K8s基本的概念及资源总结
Master
集群的管理和控制,执行kebernetes控制命令。内部进程有:Kubernetes API Server是集群控制的唯一入口,Kubernetes Controller Manager自动化控制中心,Kubernetes Scheduler负责 Pod的调度,etcd服务存储资源对象数据。
Node
负责实际运行负载(容器),内部进程有:kubelet负责pod对应的容器的创建与启停,与master紧密合作,将此Node作为集群一个成员管理起来;kube-proxy负责Kubernetes Service的通信与负载均衡机制;docker。常用Node相关命令:kubectl get nodes。kubectl describe node nodeName。
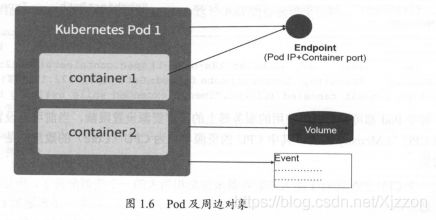
Pod

以Pause代表Pod的生存状态,每个Pod共享IP及Volume。在Kubernetes中Pod之间可以相互通信。
定义一个Redis的Pod
apiVersion: v1
kind: Pod
metadata:
name: tb-redis // Pod名称
labels:
app: tb-redis // Pod的标签
spec:
containers:
- name: server // Pod里的容器名为server
imagePullPolicy: IfNotPresent
image: redis:4.0 //用的redis:4.0镜像
ports:
- containerPort: 6379 //在Pod的6379上启动此容器进程,PodIp+port就可以定位到这个容器
resources: //限定能使用的资源
requests:
memory: "64Mi"
cpu: "259m"
limits:
memory: "128Mi"
cpu: "500m"
volumeMounts:
- mountPath: /data
name: redis-data
volumes:
- name: redis-data
emptyDir: {}
restartPolicy: Always
Label
是一个key=value的键值对,Label可以附加到各种资源对象上,如Node,Pod等。给资源对象打了标签,随后可以通过Label Selector查询和筛选拥有某些Label的资源对象。Label在kubernetes中的应用:kube-controller进程通过资源对象RC上定义的Label Selector来筛选要监控的Pod副本数量。kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service到对应Pod的请求转发路由表。kube-scheduler进程可以实现Pod"定向调度"特性。
apiVersion: v1
kind: ReplicationController
metadata:
name: myweb
spec:
replicas: 1
selector: //标签选择器
app: myweb
template:
...
Replication Controller
作用是声明某种Pod的副本数量在任意时刻都符合某个预期值,包含三个部分:Pod期待的副本数,用于筛选目标Pod的Label Selector,当Pod的副本数量小于预期数量时,用于创建新Pod的Pod模板。kubectl scale rc redis-slave --replicas=3命令可用于动态伸缩。
Deployment
可以看作是RC的一次升级,可以随时知道Pod的部署进度。kubectl create -f tomcat-deployment.yaml可以创建Deployment。kubectl get deployments可以知道Deployment的信息。
Horizontal PodAutoscaler
虽然kubectl scale可以实现扩容,但是不能自动。HP可以实现自动扩容。
apiVersion autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
namespace: default
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 90 //
StatefulSet
一些服务是由状态的,而RC、Deployment等式面向无状态的。StatefulSet里的每个Pod都有为稳定、唯一的网络标识,可以用来发现集群内其他的成员。StatefulSet控制的Pod副本的启停是受控制的。StatefulSet里的Pod采用稳定的持久化存储券,通过PV/PVC来实现,删除Pod时默认不会删除与StatefulSet相关的存储券。
Service
Service定义了一个服务的访问入口地址,前端通过地址访问到该Node背后的一组由Pod组成的集群来提供服务,kube-proxy进程其实是一个智能的软件负载均衡器,它负责将对Service的请求转发到后端的某个Pod实例上,并在内部实现服务的负载均衡及会话保持。每个Service都有一个Cluster IP,J即使Pod的ip发生变化,Service IP并不会变化,所以只要用Service的Name与Serivice IP地址做一个DNS域名映射,就可以实现服务发现。但是Service本身的负载均衡问题没解决,如果有多个Service,那么按理是有一个负载均衡器转发到各个Service上,而现在是单独NodeIp+NodePort访问Service。比如一个系统有多个service,如 device, portal, mall等多个servcie,需要一个负载均衡器如nginx,根据url将请求转发到servcie中。
Volume
Volume是Pod中能够被多个容器访问的共享目录,定义在Pod上,被Pod里的多个容器挂载到具体目录下。在Pod上声明一个Volume,然后再容器里引用该Volume并mount到容器里的某个目录。
template:
metadata:
labels:
app: app-demo
tier: frontend
spec:
volumes:
name: datavol // 声明一个名为datavol的volumes
emptyDir: {}
containers:
name: tomcat-demo
image: tomcat
volumeMounts: // 挂载到volumes
mountPath: /mydata-data
name: datavol
emptyDir,Kubernets将自动在宿主机上分配一个目录,Pod从Node移除时,emptyDir中的数据也会被移除。hostPath可以指定宿主机的文件或目录,会一直保存着。还有一些其它类型的Volume,如NFS等。
Persistent Volume
“网络存储”是相对于"计算资源"而存在的一种实体资源,之前的Volume是定义在Pod上的,属于"“计算资源”。PV只能是网络存储,不属于任何Node,但可以在每个Node上访问。
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv0003
spec:
capacity:
storage: 5Gi
accessMode:
- ReadWriteOnce
nfs:
path: /somepath
server: 172.17.0.2
PersistentVolumeClaim
如果某个Pod,想申请某种类型的PV,则首先需要定义一个PersistentVolumeClaim(PVC),然后在Pod的Volume定义中引用上述PVC即可。PVC会自动找到能用的PV的。
Namespace
实现多租户管理,不同项目划分到不同的namespace中。