x264详解
x264默认是基于帧的线程,比基于切片的吞吐量更好
帧线程添加帧等待时间是需要不同的帧上工作
x264最大线程数128,一般控制16个线程以内。
在基于片段线程的情况下,所有线程都在同一帧上工作。每个帧都被分割成片,每个片在一个核上编码,然后结果一起做出最终帧。
一 码率控制
X264提供三种码率控制的方式:bitrate, qp, crf。这三种方式是互斥的,使用时设置其中之一即可。
(1)bitrate
x264会尝试把给定的位元率作为整体平均值来编码。这意味着最终编码文件的大小是已知的,但最终的品质未知。此选项通常与-pass(两阶段编码)一起使用。
注意,ffmpeg中设置bitrate的具体参数为bit_rate,单位是bits/s(x264里面对应参数i_bitrate的单位则是kbits/s, 1kbits为1000bits而非1024bits).
(2)qp
使用qp选项时,表示P帧的量化值为qp。I帧和B帧的量化值则是从--ipratio和--pbratio中取得。可使用默认参数,也可自己设定。使用qp模式,即固定量化值,意味着停用弹性量化(aq_mode)。
当qp为0时,为无损编码。
(3)crf
固定位元率系数,Constant Ratefactor,
可用的值从1到51,越小编码质量越好,码率越高。一般使用16到24,可以为浮点。(crf并不是恒定质量的方式,同一片子同一crf值,其他参数不同可能码率和质量差较大,不同的片子之间就更没有可比性了)。此模式把某个“质量”作为编码目标,根据片子质量自动分配码率的vbr(Variable Bit Rate动态比特率)。X264中构想是让crf n提供与qp n相当的视觉品质,但编码文件更小一些。
CRF是借由降低“较不重要”帧的品质来达到此目的。在此情况下,“较不重要”是指在复杂或高动态场景的帧,其品质不是很耗费位元数就是不易察觉,所以会提高它们的量化值。从这些帧里所节省下来的位元数被重新分配到可以更有效利用的帧。
当crf为0时,与qp 0相同,实现无损编码。
设置方法:av_dict_set(¶m, "crf", "18", 0);
(4)码率设置
图像运动越快的视频设置越大的码率,图像运动越慢的视频设置越低的码率,这是基本经验,图像很少运动的视频可以考虑用可变码率的低码率设置。体育比赛,军事演习这样的场景图像运动量比较大,可以考虑大码流;课堂讲课,会议演讲等这种情况运动量比较小,可以考虑小码流,尤其是讲台会议这种图像不运动的场景可以采用可变码率。码率与图像尺寸存在相关性,图像的面积越大需要的码流越多。
以下视频位率参考表为进行IPTV直播的码率设置参考,单位:kbps。参考帧率为25~30帧,其它帧率请酌情调整码率。
| 图像尺寸 | H264 | H265 | MPEG-4 | MPEG-2 |
| 1920×1080 | 3000~4500 | 1800~2500 | 8000~12000 | 20000~50000 |
| 1280×720 | 1800~2500 | 1000~1500 | 5000~6000 | 12000~30000 |
| 1024×768 | 1200~1500 | 800~1200 | 3000~4200 | 8000~20000 |
| 720×576 | 600~1000 | 400~600 | 1200~2500 | 4000~6000 |
| 352×288 | 300~400 | 200~300 | 600~1000 | 1500~2000 |
| 4096×2160 | 12000~18000 | 4000~8000 | 不支持 | 不支持 |
二 X264的preset和tune
鉴于x264的参数众多,各种参数的配合复杂,为了使用者方便,x264建议如无特别需要可使用preset和tune设置。这套开发者推荐的参数较为合理,可在此基础上在调整一些具体参数以符合自己需要,手动设定的参数会覆盖preset和tune里的参数。
--preset的参数主要调节编码速度和质量的平衡,有ultrafast、superfast、veryfast、faster、fast、medium、slow、slower、veryslow、placebo这10个选项,从快到慢。
ultrafast编码速度最快,但压缩率低,生成的文件更大,placebo则正好相反。x264所取的默认值为medium。需要说明的是,preset主要是影响编码的速度,并不会很大的影响编码出来的结果的质量。压缩高清电影时,一般用slow或者slower,当你的机器性能很好时也可以使用veryslow,不过一般并不会带来很大的好处。
设置方法:av_dict_set(¶m, "preset", "ultrafast", 0);
--tune的参数主要配合视频类型和视觉优化的参数,或特别的情况。如果视频的内容符合其中一个可用的调整值又或者有其中需要,则可以使用此选项,否则建议不使用(如tune grain是为高比特率的编码而设计的)。tune的值有:
film: 电影、真人类型;
animation: 动画;
grain: 需要保留大量的grain时用;
stillimage: 静态图像编码时使用;
psnr: 为提高psnr做了优化的参数;
ssim: 为提高ssim做了优化的参数;
fastdecode: 可以快速解码的参数;
zerolatency:零延迟,牺牲视频质量减少延迟,比如视频会议
设置方法:av_dict_set(¶m, "tune", "zerolatency", 0)
三 编码建议
编码延时
降低x264的延时是可能的,但是会降低质量。若需零延时,设置--tune zerolatency。若你可以接受一点儿小延时(如小于1秒),最好还是允许延时。下列步骤可以降低延迟,当延迟足够小时,就别再进行后续步骤了:
1.从初始值开始
2.关闭sync-lookahead(设置用于线程预测的帧缓存大小。最大值是250.在第二遍及更多遍编码或基于分片线程时自动关闭)
3.降低rc-lookahead,但别小于10(设定mb-tree位元率控制和vbv-lookahead使用的帧数)
4.降低threads(比如从12降到6)
5.使用切片线程(sliced threads)
6.禁用rc-lookahead
7.禁用b-frames
8.实在不行,就用--tune zerolatency
param->rc.i_lookahead = 0;param->i_sync_lookahead = 0; param->i_bframe = 0; param->b_sliced_threads = 1; param->b_vfr_input = 0;param->rc.b_mb_tree = 0;(使用宏块树位元率控制会改善整体压缩率)
muxdelay || max_delay:设置延迟约束,muxdelay以秒为单位设置延迟,而max_delay以微秒为单位设置延迟。最终结果是相同的。设置方法:av_dict_set(¶m, "muxdelay", "1", 0);
x264线程
x264起多少个线程比较好 ?
建议线程数:
1、2、4、8
测试结论:
1、更多的线程会消耗更多总CPU时间片,因此在长期满载的机器上不宜使用多线程。
2、获得的时间收益随线程增多呈递减趋势,8线程以后尤为明显。
3、PNSR下降随线程数增加呈抛物递增趋势,16线程增加到24线程PSNR时下降了0.6之巨。
4、设置threads=auto时,线程数为逻辑CPU个数的1.5倍。
x264各类型帧的大小及编码耗时
I帧、B帧、P帧都极大地受编码参数的影响。
通常情况下:
h264编码的帧由大到小依次为:
I > P > B
(互相之间约有5倍的差距)
x264的编码耗时由长到短依次为:
P > B > I
通常而言,较小的帧因为帧内压缩计算量(deblock、cabac等)小,所以耗时相对短。
P帧的编码耗时长是因为帧间压缩(宏块寻找、运动补偿等)耗时长所以提高了总体耗时。
另外:可以修改x264中的x264_slices_write函数来测量不同类型帧的编码耗时。
四 参数详解
profile
默认: 未设定
该选项限制输出视频流的profile。如命令中指定profile,则会忽视其他对之影响的参数,也就是说,只要指定profile,就能保证输出流的兼容性。一旦使用该选项,就无法进行无损编码 (--qp 0 or --crf 0)。若播放机只支持某种profile,编码时需相应指定。大多数解码器都支持High profile,所以无需如此设置。
H.264有四种画质级别,分别是baseline, extended, main, high:
(1)Baseline Profile:基本画质。支持I/P 帧,只支持无交错(Progressive)和CAVLC;
(2)Extended profile:进阶画质。支持I/P/B/SP/SI 帧,只支持无交错(Progressive)和CAVLC;(用的少)
(3)Main profile:主流画质。提供I/P/B 帧,支持无交错(Progressive)和交错(Interlaced), 也支持CAVLC 和CABAC 的支持;
(4)High profile:高级画质。在main Profile 的基础上增加了8x8内部预测、自定义量化、 无损视频编码和更多的YUV 格式;
H.264 Baseline profile、Extended profile和Main profile都是针对8位样本数据、4:2:0格式(YUV)的视频序列。在相同配置情况下,High profile(HP)可以比Main profile(MP)降低10%的码率。 根据应用领域的不同,Baseline profile多应用于实时通信领域,Main profile多应用于流媒体领域,High profile则多应用于广电和存储领域。
rtbufsize
减少采集缓存
av_dict_set(&p_device_options,"rtbufsize",str_buf_size,0);
rtbufsize是缓存的大小,摄像头和麦克风的数据采集出来之后会先放到这个buf中然后才能取出来做解码或编码,buf大小根据自己的需求算出来设定。
audio_buffer_size
减少音频采集sampels数量
av_dict_set(&p_device_options, "audio_buffer_size","30", 0);
音频采集如果不设置一般是采集出来1920个samples,如果没记错android采集出来的samples更多应该超过10000个,这么多的samples做编码的时候aac格式需要1024个samples,循环编完之后才能再次去取新的麦克风数据,所以需要减少。
slow-firstpass
默认: 未开启
使用 --pass 1 将在命令行分析完成时应用以下设定:
- --ref 1
- --no-8x8dct
- --partitions i4x4 (仅限于已事先开启的条件下)
- --me dia
- --subme MIN( 2, subme )
- --trellis 0
使用--slow-firstpass可禁用此设置。
注:当选择 --preset placebo 时,自动开启 --slow-firstpass。
参见 --pass.
keyint
默认: 250
设定x264输出的IDR帧(即关键帧)之间的最大间隔。可以设定为"infinite"(无穷),则仅在场景切换时出现IDR帧。
IDR帧相当于视频流中的"分界符":任何帧不可参考IDR帧另一侧的数据。 另外,IDR帧本身也是I帧,不参考任何其它帧。这意味着,播放器可从最近的I帧开始解码,而无需从头开始。故而,IDR帧可以用作于视频的定位点(seek point)。
此项功能是在视频定位能力和编码效率之间做权衡。因为I帧体积远大于P/B帧(低速运动的场景中,可达到10倍多),所以,当在VBV设定很低时(如小于1秒的缓冲大小),极其不利于码率控制。若遇此情况,需研究intra-refresh。
默认值适用于绝大多数视频。对于编码蓝光、广播、在线流媒体或特殊情况下,可能需要将GOP长度设得很小(通常约1x fps)。
参见:--min-keyint, --scenecut, --intra-refresh
min-keyint
默认: auto (MIN(--keyint / 10, --fps))
设定IDR帧之间的最小间隔。
关于IDR帧的解释,参见 --keyint
keyint范围太小将导致IDR帧出现在"错误"的位置(如闪烁的场景(a strobing scene))。该选项限制每个IDR帧后必须经过多少帧才能出现下一个IDR帧。
min-keyint 的最大允许值为 --keyint/2+1
推荐值: 默认,或1倍帧率
参见:--keyint, --scenecut
no-scenecut
默认: 未开启
完全禁止自动I帧选择算法(adaptive I-frame decision)。
参见:--scenecut
scenecut
默认: 40
设定I/IDR帧放置的阀值。(read: scene change detection).
x264有一指标,用于衡量每一帧与前一帧的差异程度。若该值小于scenecut,则检测到'场景切换'('scenecut')条件,并放置一个I帧 (前提:该帧与上一个IDR帧的间隔小于min-keyint,否则就放置一个IDR帧)。提高scenecut值将增加检测到的'场景切换'数量。关于 scenecut比较的具体方法,参见 this doom9 thread.
将scenecut设为0,相当于设定 --no-scenecut
推荐值: 默认
参见:--keyint, --min-keyint, --no-scenecut
intra-refresh
默认: 关
禁用IDR帧,取而代之的是x264每隔keyint长度的帧,对帧内的每个宏块(macroblock)进行帧内编码(intra coding)。各块以列为单位,沿水平方向刷新,称之为“刷新波”。该方式适用于网络延迟较低的流媒体,与标准IDR帧的方式相比,更易使每帧的数据量大小接近恒定。该方式同时增强了视频流对数据丢包的恢复能力。此选项会降低压缩效率,因此必要时才可使用。
趣闻:
- 第一帧仍然是IDR帧
- 帧内编码块(Intra-blocks)仅出现于P帧 - 跟在B帧之后出现的第一个P帧的刷新波宽于其它P帧
- 损失压缩效率的主要原因在于:刷新波"未刷新"(左侧)的宏块无法参考"已刷新"(右侧)的数据。
bframes
默认: 3
设置x264采用的最大连续B帧数。
假如没有B帧,x264数据流会是这样:IPPPPP...PI。若 --bframes 2,则最多2个连续P帧可以被替换为B帧,比如: IBPBBPBPPPB...PI。
B帧类似于P帧,但它还可以利用后续时间的帧进行运动预测,因此能大大增加压缩率。B帧的平均质量受pbratio控制。
趣闻:
- 出于对未来帧的需求,编码器的延时性增加了。参见 --sync-lookahead
- x264 偶尔区分两种不同的B帧。大写'B'代表能被其它帧参考的B帧(参见b-pyramid),而小写'b'表示不能被参考的B帧。如果你见到'B'与'b'混在一起,通常就是上述的区别。当区别不重要时,则用'B'来泛指所有B帧。
- 欲详细了解x264如何判断某帧该用P帧还是B帧,参见 this ffmpeg-devel mail。默认情况下(假设--bframes 3)帧类型像这样(显示顺序): IBBBPBBBPBPI
- B帧的另一优势在于高效的快进能力,因为解码器可跳过B帧直接解析P帧,速度由每次1帧提升为(bframs设置值+1)帧。以三个连续B帧的视频为例,解码器能以整个minigop为单位来定位,达到4倍速。
参见:--no-b-adapt, --b-bias, --b-pyramid, --ref, --pbratio, --partitions, --weightb
b-adapt
默认: 1
设置自适应B帧放置的决策算法。该选项控制x264如何决定该放置P帧还是B帧。
0 关闭:永远选择B帧。此值效果相当于旧选项 no-b-adapt。
1 “快速”算法:较快。b-frames设定越高,增速效果越明显。此模式下强烈推荐配合使用--bframes 16。
2 “优化”算法:较慢。b-frames设定越高,减速效果越明显。多次编码模式下,此选项只需在1st pass使用,因为帧类型在该pass中决定。
b-bias
默认: 0
控制B帧替代P帧的概率。越大(正数)则权重越偏向于B帧。越小(负数)则相反。此数值无量纲。范围从-100到100。100/-100并不保证 所有/没有 P帧被替换掉。(可用 --b-adapt 0 来实现 )
除非你认为自己的码率控制策略优于x264,否则别改动此项。
参见:--b-frames, --ipratio
b-pyramid
默认: normal
允许B帧被其它帧参考。若关闭此设定,所有帧只能参考I帧或P帧。虽然I/P帧的质量高,更有参考价值,但B帧也可加以利用。被参考的B帧,其量化值将介于P帧与“一次性”的b帧之间。逻辑上讲,要参考之前的B帧,则必须告知x264至少使用2个B帧。
举个例子,一个显示顺序为 P[1]b[1]b[2]B[3]b[4]b[5]P[2] 的小画面组(minigop),其中的B帧还被其它b帧用作参考,而b帧不被任何帧参考,因为称为“一次性”。当b-pyramid开启时,中间的B[3]帧将在P帧之后,b帧之前被编码,因为它是后续两个b帧的参考。P[1]将是b[1]和b[2]的L0(过去)参考,而B[3]和P[2]则是b[1]和b[2]的L1(未来)参考。编码与流的顺序将是P[1]P[2]B[3]b[1]b[2]b[4]b[5]。
目前x264的b-pyramid仅支持单层的H.264层级,即以B帧为参考的b帧不能进一步被参考。
对于蓝光的编码,必须用“none”或“strict”。
- none: 不允许B帧作为参考帧
- strict: 每个minigop中,只允许一个B帧作为参考帧;受限于蓝光标准
- normal: 每个minigop中,允许多个B帧作为参考帧。
参见:--bframes, --refs, --no-mixed-refs
open-gop
默认: none
开放画面组(Open-GOP) 技术能提升编码效率。但一些解码器对open-GOP的视频流支持不完全,所以至今依然默认为关闭。若想使用,应先测试保证所有用到的解码器能完整支持,或等待解码器完善该项支持。
no-cabac
默认: 未开启
关闭CABAC (Context Adaptive Binary Arithmetic Coder) 流压缩,转为使用较低效的CAVLC (Context Adaptive Variable Length Coder) 系统。大大降低压缩效率(一般10-20%) 和解码要求。本项不应被开启,除非是出于兼容性之类的原因不得不开启。
ref
默认: 3
控制图像解码缓存(DPB: Decoded Picture Buffer)的大小。数值范围0至16。简而言之,此值表示每个P帧能利用之前 (译者注:“之前”指的是解码顺序,而非显示顺序)的多少帧作为参考(B帧能利用的P帧数要少1、2帧,取决于是否开启B帧参考)。可被参考的最小ref是1
需注意,H.264规范中,对各个level都限制了DPB尺寸。如遵守 Level 4.1 规范,则对于720p和1080p视频,最大的ref是9和4。关于level和4.1的信息,参见level。
参见:--b-pyramid, --no-mixed-refs, --level
deblock
默认: 0:0
控制循环滤镜(loop filter,即inloop deblocker),是H.264标准的一部分。对于编码时间vs质量提升,效率提升明显。
关于循环滤镜参数的效果, this doom9 thread 解释的很好。(见一楼主贴,及akupenguin的回复)
参见:--no-deblock
no-deblock
默认: 未开启
完全禁用循环滤镜,不推荐使用。
参见:--deblock
slices
默认: 0
设置每帧的切片数,并强制为矩形切片。(会被--slice-max-size或--slice-max-mbs覆盖)
蓝光编码需使用4。其它情况,若非必要一般不用。
参见:--slice-max-size, --slice-max-mbs
slice-max-size
默认: 0
设置切片的最大字节数, 包含预估的NAL额外量(overhead)。(目前与--interlaced互不兼容)
参见:--slices
slice-max-mbs
Default: 0
设置切片的最大宏块数。(目前与--interlaced互不兼容)
参见:--slices
tff
启用交错(隔行)编码,并指定奇数场(top field)为先。x264的交错编码方式采用MBAFF,效率低于逐行编码。因此,仅在需要隔行显示(或无法将视频预先去交错)时,才使用。开启后,同时会开启pic-struct
bff
启用交错(隔行)编码,并指定偶数场(top field)为先。详见--tff
no-interlaced
强制x264以逐行模式输出。
constrained-intra
默认: 未开启
启用受限的帧内预测,在编码SVC标准视频的底层(base layer)子视频时必须开启。由于Everyone TM 忽略SVC,你也可以忽略这个开关。
pulldown
默认: none
以某个预设模式将输入流(隔行,恒定帧率)标记为软交错(soft telecine)。软交错详解见 HandBrake wiki。可用预设有: none, 22, 32, 64, double, triple , euro
使用除 none以外任一预设,都会连带开启--pic-struct
fake-interlaced
默认: 未开启
将视频流标记为交错(隔行),哪怕并非为交错式编码。可用于编码蓝光兼容的25p和30p视频。
frame-packing
默认: 未设定
编码3D视频时,此参数在码流中插入一个标志,告知解码器此3D视频是如何合并的。可选值及其意义参见 x264 --fullhelp
rc-lookahead
默认: 40
控制mb-tree码率控制和vbv-lookahead所用的帧数。最大允许值为 250.
mb-tree部分,增加此项帧数能改善质量,但速度会变慢。mb-tree所用的最大缓冲是MIN( rc-lookahead, --keyint )
vbv-lookahead部分, 在使用vbv时增加此项帧数能增加稳定性和准确率。vbv-lookahead所用的最大值是:
MIN(rc-lookahead, MAX(--keyint, MAX(--vbv-maxrate, --bitrate) / --vbv-bufsize * --fps))
参见:--no-mbtree, --vbv-bufsize, --vbv-maxrate, --sync-lookahead
vbv-maxrate
默认: 0
设置重新填满VBV缓冲的最大速率。
VBV会降低质量,仅用于回放专用的视频编码。
参见:--vbv-bufsize, --vbv-init, VBV Encoding Suggestions
vbv-bufsize
Default: 0
设定VBV缓冲的大小,单位是千比特(kilobits)。
VBV会降低质量,仅用于回放专用的视频编码。
参见:--vbv-maxrate, --vbv-init, VBV Encoding Suggestions
vbv-init
默认: 0.9
设置VBV缓冲达到多满(百分比),才开始回放。
如果小于1,则初始填充(initial fill)为: vbv-init * vbv-bufsize. 若大于1,则作为初始填充的单位kbits.
参见:--vbv-maxrate, --vbv-bufsize, VBV Encoding Suggestions
crf-max
默认: 未设定
与--qpmax类似,不同的是,qpmax设定最大量化值,crf-max设置最大码率因子。该选项仅在使用CRF并开启VBV时有效。该选项保证 x264在降低码率因子(即"质量")时,不会低于某个给定值,哪怕这么做会妨碍VBV限制。此选项最适用于自定义流媒体服务器。详见 initial commit message.
参见:--crf, --vbv-maxrate, --vbv-bufsize
qpmin
默认: 0
设定x264所使用的最小量化值。量化值越低,输出视频越接近输入视频。低到一定程度时,输出将看上去跟输入相同,虽然并不是完全相同。通常没有理由允许x264再花费比这更多的码率编码宏块了。
若开启了自适应量化(adaptive quantization,默认开启),则不建议提高qpmin,因为这样一来会降低画面内平坦背景部分的质量。
参见:--qpmax, --ipratio
qpmax
默认: 51(注:新版x264已提升为69)
与qpmin相反,它设定了x264可用的最大量化值。默认值51是H.264规范中最高的可用值,代表极低质量。该默认值等于是禁用了qpmax。如需限定x264输出视频的最低质量,可以考虑降低该值(一般别低于30-40),但通常不推荐改动。
参见:--qpmin, --pbratio, --crf-max
qpstep
默认: 4
相邻两帧之间量化值之差的最大值。
ratetol
默认: 1.0
此参数有两个目的:
- 在1-pass bitrate模式下,该设置控制x264可以偏离给定目标码率的百分比。可以设置为“inf”(无穷)来完全禁止溢出检测。最低可设置为0.01。设定 地越高,x264越能对片尾复杂场景做出反应。此参数的单位是百分比(1.0 = 1% 比特率偏移).
大多数电影(比如任意动作电影)都在结尾高潮处最复杂。1pass编码不知道这点,所以那里的所需码率通常都低估了。ratetol设为inf可弥补此点,让编码功能更接近--crf,但文件体积也会超出限定。
- 启用VBV(比如指定了--vbv-*选项)时,此选项也影响VBV的厉害程度。提高该值会允许更大的VBV波动,也增加了破坏VBV设定的风险。对于此目的,该值的单位任意。
ipratio
默认: 1.40
修改I帧与P帧平均量化值的比例。值越高,I帧的质量越高。开启mbtree(默认开启)时,此项失效,mbtree自动计算最优量化值。
参见:--pbratio
pbratio
默认: 1.30
修改P帧与B帧平均量化值的比例。值越高,B帧的质量越低。开启mbtree(默认开启)时无效,因为mbtree自动计算最优值。
参见:--ipratio
chroma-qp-offset
默认: 0
编码时,在色度平面(chroma planes)量化值基础上,增加一个偏移量,可以是负数。
当使用psy选项(psy-rd或psy-trellis)时,x264会自动降低此值(一般在此值基础上减去2),以补偿psy优化时默认过于偏重亮度(luma)质量而忽视色度(chroma)质量的问题。
注:x264 仅在量化值小于等于29时,对亮度和色度平面使用相同的量化值。超过之后,色度量化值的增加将会慢于亮度,直至最终达到亮度q51、色度q39。这是H.264标准的要求。
aq-mode
自适应量化模式(Adaptive Quantization Mode)
默认: 1
若关闭AQ,x264倾向于对低细节度的平滑区域使用过低码率,AQ可以更好把码率分配到各个宏块中. 该选项改变AQ重新安排码率的幅度:
- 0: 禁止AQ
- 1: 允许AQ在整个视频中和帧内重新分配码率
- 2: 自方差AQ(实验阶段),尝试逐帧调整强度
参见:--aq-strength
aq-strength
自适应量化强度(Adaptive Quantization Strength)
默认: 1.0
设置AQ偏向于低细节度(“平滑”)宏块的强度。不允许为负值。建议选值不超过0.0~2.0范围。
参见:--aq-mode
pass
默认: 未设定
此设置对于2pass编码很重要,控制x264如何处理--stats文件。有三个选项:
- 1: 生成新的stats文件,用于1st pass
- 2: 读取stats文件,用于最终pass
- 3: 读取stats文件,并更新之
stats文件包含输入视频每一帧的信息,作为x264的输入用于提高输出品质。大致如此:跑一次1st pass生成stats文件,然后2nd pass就能生成优化过的视频。改进的原因主要在于更优的码率控制。
参见:--stats, --bitrate, --slow-firstpass, X264_statsfile
stats
默认: 'x264_2pass.log'
设定x264读写--pass X264_statsfile的目录地址。
参见:--pass
no-mbtree
默认: 未开启
禁用macroblock tree码率控制。使用macroblock tree码率控制会记录时间方向上的各帧变化并相应权衡,因此在总体上改进了压缩。其概念与AQ同出一辙(AQ降低高复杂度区域的质量,将码率用于低复杂度的区域),但却是从时间方向上施行控制,因此与qcomp十分相似,而qcomp本身也影响mb-tree的强度。
对于多次编码模式,需要在现有stats文件基础上,增加一个大体积stats文件。
推荐值: 默认
参见:--rc-lookahead
qcomp
默认: 0.60
量化曲线(quantizer curve)压缩因子。0.0 => 恒定比特率,1.0 => 恒定量化值。
qcomp在“高成本”的高运动帧与“低成本”的低运动帧之间权衡分配码率。极端设置qcomp=0.0趋于真正的恒定比特率,通常会造成高运动场景十分难看,而将宝贵的码率用于让低运动场景看着很完美。另一极端设置qcomp=1.0则能达到近似恒定量化参数(QP),并完全关闭x264的aq-mode和时间方向的RDO(mb-tree),于是码率被浪费在高复杂度的场景上,而高复杂度的场景无法用作未来远处的帧的参考,因为帧与帧之间的变化太大。
与mbtree一起使用时,也会影响mbtree与aq-strength的强度,而这两项倾向于将更多码率用于低复杂度的场景和宏块(macroblock)。(qcomp越大,则aq与mbtree越弱)。qcomp默认值为0.6,不要改动。
推荐值: 默认
参见:--cplxblur, --qblur
cplxblur
默认: 20
根据给定的半径对量化曲线进行高斯模糊(gaussian blur)。分配给各帧的量化值在时间方向上与相邻几帧相模糊,以限制量化值波动。
当mb-tree开启时,cplxblur无效。
参见:--qcomp, --qblur, --no-mbtree
qblur
默认: 0.5
量化曲线压缩后,根据给定的半径对量化曲线进行高斯模糊。该选项不怎么重要。
参见:--qcomp, --cplxblur
zones
默认: 未设定
对视频不同段(zone)进行参数调整。大多数x264选项都可以针对各段进行调整。
- 单个段包含<起始帧>,<结束帧>,<各选项>
- 多段之间用“/”来分隔
选项:
以下两项很特殊,每段zone设定一次,若需设置则必须列在所有参数之前:
- b=<浮点数> 应用比特率系数于该段。适用于对大/小动作场景的额外调整。
- q=<整数> 对该段使用恒定量化值。适用于一段范围的帧。
其他可用选项如下:
- ref=<整数>
- b-bias=<整数>
- scenecut=<整数>
- no-deblock
- deblock=<整数>:<整数>
- deadzone-intra=<整数>
- deadzone-inter=<整数>
- direct=<整数>
- merange=<整数>
- nr=<整数>
- subme=<整数>
- trellis=<整数>
- (no-)chroma-me
- (no-)dct-decimate
- (no-)fast-pskip
- (no-)mixed-refs
- psy-rd=<浮点>:<浮点>
- me=<字符串>
- no-8x8dct
- b-pyramid=<字符串>
- crf=<浮点>
限制:
- 区段内的参考帧数量不可大于原始设置中的--ref
- Scenecut不可开启或关闭;只有在原始启用(>0)时,才能改变其数值
- 若使用--me esa/tesa,Merange不能超过原始设定值
- Subme若在原始设定为0,则不能改变其值
- 若--me原始设定为dia, hex,或umh,则不能修改为esa或tesa
例子: 0,1000,b=2/1001,2000,q=20,me=3,b-bias=-1000
推荐值: 默认
qpfile
手动忽略标准码率控制。选择一个文件,强制指定某些帧的量化值和帧类型。格式为“帧号 帧类型 量化值”。例子:
0 I 18 < IDR(关键)I帧 1 P 18 < P帧 2 B 18 < 被参考的B帧 3 i 18 < 非IDR(非关键)I帧 4 b 18 < 不被参考的B帧 5 K 18 < 关键帧*
- 无需指定所有帧
- 量化值设为-1允许x264自动选择最优量化值。适用于只想指定帧类型的情况
- 手动指定大量帧的类型和量化值,同时又让x264决定其中间的帧,这么做会降低x264的性能
- “关键帧”是一种通用的关键帧/搜寻点(seekpoint)类型。若等同于--open-gop是none,则等同于IDR I帧,否则就等同于标记为恢复点(Recovery Point)SEI的非IDR I帧
partitions
默认: 'p8x8,b8x8,i8x8,i4x4'
H.264视频在压缩时被分割为16x16的宏块。这些块可以被分为更小的块,本选项就控制此分割。
开启此选项,即开启了单个分块(individual partitions)。分块对不同帧类型(如I, P, B)分开设置。可用分块有p8x8, p4x4, b8x8, i8x8, i4x4
- I: i8x8, i4x4
- P: p8x8 (同时启用p16x8/p8x16), p4x4 (同时启用p8x4/p4x8)
- B: b8x8 (同时启用b16x8/b8x16)
也可设置为“none”或“all”。
p4x4通常没什么用,且大大增加 编码时间/编码质量之比。
参见:--no-8x8dct
direct
默认: 'spatial'
设置'直接'运动向量的预测模式。两种模式可选: spatial和 temporal。也可选择 none来关闭直接运动向量,或选 auto允许x264在两个参数间切换。若设为auto,x264会在编码结束时输出相应的使用信息。“auto”在2pass编码模式下作用最佳,但也能在单次编码中使用。在1st-pass的auto模式下,x264会不断记录两种方法效果的滑动平均值,并以此为依据决定下一次使用哪个方法。注意,只应在1st pass启用auto时,才在2nd pass启用auto。若非如此,2nd pass会默认采用temporal。
直接预测指挥x264在猜测B帧某些部分的运动时,使用何种方法。既可借助该帧的其它部分(spatial),也可与下一个P帧作比较(temporal)。最好将此项设为自动,好让x264自己决定哪种方法更好。不要以为设none能加快速度,恰恰相反,既浪费码率又让画面难看,强烈不推荐。如果你要在spatial和temporal之间做选择,spatial通常更优。
推荐值: 'auto'
no-weightb
默认: 未开启
有时,x264会根据前后帧来决定一B帧的运动补偿。当对B帧进行权重,每一帧所拥有的影响力与其对正在编码的帧的距离相关,而非具有相同的影响。所以weight-b有助于压缩淡入淡出。开启此选项将关闭该功能。
推荐值: 默认
weightp
默认: 2
开启显式权重预测,提升P帧压缩率,同时改善淡入淡出场景的质量,模式越高,编码速度越慢。
注:若编码Adobe Flash,需设置为1,否则解码后会产生artifacts。Flash 10.1修复了这个问题。
模式:
- 0. 禁用
- 1. 简单:仅分析淡入淡出,不做参考复制(reference duplication)
- 2. 智能:淡入淡出+参考复制(reference duplication)
me
默认: 'hex'
全像素(full-pixel)运动估计方法。5种选择:
- dia(diamond菱形搜索) 是最简单的搜索方式,从最优预测值出发,往上、左、下、右一个像素处检测运动向量,挑选最好值,然后重复该步骤,直至找不到更优的运动向量。
- hex(hexagon六角形搜索) 的策略类似,但它对周围六个点进行range-2搜索,因此称为六角形搜索。此方法效率大大高于dia,且速度相当,因此通常编码常用此项。
- umh(uneven multi-hex不对称多六角形搜索)比hex慢很多,但能搜索复杂的多六角形,以避免错过很难找到的运动向量。与hex和dia相似,merange参数直接控制umh的搜索半径,使用者可自行增减搜索的空间尺寸。
- esa(exhaustive全面搜索) 在最优预测值附近merange范围内的整个空间内,以高度优化的智能方式搜索运动向量。相当于数学上的穷举法,搜索区域内的每一个运动向量,但是更快些。然而,此方法远远慢于UMH,且好处不多,对于普通编码没有太大用处。
- tesa (transformed exhaustive变换全面搜索)算法尝试对各个运动向量近似哈达玛变换比较法。与exhaustive类似,但效果略好,速度略慢。
参见:--merange
merange
默认: 16
merange控制运动搜索最大范围的像素数。hex和dia的范围在4-16,默认16;umh和esa可以大于默认值16,在更广的空间内进行运动搜索,对于高清视频和高速运动视频较为有用。注:umh, esa, tesa模式下增加会大幅降低编码速度。
merange开得太高(比如>64)也不太可能找到更多有用的运动向量,有时反而会导致压缩率略微降低:在少见情形下,某些运动向量只因当前有用而被选中,但由于这些向量的delta过大而影响了对之后运动向量的预测,得不偿失。
尽管这种影响非常小,几乎可以忽略不计,但一般都不应使用这么变态的设置。 见此贴
参见:--me
mvrange
默认: -1 (auto)
设置运动向量的最大垂直范围,单位是像素。默认值根据level而不同:
- Level 1/1b: 64
- Level 1.1-2.0: 128
- Level 2.1-3.0: 256
- Level 3.1+: 512
注:若想手动更改mvrange,可在上述值基础上减去0.25(如 --mvrange 127.75)
推荐值: 默认
mvrange-thread
默认: -1 (auto)
设置线程之间的最小运动向量缓冲。不要改动。
推荐值: 默认
subme
默认: 7
子像素(subpixel)估测复杂度,越大越好。数值1-5单纯控制子像素细化强度。数值6会开启模式决策RDO,数值8将开启运动向量和内部预测模式RDO。RDO模式大幅慢于低级模式。
采用低于2的值,会使用一种较快、但较低质量的lookahead模式,同时会影响--scenecut的决策,因此不推荐。
可选值:
0. fullpel only
1. QPel SAD 1 iteration
2. QPel SATD 2 iterations
3. HPel on MB then QPel
4. Always QPel
5. Multi QPel + bi-directional motion estimation
6. RD on I/P frames
7. RD on all frames
8. RD refinement on I/P frames
9. RD refinement on all frames
10. QP-RD (requires --trellis=2, --aq-mode > 0)
11. Full RD [1] [2]
推荐值: 默认或更高,除非很在乎速度
subq
也叫--subme
no-chroma-me
默认: 未开启
通常,运动预测同时作用于亮度和色度平面,此选项禁用色度运动预测,以换取少量的速度提升。
推荐值: 默认
psy-rd
默认: 1.0:0.0
第一个值是Psy-RDO的强度(需要subme>=6),第二个数是Psy-Trellis的强度(需要trellis>=1)。注:Trellis还在试验阶段,至少不该用于动画。
psy-rd的解释,详见 this
no-psy
默认: 未开启
禁用所有会降低PSNR或SSIM的视觉优化。同时禁用了内部psy优化,此功能无法通过x264命令行控制。
推荐值: 默认
no-mixed-refs
默认: 未开启
Mixed refs基于8x8区块选择参考,而非基于宏块,对于多ref模式能提升质量,但速度减慢。设定此项,会禁用该功能。
推荐值: 默认
参见:--ref
no-8x8dct
默认: 未设定
自适应8x8 DCT启用I帧内的智能自适应8x8 transforms,此选项禁用该功能。
推荐值: 默认
trellis
默认: 1
进行格子(Trellis)量化,以提升效率。
0. 禁用
1. 仅用于最终编码的宏块
2. 用于所有模式决策
用于宏块能较好地平衡速度和效率,用于所有模式(2)时会进一步降低速度,有时还会令细节模糊。
参见: Trellis Quantization
推荐值: 默认
注:需要--cabac
no-fast-pskip
默认: 未开启
禁用早期P帧跳过检测。低码率情况下,能提升一定的质量,但速度代价很大。高码率情况下,对速度和质量都影响不大。
推荐值: 默认
no-dct-decimate
默认: 未开启
为节省空间,x264会将某些块清零,因为其认为这些块即使清零也不会被观看者察觉到。这样通常能以忽略不计的质量损失换来编码效率的提升。但在极罕见的情况下会出错导致可见的痕迹(artifact)。此情况可以通过令x264不丢弃DCT块而减轻。
开启此选项,则禁用该功能。
推荐值: 默认
nr
默认: 未设定
进行快速降噪。根据此值估计影片的噪声,并尝试通过丢弃微小细节来去噪,然后再进行量化。效果也许不如外部降噪滤镜,但速度很快。
推荐值: 默认或(如需降噪:100至1000)
deadzone-inter/intra
默认: 未设定
设定inter/intra亮度量化deadzone的大小。Deadzones应介于0~32。deadzone值设定了x264对于何种精细程 度的细节,会选择丢弃而不保留。太精细的细节很难察觉,且编码代价大,丢弃这类细节能防止在低回报画面上浪费码率。Deadzone与Trellis 互不相容 。
推荐值: 默认
cqm
默认: Flat (未设定)
将所有自定义量化矩阵设为内置预设值。预设值包括 flat和 JVT。
推荐值: 默认
参见:--cqmfile
cqmfile
默认: 未设定
根据指定的JM-compatible的文件,设置所有自定义量化矩阵。自动忽略其它 --cqm*选项。
推荐值: 默认
参见:--cqm
cqm4* / cqm8*
默认: 未设定
- --cqm4: 设置所有4x4量化矩阵。接受用逗号分隔的16个整数
- --cqm8: 设置所有8x8量化矩阵。接受用逗号分隔的64个整数
- --cqm4i, --cqm4p, --cqm8i, --cqm8p: 设置相同的亮度和色度量化矩阵
- --cqm4iy, --cqm4ic, --cqm4py, --cqm4pc: 对亮度和色度使用不同的量化矩阵,cqm8选项也可用此开关。
推荐值: 默认
overscan
默认: undef
如何处理过扫描。此处过扫描指的是显示设备只显示画面的一部分。
可选值:
- undef - 未定义
- show - 指示显示全画面,理论上设定后会必须遵守。
- crop - 指示可在回放设备上使用过扫描,未必会被遵守。
推荐: 编码前先切掉那部分,然后如果设备支持,就用 show,若不支持,就忽略。
videoformat
默认: undef
指示视频在编码/数字化之前是什么类型。
可选值:
- component
- pal
- ntsc
- secam
- mac
- undef
推荐: 视频源的类型,或 未定义
range
默认: auto
指示亮度与色度level使用全范围还是有限的level。若设为TV,则使用有限的范围。若设为auto,则使用与输入相同的范围。
注意:若range与input-range的值不同,则编码时将进行范围转换。
简单解释,参见 this
推荐: 默认
参见:--input-range
colorprim
默认: undef
选择在转换为RGB时使用哪种基色。
可选值:
- undef
- bt709
- bt470m
- bt470bg
- smpte170m
- smpte240m
- film
参见: RGB 和 YCrCb
推荐值: 默认,除非你知道源用的是哪种
transfer
默认: undef
设定所使用的光电传输特性。(设置用于修正的gamma曲线)
可选值:
- undef
- bt709
- bt470m
- bt470bg
- linear
- log100
- log316
- smpte170m
- smpte240m
参见: Gamma Correction
推荐值: 默认,除非你知道源用的是哪种
colormatrix
默认: undef
设置从RGB基色计算得到亮度和色度所用的矩阵系数。
可选值:
- undef
- bt709
- fcc
- bt470bg
- smpte170m
- smpte240m
- GBR
- YCgCo
参见: YCbCr
推荐值: 源所使用的值,或默认
chromaloc
默认: 0
设置色度采样位置。(定义于 ITU-T规范的Annex E).
范围0 ~5
参见 x264's vui.txt
推荐值:
- 从MPEG1转码,使用正确的子采样4:2:0,且不做任何色彩空间转换,则该设为1
- 从MPEG2转码,使用正确的子采样4:2:0,且不做任何色彩空间转换,则该设为0
- 从MPEG4转码,使用正确的子采样4:2:0,且不做任何色彩空间转换,则该设为0
- 其它用默认
nal-hrd
默认: None
标记HRD信息。蓝光视频流、电视广播及其它特殊领域的必须要求。可选项:
- none无HRD信息
- vbr指示HRD信息
- cbr HRD信息,且将码流(bitstream)包装于bitrate所设置的码率,需要bitrate码率控制模式。
推荐值: none,除非需要
参见:--vbv-bufsize, --vbv-maxrate, --aud
filler
默认: None
允许在不使用nal-hrd的情况下产生高度恒定码率(hard-CBR)的流。
pic-struct
默认: 未开启
强制在Picture Timing SEI传送pic_struct
使用--pulldown或--tff/--bff时自动开启。
推荐值: 默认
crop-rect
默认: 未设定
在码流层指定一个切除(crop)矩形。若不想x264在编码时做crop,但希望解码器在回放时进行切除,可使用此项。单位为像素。
Input/Output(输入输出)
output
默认: 未设定
指定输出文件名。根据扩展名决定输出视频的格式。若扩展名无法识别,则默认输出raw视频流(通常以.264扩展名保存)
特殊位置 NUL (Windows) 或 /dev/null (Unix) 表明丢弃输出。特别常用于 pass 1,因为此时只在乎输出的 stats
muxer
默认: auto
指定写文件的格式。
可选值:
- auto
- raw
- mkv
- flv
- mp4
'auto'会自动根据输出文件的文件名来挑选。
参见:--output
推荐值: 默认
demuxer
默认: Automatically detected(自动检测)
设置x264分析输入视频所使用的demuxer和解码器。
可选值:
- auto
- raw
- y4m
- avs
- lavf
- ffms
若输入文件扩展名为raw, y4m或avs,x264会使用相应demuxer来读取文件。标准输入使用raw demuxer。其它扩展名,x264会依次尝试使用ffms,lavf来读取,无法读取则失败。
'lavf'和'ffms'选项要求x264在编译时包含了相应的库。两者之一被使用时,且输出非raw,则x264会提取使用输入文件的时间码。这使x264能有效得知VFR。其它选项可通过--fps来设定恒定帧率,或用--tcfile-in来设定可变帧率。
参见:--input, --muxer
推荐值: 默认
input-csp
默认: i420
告知x264输入raw视频所使用的色彩空间。支持的色彩空间列于x264 --fullhelp
参见:--input-res, --fps
output-csp
默认: i420
告知x264输出视频所使用的色彩空间。支持的色彩空间列于x264 --fullhelp
可选值:
- i420
- i422
- i444
- rgb
参见:--input-csp
input-range
默认: auto
指定视频源的色度与亮度level范围。设为TV则使用有限范围,设为PC则使用全范围。
注意:若range与input-range的值不同,则编码时将进行范围转换。
推荐值:默认,除非你知道片源的level是TV还是PC。
参见:--range
input-res
指定raw视频的输入分辨率。用法 --input-res 720x576
参见:--input-csp, --fps
index
默认: 未设定
仅在使用ffms --demuxer时有效的可选项。指定ffms读取输入视频所对应的索引文件,对之后的编码可用,免去重复索引。通常不需要,索引相对于编码过程来说,并不慢。
参见:--demuxer, FFMS2 API 文档
推荐值: 默认,除非你非要节省一分钟的索引时间。
sar
默认: 未设定
指 定编码所使用的输入视频的采样高宽比(Sample Aspect Ratio (SAR)),格式为"宽:高"。
与帧尺寸一起,通过决定显示高宽比(Display Aspect Ratio (DAR)),可用于编码可变高宽比的输出。公式:DAR = SAR x 宽/高
详见 here
推荐值: 使用resize滤镜和编码可变输入时,需要使用。
fps
默认: autodetected(自动检测)
指定视频帧率,可以是浮点数(29.970),或是分数(30000/1001),或整数(2997/100) 值。x264能从输入流的头信息里检测到帧率(仅限于y4m, avs, ffms, lavf),若没有,在使用25。使用此项会自动开启--force-cfr。
当使用raw YUV输入,且使用--bitrate模式,则必须用此选项或--tcfile-in指定帧率。否则x264不会达到目标码率。
seek
默认: 未设定
指定编码的起始帧,允许从源文件的某一时间点开始编码。
推荐值: 默认
frames
默认: 未设定
指定最大编码帧数,允许编码能在源文件结束前停止。
推荐值: 默认
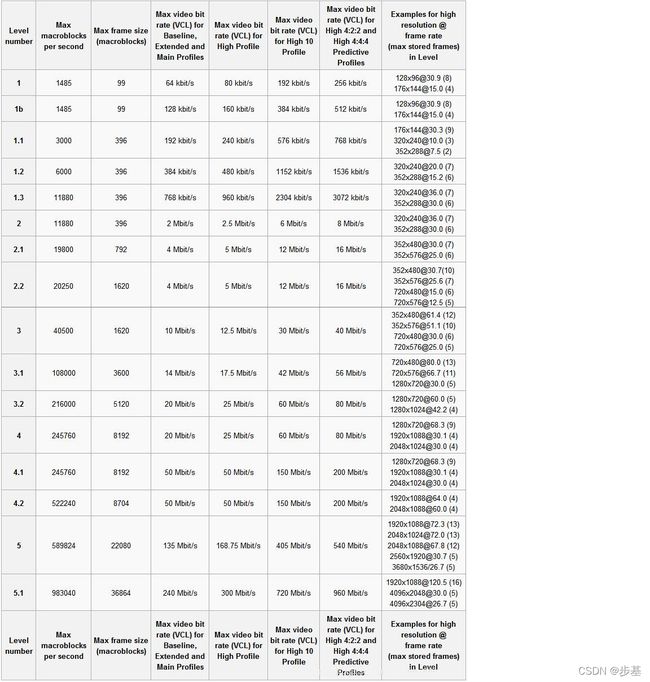
level
默认: -1 (auto)
设置输出码流的level标志。level越高视频质量也就越高。
级别:1 1b 1.1 1.2 1.3 2 2.1 2.2 3 3.1 3.2 4 4.1 4.2 5 5.1
设置方法:av_dict_set(¶m, "level", "4",0);
bluray-compat
默认: 未开启
修改x264的参数以更好地兼容所有蓝光播放器。只有当视频需要在硬件蓝光播放机上播放时,才需启用本设置。
此设置对参数做出以下修改:
- 将--weightp上限设为1(若不大于1,则不更改;若大于1,则降为1)
- 将--min-keyint设为1
- 禁用--intra-refresh
- 其它...
此设置还开启了一些x264的内部变更,以便生成的视频更利于硬件播放器的播放。例如:
- 修改GOP/mini-GOP的大小和参考列表
- 增加slice header的verbose内容
推荐值: 若用于蓝光硬件播放机,则开启本设置。
avcintra-compat
默认: 未开启
强制x264以支持High 10 Intra的profile(AVC Intra 50, AVC Intra 100, AVC Intra 200)进行编码。仅在需使用相关设备播放时开启本设置。
stitchable
默认: 未开启
不以视频内容来优化header,以保证能被附加(append)到分段的编码视频尾部。并保证当视频的各段采用完全相同的参数编码时,各段的header完全一致。
verbose
默认: 未开启
显示每一编码帧的统计信息。
推荐值: 默认
no-progress
默认: 未开启
关闭编码过程中的进度显示。
推荐值: 默认
quiet
默认: 未开启
开启安静模式,静默x264的状态消息。
推荐值: 默认
log-level
默认: info
手动指定x264cli和libx264的消息记录层级
可选值:
- none
- error
- warning
- info
- debug
推荐值: 默认
psnr
默认: 未开启
在编码结束时,报告 PSNR 值,略微减慢速度。
推荐值: 默认
ssim
默认: 未开启
在编码结束时,报告 SSIM 值,略微减慢速度。
推荐值: 默认
threads
默认: auto (基于帧编码的线程:1.5 * 逻辑处理器数,舍弃小数点;基于切片(slice-based)编码的线程:1 * 逻辑处理器数)
开启并行编码,利用多核系统的一个以上的线程来增加速度。多线程造成的质量损失可忽略不计,除非使用非常高的线程数(如大于16)。速度提升略低于线性,直至线程数> 一线程/垂直40像素,再往上速度提升大幅缩减。
x264目前内部限制最高线程数为 128,现实中不会使用到这么高。
推荐值: 默认
参见:thread-input, sliced-threads, opencl
sliced-threads
默认: off
开启基于基于切片(slice-based)的线程,该方法在压缩和效率上皆略输于默认方法,但没有编码延时。
最大切片线程数:MIN( (高+15)/16 / 4, 128 )
推荐值: 默认(off),除非需要编码实时流媒体,或是低延时很重要时。
thread-input
默认: threads > 1时,设为开启
使用与编码不同的线程来解码输入视频。
推荐值: 默认
sync-lookahead
默认: auto ( bframes+1)
设定threaded lookahead所用的缓冲帧数。最大值为 250。在2nd或后续pass,或是使用切片线程时,本选项自动关闭。
设置为0将禁用threaded lookahead,可降低延时,但性能下降。
推荐值: 默认
non-deterministic
默认: 未开启
当--threads > 1时,能略微提升质量,但输出不确定(non-deterministic)。会开启多线程mv,并在当slicetype为threaded时,使用整个lookahead缓冲来做slicetype决定,而非只用可用的最小量。
通常不用。
推荐值: 默认
参见: threads
opencl
默认: 未开启
当开启时,将look ahead线程大多分派给支持OpenCL的GPU设备。低分辨率intra成本预测,低分辨率运动搜索(包括subpel)和双向成本预测都在GPU上完成。对于不开启多线程lookahead(threaded lookahead)的preset(superfast, ultrafast),则根本不会使用到OpenCL。
小心:开启时,输出质量一般略逊于CPU模式的质量。驱动程序有bug时,编码速度有可能低于纯CPU x264,甚至可能导致系统崩溃。
opencl-clbin
默认: 未开启
在运行前,x264必须编译其针对你的设备的OpenCL内核,为避免在每次运行时都编译一次,x264会将编译完成的内核二进制码缓存于名为x264_lookahead.clbin的文件。
指定编译完的OpenCL内核缓存的路径以更改此路径。
opencl-device
默认: 未开启
x264将使用第一个支持OpenCL的GPU设备。大多现代的独立GPU或AMD的集成GPU都能用,Intel的集成GPU(IvyBridge及更早产品)不支持所需的特性。
当你的系统存在多余一个支持OpenCL的设备时,允许通过设备序号来指定运行lookahead的设备。
asm
默认: auto
忽略自动CPU检测。适用于debug和纠错。
推荐值: 默认
no-asm
默认: 未开启
禁用所有CPU优化。适用于debug和纠错。
推荐值: 默认
visualize
默认: 未开启
对编码后的视频启用宏块类型视觉化(Macroblock Type visualizations)。适用于一帧帧的debug和分析。
需要compile time支持,及X11 windowing system。
已弃用,并在最新build中去除。
推荐值: 默认
dump-yuv
默认: 未设定
将重构的YUV帧放入指定文件内。主要用于debug,通常不用。
推荐值: 默认
sps-id
默认: 未设定
设定SPS (序列参数组sequence parameter set)和PPS (图像参数组picture parameter set)ID数。通常不用。
推荐值: 默认
aud
默认: 未开启
使用接入单元(access unit)分割。
推荐值: 默认,若编码蓝光,则需设定此选项。
force-cfr
默认: 未开启
使用ffms2或lavf demuxers时,时间码复制于输入文件(假设输出不是raw)。此选项禁止该方式,转而强制x264自己生成时间码。使用此选项时,最好同时设定--fps。
推荐值: 默认
tcfile-in
指定一个时间码文件,用于解释输入视频的帧率。时间码文件格式有两种:v1和v2。 解释详见此mkvmerge文档
参见: tcfile-out, force-cfr, fps
tcfile-out
根据输入的时间戳,输出一个时间码文件(v2格式)。用于VFR输入视频且想丢弃时间码时。文件的格式,参见 tcfile-in
timebase
默认: 未设定
允许设定自定义时基(timebase)。
分子是秒数(seconds),分母是嘀嗒数(tick)。意思是一个滴答耗时多少秒。
- 若是分数,则会相应设置分子和分母。
- 若是整数,且输入时间码文件由tcfile-in设定,则会使用该值作为分子,然后相应生成分母。
- 若是整数,且未设置时间码文件,则会使用该值作为分母,并由输入视频生成"每帧嘀嗒数"。
与--force-cfr模式不兼容。
推荐值: 默认
dts-compress
默认: 未开启
小功能,仅用于FLV和MP4容器,以绕过某些有问题(认为DTS都是正的)的解码器。对于此改变, 谨慎使用.
注:DTS指的是解码时间戳( Decode Time Stamp)。每一帧都分配了一个DTS,对应其在流媒体“编码顺序”中的位置,不同于由显示时间戳( Presentation Time Stamp)指定的“显示顺序”。各帧在视频流中保存的顺序与显示的顺序不同(由于诸如B帧压缩之类的压缩技术),造成某些帧需要后续显示的帧的数据。
video-filter
x264滤镜系统用于在编码前处理输入视频。可以一定次序使用多个滤镜。
滤镜基本语法如下:--video-filter
多个滤镜依此用/分隔:--video-filter
可以“连接”随意多个滤镜。
可用滤镜包括:
crop
句法:crop:left,top,right,bottom
切除画面边缘的像素。
- 对于yv12i, i420i, nv12i格式的输入视频,在高度上切除像素个数必须为4的整数倍。
- 对于yv12p, i420p, nv12p格式的输入视频,或以上未列出的其它隔行视频作为输入视频,在高度上切除像素个数必须为2的整数倍。
- 对于i420, i422, yv12, yv16, nv12, nv16格式的输入视频,在宽度上切除像素个数必须为2的整数倍。
resize
句法:resize:[width,height][,sar][,fittobox][,csp][,method]
Resizes帧,或转换色彩空间。需要x264编译时包含 libswscale
有以下几种resize模式:
- 仅分辨率(Resolution only): 将画面resize到指定分辨率,并改变SAR以避免拉伸
- 仅SAR(SAR only): 设置SAR,并将画面resize到新的分辨率,以避免拉伸
- 分辨率+SAR(Resolution + SAR): resize画面至指定分辨率,并指定SAR值,允许存在拉伸
- 适应(Fittobox): 根据指定的画面大小resize画面,自适应分辨率,以保证SAR为1:1
- 宽度(width): resize画面以符合指定的宽度
- 高度(height): resize画面以符合指定的高度
- 宽高(both): resize画面以符合指定的画面大小限制
- 适应+SAR(Fittobox + SAR): 与普通Fittobox模式类似,但按指定的SAR生成画面,将视频缩小使可变视频符合指定的大小限制。
与resize模式无关的选项有:
- csp: 同时将画面转换至指定的色彩空间,可用色彩空间列于x264 --fullhelp
- method (默认为bicubic): resize画面,并指定resize方法
fastbilinear, bilinear, bicubic, experimental, point, area, bicublin, gauss, sinc, lanczos, spline
例子:
resize:width=1280,height=720,method=spline
select_every
句法:select_every:step,offset1[,offset2,...]
仅"选择"一部分输入帧进行编码,丢弃其它帧。每隔step个帧,仅使用指定offset位置的帧。比如:每隔两帧采用一帧 select_every:2,1
每隔三帧,丢弃第三帧 select_every:3,0,1