多任务编程习题(相关简答)
1. 线程与进程的区别?
(1)进程:进程是程序的一次执行过程,是一个动态概念,是程序在执行过程中分配和管理资源的基本单位,每一个进程都有一个自己的地址空间,至少有 5 种基本状态,它们是:初始态,执行态,等待状态,就绪状态,终止状态。
(2)线程:线程是CPU调度和分派的基本单位,它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
(3)联系与区别:
- 线程是进程的一部分,一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
- 进程是资源分配的最小单位,线程是程序执行的最小单位。
- 进程有自己的独立地址空间。线程是共享进程中的数据的,使用相同的地址空间.
- 进程之间的通信需要以通信的方式(IPC)进行。线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据。
难点:处理好同步与互斥。
2. 进程间内存是否共享?如何实现通讯?
进程间内存是共享的:

进程间实现通讯的方法有:

但主要有:共享内存、信号、管道、消息队列四种,其通信特点:
| 通信方法 | 无法介于内核态与用户态的原因 |
| 管道(不包括命名管道) | 局限于父子进程间的通信。 |
| 消息队列 | 在硬、软中断中无法无阻塞地接收数据。 |
| 信号量 | 无法介于内核态和用户态使用。 |
| 共享内存 | 需要信号量辅助,而信号量又无法使用。 |
4. 多线程有几种实现方法,都是什么?
方法一:python的threading 模块。
例如:

方法二:重写run方法。
例如:

5.GIL锁是怎么回事?
GIL即全局解释器锁,简单来说就是一个互斥体(或者说锁),这种机制的存在只允许一个线程来控制Python解释器。
这就意味着在任何一个时间点只能有一个线程处于执行状态。GIL对执行单线程任务的程序员们来说并没什么显著影响,但是它对计算密集型(CPU-bound)和多线程任务的影响是比较大的。 由于GIL即使在拥有多个CPU核的多线程框架下都只允许一次运行一个线程,因此成为众多python功能的一大问题。但为什么开发人员还是选择了GIL呢?
1)GIL解决了Python中的问题:
Python利用引用计数来进行内存管理,这就意味着在Python中创建的对象都有一个引用计数变量来追踪指向该对象的引用数量。当数量为0时,该对象占用的内存即被释放。这个引用计数变量需要在两个线程同时增加或减少时从竞争条件中得到保护。如果发生了这种情况,可能会导致泄露的内存永远不会被释放,抑或更严重的是当一个对象的引用仍然存在的情况下错误地释放内存。这可能会导致Python程序崩溃或带来各种诡异的bug。通过对跨线程分享的数据结构添加锁定以至于数据不会不一致地被修改,这样做可以很好的保证引用计数变量的安全。
2)选取GIL作为解决方案的原因:
- 当操作系统还没有线程的概念的时候Python就一直存在着。Python设计的初衷是易于使用以便更快捷地开发。人们针对于C库中那些被Python所需的功能写了许多扩展,为了防止不一致变化,这些C扩展需要线程安全内存管理,而这些正是GIL所提供的。
- GIL是非常容易实现而且很容易添加到Python中。因为只需要管理一个锁所以对于单线程任务来说带来了性能提升。
- 因此,GIL是CPython开发者在早期Python生涯中面对困难问题的一种实用解决方案。
3)GIL对多线程Python程序的影响:
- GIL对I/O密集型任务多线程程序的性能没有太大的影响,因为在等待I/O时锁可以在多线程之间共享。
- 但是对于一个线程是完全计算密集型的任务来说(例如,利用线程进行部分图像处理)不仅会由于锁而变成单线程任务而且还会明显的增加执行时间。正如上例中多线程与完全单线程相比的结果。
- 这种执行时间的增加是由于锁带来的获取和释放开销。
4)处理Python中的GIL的方法:
多进程vs多线程:最流行的方法是应用多进程方法,在这个方法中你使用多个进程而不是多个线程。每一个Python进程都有自己的Python解释器和内存空间,因此GIL不会成为问题。
注:如果想了解GIL的低层次内部运行,建议选择观看David Beazley的Understanding the Python GIL。
6. python中是否线程安全?如何解决线程安全?
线程优点: 在⼀个进程内的所有线程共享全局变量,能够在不使⽤其他⽅式的前提 下完成多线程之间的数据共享(这点要⽐多进程要好) 线程缺点: 线程是对全局变量随意遂改可能造成多线程之间对全局变量 的混乱(即线程⾮安全)
解决方法:
使用全局解释器锁(GIL):Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
7. 什么叫死锁?
在多道程序系统中,由于多个进程的并发执行,改善了系统资源的利用率并提高了系统的处理能力。然而,多个进程的并发执行也带来了新的问题——死锁。所谓死锁是指多个进程因竞争资源而造成的一种僵局,若无外力作用,这些进程都将无法向前推进。(或者说:在线程间共享多个资源的时候,如果两个线程分别占有⼀部分资源并且同时 等待对⽅的资源,就会造成死锁。)
避免死锁的几种办法:
- 避免多次锁定。尽量避免同一个线程对多个 Lock 进行锁定。
- 具有相同的加锁顺序。如果多个线程需要对多个 Lock 进行锁定,则应该保证它们以相同的顺序请求加锁。
- 使用定时锁。程序在调用 acquire() 方法加锁时可指定 timeout 参数,该参数指定超过 timeout 秒后会自动释放对 Lock 的锁定,这样就可以解开死锁了。
- 死锁检测。死锁检测是一种依靠算法机制来实现的死锁预防机制,它主要是针对那些不可能实现按序加锁,也不能使用定时锁的场景的。
8. 什么是协程?常用的协程模块有哪些?
1)定义:
协程与子例程一样,协程(coroutine)也是一种程序组件。又称微线程、纤程。协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。相对子例程而言,协程更为一般和灵活,但在实践中使用没有子例程那样广泛。
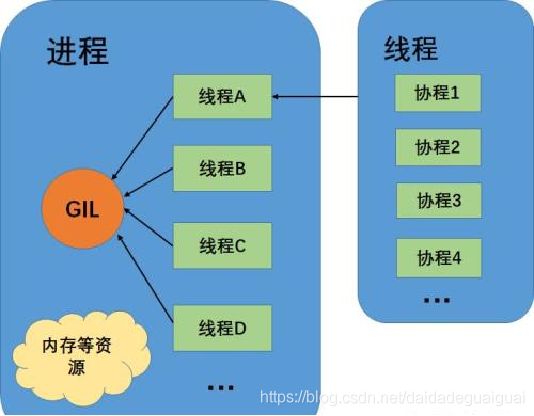
2)协程优势:
- 执行效率极高,因为子程序切换(函数)不是线程切换,由程序自身控制;
- 没有切换线程的开销。所以与多线程相比,线程的数量越多,协程性能的优势越明显;
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁,因此执行效率高很多。
3)协程缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序。
3)常用的协程模块:
- python自带的yield
- 用C实现的greenlet是一个协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator(生成器)
- Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
9. 协程中的join是用来做什么用的?它是如何发挥作用的?
1.协程执行时要想使任务执行则必须对协程对象调用join函数
2.有多个任务时,随便调用哪一个的join都会并发的执行所有任务,但是需要注意如果一个存在io的任务没有被join该任务将无法正常执行完毕
join函数源码在greenlet.py中的Greenlet类的join():
ef join(self, timeout=None):
if self.ready(): #检测是否执行完成
return
else:
switch = getcurrent().switch #获得当前greenlet的switch回调函数
self.rawlink(switch)
try:
t = Timeout.start_new(timeout)
try:
result = self.parent.switch()
assert result is self, 'Invalid switch into Greenlet.join(): %r' % (result, )
finally:
t.cancel()
except Timeout as ex:
self.unlink(switch)
if ex is not t:
raise
except:
self.unlink(switch)
raise从join的源码第六行,跟踪到rawlink函数:
def rawlink(self, callback):
if not callable(callback):
raise TypeError('Expected callable: %r' % (callback, ))
self._links.append(callback)
if self.ready() and self._links and not self._notifier:
self._notifier = self.parent.loop.run_callback(self._notify_links)可以看出,这个rawlink函数的目的只有一个:注册当前greenlet的回调函数(第四行), 当主协程hub还没有run的时候,这个时候的greenlet可以理解为一个上下文。
回到join函数。在注册了当前greenlet的回调函数后,主要干的事是第10行:切换到主协程hub
它会执行greenlet.switch(self),由于当前协程为hub,并且没有运行过run,所以会执行hub.run函数,源码在hub.py下的Hub类里面。在这个函数里面就会执行gevent的一般流程。
以下函数的输出:
def test1(id):
print(id)
gevent.sleep(0)
print(id, 'is done!')
t = gevent.spawn(test1, 't')
gevent.sleep(0)输出(为什么没有继续输出t is done!?):
t因此join()的作用是:
- 创建子协程t
- 执行到sleep函数,由于此时主协程hub还没有运行hub.run(),sleep函数中,语句
loop.run_callback(waiter.switch)保存的是当前协程(可以理解为上下文)的回调函数 - 调用
waiter.get()函数 waiter.get()函数调用hub.switch(),切换到主协程hub- 由于主协程没有run,所以执行
hub.run()函数 - 执行loop.run(),切换到子协程t中
- 执行
_run()函数,即子协程的任务:我们定义的test1函数 - 当执行完test1中的
sleep(0)的时候,会回到主协程hub,hub会执行之前保存的回调函数,即回到了上下文,不会再回到主协程hub,所以不会输出t is done!