C++11新功能_plus
文章目录
- C++11
-
- 包装器
-
- 1. function包装器
-
-
- 如何让模板只实例化出一个类型?
- 包装器解决问题-只实例化出一份对象空间
- 逆波兰表达式求解
-
- 2. bind 包装器
- 线程库
-
-
- 简单使用:
- 线程安全
-
-
-
- 实验一:两个线程同时对同一个变量x实现加加
-
- 一. 加锁操作
-
- 锁加在循环的里面还是外面呢?
-
- 实验二: N个进程对他进行M次加加
- 实验三:传参案例
- lock_guard vs unique_lock
-
- lock_guard守卫
- unique_lock
- 二. 条件变量
-
-
- 实验:两个线程交替打印,一个打印奇数一个打印偶数
- 如何避免先打印的那个连续打印呢?
- 实验现象0-100奇数偶数交替的打印:
-
-
-
C++11
包装器
1. function包装器
function 包装器也叫作适配器.本质是一个类模板,也是一个包装器.
我们知道对于lambda表达式,函数指针,仿函数的调用形式是一样的,而在模板进行实例化的时候就会出现三份
- 如图所示:count作为static变量,有三份地址,说明实例化出了三个对象.
template
T useF(F f, T x)
{
static int count = 0;
cout << " count:" << ++count << endl;
cout << " count:" << &count << endl;
return f(x);
}
double f(double i,double j)
{
return i / 2;
}
struct Functor
{
double operator()(double d,double f)
{
return d / 3;
}
};
int main()
{
函数名
cout << useF(f,11.11) << endl;
//函数对象,仿函数
cout << useF(Functor(), 11.11) << endl;
//lambda表达式
cout << useF([](double d)->double {return d / 4; }, 11.11);
}

如何让模板只实例化出一个类型?
funtion 包装器,将三份包装成同一个格式,成一份只不过实例化三次,所以即便是三种,但是地址都是一样的。
三种形式的实现忽略.
- 包装器使用

#include
double f(double i,double j)
{
return i / 2;
}
struct Functor
{
double operator()(double d,double f)
{
return d / 3;
}
};
class Plus
{
public:
static int plusi(int a, int b)
{
return a + b;
}
double plusd(double a, double b)
{
return a + b;
}
};
int main()
{
functionfunc = f;
cout << func(1.0,2.0)< func2 = Functor();
cout << func2(1.0, 2.0) << endl;
//成员函数最好都加上&,静态的可以不用加
functionfunc3 = &Plus::plusi;//包装静态成员函数
cout << func3(1.0, 2.0) << endl;
functionfunc4 = &Plus::plusd;//包装非静态成员函数
cout << func4(Plus(),1.0, 2.0) << endl;
return 0;
}
包装器解决问题-只实例化出一份对象空间

逆波兰表达式求解
题目:已经得到的是后续表达式
这种写法,只需要修改map中的映射关系,就可以避免写死操作字符串和大量的字符串插入时的时间浪费(来一个修改一次Switchcase)函数初始化可以用内三种,下面是lambda表达式。用包装器val的值可以给内三种任何一个,弥补他们不能作为参数的缺点。
int evalRPN(vector& tokens)
{
map> opFuncMap;//命令opt和对应函数之间的关系
opFuncMap["+"]=[](int a,int b)->int{return a+b;};
opFuncMap["-"]=[](int a,int b)->int{return a-b;};
opFuncMap["*"]=[](int a,int b)->int{return a*b;};
opFuncMap["/"]=[](int a,int b)->int{return a/b;};
stack s;
for(int i=0;i 2. bind 包装器
std::bind函数是一个函数模板,就像一个函数包装器(适配器),接收一个可调用对象,生成一个新的可调用对象来适应原对象的参数列表.可以将bind函数看做是一个通用的函数适配器.
int Sub1(int a, int b)
{
return a - b;
}
class Sub
{
public:
int sub(int a, int b)
{
return a - b;
}
};
int main()
{
functionf1 = Sub1;
cout << f1(10, 3) << endl;
//1. 交换两个参数位置(绑定参数顺序交换)
functionf2 = bind(Sub1,placeholders::_2,placeholders::_1);
cout << f2(10, 3) << endl;
//2. 通过绑定调整参数的个数
//例子:正常调用类中的成员函数, 两个参数int
function f4 = &Sub::sub;
cout << f4(Sub(), 10, 10) << endl;
//bind绑定第一个参数,f4()调用就可以不用传Sub这个类了,剩下两个依次走就行
function f5 = bind(&Sub::sub, Sub(), placeholders::_1, placeholders::_2);
cout << f5(10, 10) << endl;
//固定100减的话(又减少了一个传的参数):
function f6 = bind(&Sub::sub, Sub(), 100, placeholders::_1);
cout << f6(10) << endl;
//auto 也可以代替function<>,就是参数和返回值交代的不清楚
auto f7 = bind(&Sub::sub, Sub(), 100, placeholders::_1);
cout << f7(10) << endl;
return 0;
}
线程库
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得
代码的可移植性比较差**。**C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖
第三方库,而且在原子操作中还引入了原子类的概念。要使用标准库中的线程,必须包含< thread >头文
件.

| 函数名 | 功能 |
|---|---|
| thread() | 构造一个线程对象,没有关联任何线程函数,即没有启动任何线程 |
| thread(fn, args1, args2, …) | 构造一个线程对象,并关联线程函数fn,args1,args2,…为线程函数的参数 |
| get_id() | 获取线程id |
| jionable() | 线程是否还在执行,joinable代表的是一个正在执行中的线程。 |
| jion() | 该函数调用后会阻塞住线程,当该线程结束后,主线程继续执行 |
| detach() | 在创建线程对象后马上调用,用于把被创建线程与线程对象分离开,分离的线程 变为后台线程,创建的线程的"死活"就与主线程无关 |
线程是操作系统中的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态。当创建一个线程对象后,没有提供线程函数,该对象实际没有对应任何线程 .
简单使用:
- std::thread::thread Fn可以是任何可调用对象

#include
using namespace std;
void Print(int n)
{
for (int i = 0; i < n; i++)
{
cout << i< 
线程的拷贝构造和赋值是不允许的,但是如果是右值是可以移动给别人,允许资源转移.
void Print(int n)
{
for (int i = 0; i < n; i++)
{
cout << i< vfths;
int n;
cin >> n;
vfths.resize(n);//自动调用thread的构造函数
for (auto& e : vfths)
{
e=thread(Print,10);//匿名对象(右值),这行结束就被销毁,然后移动赋值操作
}
for (auto& e : vfths)
{
e.join();
}
return 0;
}
首先:Windows和Linux的线程库都是不一样的库.
C++11thread库可以跨平台进行兼容,条件编译实现的.面向对象实现的.
线程安全
实验一:两个线程同时对同一个变量x实现加加
多线程安全问题是一个偶发事件,造成每次的结果可能都不一样,所以得加锁.有的时候也可以正确,所以不加锁也可能得到正确答案。
- 设置成全局变量.没加锁,可能存在线程安全。
//设置为全局变量进行++
int x = 0;
void Func(int n)`
{
for (int i = 0; i < n; i++)
{
cout << std::this_thread::get_id() << "->"<
一. 加锁操作
x是全局变量,保存在数据段,需要进行加锁保护.互斥锁
锁加在循环的里面还是外面呢?
加锁加到循环的里面,两个线程一人加一次,是交替并行++。
加在外面,造成两个进程依次进行++完自己的次数,是串行的,失去了多线程的意义,但是比较安全。
-
如果放在循环里面(并行),效率会比放在外面(串行)低,什么原因?
主要是++x太快了,会导致两个线程频繁的获取锁和释放锁(相比于++ 这一很快的操作消耗时间太多),频繁的切换**上下文(记录起始数据)**频繁的申请次数,还可能,还没保存呢,就又切走了。
-
如果既想效率高,又不想整串行,怎么搞?
- 选择自旋锁,频繁的询问其中一个线程是否执行完,等待的人一直在空旋,一直在访问(不像互斥锁竞争失败之后就休息一会)。
- 对++x进行原子操作(操作系统级别提供的),不加锁也可以。但是还是会存在消耗使得时间变长。项目中原子的更适合。下图是原子设置的一种做法,将锁去掉
atomicx = 0; void Func(int n) { for (int i = 0; i < n; i++) { ++x; } } int main() { thread t1(Func,10000); thread t2(Func,30000); t1.join(); t2.join(); cout << x << endl; return 0; } -
所以,综合加锁在循环外串行的形式效率最佳,如下所示是用lambda 表达式实现的一种:
//代码如下: int main() { int x = 0; mutex mtx; int N = 10000000; atomiccostTime = 0; //采用lambda表达式的形式代替上面的调用函数 thread t1([&] { int begin1 = clock(); mtx.lock(); for (int i = 0; i < N; i++) { ++x; } mtx.unlock(); int end1 = clock(); costTime += (end1-begin1); }); thread t2([&] { int begin2 = clock(); mtx.lock(); for (int i = 0; i < N; i++) { ++x; } mtx.unlock(); int end2 = clock(); costTime += (end2 - begin2); }); t1.join(); t2.join(); cout << costTime << endl; return 0; }
实验二: N个进程对他进行M次加加
//原子操作保证线程安全
int main()
{
atomicx = 0;
int n, m;//n个进程执行M次
cin >> n >> m;
vectorvthds;
vthds.resize(n);
for (int i = 0; i < n; i++)
{
vthds[i] = thread([m, &x] {
for (int j = 0; j < m; j++)
{
cout << std::this_thread::get_id() << "-" << x << endl;
++x;
}
});
}
for (auto& e : vthds)
{
e.join();
}
cout << "the last val of x is->" << x << endl;
}
//加锁保证线程安全
int main()
{
int x = 0;
mutex mtx;
int n, m;//n个进程执行M次
cin >> n >> m;
vectorvthds;
vthds.resize(n);
for (int i = 0; i < n; i++)
{
vthds[i] = thread([m, &x,&mtx] {
for (int j = 0; j < m; j++)
{
mtx.lock();
cout << std::this_thread::get_id() << "-" << x << endl;
++x;
mtx.unlock();
}
});
}
for (auto& e : vthds)
{
e.join();
}
cout << "the last val of x is->" << x << endl;
}
实验三:传参案例
//void Func(int& x)//thread可执行函数对象参数不能是左值引用
//{
// cout << "x:" << &x << endl;
//}
//方法一:传指针
void Func(int* x)
{
cout << "x: " << x << endl;
*x += 10;
}
void Func2(int& x)
{
cout << "x: " << &x << endl;
++x;
}
int main()
{
int n = 0;
cout << "n: " << &n << endl;
thread t1(Func,&n);
thread t2(Func2,std::ref(n));//方法二,使用ref(https://blog.csdn.net/qq_33726635/article/details/124086352)
t1.join();
t2.join();
cout << n << endl;
}
lock_guard vs unique_lock
在多线程环境下,如果想要保证某个变量的安全性,只要将其设置成对应的原子类型即可,即高效又不容易出现死锁问题。但是有些情况下,我们可能需要保证一段代码的安全性,那么就只能通过锁的方式来进行控制。
C++的容器并不是线程安全的,也需要加锁。向vector中添加数据的时候,出现内存问题,new失败了就会抛异常,他就去走catch了,在加锁的情况无法释放锁,就会出现死锁的情况,然后卡死,如图所示:

void Func(vector& vec, int n, int base,mutex& mtx)
{
try
{
for (int i = 0; i < n; i++)
{
//cout << this_thread::get_id() << ":" << base + i << endl;
mtx.lock();
//中间代码失败,抛异常(扩容申请空间失败,就是抛异常)
//需要try-catch处理
vec.push_back(base + i);
//模拟失败
if (base == 1000 && i == 88)
{
throw bad_alloc();
}
mtx.unlock();
}
}
catch (const exception& e)
{
cout << e.what() << endl;
mtx.unlock();
}
}
int main()
{
vectorvec;
mutex mtx;
thread t1(Func,std::ref(vec),1000,100,std::ref(mtx));
thread t2(Func,std::ref(vec),1000,1000,std::ref(mtx));
t1.join();
t2.join();
for (auto& e : vec)
{
cout << e << endl;
}
cout < 我们只需要在catch里面把锁给释放了就行了,但是这只是一个简单的代码就需要对这一处特判,如果代码很多,就很费事.一种方法是使用智能指针,另一种方式就是封装的LockGuard类.
lock_guard守卫
将抛异常处理代码块中的锁啊,申请的内存需要释放啊,都转移到锁的析构函数中,出了代码块生命周期就自动释放.
class LockGuard
//当抛异常或者出作用域之后,就会自动调用析构函数然后顺带着把锁也释放了
{
public:
LockGuard(Lock& lock)
:_lock(lock)
{
_lock.lock();
}
~LockGuard()
{
_lock.unlock();
}
private:
Lock& _lock;//锁的引用,因为锁不支持拷贝
};
void Func(vector& vec, int n, int base,mutex& mtx)
{
try
{
for (int i = 0; i < n; i++)
{
LockGuard lock(mtx);//出了这个代码块的声明周期就自动释放了
vec.push_back(base + i);
//模拟失败
if (base == 1000 && i == 88)
{
throw bad_alloc();
}
}
}
catch (const exception& e)
{
cout << e.what() << endl;
}
}
int main()
{
vectorvec;
mutex mtx;
thread t1(Func,std::ref(vec),1000,100,std::ref(mtx));
thread t2(Func,std::ref(vec),1000,1000,std::ref(mtx));
t1.join();
t2.join();
for (auto& e : vec)
{
cout << e << endl;
}
cout < 通过上述代码可以看到,lock_guard类模板主要是通过RAII的方式,对其管理的互斥量进行了封装,在需要加锁的地方,只需要用上述介绍的任意互斥体实例化一个lock_guard**,调用构造函数成功上锁,出作用域前,lock_guard对象要被销毁,调用析构函数自动解锁,可以有效避免死锁问题**。
lock_guard的缺陷:太单一,用户没有办法对该锁进行控制,因此C++11又提供了unique_lock
unique_lock
与lock_gard类似,unique_lock类模板也是采用RAII的方式对锁进行了封装,并且也是以独占所有权的方式管理mutex对象的上锁和解锁操作,即其对象之间不能发生拷贝**。**
在构造(或移动(move)赋值)时,unique_lock 对象需要传递一个 Mutex 对象作为它的参数,新创建的 unique_lock 对象负责传入的 Mutex对象的上锁和解锁操作。使用以上类型互斥量实例化unique_lock的对象时,自动调用构造函数上锁unique_lock对象销毁时自动调用析构函数解锁,可以很方便的防止死锁问题。与lock_guard不同的是,unique_lock更加的灵活,提供了更多的成员函数:
上锁解锁操作:lock、try_lock、try_lock_for、try_lock_until和unlock修改操作:移动赋值、交换(swap:与另一个unique_lock对象互换所管理的互斥量所有权)、释放(release:返回它所管理的互斥量对象的指针,并释放所有权)
获取属性:owns_lock(返回当前对象是否上了锁)、operator bool()(与owns_lock()的功能相同)、mutex(返回当前unique_lock所管理的互斥量的指针)
二. 条件变量
实验:两个线程交替打印,一个打印奇数一个打印偶数
- 单纯加锁守卫,可以解决问题,会存在什么问题呢?
如果一个线程连续拿到锁,一个释放锁另一个可能不在等待锁的状态,同时竞争就可能连续拿到锁,一个线程连续打印多次,就不是交替打印了.
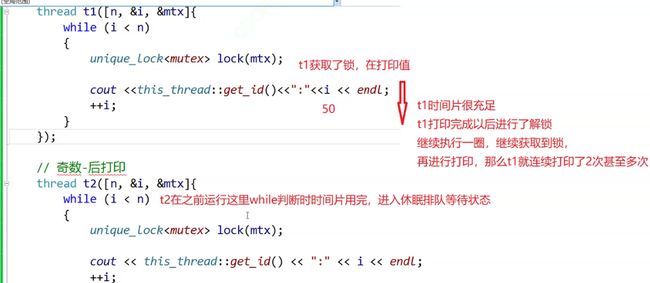
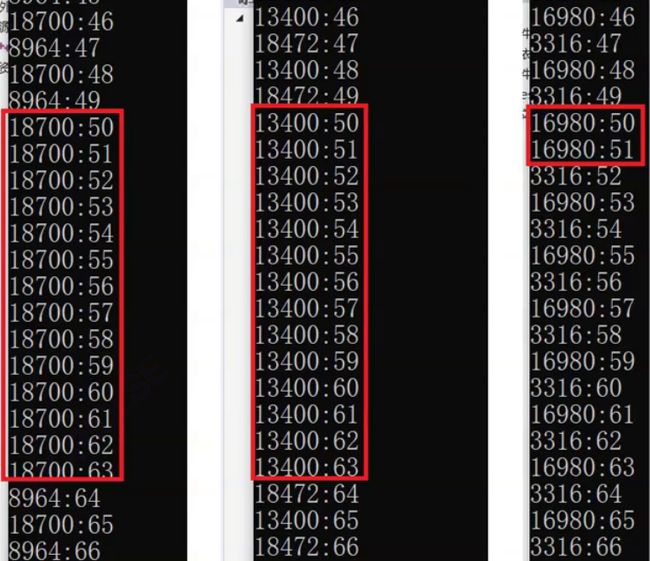
根据优先级进行设计时间片轮转,保证不饿死。同时创建无法保证奇偶数的优先打印,谁放在前面来保证是非常不靠谱的。
- 使用条件变量-面向对象的方式 wait (因为锁阻塞,还是因为wait中的flag阻塞)

while (!pred()) wait(lck);
-
condition_variable ,条件变量也不是线程安全的,不能拷贝,和互斥锁互相配合使用。
-
进入阻塞的瞬间,将自己的锁释放,被唤醒之后,可调用对象的返回值是TRUE,先得到锁然后走出阻塞的状态。可调用对象的返回值是假,就一直进入阻塞。
-
实现优先级。即使不应该先打印的先竞争到锁,wait的时候阻塞然后把锁释放给优先打印的,然后他也不用wait,就完成了。
-
flag是false会一直阻塞,直到flag为TRUE,终极保证。也就是说哪怕后打印的先获取到锁也会阻塞,因为flag是False.先打印的先获取到锁,取!,false->true,刚才阻塞的那个就可以进行了.
如何避免先打印的那个连续打印呢?
- 如果后打印的是因为锁等待阻塞时,使用notify_one去唤醒一下.
- 并且把flag改为TRUE.保证我能把你唤醒,也可以阻止先打印的连续打印运行.即使极端情况下,后打印的t2因为其他原因转走了,t1还是获取到锁,但是由于此时flag=TRUE,在wiat()函数体中,!flag的原因,也会让t1卡主.
- 同理t2完成一次之后,避免连续打印,把flag再改为false,notify_one让t1去打印了.此时flag是False,t2仍被卡主避免连续打印.
实验现象0-100奇数偶数交替的打印:

int main()
{
int n = 100;
int i = 0;
mutex mtx;
condition_variable cv;
bool flag = false;
// 奇数-后打印
thread t2([n, &i, &mtx, &cv, &flag] {
while (i < n)
{
unique_lock lock(mtx);
// flag是false的时候,这里会一直阻塞,知道flag变成true
cv.wait(lock, [&flag]() {return flag; });
cout << this_thread::get_id() << ":->" << i << endl;
++i;
flag = false;
cv.notify_one();
}
});
// 偶数-先打印
thread t1([n, &i, &mtx, &cv, &flag] {
while (i < n)
{
unique_lock lock(mtx);
// !flag是true,那么这里获取侯不会阻塞,优先运行了
cv.wait(lock, [&flag]() {return !flag; });
cout << this_thread::get_id() << "->:" << i << endl;
++i;
// 保证下一个打印运行一定是t1,也可以防止t1连续打印运行
flag = true;
cv.notify_one();
}
});
// 交替走
t1.join();
t2.join();
return 0;
}