MIT6.828_Lab4_PartA_Multiprocessor Support and Cooperative Multitasking
Lab 4: Preemptive Multitasking
简介
本次实验我们将要实现在多并发进程的情况下实现抢占式多任务,在PartA中,将为JOS提供多处理器支持,实现循环调度,并添加基本的进程管理系统调用(创建和销毁环境以及分配/映射内存的调用)。在PartB中,将实现一个类Unix的fork(),它允许用户进程创建子进程。最后,在PartC中,将提供对进程间通信(IPC)的支持,从而允许不同的用户进程进行通信和同步。 还将添加对硬件时钟中断和抢占的支持。
预备工作:首先按课程提示提交lab3代码然后检出lab4代码并合并,lab4包含了一组新的源文件:
kern / cpu.h, 支持多处理器的内核私有定义
kern / mpconfig.c 读取多处理器配置的代码
kern / lapic.c 在每个处理器中驱动本地APIC单元的内核代码
kern / mpentry.S 非引导CPU的汇编语言入口代码
kern / spinlock.h 自旋锁(包括大内核锁)的内核私有定义
kern / spinlock.c 实现自旋锁的内核代码
kern / sched.c 将要实现的调度程序的代码框架
实验要求:本实验分为三部分,每部分限时一周,你应当完成实验中要求的所有练习并解决至少一个挑战问题,并为实现的挑战问题写一个简短的描述说明。
Part A: Multiprocessor Support and Cooperative Multitasking
在本实验的第一部分,我们将首先扩展JOS以使其在多处理器系统上运行,然后实现一些新的JOS内核系统调用,以允许用户进程创建其他新进程。 还将实现协作循环调度,在当前进程自愿放弃CPU(或退出)时,允许内核切换进程。 在PartC中,还将实现抢占式调度,该调度使内核可以在经过一定时间后从进程手中强制重新获得对CPU的控制。
Multiprocessor Support
我们将使JOS支持“对称多处理”(SMP),一种多处理器模型,其中所有CPU都具有对系统资源(例如内存和I / O总线)的同等访问权限。 尽管所有CPU在SMP中在功能上都是相同的,但是在引导过程中,它们可以分为两种类型:引导处理器(BSP)负责初始化系统和引导操作系统; 仅在操作系统启动并运行后,BSP才会激活应用程序处理器(AP)。 哪个处理器是BSP由硬件和BIOS决定。 到目前为止,您所有现有的JOS代码都已在BSP上运行。
在SMP系统中,每个CPU都有一个随附的本地APIC(LAPIC)单元。 LAPIC单元负责在整个系统中传递中断。 LAPIC还为其连接的CPU提供唯一的标识符。 在本实验中,我们利用LAPIC单元的以下基本功能(在kern / lapic.c中):
1.读取LAPIC标识符(APIC ID)以了解我们的代码当前在哪个CPU上运行(请参阅cpunum())。
2.从BSP发送 STARTUP 处理器间中断(IPI)到AP以唤醒其他CPU(请参阅lapic_startap())。
3.在PartC中,我们对LAPIC的内置计时器进行编程,以触发时钟中断以支持抢占式多任务(请参阅apic_init())。
处理器使用内存映射的I / O(MMIO)访问其LAPIC。 在MMIO中,一部分物理内存被硬连线到某些I / O设备的寄存器,因此通常用于访问内存的相同加载/存储指令可用于访问设备寄存器。 您在物理地址0xA0000上有一个I/O Hole(我们使用它来写入VGA显示缓冲区)。 LAPIC的Hole开始于物理地址0xFE000000(4GB下的32MB),但是这地址太高,我们无法访问。 不过JOS虚拟内存映射在MMIOBASE处预留了4MB的空间,因此我们需要建立映射关系。
练习1:
实现kern/pmap.c的mmio_map_region函数,阅读kern/lapic.c的lapic_init函数来看看这个函数怎么被使用的,另外在测试mmio_map_region之前,得先完成下一个练习。
按注释实现mmio_map_region()就行了:

Application Processor Bootstrap
在启动AP之前,BSP首先收集有关多处理器系统的信息,例如CPU的总数,它们的APIC ID和LAPIC单元的MMIO地址。 kern / mpconfig.c中的mp_init()函数通过读取驻留在BIOS内存区域中的MP配置表来检索此信息。
kern / init.c中的boot_aps函数驱动AP引导过程。 AP在实模式下启动,类似the boot loader在boot / boot.S中启动的方式,因此boot_aps将AP入口代码(kern / mpentry.S)复制到可在实模式下寻址的内存位置。与the boot loader不同,我们可以控制AP从何处开始执行代码。我们将入口代码复制到0x7000(MPENTRY_PADDR),但是小于640KB的任何未使用的,页面对齐的物理地址都可以使用。之后,boot_aps通过向相应AP的LAPIC单元发送STARTUP IPI以及初始的CS:IP地址(AP在本例中为MPENTRY_PADDR开始运行),依次激活AP。 kern / mpentry.S中的入口代码与boot / boot.S的入口代码非常相似。经过一些简短的设置后,它将使AP进入启用分页的保护模式,然后调用mp_main()(也在kern / init.c中)。 boot_aps()等待AP在其CpuInfo的cpu_status字段中发信号通知CPU_STARTED标志,然后再唤醒下一个。
练习2:
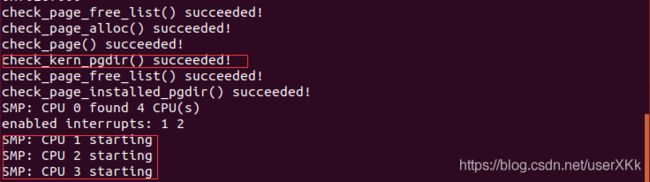
阅读kern / init.c中的boot_aps()和mp_main(),以及kern / mpentry.S中的汇编代码。 确保您了解AP引导过程。 然后在kern / pmap.c中修改page_init()代码,避免将MPENTRY_PADDR中的页面添加到free list 中,以便我们可以安全地在该物理地址复制并运行AP引导程序代码。 您的代码应通过更新的check_page_free_list()测试(但可能无法通过更新的check_kern_pgdir()测试,我们将尽快修复)。
AP引导过程简述:
BSP上运行内核代码后会调用i386_init(),i386_init在初始化一系列环境后会调用boot_aps()来启动其他AP处理器,boot_aps()在复制AP入口代码到MPENTRY_PADDR且设置mpentry.S使用的堆栈后就会调用lapic_startap上发送IPI中断激活AP并开始执行复制的mpentry.S中的代码,mpentry.S中在设置一系列寄存器,初始化环境后,启动分页机制进入保护模式并调用mp_main(),mp_main()中会改变当前处理器的状态为已启动,boot_aps在检测到该处理器状态改变后开始启动下一个AP处理器。
page_init(),红框为修改处:

测试通过check_page_free_list:

问题:
将kern / mpentry.S与boot / boot.S并排比较。kern / mpentry.S就像内核中的所有其他内容一样经过编译和链接以在KERNBASE之上运行,宏MPBOOTPHYS的目的是什么? 为什么在kern / mpentry.S中有必要,但在boot / boot.S中却没有必要? 换句话说,如果在kern / mpentry.S中省略了它,那会出什么问题?(提示:回忆一下我们在实验1中讨论的链接地址和加载地址之间的区别。)
答:宏MPBOOTPHYS的作用是获取变量的物理地址,boot.S存在于启动扇区内,经过编译链接后,代码直接加载到0x7c00处,变量能够被正常访问到,而mpentry.S的被编译链接后的源代码在KERNBASE之上,AP最开始执行的入口代码其实是复制到MPENTRY_PADDR的的副本,里面的变量地址并不正确,所以要通过宏MPBOOTPHYS来算出正确的变量地址,如果省略了它,那么将无法访问到正确的变量或者访问地址超过寻址范围。
Per-CPU State and Initialization
编写多处理器OS时,区分每个处理器的CPU状态和整个系统共享的全局状态非常重要。 kern / cpu.h定义了大多数per-CPU状态,包括存储per-CPU变量的struct CpuInfo结构。 cpunum()始终返回调用它的CPU的ID,该ID可用作cpus之类的数组的索引,宏thiscpu指向当前CPU的结构CpuInfo。
下面是一些值得关注的per-cpu state:
Per-CPU kernel stack.
因为多个CPU可以同时陷入内核,所以我们需要为每个CPU都分配一个内核栈并使它们相互隔离来保证它们执行时互不干涉,数组percpu_kstacks[NCPU][KSTKSIZE] 保留了NCPU个内核栈。
实验2中,我们映射了BSP的内核堆栈的物理地址到[KSTACKTOP-KSTKSIZE,KSTACKTOP],本实验中,我们需要将每个CPU的内核堆栈都映射到对应的区域,其中保护页充当它们之间的缓冲区。
Per-CPU TSS and TSS descriptor.
每个CPU的任务状态段(TSS)指定每个CPU的内核堆栈所在的位置。 CPU i的TSS存储在cpus [i] .cpu_ts中,并且相应的TSS描述符在GDT表项gdt [(GD_TSS0 >> 3)+ i]中定义,在kern / trap.c中定义的全局ts变量将不再有用。
Per-CPU current environment pointer.
因为多核cpu可以同时运行不同的用户进程,为了加以区分,我们重新定义curenv为 cpus[cpunum()].cpu_env(or thiscpu->cpu_env),指向当前CPU上运行的当前进程。
Per-CPU system registers.
所有寄存器,包括系统寄存器,都是每个CPU专用的。 因此,初始化这些寄存器的指令,例如lcr3(),ltr(),lgdt(),lidt()等,必须在每个CPU上执行一次。 为此,定义了函数env_init_percpu()和trap_init_percpu()。除此之外,如果在解决方案中添加了任何额外的per-CPU state或执行了其他任何特定的CPU的初始化(例如,在CPU寄存器中设置新位)来解决早期实验中的问题,请确保复制它们到每个CPU上!
练习3:修改kern/pmap.c中的mem_init_mp(),按照memlayout.h 来建立每个CPU的内核堆栈和对应KSTACKTOP下虚拟地址的映射关系,代码应当通过check_kern_pgdir()的测试。
按照注释中给出的提示,依葫芦画瓢写就行了,修改后的代码如下:

练习4:kern/trap.c中trap_init_percpu()的代码为BSP初始化了TSS和TSS描述符,在实验3中它能正常工作,但是当运行在其他cpu上时,这段代码是不正确的,修改这段代码使其能在所有cpu上正常工作。(注意:新代码不应再使用全局ts变量)
将全局ts改为thiscpu->cpu_ts来初始化各个处理器,注意下图红框部分偏移量要左移三位,保证低三位为0,修改后的代码如下:
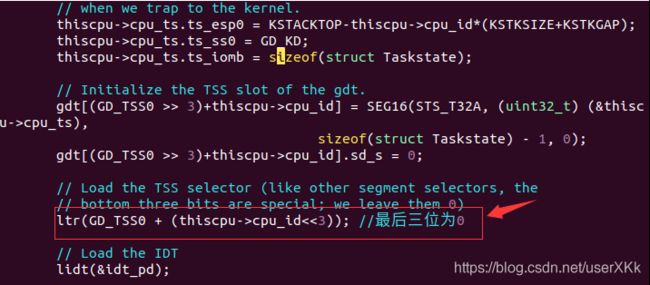
练习3,4测试通过:
Locking
我们的当前代码在mp_main()中初始化AP后自旋,在让AP做更多的工作之前,我们首先需要解决多个处理器可能同时运行内核代码的问题,最简单的方式是使用大内核锁,大内核所是一个全局锁,不论何时当一个进程进入内核态时都会获取该锁,并在返回用户态时释放该锁,在这种模式下,用户态下的进程可以在任何可用的CPU上同时运行,但是同一时刻只能有一个进程能正在内核态下运行,任何其他请求进入内核态的进程都会被强制阻塞。
kern/spinlock.h中声明大内核锁为kernel_lock,同时提供了两种方法lock_kernel和unlock_kernel来获取和释放锁,你应当将大内核锁应用到以下四个位置:
i386_init()中在BSP激活其他CPU前上锁
mp_main()中,在初始化AP后上锁,然后调用sched_yield()在当前AP上开始运行进程。
trap()中,当从用户态陷入时上锁,可以通过检查tf_cs的低两位判断陷入是否发生在用户态
env_run()中,在切换到用户态前释放锁,不要太早也不要太迟,否则你将经历races或死锁
练习5:通过在合适的位置调用lock_kernel()和unlock_kernel()将大内核锁应用到上述区域
(在完成下一个练习实现scheduler后才能测试Locking是否正确)
练习5比较简单,按照上面的提示在给定位置上锁或释放锁就行了,代码就不贴了。
问题:使用大内核锁能够保证同一时刻只有一个cpu能够运行内核代码下,那为什么我们仍需要为每个CPU都分配一个内核栈呢,描述一下在使用大内核锁时使用共享内核栈可能出错的情况。
答:在_alltraps到trap()中lock_kernel()前,已经切换到了内核态,但未对内核代码进行上锁,考虑这样一种情况,cpu1发生陷入,在_alltraps中构建trap frame,构建到一半时,cpu2也发生了陷入并开始构建trapframe,若使用共享内核栈,那么cpu2的构建过程会破坏cpu1的trapframe结果进而导致trapframe数据丢失。
Round-Robin Scheduling
本实验中,下一个任务是修改JOS内核使其能进行循环轮转调度,JOS中的循环调度工作方式如下:
1.kern / sched.c中的sched_yield()负责选择一个要运行的新进程上CPU运行。 它以循环的方式依次搜索envs []数组,从先前运行的环境之后开始(如果没有先前运行的环境,则从数组的开头开始),选择状态为ENV_RUNNABLE的第一个进程(请参见 inc / env.h),然后调用env_run()跳入该进程。
2.sched_yield()绝对不能在两个CPU上同时运行相同的进程。 它可以依靠进程状态ENV_RUNNING表明某个进程当前正在某些CPU(可能是当前CPU)上运行。
3.课程实现了一个新的系统调用sys_yield(),用户进程可以调用该系统调用来调用内核的sched_yield()函数,从而自动放弃CPU。
练习6:如上所述,请在sched_yield()中实现循环调度。 不要忘记修改syscall()来调用sys_yield()。确保在mp_main中调用sched_yield()。修改kern/init.c中的代码以创建三个运行同一程序user/yield.c的进程,运行make qemu,在终止之前,你应当看到进程在彼此之间来回切换了五次,测试输出应该类似下方输出(使用make qemu CPUS=2进行测试):
…
Hello, I am environment 00001000.
Hello, I am environment 00001001.
Hello, I am environment 00001002.
Back in environment 00001000, iteration 0.
Back in environment 00001001, iteration 0.
Back in environment 00001002, iteration 0.
Back in environment 00001000, iteration 1.
Back in environment 00001001, iteration 1.
Back in environment 00001002, iteration 1.
…
在执行yield程序的进程都退出后,系统中应当没有可运行的进程,调度系统应当唤醒JOS内核监视器,如果与上述情况不符,在进行下一步前,请修改代码。
打开sched.c,按照注释的要求编写代码就可以了
修改后的sched_yiled代码:

测试时居然死在了uer_mem_check里面:
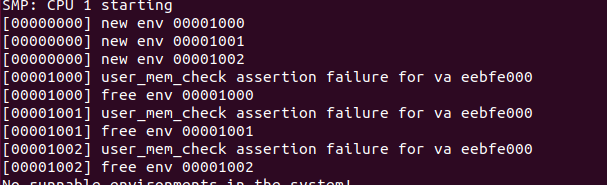
找了半天错误,发现居然多检查了一页:
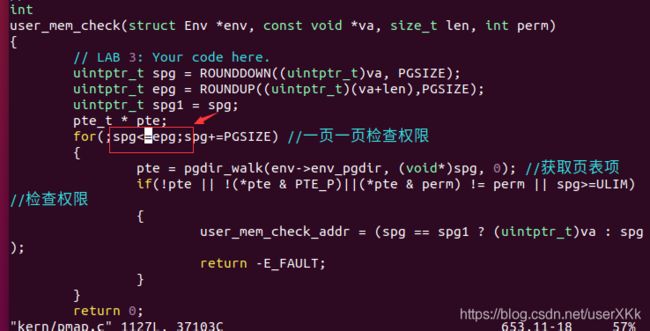
将上图红框中的<=改成<后就能通过测试了:

问题3:在实现env_run时,我们在调用lcr3()加载当前进程的页目录表后,MMU的寻址上下文发生了改变,但是为什么虚拟地址e(env_run的参数)在调用lcr3()前后都能够被解引用?
答:我们在调用env_create创建一个进程时,会调用env_set_vm对被创建进程的虚拟地址空间进行初始化,复制内核页目录表到当前进程页目录表,并修改虚拟地址UVPT使其映射到当前进程页目录表存放的物理地址,在内核页目录表中已经建立了UENVS到envs结构体的映射,所以这份映射关系也被复制到了当前进程页目录表中,简单来说UTOP上方区域除了UVPT那一块映射的地址与内核有所不同,其他映射关系都是一样的。
问题4:每当内核发生进程切换时,都必须确保保存了旧进程的寄存器,以便之后可以正确恢复它们。 为什么? 这发生在哪里?
答:进程切换一定发生在内核态,用户进程从用户态进入内核态只能通过陷入或被中断方式,这两种方式下都会构建trapframe保存陷入/被中断进程的上下文。
System Calls for Environment Creation
尽管内核现在已经能够运行并且在多个用户级进程间切换,但它仍然只能运行内核初始创建的几个进程,我们现在在要实现必要的系统调用来允许用户进程创建并开始其他新的用户进程。
Unix提供fork()系统调用作为进程创建原语。fork()复制父进程的整个地址空间,以创建一个子进程。 从用户空间可观察到的两个唯一区别是它们的进程ID和父进程ID(由getpid和getppid返回)。 在父进程中,fork()返回子进程的进程ID,而在子进程中,fork()返回0。默认情况下,每个进程都获得自己的私有地址空间,并且另一个进程对内存的修改对其他进程都不可见。
我们将提供一组不同的,更原始的JOS系统调用,以创建新的用户进程。 通过这些系统调用,除了其他进程创建之外,还可以完全在用户空间中实现类Unix的fork(),我们将为JOS编写的新系统调用如下:
sys_exofork:
该系统调用创建了一个几乎空白的新进程:在其地址空间的用户部分中未映射任何内容,并且该进程不可运行。 调用sys_exofork时,新进程将与父进程具有相同的寄存器状态。 在父进程中,sys_exofork将返回新创建的进程的envid_t(如果进程分配失败,则返回一个负的错误代码)。 但是,在子进程中,它将返回0。(由于该子进程开始时标记为不可运行,因此sys_exofork不会真正返回该子级,直到父进程显式标记子进程允许该操作。)
sys_env_set_status:
设置给定进程状态为ENV_RUNNABLE或ENV_NOT_RUNNABLE,该系统调用通常用于标记一个地址空间和寄存器状态完全初始化的新进程为就绪态。
sys_page_alloc:
为给定的进程分配一个物理页并将其映射到给定的虚拟地址。
sys_page_map:
将一个物理页的映射(并不是物理页的内容)从一个进程的地址空间中复制到另一进程,使新老映射都引用物理内存的同一页来实现内存共享。
sys_page_unmap:
解除给定进程的指定虚拟地址与对应物理页的映射关系。
对于上面所有接受envid_t的系统调用,JOS内核支持以下约定:值0表示“当前进程”。 此约定由kern / env.c中的envid2env()实现。
我们在测试程序user / dumbfork.c中提供了一个类似于Unix的fork()的实现。 该测试程序使用上述系统调用来创建和运行带有其自身地址空间副本的子进程。 然后,像前面的练习一样,使用sys_yield在两个环境之间来回切换。 父进程在10次迭代后退出,而子进程在20次迭代后退出。
练习7.在kern / syscall.c中实现上述系统调用,并确保syscall()对其进行调用。 实现过程中,我们将需要在kern / pmap.c和kern / env.c中调用各种函数,尤其是envid2env()。 现在,无论何时调用envid2env(),都要在checkperm参数中传递1。 确保检查所有无效的系统调用参数,在这种情况下返回-E_INVAL。 使用user / dumbfork测试JOS内核,并在继续之前确保其工作正常。
sys_exofork的实现难点在于如何使子进程的返回值为0,前面完成的关于系统调用的练习中提到过系统调用的返回值是保存在eax寄存器中的,所以我们可以利用这个机制。修改后的代码如下:

其他函数的实验比较简单,按注释来就行了。
sys_env_set_status:

sys_page_alloc:

sys_page_map:
sys_page_unmap:
make grade测试一下,第一次居然没通过,发生了pgflt:

光看也看不出啥来…修改一下trap.c,添加一下调试代码
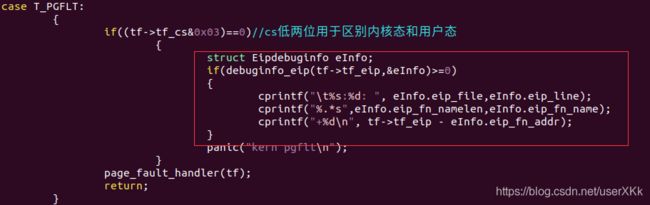
再./grade-lab4 -v测试一下看看打印出啥信息了:

死在sched_yield函数…,仔细检查后发现有两个错误,下图第一个红框部分少判断了一个env结构体,第二个红框部分没有对curenv做检查,导致pgflt:

瑕疵太多,换种写法好了:

再make grade测试一下,这次终于成功通过了:
![]()
测试程序dumbfork也能正常执行:
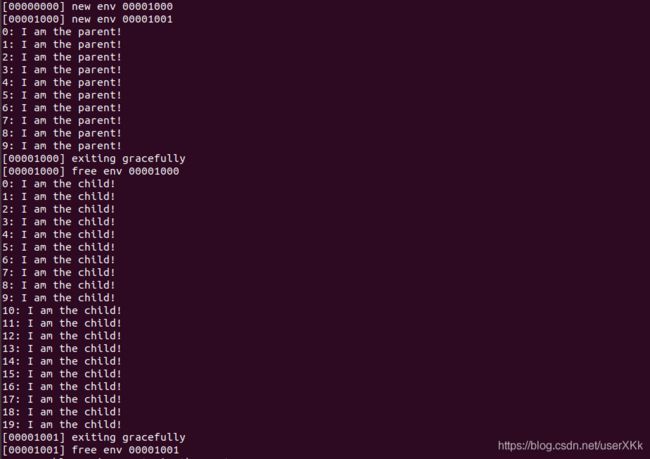
终于完成PartA了…不容易啊。