Java数据结构之优先级队列(堆)
文章目录
- 一、优先级队列
-
- (一)概念
- 二、优先级队列的模拟实现
-
- (一)堆的概念
- (二)堆的存储结构
- (三)堆的创建
-
- 1.堆的创建和向下调整
- 2.堆的创建和向上调整
- (四)堆的插入和删除
-
- 1.堆的插入
-
- 堆的创建和向上调整(续)
- 2.堆的删除
- (五)用堆模拟实现优先级队列
- 三、常用接口介绍
-
- (一)PriorityQueue的特性
- (二)PriorityQueue常用接口介绍
-
- 1.优先级队列的构造
- 2. 插入/删除/获取优先级最高的元素
- 四、堆的应用
-
- (一)PriorityQueue的实现
- (二)堆排序
- (三)Top-k问题
一、优先级队列
(一)概念
优先级队列:能够添加新的对象并且能够返回一组对象中的最高优先级对象的数据结构
二、优先级队列的模拟实现
JDK1.8中的PriorityQueue底层使用了堆的数据结构,而堆实际就是在完全二叉树的基础上进行了一些元素的调整
(一)堆的概念
如果有一个**关键码的集合K = {k0,k1.k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,**并满足:ki <= k2i+1 且 ki <= k2i+2(ki >= k2i+1 且 ki >= k2i+2)i=0,1,2,…,则 称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆
堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值;
- 堆总是一棵完全二叉树(堆就是在二叉树那一节所讲的顺序存储结构)
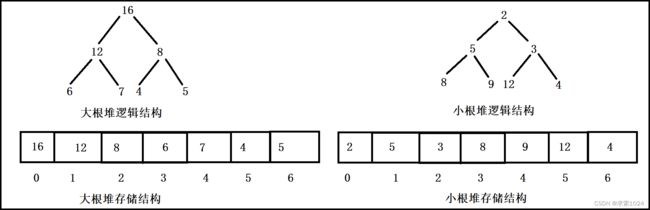
(二)堆的存储结构
从堆的概念可知,堆是一棵完全二叉树,因此可以通过层序遍历的规则采用顺序的方式来高效存储
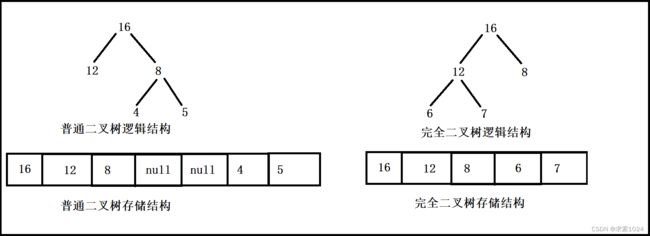
注意:对于非完全二叉树,则不适合使用顺序方式进行存储,因为为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。
将元素存储到数组中后,可以根据二叉树章节的性质5对树进行还原。假设 i 为节点在数组中的下标,则有:
- 如果 i 为0,则 i 表示的节点为根节点,否则 i 节点的双亲节点为(i - 1) / 2
- 如果2 * i + 1小于节点个数,则节点的左孩子下标为2 * i + 1,否则没有左孩子
- 如果2 * i + 2小于节点个数,则节点 i 的右孩子下标为 2 * i + 2,否则没有右孩子
(三)堆的创建
1.堆的创建和向下调整
举例:将集合{15,2,28,7,4,45,22,6}中的数据,如何将其创建成堆呢?
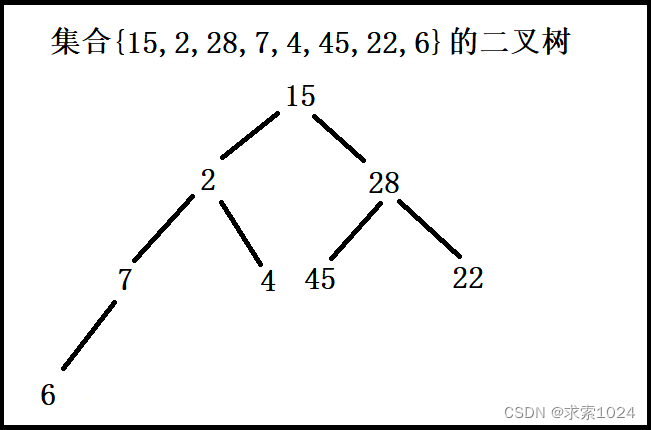
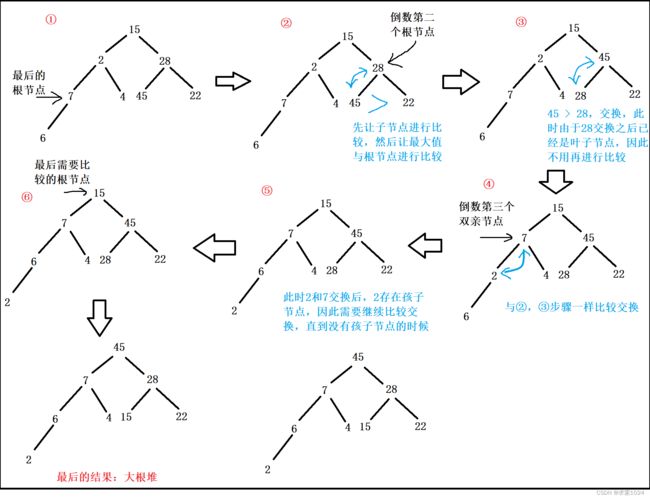
向下过程(以创建大根堆为例)
由于对于大根堆来说,每个节点作为头节点时都是大根堆,那么我们选择从下往上逐个比较排序
那么为什么说是向下调整,因为我们在对根节点和自己的孩子节点进行比较时,假如将孩子节点和根节点交换了,那新的孩子节点作为自己的根节点时,是否还是大根堆呢,我们不得而知,因此我们还要继续向下调整,(重要:虽然我们是从最下面开始,但是并不需要从最后一个开始,只需要从最后一个根节点开始就行)如图:
2.堆的创建和向上调整
在第一种方法中,我们用的是向下调整,但是这么做有个前提,即数据已经全部存放在数组中了,后续不再需要插入数据,在之后,我们还会遇到一种常见的建堆方式,即数据还没有保存到数组中,需要我们一个一个手动插入,那么我们就需要在插入的过程中维护堆,保证插入数据后仍然是一个堆,而关于这种堆的创建方式,我们在介绍完堆的插入之后再详细说明
代码示例:
public void createHeap(int[] array) {
//这里只是添加元素,不理解没关系
for (int i = 0; i < array.length; i++) {
if(usedSize == this.elem.length) {
elem = Arrays.copyOf(elem,elem.length + elem.length>>>1);
}
this.elem[i] = array[i];
usedSize++;
}
//这段代码才调用了向下调整方法
for (int i = (usedSize - 1 - 1) / 2; i >= 0; i--) {
shiftDown(this.elem,i);
}
}
//重点:向下调整算法
public void shiftDown(int[] array,int parent) {
while(parent * 2 + 1 < usedSize) {
int child = parent * 2 + 1;
if (child + 1 < usedSize && array[child] < array[child + 1]) {
child += 1;
}
if (array[parent] < array[child]) {
int tmp = array[child];
array[child] = array[parent];
array[parent] = tmp;
}else {
break;
}
parent = child;
}
}
注意:在调整以parent为根的二叉树时,必须要满足parent的左子树和右子树已经是堆了才可以向下调整
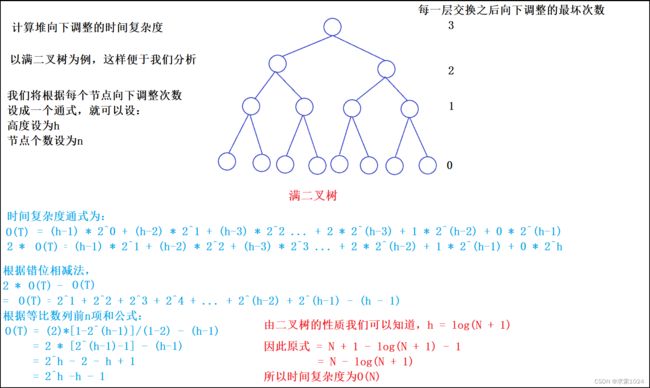
- 向下调整时间复杂度分析:
最坏的情况就是从根节点一路替换到叶子节点,那么比较的次数就是完全二叉树的高度,即时间复杂度为O(logN)- 而 向下调整建堆的时间复杂度为O(N) ,具体推导过程如下:
(四)堆的插入和删除
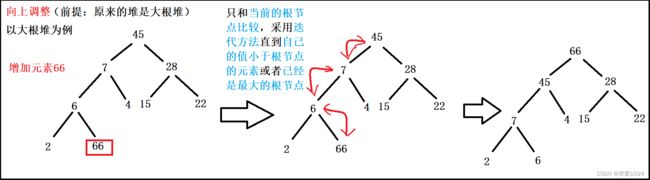
1.堆的插入
堆的插入需要两个步骤:
- 将需要插入的元素放到最后
- 利用向上调整将堆恢复为大根堆(小根堆)
代码示例:
private void shiftUp(int child) {
int parent = (child - 1) / 2;
while(parent >= 0) {
if(this.elem[parent] < this.elem[child]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
child = parent;
parent = (child - 1) / 2;
}else {
break;
}
}
}
堆的创建和向上调整(续)
单纯的插入操作我们已经知道了,而这种堆的创建方式不过就是不断的插入过程而已
在不断的插入中,假如数据量极大,就会有一半的数据都会集中在底层,最坏情况下每次向上调整的时间复杂度为O(logN),有N/2的数据时间复杂度基本都是如此,那么整个创建过程的时间复杂度就是O(N * logN)
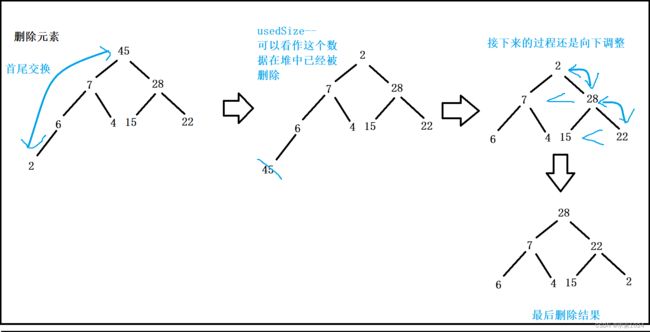
2.堆的删除
注意:堆的删除一定删除的是堆顶元素。删除过程:
- 将堆顶元素和堆中最后一个元素交换
- 将堆中有效个数减少一个,即usedSize–;
- 对堆顶元素进行向下调整
代码示例:
/**
* 出队【删除】:每次删除的都是优先级高的元素
* 仍然要保持是大根堆
*/
public int pollHeap() {
if(isEmpty()) {
throw(new NullPointerException());
}
int tmp = this.elem[usedSize];
this.elem[usedSize] = this.elem[0];
this.elem[0] = tmp;
usedSize--;
shiftDown(0,usedSize);
return this.elem[usedSize];
}
private void shiftDown(int root,int len) {
int child = root * 2 + 1;
while(child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[root] < elem[child]) {
int tmp = elem[child];
elem[child] = elem[root];
elem[root] = tmp;
root = child;
child = root * 2 + 1;
} else {
break;
}
}
}
(五)用堆模拟实现优先级队列
代码示例:
public class PriorityQueue {
public int[] elem;
public int usedSize;
private static final int DEFAULT_SIZE = 10;
public PriorityQueue(int k, Comparator<Integer> comparator) {
this.elem = new int[DEFAULT_SIZE];
}
/**
* 建堆的时间复杂度:O(N)
*
* @param array
*/
public void createHeap(int[] array) {
for (int i = 0; i < array.length; i++) {
if(isFull()) {
elem = Arrays.copyOf(elem,elem.length + elem.length>>>1);
}
this.elem[i] = array[i];
usedSize++;
}
//调整每个根节点
for (int i = (usedSize - 1 - 1) / 2; i >= 0; i--) {
shiftDown(i,usedSize);
}
}
/**
*
* @param root 是每棵子树的根节点的下标
* @param len 是每棵子树调整结束的结束条件
* 向下调整的时间复杂度:O(logn)
*/
private void shiftDown(int root,int len) {
int child = root * 2 + 1;
while(child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[root] < elem[child]) {
int tmp = elem[child];
elem[child] = elem[root];
elem[root] = tmp;
root = child;
child = root * 2 + 1;
} else {
break;
}
}
}
/**
* 入队:仍然要保持是大根堆
* @param val
*/
public void push(int val) {
if(isFull()) {
elem = Arrays.copyOf(elem,elem.length + elem.length>>>1);
}
this.elem[usedSize] = val;
usedSize++;
shiftUp(usedSize - 1);
}
private void shiftUp(int child) {
int parent = (child - 1) / 2;
while(parent >= 0) {
if(this.elem[parent] < this.elem[child]) {
int tmp = elem[child];
elem[child] = elem[parent];
elem[parent] = tmp;
child = parent;
parent = (child - 1) / 2;
}else {
break;
}
}
}
public boolean isFull() {
return usedSize == this.elem.length;
}
/**
* 出队【删除】:每次删除的都是优先级高的元素
* 仍然要保持是大根堆
*/
public int pollHeap() {
if(isEmpty()) {
throw(new NullPointerException());
}
int tmp = this.elem[usedSize];
this.elem[usedSize] = this.elem[0];
this.elem[0] = tmp;
usedSize--;
shiftDown(0,usedSize);
return this.elem[usedSize];
}
public boolean isEmpty() {
return this.usedSize == 0;
}
/**
* 获取堆顶元素
* @return
*/
public int peekHeap() {
if(isEmpty()) {
throw(new NullPointerException());
}
return this.elem[0];
}
}
三、常用接口介绍
(一)PriorityQueue的特性
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue两种类型的优先级队列,PriorityQueue是线程不安全的,PriorityBlockingQueue是线程安全的,本文主要介绍PriorityQueue
关于PriorityQueue的使用要注意:
- 使用时必须导入Priority所在的包,即:
import java.util.PriorityQueue;
- PriorityQueue中放置的元素必须能够比较大小,不能插入无法比较大小的对象,否则会抛出ClassCastException异常
- 不能插入null对象,否则会抛出ClassCastException异常
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
- 插入和删除元素的时间复杂度为O(logN)
- PriorityQueue底层使用了堆数据结构
- PriorityQueue默认情况下是小堆—即每次获取到的元素都是最小的元素
(二)PriorityQueue常用接口介绍
1.优先级队列的构造
此处只是列出了PriorityQueue中常见的几种构造方式
| 构造器 | 功能介绍 |
|---|---|
| PriorityQueue() | 创建一个空的优先级队列,默认容量是11 |
| PriorityQueue(int initialCapacity) | 创建一个初始容量为initialCapacity的优先级队列,注意:initialCapacity不能小于1,否则会抛IllegalArgumentException异常 |
| PriorityQueue(Collection c) | 用一个集合来创建优先级队列 |
注意:默认情况下,PriorityQueue队列是小堆,如果想设为大堆需要用户提供比较器
代码示例:
2. 插入/删除/获取优先级最高的元素
| 函数名 | 功能介绍 |
|---|---|
| boolean offer(E e) | 插入元素e,插入成功返回true,如果e对象为空,抛出NullPointerException异常,时间复杂度O(logN),注意:空间不够时会进行扩容 |
| E peek() | 获取优先级最高的元素,如果优先级队列为空,返回null |
| E poll() | 移除优先级最高的元素并返回,如果优先级队列为空,返回null |
| int size() | 获取有效元素的个数 |
| void clear() | 清空 |
| boolean isEmpty() | 检测优先级队列是否为空,空返回true |
注意:以下是JDK1.8中,PriorityQueue的扩容方式:
优先级队列的扩容说明:
- 如果容量小于64时,是按照oldCapacity的二倍方式扩容的
- 如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
- 如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
四、堆的应用
(一)PriorityQueue的实现
用堆作为底层结构封装优先级队列
(二)堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
- 建堆
- 升序:建大堆
- 降序:建小堆
- 利用堆删除思想进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序
代码示例:
//交换方法
private static void swap(int[] array,int i,int j) {
int tmp = array[i];
array[i] = array[j];
array[j] = tmp;
}
//向下调整
private static void shiftDown(int[] array, int root, int len) {
int child = root * 2 + 1;
while(child < len) {
if(child + 1 < len && array[child] < array[child + 1]) {
child++;
}
if(array[root] < array[child]) {
swap(array,root,child);
}else {
break;
}
root = child;
child = root * 2 + 1;
}
}
//创建大根堆
public static void creatHeap(int[] array) {
int len = array.length;
for(int i = (len - 2) / 2; i >= 0; i--) {
shiftDown(array,i,len);
}
}
// 堆升序排序
public static void heapSort(int[] array){
// write code here
creatHeap(array);
int len = array.length;
while(len > 1) {
swap(array,0,len - 1);
len--;
shiftDown(array,0,len);
}
}
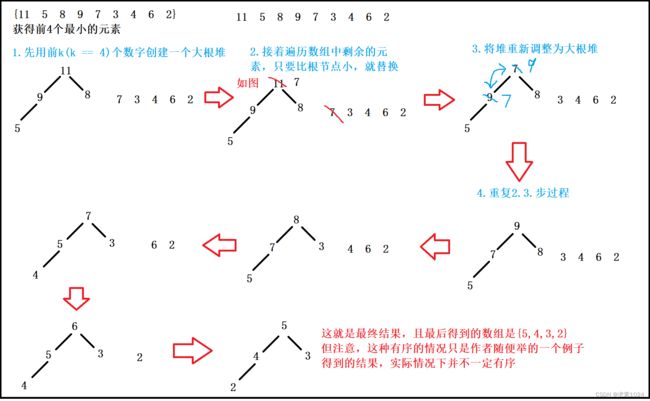
(三)Top-k问题
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大
比如:专业前十名,游戏前十名等
我们利用堆可以解决这个问题,如果还要求对前K个数进行排序,那也可以在先找到这K个元素之后再进行排序,时间复杂度会大大缩减,基本思路如下:
- 用数据集合中前K个元素来建堆
- 前k个最大的元素,则建小根堆
- 前k个最小的元素,则建大根堆
- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素并对堆进行恢复(我理解为末位淘汰机制)
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或最大的元素
图示:
实现代码:
/**
* 著名的TopK问题:得到前 k 个小的值,顺序无所谓
* @param arr 传入的数组
* @param k 具体前 K 个小的元素
* @return 前 k 个小的值的数组
*/
public int[] smallestK(int[] arr, int k) {
//当arr == null 或者 K是0的时候,需要直接返回
if(arr == null || k == 0) {
return new int[0];
}
//创建一个大根堆
PriorityQueue<Integer> pq = new PriorityQueue<>(k,new Comparator<Integer>(){
@Override
public int compare(Integer o1, Integer o2) {
return o2.compareTo(o1);
}
});
for(int i = 0; i < k; i++) {
pq.offer(arr[i]);
}
for(int i = k; i < arr.length; i++) {
int tmp = pq.peek();
if(arr[i] < tmp) {
pq.poll();
pq.offer(arr[i]);
}
}
int[] nums = new int[k];
for(int i = 0; i < k; i++) {
nums[i] = pq.poll();
}
return nums;
}