对象的使用
- 掌握定义工具类的案例
1. 类和对象
Scala是一种函数式的面向对象语言, 它也是支持面向对象编程思想的,也有类和对象的概念。我们依然可以基于Scala语言来开发面向对象的应用程序。
1.1 相关概念
什么是面向对象?
面向对象是一种编程思想, 它是基于面向过程的, 强调的是以对象为基础完成各种操作.
面向对象的三大思想特点是什么?
1. 更符合人们的思考习惯.
2. 把复杂的事情简单化.
3. 把程序员从执行者变成指挥者.
面试题: 什么是面向对象? 思路: 概述, 特点, 举例, 总结.
什么是类?
类是属性和行为的集合, 是一个抽象的概念, 看不见, 也摸不着.
属性(也叫成员变量): 名词, 用来描述事物的外在特征的.
行为(也叫成员方法): 动词, 表示事物能够做什么.
例如: 学生有姓名和年龄(这些是属性), 学生要学习, 要吃饭(这些是行为).
什么是对象?
对象是类的具体体现, 实现.
面向对象的三大特征是什么?
封装, 继承, 多态.
1.2 创建类和对象
Scala中创建类和对象可以通过class和new关键字来实现. 用class来创建类, 用new来创建对象.
1.2.1 示例
创建一个Person类,并创建它的对象, 然后将对象打印到控制台上.
1.2.2 步骤
-
创建一个scala项目,并创建一个object类
注意: object修饰的类是单例对象, 这点先了解即可, 稍后会详细解释.
-
在object类中添加main方法.
-
创建Person类, 并在main方法中创建Person类的对象, 然后输出结果.
1.2.3 实现
-
在IDEA中创建项目,并创建一个object类(main方法必须放在Object中)
- 第一步: 创建Scala项目

- 第一步: 创建Scala项目

-
第二步: 创建object类.
-
在object类中添加main方法, 并按照需求完成指定代码.
//案例: 测试如何在Scala程序中创建类和对象.
object ClassDemo01 {
//1. 创建Person类
class Person {}
//2. 定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建Person类型的对象.
val p = new Person()
//4. 将对象打印到控制台上
println(p)
}
}
1.3 简写方式
用法
- 如果类是空的,没有任何成员,可以省略
{} - 如果构造器的参数为空,可以省略
()
示例
使用简写方式重新创建Person类和对象, 并打印对象.
参考代码
//案例: 通过简写方式在Scala中创建类和对象
object ClassDemo02 {
//1. 创建Person类
class Person
//2. 定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建Person类型的对象.
val p = new Person
//4. 将对象打印到控制台上
println(p)
}
}
2. 定义和访问成员变量
一个类会有自己的属性,例如:人类,就有自己的姓名和年龄。我们接下来学习如何在类中定义和访问成员变量。
2.1 用法
- 在类中使用
var/val来定义成员变量 - 对象可以通过
对象名.的方式来访问成员变量
2.2 示例
需求
- 定义一个Person类,包含一个姓名和年龄字段
- 创建一个名为"张三"、年龄为23岁的对象
- 打印对象的名字和年龄
步骤
- 创建一个object类,添加main方法
- 创建Person类,添加姓名字段和年龄字段,并对字段进行初始化,让scala自动进行类型推断
- 在main方法中创建Person类对象,设置成员变量为"张三"、23
- 打印对象的名字和年龄
参考代码
//案例: 定义和访问成员变量.
object ClassDemo03 {
//1. 创建Person类
class Person {
//2. 定义成员变量
//val name:String = ""
//通过类型推断来实现
//var修饰的变量, 值是可以修改的. val修饰的变量, 值不能修改.
var name = "" //姓名
var age = 0 //年龄
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建Person类型的对象.
val p = new Person
//4. 给成员变量赋值
p.name = "张三"
p.age = 23
//5. 打印成员变量值到控制台上
println(p.name, p.age)
}
}
3. 使用下划线初始化成员变量
scala中有一个更简洁的初始化成员变量的方式,可以让代码看起来更加简洁, 更优雅.
3.1 用法
- 在定义
var类型的成员变量时,可以使用_来初始化成员变量- String => null
- Int => 0
- Boolean => false
- Double => 0.0
- …
val类型的成员变量,必须要自己手动初始化
3.2 示例
需求
- 定义一个Person类,包含一个姓名和年龄字段
- 创建一个名为"张三"、年龄为23岁的对象
- 打印对象的名字和年龄
步骤
- 创建一个object类,添加main方法
- 创建Person类,添加姓名字段和年龄字段,指定数据类型,使用下划线初始化
- 在main方法中创建Person类对象,设置成员变量为"张三"、23
- 打印对象的名字和年龄
参考代码
//案例: 使用下划线来初始化成员变量值.
//注意: 该方式只针对于var类型的变量有效. 如果是val类型的变量, 需要手动赋值.
object ClassDemo04 {
//1. 创建Person类
class Person {
//2. 定义成员变量
var name:String = _ //姓名
var age:Int = _ //年龄
//val age:Int = _ //这样写会报错, 因为"下划线赋值"的方式只针对于var修饰的变量有效.
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建Person类型的对象.
val p = new Person
//4. 给成员变量赋值
p.name = "张三"
p.age = 23
//5. 打印成员变量值到控制台上
println(p.name, p.age)
}
}
4. 定义和访问成员方法
类可以有自己的行为,scala中也可以通过定义成员方法来定义类的行为。
4.1 格式
在scala的类中,也是使用def来定义成员方法的.
def 方法名(参数1:数据类型, 参数2:数据类型): [return type] = {
//方法体
}
注意: 返回值的类型可以不写, 由Scala自动进行类型推断.
4.2 示例
需求
-
创建一个Customer类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kRzXl9OW-1648454435068)(pictures\1557322180244.png)]
-
创建一个该类的对象,并调用printHello方法
步骤
- 创建一个object类,添加main方法
- 创建Customer类,添加成员变量、成员方法
- 在main方法中创建Customer类对象,设置成员变量值(张三、男)
- 调用成员方法
参考代码
//案例: 定义和访问成员方法
object ClassDemo05 {
//1. 创建Customer类
class Customer {
//2. 定义成员变量
var name:String = _ //姓名
var sex = "" //性别
//3. 定义成员方法printHello
def printHello(msg:String) = {
println(msg)
}
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//4. 创建Customer类型的对象.
val c = new Customer
//5. 给成员变量赋值
c.name = "张三"
c.sex = "男"
//6. 打印成员变量值到控制台上
println(c.name, c.sex)
//7. 调用成员方法
printHello("你好!")
}
}
5. 访问权限修饰符
和Java一样,scala也可以通过访问修饰符,来控制成员变量和成员方法是否可以被外界访问。
5.1 定义
-
Java中的访问控制,同样适用于scala,可以在成员前面添加private/protected关键字来控制成员的可见性。
-
在scala中,
没有public关键字,任何没有被标为private或protected的成员都是公共的.注意:
Scala中的权限修饰符只有: private, private[this], protected, 默认这四种.
5.2 案例
需求
-
定义一个Person类

-
在main方法中创建该类的对象,测试是否能够访问到私有成员
参考代码
//案例: 演示Scala中的访问修饰符.
/*
注意:
1. Scala中可以使用private/protected来修饰成员.
2. 如果成员没有被private/protected修饰, 默认就是公共的(类似于Java中的public).
*/
object ClassDemo06 {
//1. 创建Customer类
class Customer {
//2. 定义成员变量, 全部私有化
private var name = "" //姓名
private var age = 0 //年龄
//3. 定义成员方法
//获取姓名
def getName() = name
//设置姓名
def setName(name: String) = this.name = name
//获取年龄
def getAge() = age
//设置年龄
def setAge(age: Int) = this.age = age
//打招呼的方法, 该方法需要私有化.
private def sayHello() = println("Hello, Scala!")
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//4. 创建Customer类型的对象.
val c = new Customer
//5. 给成员变量赋值
//c.name = "张三" //这样写会报错, 因为私有成员外界无法直接访问.
c.setName("张三")
c.setAge(23)
//6. 打印成员变量值到控制台上
println(c.getName(), c.getAge())
//7. 尝试调用私有成员方法
//c.sayHello() //这样写会报错, 因为私有成员外界无法直接访问.
}
}
6. 类的构造器
当创建对象的时候,会自动调用类的构造器。之前使用的都是默认构造器,接下来我们要学习如何自定义构造器。
6.1 分类
- 主构造器
- 辅助构造器
6.2 主构造器
语法
class 类名(var/val 参数名:类型 = 默认值, var/val 参数名:类型 = 默认值){
//构造代码块
}
注意:
- 主构造器的参数列表直接定义在类名后面,添加了val/var表示直接通过主构造器定义成员变量
- 构造器参数列表可以指定默认值
- 创建实例,调用构造器可以指定字段进行初始化
- 整个class中除了字段定义和方法定义的代码都是构造代码
示例
- 定义一个Person类,通过主构造器参数列表定义姓名和年龄字段,并且设置它们的默认值为张三, 23
- 在主构造器中输出"调用主构造器"
- 创建"李四"对象(姓名为李四,年龄为24),打印对象的姓名和年龄
- 创建"空"对象,不给构造器传入任何的参数,打印对象的姓名和年龄
- 创建"测试"对象,不传入姓名参数,仅指定年龄为30,打印对象的姓名和年龄
参考代码
//案例: 演示Scala中的类的主构造器.
/*
注意:
1. Scala中主构造器的参数列表是直接写在类名后的.
2. 主构造器的参数列表可以有默认值.
3. 调用主构造器创建对象时, 可以指定参数赋值.
4. 整个类中除了定义成员变量和成员方法的代码, 其他都叫: 构造代码.
*/
object ClassDemo07 {
//1. 创建person类, 主构造器参数列表为: 姓名和年龄.
class Person(val name: String = "张三", val age: Int = 23) { //这里应该用var修饰.
//2. 在主构造器中输出"调用主构造器"
println("调用主构造器!...")
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 创建"空"对象, 什么都不传.
val p1 = new Person()
println(s"p1: ${p1.name}...${p1.age}")
//4. 创建"李四"对象, 传入姓名和年龄
val p2 = new Person("李四", 24)
println(s"p2: ${p2.name}...${p2.age}")
//5. 创建测试对象, 仅传入年龄.
val p3 = new Person(age = 30)
println(s"p3: ${p3.name}...${p3.age}")
}
}
6.2 辅助构造器
在scala中,除了定义主构造器外,还可以根据需要来定义辅助构造器。例如:允许通过多种方式,来创建对象,这时候就可以定义其他更多的构造器。我们把除了主构造器之外的构造器称为辅助构造器。
语法
- 定义辅助构造器与定义方法一样,也使用
def关键字来定义 - 辅助构造器的默认名字都是
this, 且不能修改.
def this(参数名:类型, 参数名:类型) {
// 第一行需要调用主构造器或者其他构造器
// 构造器代码
}
注意: 辅助构造器的第一行代码,必须要调用主构造器或者其他辅助构造器
示例
需求
- 定义一个Customer类,包含一个姓名和地址字段
- 定义Customer类的主构造器(初始化姓名和地址)
- 定义Customer类的辅助构造器,该辅助构造器接收一个数组参数,使用数组参数来初始化成员变量
- 使用Customer类的辅助构造器来创建一个"张三"对象
- 姓名为张三
- 地址为北京
- 打印对象的姓名、地址
注意:
- 该案例涉及到"数组"相关的知识点, 目前我们还没有学习到.
- Scala中的数组和Java中的数组用法基本类似, 目前能看懂即可, 后续会详细讲解.
参考代码
//案例: 演示Scala中的类的辅助构造器.
object ClassDemo08 {
//1. 创建Customer类, 主构造器参数列表为: 姓名和地址.
class Customer(var name: String, var address: String) { //这里应该用var修饰.
//2. 定义一个辅助构造器, 接收一个数组参数
def this(arr:Array[String]) {
this(arr(0), arr(1)) //将数组的前两个元素分别传给主构造器的两个参数.
}
}
//定义main函数, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 调用辅助构造器, 创建Customer对象.
val c = new Customer(Array("张三", "北京"))
//4. 打印结果.
println(c.name, c.address)
}
}
7. 单例对象
scala中是没有static关键字的,要想定义类似于Java中的static变量、static方法,就要使用到scala中的单例对象了, 也就是object.
7.1 定义单例对象
单例对象表示全局仅有一个对象, 也叫孤立对象. 定义单例对象和定义类很像,就是把class换成object.
格式
object 单例对象名{ } //定义一个单例对象.
注意:
在object中定义的成员变量类似于Java中的静态变量, 在内存中都只有一个对象.
在单例对象中, 可以直接使用
单例对象名.的形式调用成员.
示例
需求
- 定义一个Dog单例对象,保存狗有几条腿
- 在main方法中打印狗腿的数量
参考代码
//案例: 演示Scala中的单例对象之定义和访问成员变量.
object ClassDemo09 {
//1. 定义单例对象Dog
object Dog {
//2. 定义一个变量, 用来存储狗腿子的数量
val leg_num = 4
}
//定义main方法, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 打印狗腿子的数量
println(Dog.leg_num)
}
}
7.2 在单例对象中定义方法
在单例对象中定义的成员方法类似于Java中的静态方法.
示例
需求
- 设计一个单例对象,定义一个能够打印分割线(15个减号)的方法
- 在main方法调用该方法,打印分割线
参考代码
//案例: 演示Scala中的单例对象之定义和访问成员方法.
object ClassDemo10 {
//1. 定义单例对象PrintUtil
object PrintUtil {
//2. 定义一个方法, 用来打印分割线
def printSpliter() = println("-" * 15)
}
//定义main方法, 它是程序的主入口.
def main(args: Array[String]): Unit = {
//3. 调用单例对象中的成员方法
PrintUtil.printSpliter()
}
}
8. main方法
scala和Java一样,如果要运行一个程序,必须有一个main方法。在Java中main方法是静态的,而在scala中没有静态方法。所以在scala中,这个main方法必须放在一个单例对象中。
8.1 定义main方法
main方法
def main(args:Array[String]):Unit = {
// 方法体
}
示例
需求
- 创建一个单例对象,在该单例对象中打印"hello, scala"
参考代码
object Main5 {
def main(args:Array[String]) = {
println("hello, scala")
}
}
8.2 继承App特质
创建一个object, 继承自App特质(Trait),然后将需要编写在main方法中的代码,写在object的构造方法体内。
object 单例对象名 extends App {
// 方法体
}
示例
需求
- 继承App特质,来实现一个入口。同样输出"hello, scala"
参考代码
object Main5 extends App {
println("hello, scala")
}
9. 伴生对象
在Java中,经常会有一些类,同时有实例成员又有静态成员。例如:
public class Generals {
private static String armsName = "青龙偃月刀";
public void toWar() {
//打仗
System.out.println("武将拿着"+ armsName +", 上阵杀敌!");
}
public static void main(String[] args) {
new Generals().toWar();
}
}
在scala中,要实现类似的效果,可以使用伴生对象来实现。
9.1 定义伴生对象
一个class和object具有同样的名字。这个object称为伴生对象,这个class称为伴生类
- 伴生对象必须要和伴生类一样的名字
- 伴生对象和伴生类在同一个scala源文件中
- 伴生对象和伴生类可以互相访问private属性
示例
需求
-
编写一个Generals类,有一个toWar方法,打印
武将拿着**武器, 上阵杀敌! //注意: **表示武器的名字. -
编写一个Generals伴生对象,定义一个私有变量,用于保存武器名称.
-
创建Generals对象,调用toWar方法
参考代码
//案例: 演示Scala中的伴生对象
object ClassDemo12 {
//1. 定义一个类Generals, 作为一个伴生类.
class Generals { //这里写的都是非静态成员.
//2. 定义一个toWar()方法, 输出一句话, 格式为"武将拿着**武器, 上阵杀敌!"
def toWar() = println(s"武将拿着${Generals.armsName}武器, 上阵杀敌!")
}
//3. 定义一个伴生对象, 用来保存"武将的武器".
object Generals { //这里写的都是静态成员.
private var armsName = "青龙偃月刀"
}
//定义main方法, 作为程序的主入口
def main(args: Array[String]): Unit = {
//4. 创建Generals类的对象.
val g = new Generals
//5. 调用Generals类中的toWar方法
g.toWar()
}
}
9.2 private[this]访问权限
如果某个成员的权限设置为private[this],表示只能在当前类中访问。伴生对象也不可以访问.
示例
示例说明
- 定义一个Person类,包含一个name字段, 该字段用private[this]修饰
- 定义Person类的伴生对象,定义printPerson方法
- 测试伴生对象是否能访问private[this]权限的成员
示例代码
//案例: 测试private[this]的访问权限
object ClassDemo13 {
//1. 定义一个Person类, 属性为: name
class Person(private[this] var name: String)
//2. 定义Person类的伴生对象.
object Person {
//3. 定义一个方法printPerson, 用来打印Person#name属性值.
def printPerson(p:Person) = println(p.name)
}
//定义main函数, 它是程序的主入口
def main(args: Array[String]) = {
//4. 创建Person类型的对象.
val p = new Person("张三")
//5. 调用Person伴生对象中的printPerson方法
Person.printPerson(p)
}
}
注意: 上述代码,会编译报错。但移除掉[this]就可以访问了
9.3 apply方法
在Scala中, 支持创建对象的时候, 免new的动作, 这种写法非常简便,优雅。要想实现免new, 我们就要通过伴生对象的apply方法来实现。
9.3.1 格式
定义apply方法的格式
object 伴生对象名 {
def apply(参数名:参数类型, 参数名:参数类型...) = new 类(...)
}
创建对象
val 对象名 = 伴生对象名(参数1, 参数2...)
例如: val p = Person(“张三”, 23)
9.3.2 示例
需求
- 定义一个Person类,它包含两个字段:姓名和年龄
- 在伴生对象中定义apply方法,实现创建Person对象的免new操作.
- 在main方法中创建该类的对象,并打印姓名和年龄
参考代码
//案例: 演示Scala中的apply方法
object ClassDemo14 {
//1. 定义Person类, 属性为姓名和年龄
class Person(var name: String = "", var age: Int = 0)
//2. 定义Person类的伴生对象.
object Person {
//3. 定义apply方法, 实现创建Person对象的时候免new.
def apply(name:String, age:Int) = new Person(name, age)
}
//定义main方法, 作为程序的主入口
def main(args: Array[String]): Unit = {
//4. 创建Person类型的对象.
val p = Person("张三", 23)
//5. 打印Person对象的属性值.
println(p.name, p.age)
}
}
10. 案例: 定义工具类
10.1 概述
Scala中工具类的概念和Java中是一样的, 都是
1. 构造方法全部私有化, 目的是不让外界通过构造方法来创建工具类的对象.
2. 成员全部是静态化, 意味着外界可以通过"类名."的形式来访问工具类中的内容.
综上所述, 在Scala中只有
object单例对象满足上述的要求.
10.2 示例
需求
- 编写一个DateUtils工具类专门用来格式化日期时间
- 定义一个方法,用于将日期(Date)转换为年月日字符串,例如:2030-10-05
- 定义一个方法, 用于将年月日字符串转换为日期(Date).
步骤
- 定义一个DateUtils单例对象
- 在DateUtils中定义日期格式化方法(date2String)和解析字符串方法(string2Date)
- 使用SimpleDateFormat来实现String和Date之间的相互转换
参考代码
//案例: 定义DateUtils工具类, 用于实现String和Date之间的相互转换.
object ClassDemo15 {
//1. 定义DateUtils工具类. //也就是Scala中的单例对象.
object DateUtils {
//2. 创建SimpleDateFormat类型的对象, 用来进行转换操作.
var sdf: SimpleDateFormat = null
//3. 定义方法date2String, 用来将Date日期对象转换成String类型的日期.
//参数1: 日期对象, 参数2: 模板
def date2String(date: Date, template: String):String = {
sdf = new SimpleDateFormat(template)
sdf.format(date)
}
//4. 定义方法string2Date, 用于将String类型的日期转换成Date日期对象.
def string2Date(dateString: String, template: String) = {
sdf = new SimpleDateFormat(template)
sdf.parse(dateString)
}
}
//定义main方法, 作为程序的主入口.
def main(args: Array[String]): Unit = {
//5. 调用DateUtils#date2String()方法, 用来格式化日期.
val s = DateUtils.date2String(new Date(), "yyyy-MM-dd")
println("格式化日期: " + s)
//6. 调用DateUtils#string2Date()方法, 用来解析日期字符串.
val d = DateUtils.string2Date("1314年5月21日", "yyyy年MM月dd日")
println("解析字符串: " + d)
}
}
Scala第七章节
章节目标
- 掌握继承和抽象类相关知识点
- 掌握匿名内部类的用法
- 了解类型转换的内容
- 掌握动物类案例
1. 继承
1.1 概述
实际开发中, 我们发现好多类中的内容是相似的(例如: 相似的属性和行为), 每次写很麻烦. 于是我们可以把这些相似的内容提取出来单独的放到一个类中(父类), 然后让那多个类(子类)和这个类(父类)产生一个关系, 从而实现子类可以访问父类的内容, 这个关系就叫: 继承.
因为scala语言是支持面向对象编程的,我们也可以使用scala来实现继承,通过继承来减少重复代码。
1.2 语法
- scala中使用extends关键字来实现继承
- 可以在子类中定义父类中没有的字段和方法,或者重写父类的方法
- 类和单例对象都可以有父类
语法
class/object A类 extends B类 {
..
}
叫法
- 上述格式中, A类称之为: 子类, 派生类.
- B类称之为: 父类, 超类, 基类.
1.3 类继承
需求
已知学生类(Student)和老师类(Teacher), 他们都有姓名和年龄(属性), 都要吃饭(行为), 请用所学, 模拟该需求.
- 方式一: 非继承版.
object ClassDemo01 {
//1. 定义老师类.
class Teacher{
var name = ""
var age = 0
def eat() = println("老师喝牛肉汤!...")
}
//2. 定义学生类.
class Student{
var name = ""
var age = 0
def eat() = println("学生吃牛肉!...")
}
//main方法, 程序的主入口
def main(args: Array[String]): Unit = {
//3. 测试老师类.
//3.1 创建对象.
val t = new Teacher
//3.2 给属性赋值
t.name = "刘老师"
t.age = 32
//3.3 打印属性值.
println(t.name, t.age)
//3.4 调用方法
t.eat()
println("-" * 15)
//4. 测试学生类.
val s = new Student
s.name = "张三"
s.age = 21
println(s.name, s.age)
s.eat()
}
}
- 方式二: 继承版
object ClassDemo02 {
//1. 定义人类.
class Person {
var name = ""
var age = 0
def eat() = println("人要吃饭!...")
}
//2. 定义老师类.
class Teacher extends Person
//3. 定义学生类.
class Student extends Person
def main(args: Array[String]): Unit = {
//4. 测试老师类.
val t = new Teacher
t.name = "刘老师"
t.age = 32
println(t.name, t.age)
t.eat()
println("-" * 15)
//5. 测试学生类.
val s = new Student
s.name = "张三"
s.age = 23
println(s.name, s.age)
s.eat()
}
}
1.4 单例对象继承
在Scala中, 单例对象也是可以继承类的.
需求
定义Person类(成员变量: 姓名, 成员方法: sayHello()), 定义单例对象Student继承自Person, 然后测试.
object ClassDemo03 {
//1. 定义Person类.
class Person {
var name = ""
def sayHello() = println("Hello, Scala!..")
}
//2. 定义单例对象Student, 继承Person.
object Student extends Person
//main方法, 程序的主入口
def main(args: Array[String]): Unit = {
//3. 测试Student中的成员.
Student.name = "张三"
println(Student.name)
Student.sayHello()
}
}
1.5 方法重写
1.5.1 概述
子类中出现和父类一模一样的方法时, 称为方法重写. Scala代码中可以在子类中使用override来重写父类的成员,也可以使用super来引用父类的成员.
1.5.2 注意事项
-
子类要重写父类中的某一个方法,该方法必须要使用override关键字来修饰
-
可以使用override来重写一个val字段.
注意: 父类用var修饰的变量, 子类不能重写.
-
使用super关键字来访问父类的成员方法
1.5.3 示例
需求
定义Person类, 属性(姓名, 年龄), 有一个sayHello()方法.
然后定义Student类继承Person类, 重写Person类中的字段和方法, 并测试.
参考代码
object ClassDemo04 {
//1. 定义父类Person.
class Person {
var name = "张三"
val age = 23
def sayHello() = println("Hello, Person!...")
}
//2. 定义子类Student, 继承Person.
class Student extends Person{
//override var name = "李四" //这样写会报错, 子类不能重写父类用var修饰的变量.
override val age = 24
override def sayHello() = {
//通过super调用父类的成员.
super.sayHello()
println("Hello, Student!...")
}
}
//程序的入口.
def main(args: Array[String]): Unit = {
//3. 创建学生类型的对象, 然后测试.
val s = new Student
println(s.name, s.age)
s.sayHello()
}
}
2. 类型判断
有时候,我们设计的程序,要根据变量的类型来执行对应的逻辑, 如下图:
在scala中,如何来进行类型判断呢?
有两种方式:
- isInstanceOf
- getClass/classOf
2.1 isInstanceOf, asInstanceOf
概述
- isInstanceOf: 判断对象是否为指定类的对象
- asInstanceOf: 将对象转换为指定类型
格式
// 判断对象是否为指定类型
val trueOrFalse:Boolean = 对象.isInstanceOf[类型]
// 将对象转换为指定类型
val 变量 = 对象.asInstanceOf[类型]
示例代码:
val trueOrFalse = p.isInstanceOf[Student]
val s = p.asInstanceOf[Student]
2.2 案例
需求
- 定义一个Person类
- 定义一个Student类继承自Person类, 该类有一个sayHello()方法.
- 创建一个Student类对象, 并指定它的类型为Person类型
- 判断该对象是否为Student类型,如果是,将其转换为Student类型并调用sayHello()方法.
参考代码
object ClassDemo05 {
//1. 定义一个Person类.
class Person
//2. 定义一个Student类, 继承Person.
class Student extends Person {
def sayHello() = println("Hello, Scala!...")
}
//main方法, 作为程序的主入口
def main(args: Array[String]): Unit = {
//3. 通过多态的形式创建Student类型的对象.
val p: Person = new Student
//s.sayHello() //这样写会报错, 因为多态的弊端是: 父类引用不能直接访问子类的特有成员.
//4. 判断其是否是Student类型的对象, 如果是, 将其转成Student类型的对象.
if (p.isInstanceOf[Student]) {
val s = p.asInstanceOf[Student]
//5. 调用Student#sayHello()方法
s.sayHello()
}
}
}
2.3 getClass和classOf
isInstanceOf 只能判断对象是否为指定类以及其子类的对象,而不能精确的判断出: 对象就是指定类的对象。如果要求精确地判断出对象的类型就是指定的数据类型,那么就只能使用 getClass 和 classOf 来实现.
用法
- p.getClass可以精确获取对象的类型
- classOf[类名]可以精确获取数据类型
- 使用==操作符可以直接比较类型
示例
示例说明
- 定义一个Person类
- 定义一个Student类继承自Person类
- 创建一个Student类对象,并指定它的类型为Person类型
- 测试使用isInstance判断该对象是否为Person类型
- 测试使用getClass/classOf判断该对象是否为Person类型
- 测试使用getClass/classOf判断该对象是否为Student类型
参考代码
object ClassDemo06 {
//1. 定义一个Person类.
class Person
//2. 定义一个Student类, 继承自Person类.
class Student extends Person
def main(args: Array[String]): Unit = {
//3. 创建Student类型的对象, 指定其类型为Person.
val p:Person = new Student
//4. 通过isInstanceOf关键字判断其是否是Person类型的对象.
println(p.isInstanceOf[Person]) //true,
//5. 通过isInstanceOf关键字判断其是否是Person类型的对象.
println(p.isInstanceOf[Student]) //true
//6. 通过getClass, ClassOf判断其是否是Person类型的对象.
println(p.getClass == classOf[Person]) //false
//7. 通过getClass, ClassOf判断其是否是Student类型的对象.
println(p.getClass == classOf[Student]) //true
}
}
3. 抽象类
scala语言是支持抽象类的, , 通过abstract关键字来实现.
3.1 定义
如果类中有抽象字段或者抽象方法, 那么该类就应该是一个抽象类.
- 抽象字段: 没有初始化值的变量就是抽象字段.
- 抽象方法: 没有方法体的方法就是一个抽象方法.
3.2 格式
// 定义抽象类
abstract class 抽象类名 {
// 定义抽象字段
val/var 抽象字段名:类型
// 定义抽象方法
def 方法名(参数:参数类型,参数:参数类型...):返回类型
}
3.3 抽象方法案例
需求
在这里插入图片描述
- 设计4个类,表示上述图中的继承关系
- 每一个形状都有自己求面积的方法,但是不同的形状计算面积的方法不同
步骤
- 创建一个Shape抽象类,添加一个area抽象方法,用于计算面积
- 创建一个Square正方形类,继承自Shape,它有一个边长的主构造器,并实现计算面积方法
- 创建一个长方形类,继承自Shape,它有一个长、宽的主构造器,实现计算面积方法
- 创建一个圆形类,继承自Shape,它有一个半径的主构造器,并实现计算面积方法
- 编写main方法,分别创建正方形、长方形、圆形对象,并打印它们的面积
参考代码
// 创建形状抽象类
abstract class Shape {
def area:Double
}
// 创建正方形类
class Square(var edge:Double /*边长*/) extends Shape {
// 实现父类计算面积的方法
override def area: Double = edge * edge
}
// 创建长方形类
class Rectangle(var length:Double /*长*/, var width:Double /*宽*/) extends Shape {
override def area: Double = length * width
}
// 创建圆形类
class Circle(var radius:Double /*半径*/) extends Shape {
override def area: Double = Math.PI * radius * radius
}
object ClassDemo07 {
def main(args: Array[String]): Unit = {
val s1:Shape = new Square(2)
val s2:Shape = new Rectangle(2,3)
val s3:Shape = new Circle(2)
println(s1.area)
println(s2.area)
println(s3.area)
}
}
3.4 抽象字段
在scala的抽象类中,不仅可以定义抽象方法, 也可以定义抽象字段。如果一个成员变量是没有初始化,我们就认为它是抽象的。
语法
abstract class 抽象类 {
val/var 抽象字段:类型
}
示例
示例说明
- 创建一个Person抽象类,它有一个String抽象字段occupation
- 创建一个Student类,继承自Person类,重写occupation字段,初始化为学生
- 创建一个Teacher类,继承自Person类,重写occupation字段,初始化为老师
- 添加main方法,分别创建Student/Teacher的实例,然后分别打印occupation
参考代码
object ClassDemo08 {
//1. 定义抽象类Person, 有一个抽象字段occupation(职业)
abstract class Person {
val occupation:String
}
//2. 定义Student类继承Person, 重写抽象字段occupation.
class Student extends Person{
override val occupation: String = "学生"
}
//3. 定义Teacher类继承Person, 重写抽象字段occupation.
class Teacher extends Person{
override val occupation: String = "老师"
}
//main方法, 作为程序的主入口
def main(args: Array[String]): Unit = {
//4. 创建Student类的对象, 打印occupation的值.
val s = new Student
println(s.occupation)
//5. 创建Teacher类的对象, 打印occupation的值.
val t = new Teacher
println(t.occupation)
}
}
4. 匿名内部类
匿名内部类是继承了类的匿名的子类对象,它可以直接用来创建实例对象。Spark的源代码中大量使用到匿名内部类。学完这个内容, 对我们查看Spark的底层源码非常有帮助.
4.1 语法
new 类名() {
//重写类中所有的抽象内容
}
注意: 上述格式中, 如果的类的主构造器参数列表为空, 则小括号可以省略不写.
4.2 使用场景
- 当对对象方法(成员方法)仅调用一次的时候.
- 可以作为方法的参数进行传递.
4.3 示例
需求
- 创建一个Person抽象类,并添加一个sayHello抽象方法
- 定义一个show()方法, 该方法需要传入一个Person类型的对象, 然后调用Person类中的sayHello()方法.
- 添加main方法,通过匿名内部类的方式来创建Person类的子类对象, 调用Person类的sayHello()方法.
- 调用show()方法.
参考代码
object ClassDemo09 {
//1. 定义Person类, 里边有一个抽象方法: sayHello()
abstract class Person{
def sayHello()
}
//2. 定义一个show()方法, 该方法需要传入一个Person类型的对象.
def show(p:Person) = p.sayHello()
//main方法是程序的主入口
def main(args: Array[String]): Unit = {
//3. 通过匿名内部类创建Person的子类对象, 并调用sayHello()方法.
new Person {
override def sayHello(): Unit = println("Hello, Scala, 当对成员方法仅调用一次的时候.")
}.sayHello()
//4. 演示: 匿名内部类可以作为方法的参数进行传递.
val p = new Person {
override def sayHello(): Unit = println("Hello, Scala, 可以作为方法的实际参数进行传递")
}
show(p)
}
}
5. 案例: 动物类
5.1 需求
已知有猫类和狗类, 它们都有姓名和年龄, 都会跑步, 而且仅仅是跑步, 没有什么不同. 它们都有吃饭的功能, 不同的是猫吃鱼, 狗吃肉. 而且猫类独有自己的抓老鼠功能, 狗类独有自己的看家功能, 请用所学模拟该需求.
5.2 目的
- 考察
继承, 抽象类, 类型转换这些知识点.
5.3 步骤
- 定义抽象动物类(Animal), 属性: 姓名, 年龄, 行为: 跑步, 吃饭.
- 定义猫类(Cat)继承自动物类, 重写吃饭的方法, 并定义该类独有的抓老鼠的方法.
- 定义狗类(Dog)继承自动物类, 重写吃饭的方法, 并定义该类独有的看家的方法.
5.4 参考代码
object ClassDemo10 {
//1. 定义抽象动物类(Animal), 属性: 姓名, 年龄, 行为: 跑步, 吃饭.
abstract class Animal{
//1.1 属性
var name = ""
var age = 0
//1.2 行为
def run() = println("动物会跑步!...")
//吃饭的方法.
def eat():Unit
}
//2. 定义猫类(Cat)继承自动物类, 重写吃饭的方法, 并定义该类独有的抓老鼠的方法.
class Cat extends Animal {
//2.1 重写父类的抽象方法
override def eat(): Unit = println("猫吃鱼")
//2.2 定义自己的独有方法
def catchMouse() = println("猫会抓老鼠")
}
//3. 定义狗类(Dog)继承自动物类, 重写吃饭的方法, 并定义该类独有的看家的方法.
class Dog extends Animal {
//3.1 重写父类的抽象方法
override def eat(): Unit = println("狗吃肉")
//3.2 定义自己的独有方法
def lookHome() = println("狗会看家")
}
//main方法, 作为程序的入口
def main(args: Array[String]): Unit = {
//4. 测试猫类.
//4.1 创建猫类对象.
val c = new Cat
//4.2 给成员变量赋值.
c.name = "汤姆"
c.age = 13
//4.3 打印成员变量值
println(c.name, c.age)
//4.4 调用方法.
c.eat()
//4.5 调用猫类的独有功能: 抓老鼠
if (c.isInstanceOf[Cat]) {
val cat = c.asInstanceOf[Cat]
cat.catchMouse()
} else if(c.isInstanceOf[Dog]) {
val dog = c.asInstanceOf[Dog]
dog.lookHome()
} else{
println("您传入的不是猫类, 也不是狗类对象")
}
//5. 测试狗类, 自己完成.
}
}
Scala第八章节
章节目标
- 能够使用trait独立完成适配器, 模板方法, 职责链设计模式
- 能够独立叙述trait的构造机制
- 能够了解trait继承class的写法
- 能够独立完成程序员案例
1. 特质入门
1.1 概述
有些时候, 我们会遇到一些特定的需求, 即: 在不影响当前继承体系的情况下, 对某些类(或者某些对象)的功能进行加强, 例如: 有猴子类和大象类, 它们都有姓名, 年龄, 以及吃的功能, 但是部分的猴子经过马戏团的训练后, 学会了骑独轮车. 那骑独轮车这个功能就不能定义到父类(动物类)或者猴子类中, 而是应该定义到特质中. 而Scala中的特质, 要用关键字trait修饰.
1.2 特点
-
特质可以提高代码的复用性.
-
特质可以提高代码的扩展性和可维护性.
-
类与特质之间是继承关系, 只不过类与类之间只支持
单继承, 但是类与特质之间,既可以单继承, 也可以多继承. -
Scala的特质中可以有普通字段, 抽象字段, 普通方法, 抽象方法.
注意:
- 如果特质中只有抽象内容, 这样的特质叫: 瘦接口.
- 如果特质中既有抽象内容, 又有具体内容, 这样的特质叫: 富接口.
1.3 语法
定义特质
trait 特质名称 {
// 普通字段
// 抽象字段
// 普通方法
// 抽象方法
}
继承特质
class 类 extends 特质1 with 特质2 {
// 重写抽象字段
// 重写抽象方法
}
注意
- scala中不管是类还是特质, 继承关系用的都是
extends关键字 - 如果要继承多个特质(trait),则特质名之间使用
with关键字隔开
1.4 示例: 类继承单个特质
需求
- 创建一个Logger特质,添加
log(msg:String)方法 - 创建一个ConsoleLogger类,继承Logger特质,实现log方法,打印消息
- 添加main方法,创建ConsoleLogger对象,调用log方法.
参考代码
//案例: Trait入门之类继承单个特质
object ClassDemo01 {
//1. 定义一个特质.
trait Logger {
def log(msg:String) //抽象方法
}
//2. 定义一个类, 继承特质.
class ConsoleLogger extends Logger {
override def log(msg: String): Unit = println(msg)
}
def main(args: Array[String]): Unit = {
//3. 调用类中的方法
val cl = new ConsoleLogger
cl.log("trait入门: 类继承单个特质")
}
}
1.5 示例: 类继承多个trait
需求
- 创建一个MessageSender特质,添加
send(msg:String)方法 - 创建一个MessageReceiver特质,添加
receive()方法 - 创建一个MessageWorker类, 继承这两个特质, 重写上述的两个方法
- 在main中测试,分别调用send方法、receive方法
参考代码
//案例: 类继承多个trait
object ClassDemo02 {
//1. 定义一个特质: MessageSender, 表示发送信息.
trait MessageSender {
def send(msg:String)
}
//2. 定义一个特质: MessageReceiver, 表示接收信息.
trait MessageReceiver {
def receive()
}
//3. 定义一个类MessageWorker, 继承两个特质.
class MessageWorker extends MessageSender with MessageReceiver {
override def send(msg: String): Unit = println("发送消息: " + msg)
override def receive(): Unit = println("消息已收到, 我很好, 谢谢!...")
}
//main方法, 作为程序的主入口
def main(args: Array[String]): Unit = {
//4. 调用类中的方法
val mw = new MessageWorker
mw.send("Hello, 你好啊!")
mw.receive()
}
}
1.6 示例: object继承trait
需求
- 创建一个Logger特质,添加
log(msg:String)方法 - 创建一个Warning特质, 添加
warn(msg:String)方法 - 创建一个单例对象ConsoleLogger,继承Logger和Warning特质, 重写特质中的抽象方法
- 编写main方法,调用单例对象ConsoleLogger的log和warn方法
参考代码
//案例: 演示object单例对象继承特质
object ClassDemo03 {
//1. 定义一个特质Logger, 添加log(msg:String)方法.
trait Logger{
def log(msg:String)
}
//2. 定义一个特质Warning, 添加warn(msg:String)方法.
trait Warning{
def warn(msg:String)
}
//3. 定义单例对象ConsoleLogger, 继承上述两个特质, 并重写两个方法.
object ConsoleLogger extends Logger with Warning{
override def log(msg: String): Unit = println("控制台日志信息: " + msg)
override def warn(msg: String): Unit = println("控制台警告信息: " + msg)
}
//main方法, 作为程序的入口
def main(args: Array[String]): Unit = {
//4. 调用ConsoleLogger单例对象中的两个方法.
ConsoleLogger.log("我是一条普通日志信息!")
ConsoleLogger.warn("我是一条警告日志信息!")
}
}
1.7 示例: 演示trait中的成员
需求
- 定义一个特质Hero, 添加具体字段name(姓名), 抽象字段arms(武器), 具体方法eat(), 抽象方法toWar()
- 定义一个类Generals, 继承Hero特质, 重写其中所有的抽象成员.
- 在main方法中, 创建Generals类的对象, 调用其中的成员.
参考代码
//案例: 演示特质中的成员
object ClassDemo04 {
//1. 定义一个特质Hero
trait Hero{
var name = "" //具体字段
var arms:String //抽象字段
//具体方法
def eat() = println("吃肉喝酒, 养精蓄锐!")
//抽象方法
def toWar():Unit
}
//2. 定义一个类Generals, 继承Hero特质, 重写其中所有的抽象成员.
class Generals extends Hero {
//重写父特质中的抽象字段
override var arms: String = ""
//重写父特质中的抽象方法
override def toWar(): Unit = println(s"${name}带着${arms}, 上阵杀敌!")
}
//main方法, 作为程序的入口
def main(args: Array[String]): Unit = {
//3. 创建Generals类的对象.
val gy = new Generals
//4. 测试Generals类中的内容.
//给成员变量赋值
gy.name = "关羽"
gy.arms = "青龙偃月刀"
//打印成员变量值
println(gy.name, gy.arms)
//调用成员方法
gy.eat()
gy.toWar()
}
}
2. 对象混入trait
有些时候, 我们希望在不改变类继承体系的情况下, 对对象的功能进行临时增强或者扩展, 这个时候就可以考虑使用对象混入技术了. 所谓的对象混入指的就是: 在scala中, 类和特质之间无任何的继承关系, 但是通过特定的关键字, 却可以让该类对象具有指定特质中的成员.
2.1 语法
val/var 对象名 = new 类 with 特质
2.2 示例
需求
- 创建Logger特质, 添加log(msg:String)方法
- 创建一个User类, 该类和Logger特质之间无任何关系.
- 在main方法中测试, 通过对象混入技术让User类的对象具有Logger特质的log()方法.
参考代码
//案例: 演示动态混入
object ClassDemo05 {
//1. 创建Logger特质, 添加log(msg:String)方法
trait Logger {
def log(msg:String) = println(msg)
}
//2. 创建一个User类, 该类和Logger特质之间无任务关系.
class User
//main方法, 作为程序的入口
def main(args: Array[String]): Unit = {
//3. 在main方法中测试, 通过对象混入技术让User类的对象具有Logger特质的log()方法.
val c1 = new User with Logger //对象混入
c1.log("我是User类的对象, 我可以调用Logger特质中的log方法了")
}
}
3. 使用trait实现适配器模式
3.1 设计模式简介
概述
设计模式(Design Pattern)是前辈们对代码开发经验的总结,是解决特定问题的一系列套路。它并不是语法规定,而是一套用来提高代码可复用性、可维护性、可读性、稳健性以及安全性的解决方案。
分类
设计模式一共有23种, 分为如下的3类:
-
创建型
指的是: 需要创建对象的. 常用的模式有: 单例模式, 工厂方法模式 -
结构型
指的是: 类,特质之间的关系架构. 常用的模式有: 适配器模式, 装饰模式 -
行为型
指的是: 类(或者特质)能够做什么. 常用的模式有:模板方法模式, 职责链模式
3.2 适配器模式
当特质中有多个抽象方法, 而我们只需要用到其中的某一个或者某几个方法时, 不得不将该特质中的所有抽象方法给重写了, 这样做很麻烦. 针对这种情况, 我们可以定义一个抽象类去继承该特质, 重写特质中所有的抽象方法, 方法体为空. 这时候, 我们需要使用哪个方法, 只需要定义类继承抽象类, 重写指定方法即可. 这个抽象类就叫: 适配器类. 这种设计模式(设计思想)就叫: 适配器设计模式.
结构
trait 特质A{
//抽象方法1
//抽象方法2
//抽象方法3
//...
}
abstract class 类B extends A{ //适配器类
//重写抽象方法1, 方法体为空
//重写抽象方法2, 方法体为空
//重写抽象方法3, 方法体为空
//...
}
class 自定义类C extends 类B {
//需要使用哪个方法, 重写哪个方法即可.
}
需求
-
定义特质PlayLOL, 添加6个抽象方法, 分别为: top(), mid(), adc(), support(), jungle(), schoolchild()
解释: top: 上单, mid: 中单, adc: 下路, support: 辅助, jungle: 打野, schoolchild: 小学生
-
定义抽象类Player, 继承PlayLOL特质, 重写特质中所有的抽象方法, 方法体都为空.
-
定义普通类GreenHand, 继承Player, 重写support()和schoolchild()方法.
-
定义main方法, 在其中创建GreenHand类的对象, 并调用其方法进行测试.
参考代码
//案例: 演示适配器设计模式.
object ClassDemo06 {
//1. 定义特质PlayLOL, 添加6个抽象方法, 分别为: top(), mid(), adc(), support(), jungle(), schoolchild()
trait PlayLOL {
def top() //上单
def mid() //中单
def adc() //下路
def support() //辅助
def jungle() //打野
def schoolchild() //小学生
}
//2. 定义抽象类Player, 继承PlayLOL特质, 重写特质中所有的抽象方法, 方法体都为空.
//Player类充当的角色就是: 适配器类.
class Player extends PlayLOL {
override def top(): Unit = {}
override def mid(): Unit = {}
override def adc(): Unit = {}
override def support(): Unit = {}
override def jungle(): Unit = {}
override def schoolchild(): Unit = {}
}
//3. 定义普通类GreenHand, 继承Player, 重写support()和schoolchild()方法.
class GreenHand extends Player{
override def support(): Unit = println("我是辅助, B键一扣, 不死不回城!")
override def schoolchild(): Unit = println("我是小学生, 你骂我, 我就挂机!")
}
//4. 定义main方法, 在其中创建GreenHand类的对象, 并调用其方法进行测试.
def main(args: Array[String]): Unit = {
//创建GreenHand类的对象
val gh = new GreenHand
//调用GreenHand类中的方法
gh.support()
gh.schoolchild()
}
}
4. 使用trait实现模板方法模式
在现实生活中, 我们会遇到论文模板, 简历模板, 包括PPT中的一些模板等, 而在面向对象程序设计过程中,程序员常常会遇到这种情况:设计一个系统时知道了算法所需的关键步骤,而且确定了这些步骤的执行顺序,但某些步骤的具体实现还未知,或者说某些步骤的实现与具体的环境相关。
例如,去银行办理业务一般要经过以下4个流程:取号、排队、办理具体业务、对银行工作人员进行评分等,其中取号、排队和对银行工作人员进行评分的业务对每个客户是一样的,可以在父类中实现,但是办理具体业务却因人而异,它可能是存款、取款或者转账等,可以延迟到子类中实现。这就要用到模板方法设计模式了.
4.1 概述
在Scala中, 我们可以先定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该算法结构的情况下重定义该算法的某些特定步骤, 这就是: 模板方法设计模式.
优点
-
扩展性更强.
父类中封装了公共的部分, 而可变的部分交给子类来实现. -
符合开闭原则。
部分方法是由子类实现的,因此子类可以通过扩展方式增加相应的功能.
缺点
-
类的个数增加, 导致系统更加庞大, 设计也更加抽象。
因为要对每个不同的实现都需要定义一个子类 -
提高了代码阅读的难度。
父类中的抽象方法由子类实现,子类执行的结果会影响父类的结果,这导致一种反向的控制结构.
4.2 格式
class A { //父类, 封装的是公共部分
def 方法名(参数列表) = { //具体方法, 在这里也叫: 模板方法
//步骤1, 已知.
//步骤2, 未知, 调用抽象方法
//步骤3, 已知.
//步骤n...
}
//抽象方法
}
class B extends A {
//重写抽象方法
}
注意: 抽象方法的个数要根据具体的需求来定, 并不一定只有一个, 也可以是多个.
4.3 示例
需求
- 定义一个模板类Template, 添加code()和getRuntime()方法, 用来获取某些代码的执行时间.
- 定义类ForDemo继承Template, 然后重写code()方法, 用来计算打印10000次"Hello,Scala!"的执行时间.
- 定义main方法, 用来测试代码的具体执行时间.
参考代码
//案例: 演示模板方法设计模式
object ClassDemo07 {
//1. 定义一个模板类Template, 添加code()和getRuntime()方法, 用来获取某些代码的执行时间.
abstract class Template {
//定义code()方法, 用来记录所有要执行的代码
def code()
//定义模板方法, 用来获取某些代码的执行时间.
def getRuntime() = {
//获取当前时间毫秒值
val start = System.currentTimeMillis()
//具体要执行的代码
code()
//获取当前时间毫秒值
val end = System.currentTimeMillis()
//返回指定代码的执行时间.
end - start
}
}
//2. 定义类ForDemo继承Template, 然后重写getRuntime()方法, 用来计算打印10000次"Hello,Scala!"的执行时间.
class ForDemo extends Template {
override def code(): Unit = for(i <- 1 to 10000) println("Hello, Scala!")
}
def main(args: Array[String]): Unit = {
//3. 测试打印10000次"Hello, Scala!"的执行时间
println(new ForDemo().getRuntime())
}
}
5 使用trait实现职责链模式
5.1 概述
多个trait中出现了同一个方法, 且该方法最后都调用了super.该方法名(), 当类继承了这多个trait后, 就可以依次调用多个trait中的此同一个方法了, 这就形成了一个调用链。
执行顺序为:
-
按照
从右往左的顺序依次执行.即首先会先从最右边的trait方法开始执行,然后依次往左执行对应trait中的方法 -
当所有子特质的该方法执行完毕后, 最后会执行父特质中的此方法.
这种设计思想就叫: 职责链设计模式.
注意: 在Scala中, 一个类继承多个特质的情况叫
叠加特质.
5.2 格式
trait A { //父特质
def show() //假设方法名叫: show
}
trait B extends A { //子特质, 根据需求可以定义多个.
override def show() = {
//具体的代码逻辑.
super.show()
}
}
trait C extends A {
override def show() = {
//具体的代码逻辑.
super.show()
}
}
class D extends B with C { //具体的类, 用来演示: 叠加特质.
def 方法名() = { //这里可以是该类自己的方法, 不一定非的是show()方法.
//具体的代码逻辑.
super.show() //这里就构成了: 调用链.
}
}
/*
执行顺序为:
1. 先执行类D中的自己的方法.
2. 再执行特质C中的show()方法.
3. 再执行特质B中的show()方法.
4. 最后执行特质A中的show()方法.
*/
5.3 示例
需求
通过Scala代码, 实现一个模拟支付过程的调用链.
解释:
我们如果要开发一个支付功能,往往需要执行一系列的验证才能完成支付。例如:
- 进行支付签名校验
- 数据合法性校验
- …
如果将来因为第三方接口支付的调整,需要增加更多的校验规则,此时如何不修改之前的校验代码,来实现扩展呢?
这就需要用到: 职责链设计模式了.
图解

步骤
- 定义一个Handler特质, 添加具体的handle(data:String)方法,表示处理数据(具体的支付逻辑)
- 定义一个DataValidHandler特质,继承Handler特质.
- 重写handle()方法,打印"验证数据", 然后调用父特质的handle()方法
- 定义一个SignatureValidHandler特质,继承Handler特质.
- 重写handle()方法, 打印"检查签名", 然后调用父特质的handle()方法
- 创建一个Payment类, 继承DataValidHandler特质和SignatureValidHandler特质
- 定义pay(data:String)方法, 打印"用户发起支付请求", 然后调用父特质的handle()方法
- 添加main方法, 创建Payment对象实例, 然后调用pay()方法.
参考代码
//案例: 演示职责链模式(也叫: 调用链模式)
object ClassDemo08 {
//1. 定义一个父特质 Handler, 表示处理数据(具体的支付逻辑)
trait Handler {
def handle(data:String) = {
println("具体处理数据的代码(例如: 转账逻辑)")
println(data)
}
}
//2. 定义一个子特质 DataValidHandler, 表示 校验数据.
trait DataValidHandler extends Handler {
override def handle(data:String) = {
println("校验数据...")
super.handle(data)
}
}
//3. 定义一个子特质 SignatureValidHandler, 表示 校验签名.
trait SignatureValidHandler extends Handler {
override def handle(data:String) = {
println("校验签名...")
super.handle(data)
}
}
//4. 定义一个类Payment, 表示: 用户发起的支付请求.
class Payment extends DataValidHandler with SignatureValidHandler {
def pay(data:String) = {
println("用户发起支付请求...")
super.handle(data)
}
}
def main(args: Array[String]): Unit = {
//5. 创建Payment类的对象, 模拟: 调用链.
val pm = new Payment
pm.pay("苏明玉给苏大强转账10000元")
}
}
// 程序运行输出如下:
// 用户发起支付请求...
// 校验签名...
// 校验数据...
// 具体处理数据的代码(例如: 转账逻辑)
// 苏明玉给苏大强转账10000元
6. trait的构造机制
6.1 概述
如果遇到一个类继承了某个父类且继承了多个父特质的情况,那该类(子类), 该类的父类, 以及该类的父特质之间是如何构造的呢?
要想解决这个问题, 就要用到接下来要学习的trait的构造机制了.
6.2 构造机制规则
-
每个特质只有**
一个无参数**的构造器。也就是说: trait也有构造代码,但和类不一样,特质不能有构造器参数. -
遇到一个类继承另一个类、以及多个trait的情况,当创建该类的实例时,它的构造器执行顺序如下:
- 执行父类的构造器
- 按照
从左到右的顺序, 依次执行trait的构造器 - 如果trait有父trait,则先执行父trait的构造器.
- 如果多个trait有同样的父trait,则父trait的构造器只初始化一次.
- 执行子类构造器
6.3 示例
需求
- 定义一个父类及多个特质,然后用一个类去继承它们.
- 创建子类对象, 并测试trait的构造顺序
步骤
- 创建Logger特质,在构造器中打印"执行Logger构造器!"
- 创建MyLogger特质,继承自Logger特质,,在构造器中打印"执行MyLogger构造器!"
- 创建TimeLogger特质,继承自Logger特质,在构造器中打印"执行TimeLogger构造器!"
- 创建Person类,在构造器中打印"执行Person构造器!"
- 创建Student类,继承Person类及MyLogger, TimeLogge特质,在构造器中打印"执行Student构造器!"
- 添加main方法,创建Student类的对象,观察输出。
参考代码
//案例: 演示trait的构造机制.
object ClassDemo09 {
//1. 创建Logger父特质
trait Logger {
println("执行Logger构造器")
}
//2. 创建MyLogger子特质, 继承Logger特质
trait MyLogger extends Logger {
println("执行MyLogger构造器")
}
//3. 创建TimeLogger子特质, 继承Logger特质.
trait TimeLogger extends Logger {
println("执行TimeLogger构造器")
}
//4. 创建父类Person
class Person{
println("执行Person构造器")
}
//5. 创建子类Student, 继承Person类及TimeLogger和MyLogger特质.
class Student extends Person with TimeLogger with MyLogger {
println("执行Student构造器")
}
//main方法, 程序的入口.
def main(args: Array[String]): Unit = {
//6. 创建Student类的对象,观察输出。
new Student
}
}
// 程序运行输出如下:
// 执行Person构造器
// 执行Logger构造器
// 执行TimeLogger构造器
// 执行MyLogger构造器
// 执行Student构造器
7. trait继承class
7.1 概述
在Scala中, trait(特质)也可以继承class(类)。特质会将class中的成员都继承下来。
7.2 格式
class 类A { //类A
//成员变量
//成员方法
}
trait B extends A { //特质B
}
7.3 示例
需求
- 定义Message类. 添加printMsg()方法, 打印"学好Scala, 走到哪里都不怕!"
- 创建Logger特质,继承Message类.
- 定义ConsoleLogger类, 继承Logger特质.
- 在main方法中, 创建ConsoleLogger类的对象, 并调用printMsg()方法.
参考代码
//案例: 演示特质继承类
object ClassDemo10 {
//1. 定义Message类. 添加printMsg()方法, 打印"测试数据..."
class Message {
def printMsg() = println("学好Scala, 走到哪里都不怕!")
}
//2. 创建Logger特质,继承Message类.
trait Logger extends Message
//3. 定义ConsoleLogger类, 继承Logger特质.
class ConsoleLogger extends Logger
def main(args: Array[String]): Unit = {
//4. 创建ConsoleLogger类的对象, 并调用printMsg()方法.
val cl = new ConsoleLogger
cl.printMsg()
}
}
8. 案例: 程序员
8.1 需求
现实生活中有很多程序员, 例如: Python程序员, Java程序员, 他们都有姓名和年龄, 都要吃饭, 都有自己所掌握的技能(skill). 不同的是, 部分的Java程序员和Python程序员来黑马程序员培训学习后, 掌握了大数据技术, 实现更好的就业. 请用所学, 模拟该场景.
8.2 目的
-
考察
特质, 抽象类的相关内容简单记忆: 整个继承体系的共性内容定义到父类中, 整个继承体系的扩展内容定义到父特质中.
8.3 分析

8.4 参考代码
//案例: 程序员案例
object ClassDemo11 {
//1. 定义程序员类Programmer.
abstract class Programmer {
//属性: 姓名和年龄
var name = ""
var age = 0
//行为: 吃饭和技能
def eat()
def skill()
}
//2. 定义特质BigData.
trait BigData {
def learningBigData() = {
println("来到黑马程序员之后: ")
println("我学会了: Hadoop, Zookeeper, HBase, Hive, Sqoop, Scala, Spark, Flink等技术")
println("我学会了: 企业级360°全方位用户画像, 千亿级数据仓, 黑马推荐系统, 电信信号强度诊断等项目")
}
}
//3. 定义Java程序员类JavaProgrammer.
class JavaProgrammer extends Programmer {
override def eat(): Unit = println("Java程序员吃大白菜, 喝大米粥.")
override def skill(): Unit = println("我精通Java技术.")
}
//4. 定义Python程序员类PythonProgrammer.
class PythonProgrammer extends Programmer {
override def eat(): Unit = println("Python程序员吃小白菜, 喝小米粥.")
override def skill(): Unit = println("我精通Python技术.")
}
//5. 定义PartJavaProgrammer类, 表示精通: Java和大数据的程序员.
class PartJavaProgrammer extends JavaProgrammer with BigData {
override def eat(): Unit = println("精通Java和大数据的程序员, 吃牛肉, 喝牛奶")
override def skill(): Unit = {
super.skill() //本身就掌握的内容.
learningBigData() //来到黑马之后学习的技能.
}
}
//6. 定义PartPythonProgrammer类, 表示精通: Python和大数据的程序员.
class PartPythonProgrammer extends PythonProgrammer with BigData {
override def eat(): Unit = println("精通Python和大数据的程序员, 吃羊肉, 喝羊奶")
override def skill(): Unit = {
super.skill() //本身就掌握的内容.
learningBigData() //来到黑马之后学习的技能.
}
}
def main(args: Array[String]): Unit = {
//7. 测试.
//7.1 测试普通Java程序员.
val jp = new JavaProgrammer
jp.name = "张三"
jp.age = 23
println(s"我叫${jp.name}, 年龄为${jp.age}, 我是普通的Java程序员")
jp.eat()
jp.skill()
println("-" * 15) //分割线
//7.2 测试精通Java + 大数据的程序员
val pjp = new PartJavaProgrammer
pjp.name = "李四"
pjp.age = 24
println(s"我叫${pjp.name}, 年龄为${pjp.age}, 我精通Java技术和大数据技术")
pjp.eat()
pjp.skill()
//7.3 测试普通的Python程序员, 自行测试.
//7.4 测试精通Python + 大数据的程序员, 自行测试.
}
}
Scala第九章节
章节目标
- 理解包的相关内容
- 掌握样例类, 样例对象的使用
- 掌握计算器案例
1. 包
实际开发中, 我们肯定会遇到同名的类, 例如: 两个Person类. 那在不改变类名的情况下, 如何区分它们呢?
这就要使用到包(package)了.
1.1 简介
包就是文件夹, 用关键字package修饰, 它可以区分重名类, 且功能相似的代码可以放到同一个包中, 便于我们维护和管理代码.
注意:
编写Scala源代码时, 包名和源码所在的目录结构可以不一致.
编译后, 字节码文件和包名路径会保持一致(由编译器自动完成).
包名由数字, 大小写英文字母, _(下划线), $(美元符)组成, 多级包之间用.隔开, 一般是公司域名反写.
例如: com.itheima.demo01, cn.itcast.demo02
1.2 格式
-
格式一: 文件顶部标记法, 合并版
package 包名1.包名2.包名3 //根据实际需求, 可以写多级包名 //这里可以写类, 特质... -
格式二: 文件顶部标记法, 分解版
package 包名1.包名2 package 包名3 //这种写法和 //这里可以写类, 特质... -
格式三: 串联式包语句
package 包名1.包名2 { //包名1的内容在这里不可见 package 包名3 { //这里可以写类, 特质... } }注意: 上述这种写法, 建议包名嵌套不要超过3级.
参考代码
//案例: 演示包的3种写法 //格式一: 文件顶部标记法, 合并版. /*package com.itheima.scala class Person*/ //格式二: 文件顶部标记法, 分解版. /*package com.itheima package scala class Person*/ //格式三: 串联式包语句 package cn { //嵌套不建议超过3层. package itcast { package scala { class Person{} } } } //测试类 object ClassDemo01 { //main方法是程序的主入口, 所有的代码都是从这里开始执行的. def main(args: Array[String]): Unit = { val p = new cn.itcast.scala.Person() println(p) } }
1.3 作用域
Scala中的包和其它作用域一样, 也是支持嵌套的, 具体的访问规则(作用域)如下:
-
下层可以直接访问上层中的内容.
即: 在Scala中, 子包可以直接访问父包中的内容 -
上层访问下层内容时, 可以通过
导包(import)或者写全包名的形式实现. -
如果上下层有相同的类, 使用时将采用就近原则来访问.
即: 上下层的类重名时,优先使用下层的类, 如果明确需要访问上层的类,可通过上层路径+类名的形式实现
需求
- 创建com.itheima包, 并在其中定义Person类, Teacher类, 及子包scala.
- 在com.itheima.scala包中定义Person类, Student类.
- 在测试类中测试.
参考代码
//案例: 演示包的作用域
package com.itheima{ //父包
class Person{} //这是com.itheima包中的Person类
class Teacher{} //这是com.itheima包中的Teacher类
object ClassDemo01 { //父包中的测试类
def main(args: Array[String]): Unit = {
//方式一: 导包, 导包语句可以出现在Scala代码中的任意位置, 不一定是行首.
/*import com.itheima.scala.Student
val s = new Student() //父包访问子包的类, 需要导包.
println(s)*/
//方式二: 全包名
val s = new com.itheima.scala.Student()
//因为当前包就是com.itheima, 所以上述代码可以简写成如下格式
//val s = new scala.Student()
println(s)
}
}
package scala{ //子包
class Person{} //这是com.itheima.scala包中的Person类
class Student{} //这是com.itheima.scala包中的Student类
object ClassDemo02 { //子包中的测试类.
def main(args: Array[String]): Unit = {
val t = new Teacher() //子包可以直接访问父包中的内容.
println(t)
val p = new Person() //子父包有同名类时, 采用就近原则来访问.
println(p)
val p2 = new com.itheima.Person() //子父包有同名类, 且想访问父包类时, 写全路径即可.
println(p2)
}
}
}
}
1.4 包对象
包中可以定义子包, 也可以定义类或者特质, 但是Scala中不允许直接在包中定义变量或者方法, 这是因为JVM的局限性导致的, 要想解决此问题, 就需要用到包对象了.
1.4.1 概述
在Scala中, 每个包都有一个包对象, 包对象的名字和包名必须一致, 且它们之间是平级关系, 不能嵌套定义.
注意:
- 包对象也要定义到父包中, 这样才能实现
包对象和包的平级关系.- 包对象一般用于对
包的功能进行补充, 增强等
1.4.2 格式
package 包名1 { //父包
package 包名2 { //子包
}
package object 包名2 { //包名2的包对象
}
}
1.4.3 示例
需求
- 定义父包com.itheima, 并在其中定义子包scala.
- 定义scala包的包对象, 并在其中定义变量和方法.
- 在scala包中定义测试类, 并测试.
参考代码
package com.itheima { //父包
package scala { //子包
//测试类
object ClassDemo03{
def main(args: Array[String]): Unit = {
//访问当前包对象中的内容.
println(scala.name)
scala.sayHello()
}
}
}
package object scala { //scala包的包对象, 和scala包之间是平级关系.
//尝试在包中直接定义变量和方法, 发现报错, 我们要用包对象解决.
val name = "张三"
def sayHello() = println("Hello, Scala!")
}
}
1.5 包的可见性
在scala中, 我们也是可以通过访问权限修饰符(private, protected, 默认), 来限定包中一些成员的访问权限的.
格式
访问权限修饰符[包名] //例如: private[com] var name = ""
需求
- 定义父包com.itheima, 并在其中添加Employee类和子包scala.
- 在Employee类中定义两个变量(name, age), 及sayHello()方法.
- 在子包com.itheima.scala中定义测试类, 创建Employee类对象, 并访问其成员.
参考代码
//案例: 演示包的可见性
package com.itheima { //父包
class Employee { //父包com.itheima中的Employee类
//解释: private表示只能在本类中使用, [itheima]表示只要是在itheima包下的类中, 都可以访问.
private[itheima] val name = "张三"
//什么都不写, 就是公共权限, 类似于Java中的public
val age = 23
//解释: private表示只能在本类中使用, [com]表示只要是在com包下的类中, 都可以访问.
private[com] def sayHello() = println("Hello, Scala!")
}
package scala { //子包
object ClassDemo04 { //子包com.itheima.scala中的测试类
def main(args: Array[String]): Unit = {
//创建Employee类的对象, 访问其中的成员.
val e = new Employee()
println(e)
println(e.name)
println(e.age)
e.sayHello()
}
}
}
}
1.6 包的引入
1.6.1 概述
在Scala中, 导入包也是通过关键字import来实现的, 但是Scala中的import功能更加强大, 更加灵活, 它不再局限于编写到scala文件的顶部, 而是可以编写到scala文件中任何你需要用的地方. 且Scala默认引入了java.lang包, scala包及Predef包.
1.6.2 注意事项
-
Scala中并不是完全引入了scala包和Predef包中的所有内容, 它们中的部分内容在使用时依旧需要先导包.
例如: import scala.io.StdIn -
import语句可以写到scala文件中任何需要用到的地方, 好处是: 缩小import包的作用范围, 从而提高效率.
-
在Scala中, 如果要导入某个包中所有的类和特质, 要通过
_(下划线)来实现.例如:import scala._ 的意思是, 导入scala包下所有的内容 -
如果仅仅是需要某个包中的某几个类或者特质, 则可以通过
选取器(就是一对大括号)来实现.例如:import scala.collection.mutable.{HashSet, TreeSet}表示只引入HashSet和TreeSet两个类. -
如果引入的多个包中含有相同的类, 则可以通过
重命名或者隐藏的方式解决.-
重命名的格式import 包名1.包名2.{原始类名=>新类名, 原始类名=>新类名} //例如: import java.util.{HashSet=>JavaHashSet} -
隐藏的格式import 包名1.包名2.{原始类名=>_, _} //例如:import java.util.{HashSet=>_, _} 表示引入java.util包下除了HashSet类之外所有的类
-
1.6.3 示例
需求
- 创建测试类, 并在main方法中测试上述的5点注意事项.
- 需求1: 导入java.util.HashSet类.
- 需求2: 导入java.util包下所有的内容.
- 需求3: 只导入java.util包下的ArrayList类和HashSet类
- 需求4: 通过重命名的方式, 解决多个包中类名重复的问题
- 需求5: 导入时, 隐藏某些不需要用到的类, 即: 导入java.util包下除了HasSet和TreeSet之外所有的类.
参考代码
//案例: 演示包的引入
object ClassDemo05 {
//测试方法1
def test01() = {
//1.导入java.util.HashSet
import java.util.HashSet //好处: 缩小import包的作用范围, 从而提高效率.
val hs = new HashSet()
println(hs.getClass)
//2.导入java.util包下所有的内容.
import java.util._
val hm = new HashMap()
println(hm.getClass)
val list = new ArrayList()
println(list.getClass)
}
//测试方法2
def test02() = {
//val hs = new HashSet() //这样写会报错, 因为没有导包.
//3.只导入java.util包下的ArrayList类和HashSet类
/*import java.util.{ArrayList, HashSet}
val list = new ArrayList()
val hs = new HashSet()
val hm = new HashMap() //这样写会报错, 因为没有导包.*/
//4.通过重命名的方式, 解决多个包中类名重复的问题
/*import java.util.{HashSet => JavaHashSet}
import scala.collection.mutable.HashSet
val hs = new HashSet()
val jhs = new JavaHashSet()
println(hs.getClass)
println(jhs.getClass)*/
//5. 导入时, 隐藏某些不需要用到的类.
//导入java.util包下除了HasSet和TreeSet之外所有的类
import java.util.{HashSet=>_, TreeSet=>_, _}
//val hs = new HashSet() //这样写会报错
val hm = new HashMap()
println(hm.getClass)
}
//main方法, 程序的入口.
def main(args: Array[String]): Unit = {
//调用test01()和test02()这两个测试方法.
test01()
println("-" * 15)
test02()
}
}
2. 样例类
在Scala中, 样例类是一种特殊类,一般是用于保存数据的(类似于Java POJO类), 在并发编程以及Spark、Flink这些框架中都会经常使用它。
1.1 格式
case class 样例类名([var/val] 成员变量名1:类型1, 成员变量名2:类型2, 成员变量名3:类型3){}
- 如果不写, 则变量的默认修饰符是val, 即: val是可以省略不写的.
- 如果要实现某个成员变量值可以被修改,则需手动添加var来修饰此变量.
1.2 示例
需求
-
定义样例类Person,包含姓名和年龄这两个成员变量.
其中: 姓名用val修饰, 年龄用var修饰 -
在测试类中创建Person类的对象, 并打印它的属性值.
-
尝试修改姓名, 年龄这两个成员变量的值, 并观察结果.
参考代码
//案例: 样例类入门
object ClassDemo01 {
//1. 创建一个Person样例类, 属性为: 姓名, 年龄.
case class Person(name:String = "张三",var age:Int = 23) {}
def main(args: Array[String]): Unit = {
//2. 创建Person类型的对象, 然后打印属性值.
val p = new Person()
println(p)
//3. 尝试修改对象p的属性值
//p.name = "李四" //这样写会报错, 因为样例类的成员变量默认修饰符是: val
p.age = 24
println(p)
}
}
1.3 样例类中的默认方法
1.3.1 简介
当我们定义一个样例类后,编译器会自动帮助我们生成一些方法, 常用的如下:
- apply()方法
- toString()方法
- equals()方法
- hashCode()方法
- copy()方法
- unapply()方法
1.3.2 功能详解
-
apply()方法
- 可以让我们快速地使用类名来创建对象, 省去了new这个关键字
- 例如:
val p = Person()
-
toString()方法
- 可以让我们通过输出语句打印对象时, 直接打印该对象的各个属性值.
- 例如:
println(p) 打印的是对象p的各个属性值, 而不是它的地址值
-
equals()方法
- 可以让我们直接使用
==来比较两个样例类对象的所有成员变量值是否相等. - 例如:
p1 == p2 比较的是两个对象的各个属性值是否相等, 而不是比较地址值
- 可以让我们直接使用
-
hashCode()方法
-
用来获取对象的哈希值的. 即: 同一对象哈希值肯定相同, 不同对象哈希值一般不同.
-
例如:
val p1 = new Person("张三", 23) val p2 = new Person("张三", 23) println(p1.hashCode() == p2.hashCode()) //结果为: true
-
-
copy()方法
-
可以用来快速创建一个属性值相同的实例对象,还可以使用带名参数的形式给指定的成员变量赋值.
-
例如:
val p1 = new Person("张三", 23) val p2 = p1.copy(age = 24) println(p1) //结果为: 张三, 23 println(p2) //结果为: 张三, 24
-
-
unapply()方法
- 一般用作
提取器, 但是它需要一些铺垫知识, 我们暂时还没学到, 在后续章节详细解释.
- 一般用作
1.3.3 示例
需求
- 创建Person样例类, 指定姓名, 年龄.
- 在测试类中创建Person类的对象, 并测试上述的5个方法.
参考代码
//案例: 演示样例类的默认方法.
object ClassDemo02 {
//1. 定义一个样例类Person.
case class Person(var name:String, var age:Int) {}
def main(args: Array[String]): Unit = {
//2. 测试样例类中的一些默认方法.
val p1 = Person("张三", 23) //免new, 说明支持apply方法
println(p1) //直接打印对象输出属性值, 说明支持toString方法
val p2 = Person("张三", 23)
println(p1 == p2) //比较的是属性值, 说明重写了equals方法
println("-" * 15)
//记忆: 同一对象哈希值肯定相同, 不同对象哈希值一般不同.
println(p1.hashCode()) //可以获取哈希值, 说明重写了hashCode方法
println(p2.hashCode())
//演示copy方法, 就是用来复制对象的.
//需求: 想创建一个张三, 50这样的对象.
val p3 = p2.copy(age = 50)
println(p3) //结果为: 张三, 50
}
}
3. 样例对象
在Scala中, 用case修饰的单例对象就叫: 样例对象, 而且它没有主构造器 , 它主要用在两个地方:
-
当做枚举值使用.
枚举: 就是一些固定值, 用来统一项目规范的.
-
作为没有任何参数的消息传递
注意: 这点目前先了解即可, 后续讲解Akka并发编程时会详细讲解.
3.1 格式
case object 样例对象名
3.2 示例
需求
- 定义特质Sex, 表示性别, 且它只有两个实例(Male: 表示男, Female: 表示女)
- 定义Person类,它有两个成员变量(姓名、性别)
- 在测试类中创建Person类的对象, 并测试.
参考代码
object ClassDemo03 {
//1. 定义一个特质Sex, 表示性别.
trait Sex
//2. 定义枚举Male, 表示男.
case object Male extends Sex
//3. 定义枚举Female, 表示女.
case object Female extends Sex
//4. 定义Person样例类, 属性: 姓名, 性别.
case class Person(name:String, sex:Sex) {}
def main(args: Array[String]): Unit = {
//5. 创建Person类型的对象.
val p = Person("张三", Male)
//6. 打印属性值.
println(p)
}
}
4. 案例: 计算器
8.1 需求
- 定义样例类Calculate, 并在其中添加4个方法, 分别用来计算两个整数的
加减乘除操作. - 在main方法中进行测试.
8.2 目的
- 考察
样例类的相关内容.
8.3 参考代码
//案例: 计算器.
object ClassDemo04 {
//1. 定义样例类Calculate, 添加加减乘除这四个方法.
case class Calculate(a:Int, b:Int){
//加法
def add() = a + b
//减法
def subtract() = a - b
//乘法
def multiply() = a * b
//除法
def divide() = a / b
}
//main方法, 程序的入口
def main(args: Array[String]): Unit = {
//2. 测试Calculate类中的加减乘除这四个方法.
val cal = Calculate(10, 3)
//测试加法
println("加法: " + cal.add())
//测试减法
println("减法: " + cal.subtract())
//测试乘法
println("乘法: " + cal.multiply())
//测试除法
println("除法: " + cal.divide())
}
}