AIMA 第三版 笔记
aima被传很难啃,我觉得跟中文翻译时追求保留原书内容有关吧。
如果让某个知之者来读,然后写一篇更简洁的笔记。
相当于有人帮你消化了知识,后来者再看会不会更轻松一点?
Part2 问题求解
Chaper3 通过搜索进行问题求解
3.1 Overview
如果学过数据结构,再来看这个入门第一篇章,应该是很轻松的。
我觉得这个篇章,放在入门这里,最重要的是去习惯【2个概念】:
①评价 evaluation 表示某一步的【好坏】。大部分情况下,其本质上是个【数值】!
②启发 heuristic 评估某一步的【成本】。同上,基本可以当【数值】来看。
(heuristic 这东西很怪,看起来像个形容词,翻译过来又很模糊,就成了阅读上的劝退点之一。)
无论哪个领域,所谓学习就是学到圈内人的【语言】,适应并使用这些【语言】。
在这一章,只需要掌握上述2个新单词,比背英语简单。
通常我们在一本书里会有默认的符号体系。
①evaluation,在n结点的评价值,记为f(n)
②heuristic , 从n点出发到目标点的启发值(成本大小), 记为 h(n)
③accumulated cost, 从起始点到达n点的累计成本 , 记为 g(n)
很显然,我们可以用不同的方法来做【评估】。
例如, 令f(n) = h(n) , 此举下,我们以【从n点往下走的启发值】作为评估值,f(n)越大,则认为这个n越坏。
例如,令f(n) = g(n) + h(n) , 此举下,我们综合考虑 【到达n点累积的成本】与【从n点往下走需要消耗的成本】,f(n)越大,则认为n越坏。
显然,f(n)是一个超然的东西,你可以自己任意指定一种方式,来计算【评估值】。
而评估值是bigger-better还是smaller-better,也是随自己心意的。
还有一些其他细枝末节的概念
完备性 comleteness, 若有解则必得之,若未得则必无解。
最优性 optimism (似乎又叫optimistic efficiency?)
问题形式化(problem formulation)是给定一个目标,决定要考虑的动作与状态的处理。
- 全态形式化 (Complete-state formulation) 比如八皇后问题一开始就上八个皇后直击终极目标
- 增量形式化 (Incremental formulation) 比如开局一皇后,每次加一个皇后
补充一句话
有限状态空间的图搜索是完备的(complete)。
【无限图(infinity graph)的搜索却未必。】
3.2 无信息搜索 Uninformed search
又称blind search
本节就4种基本算法,对应到数据结构的树图部分。
- breadth-first 广度优先 ,空间O(b^d), b是expand factor,举例,二叉树的话就是2。d 是最浅解深度。
- depth-first 深度优先 时间O(b^m) ,m for some depth 某个解深度。
- uniform-cost 一致代价搜索 (注意uniform和uninform的区别)
- Bidirectional search 双向搜索
2)
稍微值得一提的是,在图搜索中,如果是无限图,depth-first显然会失效。
于是我们很自然的想,如果限制depth到某个定值,再去搜索好不好呀?
于是得到 depth-first family的一个成员。给定mak_depth = K
Depth-limited Search 深度受限搜索。
进一步的,我们又会很自然的想,我们慢慢增大K的值,这样再去搜不是更好吗?
于是又得到一个
Iterative Deepening Search 迭代加深搜索。
就是做了点微小改进罢了。
3)
一致代价搜索中,评价函数f(n) = g(n), 选择这个函数是无可奈何的事。
因为我们得不到未来的信息,只能知道自己的累积成本。
3.3 有信息搜索 informed search
因为引入了外部信息,所以往往比无信息搜索能更好地求解。很好理解。
本节用经典的罗马尼亚问题引出2个算法
- Greedy Best-first Search 贪婪最值优先搜索(GBS) , f(n) = h(n)
- A* Search A星搜索 , f(n) = g(n) + h(n)
两个算法唯一的区别就在于评价函数。
采用 f(n) = h(n) 的贪婪搜索之所以失败,核心原因在于h(n)只是一个【实际cost的估计值】。
每次都选【估计值最小的节点】,就有可能漏掉一些【实际cost最小、但是估计值并非最小的最优解】。
这也是无可奈何的事情。
而采用A*的好处是,加入了一个accumulated cost,使贪婪的人稍微清醒一点。
如果输光了裤子就别头铁了赶紧回家。
3.4 可采纳性与一致性
上面的罗马尼亚都是引子,其主要目的,除了介绍算法,更重要的却是引入另外2个概念。
①可采纳性,admissable
②一致性 , consistent
对所有n,代价的估计值h(n) ≤ 实际代价,则称h(n)为admissable的启发函数。
对所有n,从n点到目标的代价的估计值h(n) ≤ 从n点走到n'点的实际代价c(n,n') + 从n'点到目标的代价的估计值h(n'),则称h(n)为consistent(或者monotone)。
可采纳性,在我理解里,意思是【总是保守地估计】。
非常像我们平时讨论问题,都有一些口癖,像“最起码”、“保守估算”、“哪怕”、“退一万步说”。
显然只有【保守地估计】才是【可采纳的】。
如果你不保守,而是非常大胆地估计,那么你说的话就会被质疑,你给的数字就没人信。
所以admissable这个单词,选的也是略微精妙。
一致性,又称单调性。
书上用三角形关系来比喻。
如果学过dijkstra的话,就会觉得这个不等式非常熟悉。
通俗地说就是【成本不递减】。
(否则就等于图算法里出现了负值圈,越走下去值还越小了,那我多走几圈好不好?)
而①和②的关系是,
若consistent,则必admissable。(习题3.29,递推法易证)
即便admissable,却也有可能unconsistent。
理论上可以证明,
若同时满足admissable和consistent,则A*类的算法全都是optimally efficient(最优效率的)。
若只满足admissable,不满足consistent,则一个节点可能被多次展开。最坏情况下被展开的次数是一个指数级的值,此时采用Dijkstra算法远胜A*算法。(引自wiki:https://en.wikipedia.org/wiki/A*_search_algorithm)
再考虑不同的任务场景。
若admissable,则A*的树搜索版本最优。
若consistent,则A*的图搜索版本最优。
无论哪个版本,A*算法的共同缺点都是,太耗内存了。
所以又引出了一些改进内存消耗的A*衍生物。
不细述。
3.5 启发函数的优势性 heuristic function advantage
同一个问题,例如8数码问题(8-puzzle problem),可以定义不同的启发函数。
同上,目前为止的所谓heuristic function,依然可以理解为 【到目标的代价的估计值】。
若2个启发函数,总有h2(x) ≥ h1(x),则称h2(x)比h1(x)占优势。
注意,这句话的前提是默认了h1(x)与h2(x)遵守admissable原则,即大家都对代价作保守估计。
在admissable限制下,h1(x) ≤ h2(x) ≤ RealCost(x)。
显然h2(x)更接近实际代价,显然h2(x)更精确,这样h2(x)扩展的结点数不会大于h1(x)。
显然采用h2(x)搜索效率更高。(如果计算h2(x)的开销不是特别特别大的话)
(你用一个更精确的估计值去跑搜索,结果还能干不过一个不精确的估计值?)
一切都符合直觉。
3.6 松弛问题 Relaxation Problem
松弛(relaxation)这个概念,跟启发(heuristic)一样,都是中文莫名其妙的东西。
但是要习惯它。
定义:
松弛问题 = 减少了行动限制的问题。
用大白话讲,松弛 = 约束条件更少的简化版问题。
书上的栗子倒是蛮好。

(图源:https://blog.csdn.net/weixin_39278265/article/details/80923249 )
因为松弛问题减少了行动约束,所以增大了状态空间。
原问题的最优解一定是松弛问题的解,但是松弛问题可能存在更好的解。
【注:中文版翻译成“原问题的最优解一定是松弛问题的最优解”,这句话显然是错的。】
书上原句【由于得出的启发式是松弛问题的确切代价,那么它一定遵守三角不等式,因而是一致的。】
这句话我觉得应该这样解读。
首先,松弛问题是很好提出的,我们可以任意减少行动限制得到一个松弛问题。
其次,任何一个问题都可以有多种启发函数,这是随我们高兴自己定义的。
第三,这句话的潜在意思是,我们可以对自己提出的松弛问题,设计一种【能够表达确切代价】的启发式(启发函数)。
第四,基于上述前提,我们为松弛问题设计的启发函数能够表达确切代价,即 h'(n) == RealCost'(n)。
因而在松弛问题内,h'(n)是一致的(consistent)。
从一致性可得,在对松弛问题而言,我们设计的h'(n)同时还是可采纳的(admissable)。
【特别需要注意的是,这个h'(n)一定要是能够确切表达代价的!!!实际操作中,如果你提出的松弛问题,找不到一个好的确切表达代价的计算方法,这个松弛问题就没有意义!】
还可以直观地这样理解。
原问题是限制A->B->C,则原来在A点的启发函数值 h(A) ≤ RealCost = distance(A,B)+distance(B,C)
松弛问题对行动的限制减少,导致A->C可能增加了一条更短的直连路径。
(就算没增加也没关系)
反正就算没增加,松弛问题对【代价的估计】,即新的启发函数h'(n),至少不会大于原来的实际代价。
(这句话成立的前提,如上文所言,是h'(n)能够表达确切代价,h'(n)==RealCost'(n))
(若增加了捷径,从A->C有更短路,那么h'(n)==RealCost'(n) < RealCost(n),就比原来的实际代价小)
(若没加捷径,从A->C还是得走B,那么h'(n)==RealCost'(n) == RealCost(n))
即,h'(n) ≤ RealCost(n),所以松弛问题的启发函数,对原问题而言(重点), is admissable。
从这段描述也可以看出,新构造的h'(n)比原来的启发式,很容易更有优势(精度更高)。
因为实践中,一个行动严格受限的问题的启发函数,h(n)会偏离实际代价很远。
例如罗马尼亚问题用直线距离作为h(n),8数码问题用错位棋子数作为h1(n)。
即h(n) << RealCost(n)。
而我们的 h'(n) == RealCost'(n) ≤ RealCost(n),直觉上h'(n)会更加精确一些。
上面2段话,就是为了直观地理解为什么需要提出一个松弛问题。
哦!!!
原来,可以通过在松弛问题里设计【精确表达代价】的启发式(启发函数)h'(n),
来获得在原问题里精度更高的启发式(启发函数)。
由上一小节的知识我们知道,精度更高(占优势)的启发函数总是更让人愉悦的!
这样我们用h'(n)求解原问题,就更加优雅而有效。
这就是松弛(relaxation)为什么在wiki被称为技巧(technique)的原因。
【wiki地址: https://en.wikipedia.org/wiki/Relaxation_(approximation) 】
它本质是帮我们获得更精确的启发函数的方法。
太神奇了!
这是有用性的证明。再来看一下必要性,为什么非得是松弛问题不可呢?
我不能直接在原问题里设计出一个“精确表达代价”的启发函数吗?
不,你不可以。
因为原问题往往有诸多限制,不直观,非线性,等等等等。
这导致你很难有一个“易于计算的”、“精确表达代价的”的启发函数。(有些式子根本写不出来,只能用符号+自然语言描述,为了计算又需要设计一套算法。)
精度和计算成本需要权衡。
sorry,松弛问题就是可以为所欲为。
不过北大OJ里,王文敏先生没有怎么讲松弛问题。
也没有讲【从子问题出发设计可采纳的启发式:模式数据库】这一节,有点遗憾。
Chapter 4 超越经典搜索 Beyond Classic Search
4.1 Overview
局部搜索 local search:
局部搜索算法是从单个当前结点(而不是多条路径)出发,通常只移动到它的邻近状态,通常不保留搜索路径。
局部搜索不是系统化的。
所以有2个优点,(1)很少内存,通常为常数 (2)通常能在系统化算法不适用的很大或无限的(连续的)状态空间中找到合理的解。
所谓局部呢,就是片面。
何谓片面呢?
就在于,局部搜索不关心路径,只关心最终状态是什么。
我只想知道8个皇后怎么摆,你不需要告诉我怎么移动。
也就是说,局部搜索是来搜索状态(state)的,而不是路径(path)。
很自然的,我们会想到把局部搜索放到优化问题里去。
对于纯粹的优化问题( pure optimical problem),可以给定一个目标函数,找到一个更优的状态。
定义一个状态空间图,state-space landscape
横轴为状态,纵轴为启发式代价函数或目标函数。
像不像神经网络里对loss function求最优参数?
4.2 基础局部搜索算法
本节4个基础局部搜索算法。
①爬山法 Hill-Climbing
我们假设目标函数是bigger-better的。
那么爬山法简单的说,就是每次向目标函数增大的方向移动。
爬山法有一个最陡版本(steepest -ascent version),每次都选取最佳邻接点。
因为这种短视的特性,又称贪婪局部搜索(greedy local search)。
从短视来看,其缺点是容易陷入局部极大值。
于是很自然的引申出一个随机重启爬山法(random restart hill climbing),类似给定初动量的优化函数SGD,帮忙跳出局部极值。
还有一种随机爬山法(random hill cimbing),以不同方向的斜率(梯度)为概率值,随机往某个方向前进。
很像deepwalk吧,随机游走一哈,没准就摆脱局部极值陷阱了。
②模拟退火搜索 Simulated Annealing Search
这个做过信息题的人应该不陌生。
此处我们假设目标函数是smaller-better的,即可以理解为loss function。
简单的说,每次随机移动到某点,若loss降低则接受该移动。
若loss增加,则以一个p概率接受该移动。
p的计算方式含2层。
1) △Loss,即损失的增加幅度,指数级增长,loss增加的越多,p概率越小,我们越不允许这次移动发生。
2) 当前loss。原句【开始温度T高的时候可能允许“坏的”移动,T越低则越不可能发生】。
③局部束搜索 Local Beam Search
我们假设目标函数是bigger-better的。
本算法的特性在于能存储K个状态,而不是一个。
你可以理解为,K个局部搜索任务并行,其中一个任务达到目标就停止。
但与完全并行不同的是,K个任务之间会互相传递信息,反而更像大家分散出去四面八方找水源,找到的人通知其他人也过来。
和爬山法相比,无非是一个人爬山,变成了K个人爬山。
最简单的局部束搜索,很容易K个人一起在局部极大值顶点被套牢罚站。
于是很自然的有人就提出了随机局部束搜索。
假设K个结点移动一次之后生成N个后继状态,那么不再从N个里面按目标函数最大的topK这么无脑取了。
而是随机地从N个后继状态中选择K个,概率值随N个后继状态的权值(目标函数值)的增大而增大(类似于softmax)。
④遗传算法 Genetica Algorithm GA
遗传算法是一类算法,而不是某个算法。
(deeplearning早期就有用遗传算法去搜参数的论文,但是模型一深参数一多就爆炸了,后来还是反向传播一统天下。)
本质是受达尔文进化论启发创造出来的。
无非是把目标函数的名字偷换成了“适应度函数”这种。
同样的,适应度函数是bigger-better的。
选择后代的过程,和随机局部束搜索类似,也是“适应度”权重作为概率值,然后随机选择。
本节概括一下就是......
没什么困难是一层随机不能解决的。
如果有就再套一层随机。(摊手)
4.3 连续空间中的局部搜索(待填)
这一节看着短,涉及到好多课外知识。
王文敏mooc没讲,需要自己补作业。
【注意北大mooc只讲了4种基础局部搜索算法,以及后面的集群智能算法。aima上第四章的其他内容都没介绍。
】
4.4 不确定情况下的搜索
如果环境是部分可观察或不确定的(也可能两者都有),就需要引入“感知信息”这一概念。
此处分两类。
1)环境确定,但是仅部分可观察。那么agent无法确定自己处在哪里,每一个感知信息会缩小Agent判定自身状态的可能范围。
2)环境不确定,但是部分可观察。Agent只能依赖当前感知信息,感知信息告知Agent某一行动的结果到底是什么。(我摔了杯子,感知信息告诉我杯子碎了这一结果。)
上面两种情况,对于Agent来说差不多,Agent都无法确定自己所在的确切状态,只能不断的行动,尝试,根据感知信息来反馈调节,产生应急规划(策略strategy)。
所谓的应急规划,本质上是一连串if else。
比如,在t-1时刻,根据感知信息得到一个stratefy,里面包含了内容{if 1 then do a , else if 2 then do b}。
到了B怎么办呢,又要算新的步骤。
显然,这是一个树结构,一路扩展下去。
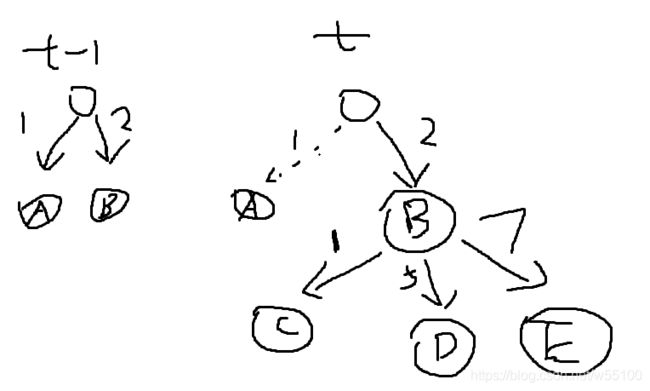
书上是引入了“不确定动作,不稳定的吸尘器世界”这一节来说明的。
non-deterministic actions : the erratic vacuum world
这样就引入了 (And/Or Tree)与或树 ,这一概念。
在该树中,
同一条路径上的所有结点,由于后者是前者行动的结果,这些结点被称为与结点(And Node)
同一个结点的所有孩子,由于彼此是同一个parent node的分支,互相之间被称为或结点(Or Node)
根结点root被视为initial problem。
每一个结点被视为一个subproblem。
当该subproblem被解决时,就terminate。
否则,在该结点处继续expand分支。
从定义来看,就是对搜索树换了层皮......
与或搜索问题的解是一颗子树。
我们可以继续扩展,得到AND-OR Graph 与或图。
与或图的搜索算法很多,偷一张slide。

(src:https://www.ics.uci.edu/~kkask/Fall-2016 CS271/slides/03-InformedHeuristicSearch.pdf)
4.5 完全不可观察情况下的搜索
Agent感知不到任何信息的问题,称为无传感问题(sensorless problems),或相容问题(conformant problem)。
相容问题这个翻译有很大的偏差,还是看英文体会吧。
完全不可观察情况下,可以产生一些特别的解。
原书举例吸尘器问题中使用{Right,Suck,Left,Suck}这一策略,总能迫使世界达到状态7(coerce the world into state 7)。
解决无观察问题,我们在信念空间(space of belief states)中搜索,而不是实际状态空间(rather than physical states)中搜索。
后面的东西玄乎其玄......
4.6 联机搜索Agent
脱机搜索:诸葛亮坐在大后方计算出完整的方案,然后交给其他人去执行。不涉及动作执行过程
联机搜索:计算和动作执行交替进行。 先采取某个行动,然后观察环境变化并且计算出下一行动。
联机搜索存在一个隐含条件,即状态之间的转移可逆。
毕竟联机搜索的本质是探索问题(这是个名词!!!exploration problem)
我从A来到B,这是一个action,然后发现B不好待,就要原路返回。不然我就算不出从A出发的其他路径的好坏。
如果某些活动是不可逆的(irreversable),就容易陷入死胡同(dead-end)。
再关注一下敌对论点(adversary argument)这个翻译。
4.7 群体智能Swarm Intelligence
北大mooc单独新增。
Altruism Algorithm 利他算法
Ant Colony Algorithm **蚁群算法**
Bee Colony Algorithm 蜂群算法
Artificial Immune System 人工免疫系统
Bat Algorithm 蝙蝠算法
Differential Evolution Algorithm 差分进化算法
Multi-swarm optimization **粒子群优化** https://en.wikipedia.org/wiki/Multi-swarm_optimization
Chapter 5 对抗搜索 Adversarial Search
整理中...
5.1 Overview

博弈论(Game Theory)是研究理性决策者之间的冲突与合作的数学模型。
一个可替换属于是交互式决策理论(interactive decision theory)。
零和博弈(Zero Sum Games),【为什么发音是灵狐博弈???文敏sensai???】
Two Players Game


博弈树 【为什么发音是波衣术???】
optimal decision in game
minmax value
使对手的最大收益最小。
使自己的最大损失最小。
pruning剪枝

Chapter 6 约束满足问题 Constraint Satisfaction Problem
6.1 Overview
一组变量,每个变量有自己的值。
当每个变量都有自己的赋值同时满足所有关于变量的约束时,问题就得到了解决。
这类问题就叫做约束满足问题 Constraint Satisfaction Problem,CSP。
CSP搜索算法利用了状态结构的优势,使用的是通用策略而不是问题专用启发式来求解复杂问题。
主要思想是通过识别违反约束的变量/值的组合迅速消除大规模的搜索空间。


形式化定义为三个成分X,D,C
X为变量。
D为值域。
C为约束集合。
一个不违反任何约束的赋值被称为相容的(conformant)或者合法的赋值。

