【音视频第4天】视频音频编码的基础知识概述
http://www.52im.net/thread-1620-1-1.html
里面的链接
《即时通讯音视频开发(一):视频编解码之理论概述》
《即时通讯音视频开发(二):视频编解码之数字视频介绍》
《即时通讯音视频开发(三):视频编解码之编码基础》
《即时通讯音视频开发(四):视频编解码之预测技术介绍》【没看】
《即时通讯音视频开发(五):认识主流视频编码技术H.264》【没看】
《即时通讯音视频开发(六):如何开始音频编解码技术的学习》【没看】
《即时通讯音视频开发(七):音频基础及编码原理入门》
《即时通讯音视频开发(八):常见的实时语音通讯编码标准》
《即时通讯音视频开发(九):实时语音通讯的回音及回音消除概述》
《即时通讯音视频开发(十):实时语音通讯的回音消除技术详解》
《即时通讯音视频开发(十一):实时语音通讯丢包补偿技术详解》
《即时通讯音视频开发(十二):多人实时音视频聊天架构探讨》
《即时通讯音视频开发(十三):实时视频编码H.264的特点与优势》
《即时通讯音视频开发(十四):实时音视频数据传输协议介绍》
《即时通讯音视频开发(十五):聊聊P2P与实时音视频的应用情况》
《即时通讯音视频开发(十六):移动端实时音视频开发的几个建议》
《即时通讯音视频开发(十七):视频编码H.264、VP8的前世今生》
另外,《移动端实时音视频直播技术详解》这个系列文章能很好地对应上我刚说的这些技术点,建议读一读:
《移动端实时音视频直播技术详解(一):开篇》
《移动端实时音视频直播技术详解(二):采集》
《移动端实时音视频直播技术详解(三):处理》
《移动端实时音视频直播技术详解(四):编码和封装》
《移动端实时音视频直播技术详解(五):推流和传输》
《移动端实时音视频直播技术详解(六):延迟优化》
实时音视频通信
http://www.52im.net/article-119-1.html
遇到的问题
实时音视频技术 = 音视频处理技术 + 网络传输技术
协议方面:tcp有无法忍受的延时,udp有丢包延时抖动乱序。
架构方面:公共网络每个节点都不可靠,后台工程师熟悉的mtr命令可以分析哪个路由节点丢包高,如果此时正在传输音视频,质量必然受到影响。
(mtr命令可以分析哪个路由节点丢包高?)
解决方法
质量评估:声音卡成翔,首先需要通过网络参数来评估语音质量。
数据统计:用户的使用情况到底怎么样,需要完善的数据统计模型和支撑系统,不然开发者就是睁眼瞎。
智能接入:影响质量的原因——不同的ISP会有不同的丢包水平,需要多线服务器。
智能路由:随着用户扩张到海外,比如电信用户和美国用户通话时丢包大,没有一边电信一边美国这种多线服务器,可能通过日本转发过去就不丢包了,这就是智能路由。
虚拟专线:智能接入加上智能路由,可以媲美网络专线的质量了,这就是所谓的虚拟专线。
丢包对抗:用户抱怨明显少了很多,还剩下一些自己网络不给力的用户。用户x一直用2G,用户y在公司里很多WIFI有信号污染,那么就需要丢包对抗机制。
网络可用性:用户报虹桥机场打不通,小发现公共场所WIFI有很多限制,所以需要考虑网络可用性。
后台高可用:用户没问题了,但各种互联网公司事件让运营者担心自己服务器电源也被挖掘机铲断,所以需要后台高可用。
编解码基础理论
1. 为什么要压缩
未经压缩的数字视频的数据量巨大,存储困难,传输困难
2. 冗余
原始视频压缩的目的是去除冗余信息,可以去除的冗余包括:
空间冗余:图像相邻像素之间有较强的相关性
时间冗余:视频序列的相邻图像之间内容相似
编码冗余:不同像素值出现的概率不同
视觉冗余:人的视觉系统对某些细节不敏感
知识冗余:规律性的结构可由先验知识和背景知识得到
(啥是编码冗余?)
3. 压缩类型
无损压缩(Lossless):压缩前、解压缩后图像完全一致X=X’,压缩比低(2:1~3:1)。典型格式例如:Winzip,JPEG-LS。
有损压缩(Lossy):压缩前解压缩后图像不一致X≠X’,压缩比高(10:1~20:1),利用人的视觉系统的特性。典型格式例如:MPEG-2,H.264/AVC,AVS。
4. 编解码器的关键技术

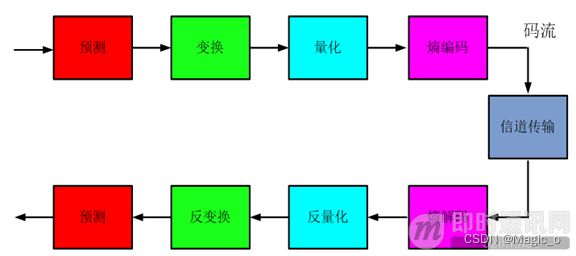
5. 编解码器的实现平台:
超大规模集成电路VLSI、ASIC, FPGA、数字信号处理器DSP、软件
编解码器产品:机顶盒、数字电视、摄像机、监控器
6. 传输差错控制:
差错控制(Error Control)解决视频传输过程中由于数据丢失或延迟导致的问题。
差错控制技术有:信道编码差错控制技术、编码器差错恢复、解码器差错隐藏
7. 视频传输中QoS质量保证参数
数据包的端到端的延迟、带宽:比特/秒、数据包的流失率、数据包的延迟时间的波动
8. 如何理解帧和场图像?
一帧图像包括两场——顶场,底场:


9. 逐行与隔行图像
逐行图像是指:一帧图像的两场在同一时间得到,ttop=tbot。
隔行图像是指:一帧图像的两场在不同时间得到, ttop≠tbot。
【有啥区别】
10. 编码层次组成

11. B帧P帧
. 
12. 关键技术
预测:通过帧内预测和帧间预测降低视频图像的空间冗余和时间冗余。
变换:通过从时域到频域的变换,去除相邻数据之间的相关性,即去除空间冗余。
量化:通过用更粗糙的数据表示精细的数据来降低编码的数据量,或者通过去除人眼不敏感的信息来降低编码数据量。
扫描:将二维变换量化数据重新组织成一维的数据序列。
熵编码:根据待编码数据的概率特性减少编码冗余。

13.码率控制
码率控制考虑的问题:
防止码流有较大的波动,导致缓冲区发生溢出,
同时保持缓冲区尽可能的充满,让图像质量尽可能的好而且稳定
音频基础及编码原理入门【好难以后用到了再看吧】
http://www.52im.net/thread-242-1-1.html
1. 基本概念
比特率:
表示经过编码(压缩)后的音频数据每秒钟需要用多少个比特来表示,单位常为kbps。
响度和强度:
声音的主观属性响度表示的是一个声音听来有多响的程度。响度主要随声音的强度而变化,但也受频率的影响。总的说,中频纯音听来比低频和高频纯音响一些。
采样和采样率:
采样是把连续的时间信号,变成离散的数字信号。采样率是指每秒钟采集多少个样本。

Nyquist采样定律:采样率大于或等于连续信号最高频率分量的2倍时,采样信号可以用来完美重构原始连续信号【什么意思】
2. 音频编码的基本原理
语音编码致力于:降低传输所需要的信道**带宽**,同时保持输入语音的**高质量**。
语音编码的目标在于:设计**低复杂度**的编码器以尽**可能低的比特率**实现**高品质数据**传输。
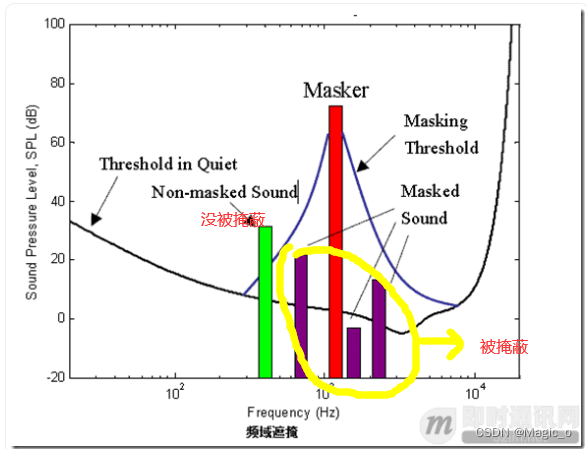
频域上的掩蔽效应:幅值较大的信号会掩蔽频率相近的幅值较小的信号
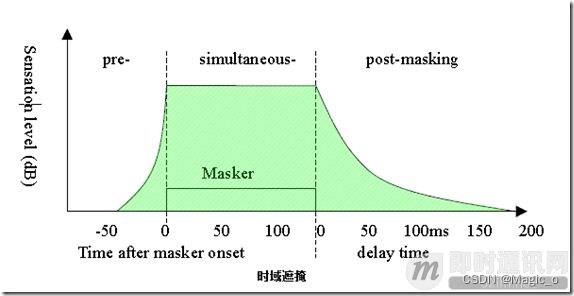
时域上的遮蔽效应:在一个很短的时间内,若出现了2个声音,SPL(sound pressure level)较大的声音会掩蔽SPL较小的声音。时域掩蔽效应分前向掩蔽(pre-masking)和后向掩蔽(post-masking),其中post-masking的时间会比较长,约是pre-masking的10倍。
3. 编码的基本手段
量化和量化器
基本概念:
1)量化和量化器:量化是把离散时间上的连续信号,转化成离散时间上的离散信号。
2)常见的量化器有:均匀量化器,对数量化器,非均匀量化器。
3)量化过程追求的目标是:最小化量化误差,并尽量减低量化器的复杂度(这2者本身就是一个矛盾)。
常见的量化器的优缺点:
(a)均匀量化器:最简单,性能最差,仅适应于电话语音。
(b)对数量化器:比均匀量化器复杂,也容易实现,性能比均匀量化器好。
(c)非均匀(Non-uniform)量化器:根据信号的分布情况,来设计量化器。信号密集的地方进行细致的量化,稀疏的地方进行粗略量化。
语音编码器
基本概念
语音编码器分为三种类形:(a)波形编器 、(b)声码器 、(c)混合编码器 。
波形编码器以构造出背景噪单在内的模拟波形为目标。作用于所有输入信号,因此会产生高质量的样值并且耗费较高的比特率。 而声码器 (vocoder)不会再生原始波形。这组编码器 会提取一组参数 ,这组参数被送到接收端,用来导出语音产生模形。声码器语音质量不够好。混合编码器,它融入了波形编码器和声器的长处。
波形编码器
波形编码器的设计常独立于信号。所以适应于各种信号的编码而不限于语音。
时域编码:
a)PCM:pulse code modulation,是最简单的编码方式。仅仅是对信号的离散和量化,常采用对数量化。
b)DPCM:differential pulse code modulation,差分脉冲编码,只对样本之间的差异进行编码。前一个或多个样本用来预测当前样本值。用来做预测的样本越多,预测值越精确。真实值和预测值之间的差值叫残差,是编码的对象。
即时通讯音视频开发(七):音频基础及编码原理入门_5.gif
c)ADPCM:adaptive differential pulse code modulation,自适应差分脉冲编码。即在DPCM的基础上,根据信号的变化,适当调整量化器和预测器,使预测值更接近真实信号,残差更小,压缩效率更高。
频域编码: 频域编码是把信号分解成一系列不同频率的元素,并进行独立编码。
a)sub-band coding:子带编码是最简单的频域编码技术。是将原始信号由时间域转变为频率域,然后将其分割为若干个子频带,并对其分别进行数字编码的技术。它是利用带通滤波器(BPF)组把原始信号分割为若干(例如m个)子频带(简称子带)。将各子带通过等效于单边带调幅的调制特性,将各子带搬移到零频率附近,分别经过BPF(共m个)之后,再以规定的速率(奈奎斯特速率)对各子带输出信号进行取样,并对取样数值进行通常的数字编码,其设置m路数字编码器。将各路数字编码信号送到多路复用器,最后输出子带编码数据流。对不同的子带可以根据人耳感知模型,采用不同量化方式以及对子带分配不同的比特数。
b)transform coding:DCT编码。
声码器
channel vocoder: 利用人耳对相位的不敏感。
homomorphic vocoder:能有效地处理合成信号。
formant vocoder: 以用语音信号的绝大部分信息都位于共振峰的位置与带宽上。
linear predictive vocoder:最常用的声码器。
混合编码器
波形编码器试图保留被编码信号的波形,能以中等比特率(32kbps)提供高品质语音,但无法应用在低比特率场合。声码器试图产生在听觉上与被编码信号相似的信号,能以低比特率提供可以理解的语音,但是所形成的语音听起来不自然。
混合编码器结合了2者的优点:
RELP: 在线性预测的基础上,对残差进行编码。机制为:只传输小部分残差,在接受端重构全部残差(把基带的残差进行拷贝)。
MPC: multi-pulse coding,对残差去除相关性,用于弥补声码器将声音简单分为voiced和unvoiced,而没有中间状态的缺陷。
CELP: codebook excited linear prediction,用声道预测其和基音预测器的级联,更好逼近原始信号。
MBE: multiband excitation,多带激励,目的是避免CELP的大量运算,获得比声码器更高的质量。
4.常见的实时语音通讯编码标准
实时音频通讯编码标准:G.711
实时音频通讯编码标准:G.721
实时音频通讯编码标准:G.722
实时音频通讯编码标准:G.722.1
实时音频通讯编码标准:G.721附录C
实时音频通讯编码标准:G.723(低码率语音编码算法)
实时音频通讯编码标准:G.723.1(双速率语音编码算法)
实时音频通讯编码标准:G.728
实时音频通讯编码标准:G.729
实时音频通讯编码标准:G.729A
实时音频通讯编码标准:MPEG-1 audio layer 1
实时音频通讯编码标准:MPEG-1 audio layer 2,即MP2
实时音频通讯编码标准:MPEG-1 audio layer 3(MP3)
实时音频通讯编码标准:MPEG-2 audio layer
实时音频通讯编码标准:AAC-LD (Advanced Audio Coding,先进音频编码)
回音
1.什么是回音?
在一般的VOIP软件或视频会议系统中,假设我们只有A和B两个人在通话,首先,A的声音传给B,B然后用喇叭放出来,而这时B的MIC则会采集到喇叭放出来的声音,然后传回给A,如果这个传输的过程中时延足够大,A就会听到自己刚才说的话,这就是回音。
2.什么是回音消除?
回音消除的作用就是在B端对B采集到的声音进行处理,把采集到的声音中包含的A的声音去掉之后在传给A,这样A就不会听到自己说过的话了。
3.回音消除的思路
在语音通话中,如果使用扬声器,会使扬声器发出的声音再次传回麦克风,形成回声,影响听取对方的声音。为了消除这种回声,需要使用回声消除器对采集到的声音进行处理。
回声消除器需要接收两个声音信号:一个是从麦克风采集到的声音,另一个是从扬声器播放出来的声音。这两个声音信号之间的延时是非常重要的,因为如果两个信号的延时不同,就很难找到频率相同的部分进行消除。
具体来说,当A端说话时,A端采集的声音经过网络传输到B端,B端的扬声器会播放出A端说的话。这时,B端在接收到A端的声音后,会将这些声音数据传给回声消除器做参考,然后再传给声卡播放出来。但这里声音的传输和处理都需要一定的时间,就会在B端的麦克风再次采集到声音时,产生一定的延时。如果传给回声消除器的两个信号同步得不好,就会出现扬声器发出的声音和麦克风采集到的声音之间的延时不同,导致回声消除器无法找到频率相同的部分进行消除。
因此,在语音通话中,为了消除回声,需要保证传给回声消除器的两个声音信号同步得非常好,也就是说需要控制好延时。这通常通过调节回声消除器的参数来实现,以保证回声消除器可以准确地找到频率相同的部分进行消除。
在一般的VOIP软件中,接收对方的声音并传到声卡中播放是在一个线程中进行的,而采集本地的声音并传送到对方又是在另一个线程中进行的,而声学回声消除器在对采集到的声音进行回声消除的同时,还需要播放线程中的数据作为参考,而要同步这两个线程中的数据是非常困难的,因为稍稍有些不同步,声学回声消除器中的自适应滤波器就会发散,不但消除不了回声,还会破坏采集到的原始声音,使被破坏的声音难以分辨。
采集声音:使用麦克风采集声音信号。
播放声音:使用扬声器播放声音信号。
传输声音:将采集到的声音信号和扬声器播放出的声音信号传输到对方的设备上。
接收声音:接收对方传输过来的声音信号。
消除回声:将采集到的声音信号和扬声器播放出的声音信号传给回音消除器进行处理,消除回声。
输出声音:将消除回声后的声音信号输出到扬声器上。
需要注意的是,在进行回声消除时,需要控制好采集到的声音和扬声器播放的声音之间的延时,以确保回音消除器能够准确地找到频率相同的部分进行消除。同时,回声消除器的效果也会受到环境、噪声等因素的影响,因此需要对算法进行动态调整,以适应不同的环境和场景。
声学回音主要又分成以下两种:
直接回音:由扬声器产生的声音未经任何反射直接进入麦克风
间接回音:由扬声器发出的声音经过多次反射后,再进入Mic
对于第二种回声,拥有多路径、时变性的特点,是比较难处理的。
4.回音消除的方法
第一种:通过硬件实现,有很多手机就是这么做的,也有专业的芯片,但是只支持8khz的,如果要求高质量的音质的话,基本实现不了。
第二种:通过软件实现,qq,msn,skype很多具有通话功能的软件,现在都具有回声消除的功能(需是比较高版本的,低版本的可能没有),但是实现代码是不对外的,开源的回声消除代码只有speex和webrtc。
一般常用的开源的AEC有两个:Speex 和 webrtc。AEC是回声消除(Acoustic Echo Cancellation)的缩写,webrtc相对比Speex强的多,原因如下:
1、webrtc有回声时延估计算法模块
2、webrtc有neteq模块
3、webrtc核心就是gips,原因你懂的。
GIPS是Global IP Solutions的缩写,是一家专门从事语音和视频通信技术的公司。GIPS曾经开发了一套音视频引擎,被Google收购后被用于WebRTC中,并且成为了WebRTC的核心。
GIPS在音视频通信领域有着丰富的经验和技术积累,他们的音视频引擎包含了很多优秀的技术,比如:
AEC(Acoustic Echo Cancellation):回声消除技术,可以消除语音通话中的回声。
NS(Noise Suppression):噪声抑制技术,可以消除语音通话中的噪声。
AGC(Automatic Gain Control):自动增益控制技术,可以自动调节音频输入的音量。
VAD(Voice Activity Detection):语音活动检测技术,可以检测语音通话中的语音活动。
PLC(Packet Loss Concealment):丢包恢复技术,可以在网络丢包的情况下尽可能地恢复语音质量。
这些技术都非常重要,可以使得WebRTC在语音和视频通话的质量上有着非常出色的表现。因此,GIPS的音视频引擎成为了WebRTC的核心,使得WebRTC成为了一种非常优秀的Web实时通信技术。