Java数组的定义和使用(万字详解)

目录
编辑
一. 数组的基本概念
1、什么是数组
2、数组的创建及初始化
1、数组的创建
2、数组的初始化
3、数组的使用
(1)数组中元素访问
(3)遍历数组
二、数组是引用类型
1、初始JVM的内存分布
2、基本类型变量与引用类型变量的区别
3、再谈引用变量
4、认识 null
三、数组的应用场景
1、保存数据
2、作为函数的参数
(1)参数传基本数据类型
(2)参数传数组类型(引用数据类型)
四、数组练习
1、数组转字符串
2、数组拷贝
3、求数组中元素的平均值
4、查找数组中指定元素(顺序查找)
5、查找数组中指定元素(二分查找)
6、数组排序(冒泡排序)
7、数组逆序
五、二维数组
1、二维数组的本质
2、遍历数组
3、不规则二维数组
一. 数组的基本概念
1、什么是数组
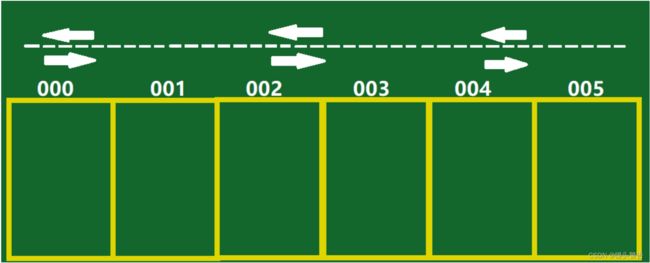
1. 数组中存放的元素其类型相同2. 数组的空间是连在一起的3. 每个空间有自己的编号,其实位置的编号为 0 ,即数组的下标。
2、数组的创建及初始化
1、数组的创建
在之前的C语言的学习过程中,我们采用的是下面的这种方法来创建的数组:
int arr[] = {1,2,3,4,5};在Java中,我们也可以采用和C中同样的方法来创建数组,这是被编译器所允许的,但是在实际的操作中,我们并不推荐用这种方法来创建数组,这是因为:
T[] 数组名 = new T[N];接下来,我们来看一下创建格式中的字符代表的意义:
T :表示数组中存放元素的类型T[] :表示数组的类型N :表示数组的长度
接下来,我们尝试用这种方法创建几个数组:
int[] array1 = new int[10]; // 创建一个可以容纳10个int类型元素的数组
double[] array2 = new double[5]; // 创建一个可以容纳5个double类型元素的数组
String[] array3 = new double[3]; // 创建一个可以容纳3个字符串元素的数组2、数组的初始化
int[] array = new int[10]; T[] 数组名称 = {data1, data2, data3, ..., datan};现在,让我们学以致用,尝试用静态初始化来完成数组的初始化:
int[] array1 = new int[]{0,1,2,3,4,5,6,7,8,9};
double[] array2 = new double[]{1.0, 2.0, 3.0, 4.0, 5.0};
String[] array3 = new String[]{"hell", "Java", "!!!"};此外,在初始化数组的时候,我们要注意以下注意事项:
1、静态初始化虽然没有指定数组的长度,编译器在编译时会根据 {} 中元素个数来确定数组的长度。2、静态初始化时 , {} 中数据类型必须与 [] 前数据类型一致。3、静态初始化可以简写,省去后面的 new T[] 。
现在,我们来思考一个问题:当我们想用下面的方法来将数组进行整体的初始化的时候,这段代码是否会报错呢?
int[] arry = new int[5];
arry = {1,2,3,4,5};答案是:这段代码是错误的!!

这是因为在Java中如果想要将代码整体初始化的时候,必须且只能在定义的时候初始化,否则编译器便会进行报错!
但是如果只是对某个特定下标的元素进行初始化,那么是可以直接进行的,例如:
int[] arry = new int[5];
arry [2] = 4;因此,当我们想要实现数组整体的初始化的时候,只能使用下面的这几种代码来实现;
int[] arry = {1,2,3,4,5};
//或者
int[] arry;
arry = new int[]{1,2,3,4,5};现在,我们来思考一下,如果数组尚未进行初始化,那么数组中的元素储存的是什么呢?
我们用下面这几行未被初始化的代码来试验;
int[] arry = new int[5];
for (int x : arry) {
System.out.print(x+" ");
}运行结果如下图所示:
通过这个小实验,我们可以得知:如果没有对数组进行初始化,数组中元素有其默认值
对于不同的数据类型,其数组中元素的默认值也是不一样的
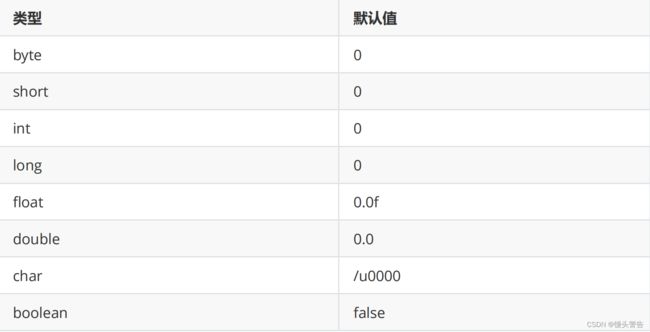
如果数组中存储元素类型为引用类型,默认值为null
3、数组的使用
(1)数组中元素访问
int[]array = new int[]{10, 20, 30, 40, 50};
System.out.println(array[0]);
System.out.println(array[1]);
System.out.println(array[2]);
System.out.println(array[3]);
System.out.println(array[4]);
// 也可以通过[]对数组中的元素进行修改
array[0] = 100;
System.out.println(array[0])注意事项:
1. 数组是一段连续的内存空间,因此 支持随机访问,即通过下标访问快速访问数组中任意位置的元素2. 下标从 0 开始,介于 [0, N )之间不包含 N , N 为元素个数,不能越界,否则会报出下标越界异常。
我们可以通过下面这个数组超标的例子来进行观察:
int[] array = {1, 2, 3};
System.out.println(array[3]); // 数组中只有3个元素,下标一次为:0 1 2,array[3]下标越界运行结果:

因此使用数组一定要下标谨防越界
(3)遍历数组
int[]array = new int[]{10, 20, 30, 40, 50};
System.out.println(array[0]);
System.out.println(array[1]);
System.out.println(array[2]);
System.out.println(array[3]);
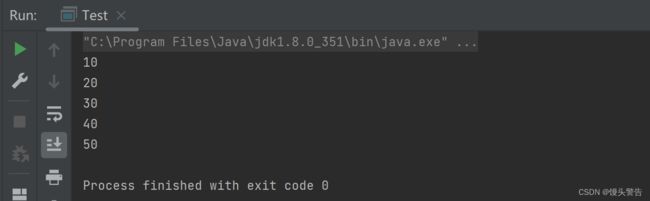
System.out.println(array[4]);int[]array = new int[]{10, 20, 30, 40, 50};
for(int i = 0; i < 5; i++){
System.out.println(array[i]);
}int[]array = new int[]{10, 20, 30, 40, 50};
for(int i = 0; i < array.length; i++){
System.out.println(array[i]);
}
第二种:使用 for-each 遍历数组
int[] array = {1, 2, 3};
for (int x : array) {
System.out.println(x);
}运行结果:

int[] array = {1,2,3,4,5};
System.out.println(Arrays.toString(array));运行结果:

java帮你实现了一个打印数组的方法 : 将数组里面的值 以字符串的形式组织一下然后进行打印
二、数组是引用类型
1、初始JVM的内存分布
1. 程序运行时代码需要加载到内存2. 程序运行产生的中间数据要存放在内存3. 程序中的常量也要保存4. 有些数据可能需要长时间存储,而有些数据当方法运行结束后就要被销毁
如果对内存中存储的数据不加区分的随意存储,那对内存管理起来将会非常麻烦,因此JVM也对所使用的内存按照功能的不同进行了划分:
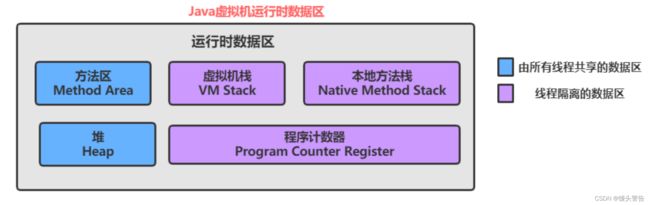
这里我们要注意到的是:JVM的底层代码是由C和C++编写的,因此本地方法栈存储的主要是这些底层代码的内存
那么图中的各个区域又分别有哪些功能呢?
程序计数器 (PC Register): 只是一个很小的空间 , 保存下一条执行的指令的地址虚拟机栈(JVM Stack): 与方法调用相关的一些信息, 每个方法在执行时,都会先创建一个栈帧 ,栈帧中包含 有:局部变量表 、 操作数栈 、 动态链接 、 返回地址 以及其他的一些信息,保存的都是与方法执行时相关的一 些信息。比如:局部变量 当方法运行结束后,栈帧就被销毁了,即栈帧中保存的数据也被销毁了 。本地方法栈(Native Method Stack): 本地方法栈与虚拟机栈的作用类似 . 只不过 保存的内容是 Native 方法的局 部变量 . 在有些版本的 JVM 实现中 ( 例如 HotSpot), 本地方法栈和虚拟机栈是一起的堆(Heap): JVM 所管理的最大内存区域 . 使用 new 创建的对象都是在堆上保存 ( 例如前面的 new int[]{1, 2, 3} ) , 堆是随着程序开始运行时而创建,随着程序的退出而销毁,堆中的数据只要还有在使用,就不会被销 毁 。方法区(Method Area): 用于 存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数 据 . 方法编译出的的字节码就是保存在这个区域
现在我们只简单关心堆 和 虚拟机栈这两块空间,后序JVM中还会更详细介绍。
2、基本类型变量与引用类型变量的区别
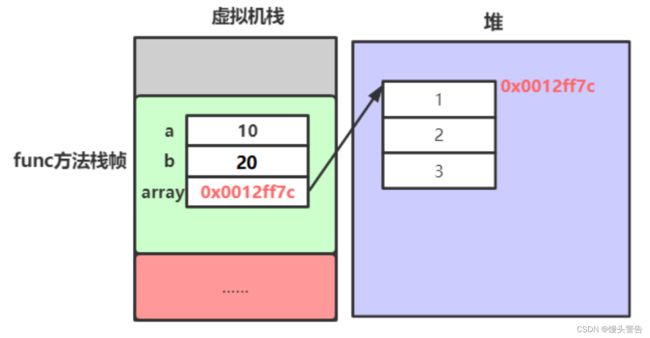
public static void func() {
int a = 10;
int b = 20;
int[] arr = new int[]{1,2,3};
}
3、再谈引用变量
public static void func() {
int[] array1 = new int[3];
array1[0] = 10;
array1[1] = 20;
array1[2] = 30;
int[] array2 = new int[]{1,2,3,4,5};
array2[0] = 100;
array2[1] = 200;
array1 = array2;
array1[2] = 300;
array1[3] = 400;
array2[4] = 500;
for (int i = 0; i < array2.length; i++) {
System.out.println(array2[i]);
}
}我们可以用几幅图来进一步理解:


4、认识 null
int[] arr = null;
System.out.println(arr[0]);
在这段代码报错中的.NullPointerException 是“空指针异常”的意思,但是注意:此指针非彼指针,这里的指针指的并不是我们在C语言中认识的指针,而是因为英文翻译的原因所以称为指针。
三、数组的应用场景
1、保存数据
public static void main(String[] args) {
int[] array = {1, 2, 3};
for(int i = 0; i < array.length; ++i){
System.out.println(array[i] + " ");
}
}2、作为函数的参数
(1)参数传基本数据类型
public static void main(String[] args) {
int num = 0;
func(num);
System.out.println("num = " + num);
}
public static void func(int x) {
x = 10;
System.out.println("x = " + x);
}
// 执行结果
x = 10
num = 0(2)参数传数组类型(引用数据类型)
public static void main(String[] args) {
int[] arr = {1, 2, 3};
func(arr);
System.out.println("arr[0] = " + arr[0]);
}
public static void func(int[] a) {
a[0] = 10;
System.out.println("a[0] = " + a[0]);
}
// 执行结果
a[0] = 10
arr[0] = 10所谓的 " 引用 " 本质上只是存了一个地址 . Java 将数组设定成引用类型 , 这样的话后续进行数组参数传参 , 其实 只是将数组的地址传入到函数形参中. 这样可以避免对整个数组的拷贝 ( 数组可能比较长 , 那么拷贝开销就会很大 ).
四、数组练习
1、数组转字符串
代码示例:
import java.util.Arrays
int[] arr = {1,2,3,4,5,6};
String newArr = Arrays.toString(arr);
System.out.println(newArr);
// 执行结果
[1, 2, 3, 4, 5, 6]2、数组拷贝
// newArr和arr引用的是同一个数组
// 因此newArr修改空间中内容之后,arr也可以看到修改的结果
int[] arr = {1,2,3,4,5,6};
int[] newArr = arr;
newArr[0] = 10;
System.out.println("newArr: " + Arrays.toString(arr));我们可以用下面这个图片来进行理解;
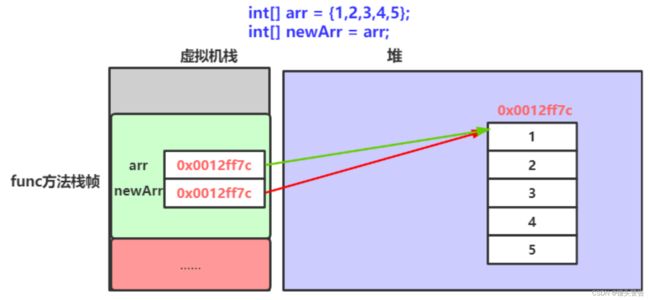
此时,两个数组引用的数组元素一致
第二种:
// 使用Arrays中copyOf方法完成数组的拷贝:
// copyOf方法在进行数组拷贝时,创建了一个新的数组
// arr和newArr引用的不是同一个数组
arr[0] = 1;
newArr = Arrays.copyOf(arr, arr.length);
System.out.println("newArr: " + Arrays.toString(newArr));
// 因为arr修改其引用数组中内容时,对newArr没有任何影响
arr[0] = 10;
System.out.println("arr: " + Arrays.toString(arr));
System.out.println("newArr: " + Arrays.toString(newArr))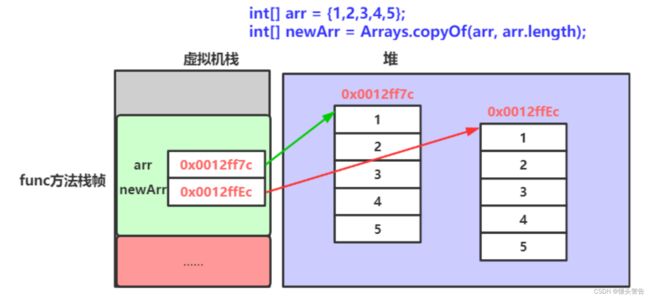
使用Arrays中的copyOf方法来完成堆数组元素的拷贝,其中括号内包含两个部分,第一个部分为被拷贝的数组名,第二个元素为数组长度,我们可以将其理解为,此时两个数组引用的数组内容不同
第三种:
// 拷贝某个范围.
int[] newArr2 = Arrays.copyOfRange(arr, 2, 4);
System.out.println("newArr2: " + Arrays.toString(newArr2));有时候,我们在拷贝数组的时候,不想拷贝整个完整的数组,只想拷贝数组中的某一小部分,这个时候,我们便可以使用Java中的copyOfRange来完成这一系列操作
注意:在Java中表示范围的时候一般都是左闭右开
在这段代码copyOfRange括号内的2,4这个范围表示的就是 [2,4),也就是我们在数学中常说到的左闭右开
第四种:
除了使用Java中已有的方法来实现拷贝数组,我们也可以创建一个自己的方法来完成这个操作
代码如下:
public static int[] copyOf(int[] arr) {
int[] ret = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
ret[i] = arr[i];
}
return ret;
}3、求数组中元素的平均值
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6};
System.out.println(avg(arr));
}
public static double avg(int[] arr) {
int sum = 0;
for (int x : arr) {
sum += x;
}
return (double)sum / (double)arr.length;
}
// 执行结果
3.54、查找数组中指定元素(顺序查找)
public static void main(String[] args) {
int[] arr = {1,2,3,10,5,6};
System.out.println(find(arr, 10));
}
public static int find(int[] arr, int data) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == data) {
return i;
}
}
return -1; // 表示没有找到
}
// 执行结果
35、查找数组中指定元素(二分查找)
针对有序数组, 可以使用更高效的二分查找.
以升序数组为例 , 二分查找的思路是先取中间位置的元素 , 然后使用待查找元素与数组中间元素进行比较:如果相等,即找到了返回该元素在数组中的下标如果小于,以类似方式到数组左半侧查找如果大于,以类似方式到数组右半侧查找
那么接下来,我们来看一下二分查找的代码实现:
public class Test {
public static void main(String[] args) {
int[] arr = {1,2,3,4,5,6};
System.out.println(binarySearch(arr, 6));
}
public static int binarySearch(int[] arr, int toFind) {
int left = 0;
int right = arr.length - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (toFind < arr[mid]) {
// 去左侧区间找
right = mid - 1;
} else if (toFind > arr[mid]) {
// 去右侧区间找
left = mid + 1;
} else {
// 相等, 说明找到了
return mid;
}
}
// 循环结束, 说明没找到
return -1;
}
// 执行结果
5
}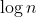 次 ,大大节省了代码的运行时间,提高代码的效率
次 ,大大节省了代码的运行时间,提高代码的效率
6、数组排序(冒泡排序)
假设排升序:1. 将数组中相邻元素从前往后依次进行比较,如果前一个元素比后一个元素大,则交换,一趟下来后最大元素 就在数组的末尾2. 依次从上上述过程,直到数组中所有的元素都排列好

代码示例:
public static void main(String[] args) {
int[] arr = {9, 5, 2, 7};
bubbleSort(arr);
System.out.println(Arrays.toString(arr));
}
public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 1; j < arr.length-i; j++) {
if (arr[j-1] > arr[j]) {
int tmp = arr[j - 1];
arr[j - 1] = arr[j];
arr[j] = tmp;
}
}
} // end for
} // end bubbleSort
// 执行结果
[2, 5, 7, 9] public static void main(String[] args) {
int[] arr = {9, 5, 2, 7};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}7、数组逆序
设定两个下标 , 分别指向第一个元素和最后一个元素 . 交换两个位置的元素 .然后让前一个下标自增 , 后一个下标自减 , 循环继续即可 .
代码示例:
public static void main(String[] args) {
int[] arr = {1, 2, 3, 4};
reverse(arr);
System.out.println(Arrays.toString(arr));
}
public static void reverse(int[] arr) {
int left = 0;
int right = arr.length - 1;
while (left < right) {
int tmp = arr[left];
arr[left] = arr[right];
arr[right] = tmp;
left++;
right--;
}
}五、二维数组
1、二维数组的本质
数据类型 [][] 数组名称 = new 数据类型 [ 行数 ][ 列数 ] { 初始化数据 };
int[][] arr ={{1,2,3},{4,5,6}};这里,我们要注意的是:在Java中,二维数组的定义可以省略列,但是不可以省略行!!!
例如:
//错误的写法:
int arr[] = new int[][3];
//正确的写法:
int arr[] = new int[2][];我们在开头就说过,二维数组的本质就是特殊的一维数组,接下来我们来看看这样说的原因:
public class Test {
public static void main(String[] args) {
int[][] arr ={{1,2,3},{4,5,6}};
System.out.println(arr[0]);
System.out.println(arr[1]);
}
}这段代码的运行结果是这个样子的:

那么这个运行结果到底是什么意思呢?我们先来看一下二维数组的本质:
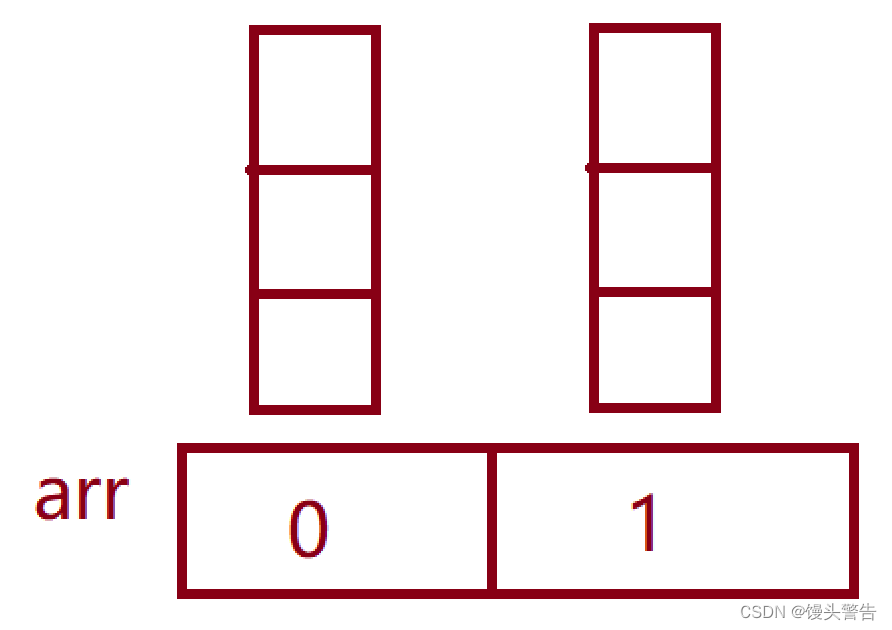
我们可以将二维数组的行下标看成一个个的一维数组,而列下标也看成一个个的一维数组,此时行下标所对应的一维数组存放的便是列下标对应的一维数组的地址,也就是说,我们可以通过行下标来引用列下标中对应的元素
为了验证这一猜想,我们可以来计算一下二维数组的长度:
int[][] array1 ={{1,2,3},{4,5,6}};
System.out.println(array1.length);//行的长度
System.out.println(array1[1].length);//每一列的长度这段代码的运算结果如下:

由此可知,我们的猜想是正确的
2、遍历数组
那么在Java中如何将一个二维数组打印出来呢?
第一种:
public static void main(String[] args) {
int[][] arr = {{1,2,3},{4,5,6}};
for(int[] x:arr)
{
for(int y:x)
{
System.out.println(y);
}
}
}与一维数组中类似,连续使用两个for-each循环便可
第二种:
public static void main(String[] args) {
int[][] arr = {{1,2,3},{4,5,6}};
System.out.println(Arrays.deepToString(arr));
}运行结果如下:

3、不规则二维数组
在Java中,是允许不规则数组的存在,我们一般将每一行列数不一样的数组称为不规则的二维数组
public class Test {
public static void main(String[] args) {
int[][] arr = new int[2][];
arr[1] = new int[3];
arr[0] = new int[5];
System.out.println(Arrays.deepToString(arr));
}
}这段代码的运行结果为:
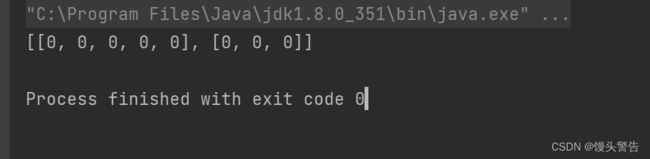
我们可以发现,第一行有五个元素,但是第二行只有三个元素,类似于此的二维数组是可以在Java中存在的。