深入学习JavaScript系列(四)——JS闭包
本篇为此系列第四篇
第一篇:#深入学习JavaScript系列(一)—— ES6中的JS执行上下文
第二篇:# 深入学习JavaScript系列(二)——作用域和作用域链
第三篇:# 深入学习JavaScript系列(三)——this
第四篇:# 深入学习JavaScript系列(四)——JS闭包
第五篇:# 深入学习JavaScript系列(五)——原型/原型链
第六篇: # 深入学习JavaScript系列(六)——对象/继承
第七篇:# 深入学习JavaScript系列(七)——Promise async/await generator
闭包的概念和执行上下文,作用域,作用域链密不可分,建议先阅读前两篇后在阅读本文。
一 闭包的概念
当一个函数在访问它所在的词法环境之外的变量时,就形成了闭包。简单来说,闭包就是一个函数能够访问其父级作用域中的变量
一个闭包通常由两部分组成:函数体和创建函数时的作用域。
js 的函数都会创建自己的执行环境(函数作用域),函数的局部变量和参数都存储在该环境中。当函数执行完毕后,该执行环境会被销毁,其中的局部变量和参数也随之消失。
如果在函数内部定义了一个函数,并且这个函数访问了父级函数的变量或参数,那么这个内部函数就会形成一个闭包,因为它需要在父级函数执行完毕后,仍然能够访问到父级函数中的变量或参数。
简单来说:就是在一个执行上下文中创建的函数,如果访问了这个执行上下文中变量对象的值,那么闭包就产生了。
闭包可以用来实现一些特殊的功能,比如在 JavaScript 中创建私有变量。例如,可以在一个函数内部定义另一个函数,将该函数作为返回值返回,这样就可以在函数外部通过闭包访问到函数内部的变量,但又不会暴露给全局作用域。
举个例子:
function foo() {
var a = 20;
var b = 30;
function bar() {
return a + b;
}
return bar;
}
var bar = foo();
bar();
在上面的例子中 foo()产生的执行上下文中创建了bar(),同时调用了foo中的变量a 和b 这样就产生了闭包,那么具体哪个函数是闭包呢,大部分文章都说bar就是闭包函数。
我根据上面的定义分析,闭包实际是bar函数+包含bar函数的foo上下文组成
二 闭包的特点
-
捕获父函数作用域中的变量或参数,并在子函数返回后仍然保留对这些值的引用。
-
访问父级函数的变量,即使父级函数已经返回,这就是所谓的“记忆效应”。
-
扩展函数作用域,允许外部访问内部函数的作用域。这种能力使得 JavaScript 中可以使用很多强大的编程模式,例如模块化设计和函数柯里化。
-
可能导致内存泄漏和性能问题。如果闭包长时间持有对大型数据结构的引用,则可能会导致内存泄漏。此外,闭包可能会对程序性能产生一定程度的影响,因为每个闭包都需要维护一个作用域链。
通过一段代码来看一下
function outerFunction() {
let outerVariable = "I am outside!";
function innerFunction() {
console.log(outerVariable);
}
return innerFunction;
}
let closure = outerFunction();
closure(); // 输出 "I am outside!"
outerFunction 是一个创建闭包的函数。它定义了一个内部函数 innerFunction,并返回该函数的引用。在 innerFunction 中,我们可以访问 outerFunction 的外部变量 outerVariable。
当我们调用 outerFunction 并将其返回值赋给 closure 变量时,closure 变量实际上保存了 innerFunction 的引用,以及对 outerVariable 变量的引用。由于 JavaScript 中的所有函数都是对象,因此可以返回对它们自己的引用。
当我们调用 closure() 时,它执行了 innerFunction 中的代码,并在控制台上输出 outerVariable 的值,即 “I am outside!”。这是因为 innerFunction 可以访问 outerVariable,即使它已经超出了 outerFunction 的作用域。
这就是闭包的主要特点之一:一个函数可以捕获其父级函数中的变量或参数,并在该函数返回后仍然保留对这些值的引用。在这种情况下,innerFunction 捕获了 outerVariable,并创建了一个闭包,使得我们可以在 closure() 调用中访问它。
闭包的优缺点
优点:
封装变量和方法,避免全局污染和命名冲突,并提高代码的可维护性和安全性。- 创建私有作用域。从而限制外部访问内部变量和方法的能力。
- 延长变量生命周期。将变量的生命周期延长到函数执行完成后,使其在函数外部仍然可被引用。
- 支持函数式编程,例如高阶函数、柯里化和函数组合等。
- 可以使用在异步编程中,闭包可以捕获异步操作期间所需的上下文和状态,并在操作完成后提供回调。
缺点:
- 内存泄漏。如果闭包长时间持有对大型数据结构的引用,则可能会导致内存泄漏。
- 性能问题。由于每个闭包都需要维护一个作用域链,它们可能会对程序性能产生一定程度的影响。
- 难以理解和调试。复杂的嵌套函数和闭包嵌套可能会使代码难以理解和调试,因此需要小心使用。
- 容易出错。错误使用闭包可能会导致应用程序中的 bug 和安全问题。
- 代码复杂。使用闭包可能会增加代码的复杂性,使其更难以阅读和理解。
三 闭包的应用场景
封装变量
使用闭包封装全局变量,能防止变量污染,通过创建一个函数并在其中定义变量来完成,然后将该函数返回为内部函数。通过这种方式,内部函数可以访问外部函数的变量,但外部函数的变量不会暴露给全局范围。
function createCounter() {
let count = 0;
function increment() {
count++;
console.log(count);
}
return increment;
}
let counter = createCounter();
counter(); // 输出 1
counter(); // 输出 2
创建createCounter 函数,该函数定义变量 count 和一个内部函数 increment。当我们调用 createCounter 并将其返回值赋给 counter 变量时,counter 变量实际上保存了 increment 的引用以及对 count 变量的引用。由于 count 变量是在 createCounter 函数内部定义的,因此它不会被其他代码所访问。
每次调用 counter 函数时,它都会执行 increment 中的代码,并在控制台输出当前计数器的值。由于 increment 函数捕获了 count 变量,因此它可以增加计数器的值并在每次调用时输出正确的结果。
模块封装:
利用闭包封装了私有变量和方法,以便可以在需要时安全地公开公共接口。
let myModule = (function() {
let privateVariable = "I am private";
function privateFunction() {
console.log("This is a private function.");
}
return {
publicVariable: "I am public",
publicFunction: function() {
console.log("This is a public function.");
},
accessPrivate: function() {
console.log(privateVariable);
privateFunction();
}
};
})();
console.log(myModule.publicVariable); // 输出 "I am public"
myModule.publicFunction(); // 输出 "This is a public function."
myModule.accessPrivate(); // 输出 "I am private" 和 "This is a private function."
自调用函数表达式(Immediately Invoked Function Expression, IIFE)创建一个立即执行的函数,并使用闭包创建一个模块。在模块中,定义了一个私有变量 privateVariable 和一个私有方法 privateFunction。然后,我们返回一个具有公共变量和方法的对象字面量,以便可以在需要时从外部访问它们。最后,我们将对象字面量赋给 myModule 变量,以便可以在其他代码中使用它。
可以从外部访问公共变量和方法,而不能直接访问私有变量和方法。这样可以确保私有状态不会被意外修改或泄漏,并提高了代码的可维护性和安全性。
其他问题
1、闭包与作用域的关系
闭包是通过作用域链实现的,它可以访问其父级函数的作用域,即使该函数已经退出。闭包可以保留对父级作用域中变量的引用,这是基于作用域链的特性,可以利用闭包来封装变量、延长变量生命周期、创建私有作用域等。
2、 闭包和垃圾回收机制的关系
闭包可以导致内存泄漏,并影响垃圾回收机制的表现。这是因为闭包可以继续引用从其父级作用域中捕获的变量和对象,即使该函数已经退出。
垃圾回收机制是负责释放不再使用的对象和变量,以便节省内存空间的一部分。为此,它会周期性地检查应用程序中的变量和对象,并删除不再使用的内容。但是,如果闭包仍然引用某些变量或对象,则它们将无法被垃圾回收器释放,从而导致内存泄漏。
避免内存泄漏的方法是在使用完成引用后取消引用,赋值null
function createClosure() {
let bigObject = { /* 大型数据结构 */ };
return function() {
// 使用 bigObject
};
}
let closure = createClosure();
// 执行代码后,手动解除对 bigObject 的引用
closure = null;
将其设置为 null,从而手动解除对 bigObject 的引用
3 闭包和面向对象编程的关系
1.隐藏状态。在面向对象编程中,我们经常使用类来封装数据和方法,并限制对其状态的直接访问。同样,使用闭包也可以隐藏变量和方法,以避免全局污染和命名冲突。
2、封装与继承。在面向对象编程中,我们可以利用封装和继承来组合代码块并创建可维护和可扩展的应用程序。同样,使用闭包也可以实现类似的效果,通过将内部函数作为公共方法返回,并捕获所需的上下文和状态来实现。
3、模块化编程。面向对象编程和闭包都支持模块化编程,可以帮助我们组织代码和提高代码的可重用性。特别地,使用闭包可以实现自包含的组件和库,而无需暴露其内部实现细节。
4、 函数式编程。函数式编程强调函数的纯粹性和不可变性,并使用高阶函数、柯里化和函数组合等技术来实现。同样,使用闭包也可以支持函数式编程,通过创建一个不可变的状态和相应的函数来实现。
4 闭包与异步编程的关系
闭包可以捕获异步操作期间所需的上下文和状态,并在操作完成后提供回调。
异步编程是通过回调函数实现的,它们被传递给异步函数并在操作完成后被调用。由于回调函数是在异步函数调用之外定义的,因此它们无法直接访问异步函数中的变量和对象。但是,使用闭包可以轻松地解决这个问题,从而使回调函数能够访问所需的上下文和状态。
示例:
function fetchData(url, callback) {
fetch(url)
.then(response => response.json())
.then(data => callback(data))
.catch(error => console.error(error));
}
let data;
fetchData('https://api.example.com/data', function(response) {
data = response;
console.log(data);
});
定义了一个 fetchData 函数,该函数采用一个 URL 和回调函数作为参数。在内部,它使用 fetch API 来获取数据,并在操作完成后将结果传递给回调函数。然后,我们调用 fetchData 并向其中传递一个匿名函数作为回调。在回调函数中,我们将返回的数据保存在 data 变量中,并在控制台中输出它。
由于回调函数是在异步函数调用之外定义的,因此它可以通过闭包访问 data 变量,即使它在异步操作开始之前被定义。这使得我们可以在异步操作完成后处理数据,并避免在异步操作期间出现竞争条件和其它问题。
5 ES6中箭头函数对闭包的影响
箭头函数没有自己的 this 值、arguments 对象和 super 关键字。这意味着它们只能使用父级作用域中的这些值。此外,箭头函数始终捕获其定义时的上下文,而不是调用时的上下文。
由于箭头函数没有自己的 this 值,当它们嵌套在另一个函数内部时,它们可以继承其父级函数的 this 值,从而避免了使用 bind() 或变量保存 this 的需要。这也意味着,在使用箭头函数时,可能需要注意 this 的上下文,并避免在非预期的情况下修改它的值。
由于箭头函数始终捕获其定义时的上下文,因此它们可能会对闭包的行为产生影响。如果在箭头函数中使用闭包并且其中包含了对其所引用的变量的改变,则这些变化会持续存在,直到程序退出。这可能会导致内存泄漏和其他问题。
闭包代码题
经典题目一
for (var i = 0; i < 5; i++) {
setTimeout(function() {
console.log(new Date, i);
}, 1000);
}
console.log(new Date, i);
// 5,5,5,5,5,5
// 错误: 5 -> 5 -> 5 -> 5 -> 5 ;正确: 5 -> 5,5,5,5,5
解读:
1、这里涉及了闭包和异步,for循环是立即执行的,定时器的内容则是异步的 且采用var 的方式设置的是全局变量,因此第一次定时器打印的时候就输出5(因为for循环已经执行6次,执行结束之后才到异步的定时器执行),所以打印六次都是5
2 用箭头表示其前后的两次输出之间有 1 秒的时间间隔,而逗号表示其前后的两次输出之间的时间间隔可以忽略 那么实际打印的结果如上 第一个5直接输出,1秒后输出5个5。
具体参考# 前端基础进阶(六):setTimeout与循环闭包面试题详解:
继续:如果想把输出结果改为:5 -> 0,1,2,3,4
怎么改呢?
方案一: let
首先想到最简单的就是使用let,这样就解决了i被设置成全局变量的问题。
for (let i = 0; i < 5; i++) {
setTimeout(function() {
console.log(new Date, i);
}, 1000);
}
console.log(new Date, i);
打印结果如下:
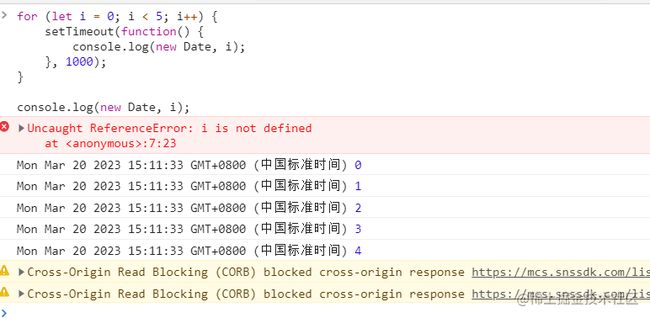
会报错 因为i只在for循环的作用域内,log无法取到。
方案二: 立即执行函数
for (var i = 0; i < 5; i++) {
(function(j) { // j = i
setTimeout(function() {
console.log(new Date, j);
}, 1000);
})(i);
}
console.log(new Date, i);
解释:这个方法还没太弄明白 后续需要学习一下
方案三:利用setTimeout第三个参数
for (var i = 0; i < 5; i++) {
setTimeout(function(j) {
console.log(new Date, j);
}, 1000, i);
}
console.log(new Date, i);
解释:使用setTimeout的第三个参数 返回附加参数 setTimeout -MDN
方案四: 把函数提取出来
var output = function (i) {
setTimeout(function() {
console.log(new Date, i);
}, 1000);
};
for (var i = 0; i < 5; i++) {
output(i); // 这里传过去的 i 值被复制了
}
console.log(new Date, i);
解释:这样的话每次传参的i是不一样的,打印出来的i也不一样。
继续:如果期望代码的输出变成 0 -> 1 -> 2 -> 3 -> 4 -> 5,并且要求原有的代码块中的循环和两处 console.log 不变,该怎么改造代码?
方案一:暴力解法
for (var i = 0; i < 5; i++) {
(function(j) {
setTimeout(function() {
console.log(new Date, j);
}, 1000 * j); // 这里修改 0~4 的定时器时间
})(i);
}
setTimeout(function() { // 这里增加定时器,超时设置为 5 秒
console.log(new Date, i);
}, 1000 * i);
解释: 把for循环内的定时器设置为0-4秒打印 增加一个第五秒打印的定时器
方案二: promise大法
const tasks = [];
for (var i = 0; i < 5; i++) { // 这里 i 的声明不能改成 let,如果要改该怎么做?
((j) => {
tasks.push(new Promise((resolve) => {
setTimeout(() => {
console.log(new Date, j);
resolve(); // 这里一定要 resolve,否则代码不会按预期 work
}, 1000 * j); // 定时器的超时时间逐步增加
}));
})(i);
}
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(new Date, i);
}, 1000); // 注意这里只需要把超时设置为 1 秒
});
方案三: promise的简洁写法
const tasks = []; // 这里存放异步操作的 Promise
const output = (i) => new Promise((resolve) => {
setTimeout(() => {
console.log(new Date, i);
resolve();
}, 1000 * i);
});
// 生成全部的异步操作
for (var i = 0; i < 5; i++) {
tasks.push(output(i));
}
// 异步操作完成之后,输出最后的 i
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(new Date, i);
}, 1000);
});
方案四:最终写法 async await
// 模拟其他语言中的 sleep,实际上可以是任何异步操作
const sleep = (timeountMS) => new Promise((resolve) => {
setTimeout(resolve, timeountMS);
});
(async () => { // 声明即执行的 async 函数表达式
for (var i = 0; i < 5; i++) {
if (i > 0) {
await sleep(1000);
}
console.log(new Date, i);
}
await sleep(1000);
console.log(new Date, i);
})();
代码题一是参考了王仕军大佬的文章(详情见文末参考四),写的很好,我水平有限其中很多地方还没有理解透,有兴趣的同学可以去看原文,相信肯定能收获很多
闭包实现计数器函数
function createCounter() {
let count = 0;
return function() {
count++;
console.log(count);
};
}
let counter = createCounter();
counter(); // 输出 1
counter(); // 输出 2
counter(); // 输出 3
// ...
使用闭包实现一个缓存函数
function createCache() {
let cache = {};
return function(key, value) {
if (value === undefined) {
// 如果未提供值,则返回缓存中的值(如果存在)
return cache[key];
} else {
// 如果提供了值,则将其保存到缓存中并返回它
cache[key] = value;
return value;
}
};
}
let cache = createCache();
cache('foo', 'bar'); // 返回 'bar'
cache('baz'); // 返回 undefined
console.log(cache('foo')); // 输出 'bar'
总结
一个闭包通常由两部分组成:函数体和创建函数时的作用域,就是在一个执行上下文中创建的函数,如果访问了这个执行上下文中变量对象的值,那么闭包就产生了
水平有限,很多地方写的不够严谨,下面几篇是我在学习过程中觉得很好的文章,想继续深入了解的同学可以去看看。
参考链接:
参考一:# [译]发现 JavaScript 中闭包的强大威力
参考二:# JavaScript闭包的底层运行机制
参考三:# 我从来不理解JavaScript闭包,直到有人这样向我解释它…
参考三:# 破解前端面试(80% 应聘者不及格系列):从闭包说起