(二) OpenStack概述 第一篇
OpenStack是一个云操作系统,通过数据中心控制大型的计算、存储、网络资源池,并可以使用Web界面和API进行管理。OpenStack示意图如下:

OpenStack项目旨在提供开源的云计算解决方案以简化云的部署过程,实现类似亚马逊的EC2和S3的IaaS服务。其主要应用场合包括Web应用、大数据、电子商务、视频处理与内容分发、大吞吐量计算、容器优化、主机托管、公共云、计算启动工具包(Computes Starter Kit)和DBaas(数据库即服务,DateBase-as-a-Service)等。
Open意为开放,Stack意为堆栈或堆叠,OpenStack是一系列开源软件的组件,包括若干项目。每个项目都有自己的代号(名称),包括不同的组件,每个组件又包含若干服务,一个服务意味着运行一个进程。这些组件部署灵活,支持水平扩展,具有伸缩性,支持不同规模的云平台。
OpenStack最初仅包含Nova和Swift两个项目,现在已经有数十个项目,其中主要的项目如下表所示。
| 服务 | 项目名称 | 功能 | 对应的AWS服务 |
|---|---|---|---|
| 仪表板 (Dashboard) |
Horizon | 提供一个与OpenStack服务交互的基于Web的自服务门户,让最终用户和运维人员都可以完成大多数的操作,比如启动虚拟机、分配IP地址、动态迁移等 | Console |
| 计算 (Compute) |
Nova | 部署与管理虚拟机并为用户提供虚拟机服务。管理OpenStack环境中计算实例的生命周期,按需响应包括生成、调度、回收虚拟机等操作 | EC2 |
| 网络 (Netwrok) |
Neutron | 为其他OpenStack服务提供网络连接服务,为用户提供API定义网络和接入网络,允许用户创建自己的虚拟网络并连接各种网络设备接口。它提供基于插件的架构,支持众多的网络提供商和技术 | VPC |
| 对象存储 (Object Storage) |
Swift | 允许通过RESTful存储和检索对象(文件),能以低成本的方式管理大量非结构化数据。它具有数据复制和横向扩展的架构,能够实现高度容错 | S3 |
| 块存储 (Block Storage) |
Cinder | 提供块存储服务,为运行实例提供持久下块存储。它的可插拔驱动架构的功能有助于创建和管理块存储设备 | EBS |
| 身份 (Identity) |
Keystone | 为所有OpenStack服务提供身份认证和授权,跟踪用户及他们的权限,提供一个可用的服务及API列表(端点目录) | 无 |
| 镜像 (image) |
Glance | 提供虚拟机镜像的存储、查询和检索服务,通过提供一个虚拟磁盘镜像的目录和存储库,为Nova虚拟机提供镜像服务 | VM Import/Export |
| 计量 (Telenetry) |
Ceilometer | 为OpenStack云的计费、基准测试、扩展及统计等目的提供监测和计量 | CloudWatch |
| 编排 (Orchgestration) |
Heat |
基于模板来编排复合云应用,当在实现应用系统的自动化部署。Heat的作用就是预定义的虚拟机创建时所使用的资源,将这些资源信息汇集到一个模板文件中,通过读取这个模板文件,根据指定的资源来创建虚拟机 | CloudFomation |
| 数据库 (Database) |
Trove | 提供可扩展和可靠的云数据库即服务的功能,可同时支持关系型和非关系型数据库引擎 | RDS |
| 数据处理 (Data Proccssiong) |
Sahara | 为用户提供简单的Hadoop机器的能力,如通过简单配置(Hadoop版本、集群结构、节点硬件信息等)迅速将Hadoop集群部署起来。Hadoop是一个开发和运行处理大规模数据的软件平台 | EMR |
作为免费的开源软件项目,OpenStack由一个名为OpenStack Community的社区开发和维护,来自世界各地的云计算开发人员和技术人员共同开发,维护OpenStack项目。与其他开源的云计算软件相比,OpenStack具有以下优势。
(1)模块松耦合。OpenStack模块分明,容器添加独立功能的组件。往往无须通读OpenStack整个源代码,只需了解其接口规范及API使用,就能添加一个新的模块。
(2)组件配置灵活。OpenStack的组件安装非常灵活,可以全部集中装在一台主机上,也可以分散安装到多台主机中,甚至可以把所有的节点都部署在虚拟机中。
(3)二次开发容易。OpenStack发布的OpenStack API是RESTful API,所有组件采用这种统一的规范,加上模块松耦合设计,二次开发较为简单。
在学习OpenStack的部署和运维之前,我们应当熟悉其架构和运行机制。其架构设计主要通过模块的划分和模块间的功能协作,设计的基本原则如下:
1. 按照不同的功能和通用性划分不同的项目,拆分子系统。
2.按照逻辑计划,规范子系统之间的通信。
3.通过分层设计整个系统架构
4.不同功能子系统间提供统一的API接口。
OpenStack 通过一组相关的服务提供一个基础设施即服务(IaaS)的解决方案。这些服务以虚拟机为中心。虚拟机主要是由Nova、Glance、Cinder和Neutron4个核心模块进行交互的结构。Nova为虚拟机提供计算资源,包括Vcpu、内存等。Glance为虚拟机提供镜像服务,安装操作传统的运行环境。Cinder提供存储资源,类似传统计算机的磁盘或卷。Neutron为虚拟机提供网络配置,以及访问云平台的网络通道。
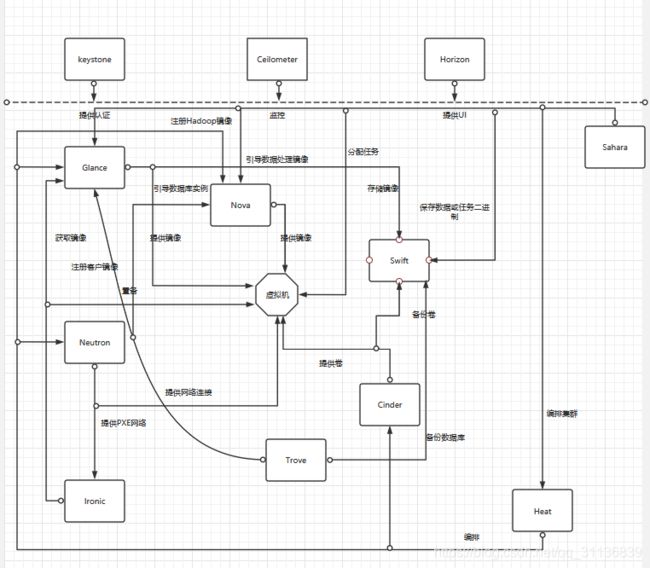
云平台用户在经Keystone服务认证授权后,通过Horizon或REST API模式创建虚拟机服务。创建过程包括利用Nova服务创建虚拟机实例,虚拟机实例采用Glance提供的镜像服务,然后使用Neutron为新建的虚拟机分配IP地址,并将其纳入虚拟网络中,之后再通过Cinder创建的卷为虚拟机挂在存储块。整个过程都在Ceilometer模块的资源监控下,Cinder产生的卷和Glance提供的镜像可以通过Swift的对象存储机制进行保存。
Horizon、Ceilometer、Keystone提供访问访问、监控、身份认证功能,Swift提供对象存储功能,Heat实现应用系统的自动化部署,Trove用于部署和管理各种数据库,Sahara提供大数据处理架构,而Ironic提供裸金属云服务。
云平台用户通过nova-api等来与其他OpenStack服务交互,而这些OpenStack服务守护进程通过消息总线(动作)和数据库(信息)来执行API请求。
消息队列为所有守护进程提供一个中心的消息机制,消息的发送者和接收者相互交换任务或数据进行通信,协同完成各种云平台功能。消息队列各个服务进程解耦,所有进程可以任意分布式部署,协同工作在一起。目前RabbitMQ是默认的消息队列实现技术。
SQL数据库保存了云平台大多数创建和运行时的状态,包括可用的虚拟机实例类型,正在使用的实例、可用的网络项目等。理论上,OpenStack可以使用任一支持SQL-Alchemy的数据库。
想要设计、部署和配置OpenStack,管理员必须理解其逻辑架构,下图为OpenStack服务各个组成部分以及各组件间之间的逻辑关系。

OpenStack包含若干称为OpenStack服务的独立组件。所有服务均可通过一个公共的身份服务进行身份验证。除了那些需要管理权限的命令,每个服务之间均可通过公共API进行交互。
每个OpenStack服务又由若干组件组成,包含多个进程。所有的服务至少有一个API进程,用于倾听API请求,对这些请求进行预处理,并将他们传送到该服务的其他组件。除了认证服务,实际工作是由具体的进程完成的。
至于一个服务的进程之间的通信,则使用AMQP消息代理。服务的状态存储在数据库中。部署和配置OpenStack云时,可以从几种消息代理和数据库解决方案中进行选择,如Rabbitmq,MYSQL,mariaDB和SQLite.
用户访问OpenStack有多种方法,可以通过由Horizon仪表板服务实现的基于Web的用户界面,也可以通过命令行客户端,或者通过浏览器插件或curl发送API请求。对于应用程序来说,可以使用多种软件开发工具包。所有这些访问方法最终都要将REST API 调用发送给各种不同的OpenStack服务。
在实际的部署中,各个组件可以部署到不同的物理节点上。OpenStack本身是一个分布式系统,不仅各个服务可以分布式部署,服务中的组件也可以分布式部署。这种分布式特性让OpenStack具备极大的灵活性、伸缩性和高可用性。当然,从另一个角度来看,这一特性也使OpenStack比一般系统复杂,学习难度也更大。
今天的内容到此结束,多多关注。