再探SPDK----使用方法及基础机制概览
再探SPDK----使用方法及基础机制概览
一直以来SPDK作为用户态的存储应用框架,受到了广泛的关注和跟进。本文在之前《初识SPDK》(点击斜体文字,阅读往期文章)的基础上,更进一步从使用、代码目录结构、基础机制和初始化流程的角度对SPDK做了简要的介绍,希望能给大家提供参考。
编译
依赖的子模块

当使用git clone命令从github代码仓库中下载SPDK版本时,可以看到在下载的代码目录下会有一些名如“dpdk”、“isa-l”、“ocf”等的空白目录。无须奇怪,这些目录是SPDK工程所依赖的用以支持某些特性的子模块。这些子模块的描述信息存在于代码工程目录下的“.gitmodules”文件中。有了这些信息当执行“git submodule update --init”命令时,这些被依赖的子模块的代码便会被下载到对应的目录中。 .gitmodules 文件中的内容可如图1所示。
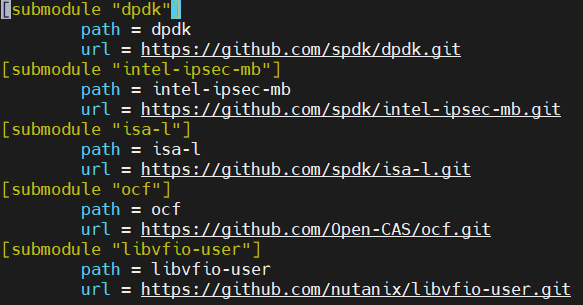
图1. SPDK代码目录中.gitmodules文件内容举例
编译前的配置

在使用“git submodule update --init” 命令更新了依赖的submodule代码后,可以在执行其他的操作前先运行“./spdk/scripts/pkgdep.sh”脚本。这个脚本会根据当前运行的OS类型和指定的参数尝试下从网络上下载安装所需要的依赖包和编译工具。这个脚本也支持指定参数,如果需要指定特性相关的依赖,则可以根据帮助提示信息设置命令参数。运行脚本时建议确保环境可以访问外部网络。
SPDK目前仍然使用的是基于Makefile的编译方式,因而在编译前需要生成完整的Makefile文件。并且通过使用*.mk类型文件将各个相对独立且能被复用的逻辑独立存放也使得 SPDK的配置显得有条理且简练。如果感兴趣,可以在代码目录的mk子目录中看到承载各个基本逻辑的*.mk类型文件。
如果未执行必要的configure操作直接使用make编译时,Makefile的执行过程会因为未检测到相关.mk文件而退出。如同代码目录下的README.md文件所述,在编译前首先需要运行configure相关的配置命令。
1)具体的命令形式如“./configure xxx”, 其中xxx是具体的配置参数,可以使用“--help”参数查看具体的帮助信息。当然也可以不加参数运行,如果不带参数执行,则会使用代码目录下CONFIG文件中的默认配置参数。
2)通过configure命令的参数,可以选择编译或者不编译的模块,指定是否开启debug以及使用指定使用不同版本的依赖模块。例如,通过参数设置可以指定使用个人倾向的另外的DPDK版本或者使用非DPDK子模块目录中的代码。具体的命令如“./configure --with-dpdk=/path/of/dpdk/build”,命令中跟在“--with-dpdk”后的路径下存放的是已经编译生成的DPDK库文件、头文件等。如果使用默认自带子模块中的版本,则SPDK编译的过程中会使用代码目录dpdkbuild子目录中的Makefile来编译子模块目录中的DPDK,并且生成的文件会放在“./spdk/dpdk/build” 路径下。
3)在configure命令执行的过程中会生成“./spdk/mk/cc.mk”、“./spdk/mk/config.mk” 这两个文件。其中cc.mk文件指定了SPDK编译所需要使用的编译和连接的工具链,例如使用交叉编译时的相关配置,即可以在此文件中指定。编译过程中对各个特性或编译过程进行控制的参数则主要存在于config.mk文件中。
4)前已提及的.mk类型文件实际就是一个个的GUN Makefile的逻辑片段。使用它们主要的目的之一就是为了能够方便重用。在SPDK代码目录的mk子目录下有很多的.mk类型文件,它们可以轻松地被其他的Makefile包含使用。以编译nvmf_tgt为例,在 “./spdk/app/nvmf_tgt” 目录下的Makefile中指定了最终要生成的目标文件和所依赖的库文件,但实际如何生成目标文件以及如何连接依赖的库文件都是由“./spdk/mk/spdk.app.mk”中的逻辑进行控制。特别提醒一下:spdk.app.mk文件中的逻辑会让编译生成的文件最终被放到“./spdk/build/bin”目录中。
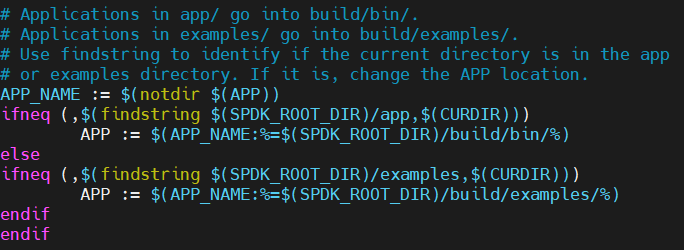
图2. spdk.app.mk文件的片段示意
编译操作

在执行了上述的相关配置操作后,就可以在代码根目录下执行make命令进行编译。对编译的过程,有如下信息需要留意。
1)SPDK代码根目录下Makefile的默认目标是 “all” 并且其依赖于 “mk/cc.mk” 和 “$(DIR-y)” 。鉴于Makefile前向解析依赖反向执行命令的逻辑特性,所以当 “mk/cc.mk” 没有生成时,make命令就会被中断,并提示 “Please run configure prior to make” 。
2)“DIR-y”是“./mk/spdk.subdirs.mk”文件中的定义。得益于这个中间目标的逻辑,make命令可以根据“DIR-y”的值来控制进入各个子目录执行具体的编译操作。因此可以通过它的值来控制编译或者不编译的目录。如果使用默认自带的dpdk子模块的代码,那“DIRS-y”中就会加上“./dpdkbuild”的值,并且由于这个值是最后添加的,所以make命令执行时,会首先编译dpdk模块。如果开启了isa-l的配置时,由于DPDK对isa-l存在依赖,则会在之前先编译isa-l子模块。
3)“./spdk/dpdkbuild”目录下的Makefile是用来控制dpdk编译的,其中的逻辑会创建“./spdk/dpdk/build-temp”的子目录用于编译,并将编译后的文件放到新创建的“./spdk/dpdk/build”子目录中。
4)DPDK的代码从2020年的版本开始已经切换为meson的编译方式,主要使用meson和ninja来加快编译的速度。为了能够正常完成编译过程,需要先安装meson和ninja的工具包。前已提及的pkgdep.sh脚本执行时会尝试安装。
5)如果需要使用非自带的DPDK的源码,那编译DPDK时可以参考如下的步骤来进行。
A. 进入DPDK 源码根目录;
B. 执行命令meson --prefix=”/path/build” build_temp,其中build_temp 是根目录下创建的用于执行编译的子目录;
C. 执行命令ninja -C build_temp进行编译
D. 执行命令meson install -C /src-path/build_temp –only-changed安装编译生成的文件。
注意: 可以通过--profix参数来指定安装的目的路径,如果没有指定,则执行安装操作时,生成的文件会被默认安装到/usr目录下。
运行app
SPDK的应用程序启动前需要有一些必要的配置如分配大页内存等,也有一些可选的配置如通过json文件来指定要执行的私有化操作。
大页内存分配和绑定设备到用户态驱动

SPDK的实现依赖了DPDK的机制,在运行过程中需要使用大页内存。启动SPDK的应用程序前,需要先分配大页内存。当前分配大页内存和将设备绑定到用户态驱动的工作可以由 “./spdk/scripts/setup.sh” 脚本来完成。执行这个脚本时会默认分配1024个大页,并根据系统下IOMMU的配置决定是加载vfio驱动还是uio驱动,且默认将NVMe等类型的PCIe设备绑定到用户态的驱动。如果需要调整分配的大页的数量,或者设置默认绑定到用户态驱动的设备范围,则可以根据帮助信息的提示传递不同的参数来实现。
该脚本使用了“./spdk/include/spdk/pci.h” 中的定义的变量,因而对SPDK的代码路径存在依赖,默认无法单独拿到别的路径执行。脚本默认执行绑定到用户态驱动的PCI设备的类型(主要是由厂商ID和设备ID决定)由其中的collect_devices函数实现的逻辑来控制,如果想要增加其他的设备类型,则可以尝试修改这里的逻辑。
带着json文件启动

SPDK从v20.x的版本开始已经切换为json配置文件的格式。运行可执行程序时可以通过 “--json” 参数来传递json配置文件。当启动SPDK的应用程序时指定了json文件,那在SPDK的初始化流程中就会以rpc的模式来执行其中subsystems(SPDK中各个特性子归集的子系统,后文中会有介绍)的初始化并执行json文件中指定的操作。例如函数bootstrap_fn 中针对有指定json配置文件时,就会在rpc_client_connect_poller函数中来执行subsystem的初始化,并在完成后回调spdk_start_rpc函数。
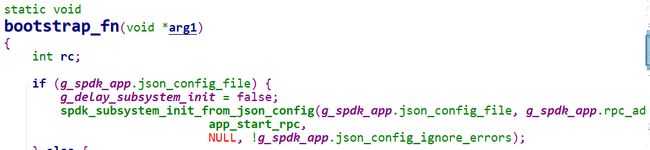
图3. SPDK代码中bootstrap_fn函数片段示例
上述的有json配置文件时以rpc模式执行初始化过程中使用的rpc服务端的监听端口和spdk运行过程中响应用户rpc命令的rpc服务端的监听端口(在函数app_start_rpc中启用)是不同的。在这里的初始化的过程中,函数rpc_client_connect_poller和rpc_client_poller 是扮演了rpc客户端的角色,模拟了通过别的进程来发送rpc命令的动作。基于此,所有从json配置文件中来的参数都被传递给这个临时的rpc服务端在app_json_config_load_subsystem函数来依次执行。
对于SPDK的json配置文件,可以参考如下列出的例子。
{
"subsystems": [
{
"subsystem": "accel",
"config": []
},
{
"subsystem": "vmd",
"config": []
},
{
"subsystem": "schedule",
"config": []
},
{
"subsystem": "sock",
"config": [
{
"method": "sock_impl_set_options",
"params": {
"impl_name": "posix",
"recv_buf_size": 2097152,
"send_buf_size": 2097152,
"enable_recv_pipe": false,
"enable_zerocopy_send": false
}
}
]
},
{
"subsystem": "bdev",
"config": [
{
"method": "bdev_set_options",
"params": {
"bdev_io_pool_size": 65535,
"bdev_io_cache_size": 256,
"bdev_auto_examine": true
}
},
{
"method": "bdev_nvme_set_options",
"params": {
"action_on_timeout": "none",
"timeout_us": 0,
"keep_alive_timeout_ms": 10000,
"retry_count": 4,
"arbitration_burst": 0,
"low_priority_weight": 0,
"medium_priority_weight": 0,
"high_priority_weight": 0,
"nvme_adminq_poll_period_us": 10000,
"nvme_ioq_poll_period_us": 0,
"io_queue_requests": 0,
"delay_cmd_submit": true
}
},
{
"method": "bdev_nvme_set_hotplug",
"params": {
"period_us": 100000,
"enable": false
}
},
{
"method": "bdev_null_create",
"params": {
"name": "null1",
"num_blocks": 2097152,
"block_size": 512,
"md_size": 0,
"dif_type": 0,
"dif_is_head_of_md": false,
"uuid": "d4e960b6-f513-4410-8fcf-e5a2118e7864"
}
}
]
},
{
"subsystem": "nbd",
"config": []
},
{
"subsystem": "scsi",
"config": []
},
{
"subsystem": "iscsi",
"config": []
},
{
"subsystem": "vhost",
"config": []
}
]
}
SPDK应用程序的可用参数和帮助信息

当执行“./spdk_app -h” 的命令时,就可以看到很多的帮助提示信息(此处的spdk_app就是指SPDK的应用程序,例如可以是nvmf_tgt、vhost等等)。默认显示的帮助信息来自在app.c文件中定义且在spdk_app_parse_args函数中调用的usage函数,这些描述的基本也就是SPDK的框架所定义的公共的参数信息。
当然也可以在应用程序的文件中定义私有的参数解析和帮助提示的函数如app_parse和app_usage,并传递给spdk_app_parse_args函数使用。
rpc的使用
rpc是一种为大家所熟知在程序启动后动态灵活地执行操作的方法。其主要使用了unix socket来在客户端和服务端之间传递消息数据。SPDK也集成或者实现了rpc的交互通道,可以支持动态的操作。
SPDK中的rpc服务端

SPDK中的rpc服务端在函数 spdk_rpc_initialize中完成初始化。如果没有指定用于监听的地址,那就会使用默认的监听地址“/var/tmp/spdk.sock”。rpc客户端访问时使用的默认监听地址就是这个。每个需要提供rpc调用的模块或者功能都可以通过SPDK_RPC_REGISTER 来注册其提供服务的函数到g_rpc_methods链表中。函数 jsonrpc_handler是处理所有从客户端过来的请求的入口,其中就会从g_rpc_methods链表中来根据请求匹配具体的处理函数。
SPDK中的rpc客户端

SPDK的rpc客户端提供的功能大部分是以 “./spdk/scripts/rpc.py” 脚本为入口来进行调用的。该脚本会包含“./spdk/python/spdk/rpc”目录下的python脚本,各个rpc功能的客户端处理,以及公共的用于和服务端进行交互的函数就定义在这些被包含的脚本中。每个模块提供的rpc功能中客户端的相应处理逻辑都归集在以模块名字作为名字的python文件中。如果想查询有哪些已经支持的rpc调用功能,则可以直接执行“./rpc.py -h”查询。
当然,rpc的命令调用也可以不局限于rpc.py这个脚本,可以参照其中的逻辑进行私有化的实现。通常一些非正式的或者非通用的用于测试的rpc调用功能就会以这种方式存在,例如,“./spdk/test/bdev/bdevperf/bdevperf.py”就是一个可以参考的例子。但这种情况下,执行对应的python脚本时,通常需要指定“./spdk/python”的路径,以便正常包含并使用对应公共的rpc实现。此类命令的执行,可以举例如“PYTHONPATH=$PYTHONPATH:./python/ test/bdev/bdevperf/bdevperf.py -s /var/tmp/spdk1.sock -t 200 perform_tests”,其中PYTHONPATH就是指定的“./spdk/python”对应的路径以便于能够正常访问该目录下的“spdk/rpc”的子目录。
如果想要添加新的rpc的功能,那就需要通过SPDK_RPC_REGISTER 注册新的功能,并在rpc客户端添加相应的python脚本逻辑。另外,对于启动多进程实例的情况,需要给不同进程指定不同的rpc监听端口(包括rpc服务端和rpc客户端)。
代码目录的关系
总体而言,在不考虑测试代码的情况下SPDK的源码可以近似简单地划分为3个部分:其一,“./spdk/app”和“./spdk/example”目录下最终面向用户的参考应用程序;其二,“./spdk/module”目录下的各个主要特性的实现;其三,“./spdk/lib”目录中实现的各个基础的用以支撑应用和特性的基础机制。
在“./spdk/app”和“./spdk/example”目录下的代码通常都实现有main函数,能编译出具体可执行的应用程序。spdk的应用程序基本都以 spdk_app_start函数来启动,不同的应用可以实现不同的start_fn来执行SPDK框架初始化完成后的私有化操作。start_fn被定义为 spdk_msg_fn 函数指针类型,具体的实现可以参考 spdk_nvmf_tgt_started。当start_fn被调时SPDK的框架已经初始化完成了,并且rpc服务端也已经初始化完成。可以选择将这个start_fn中执行私有的操作以rpc的方式来完成,而这个函数中什么都不做。
“./spdk/lib”目录下的大部分代码主要是为“./spdk/module”目录下的实现提供基础的公共的调用接口和逻辑,而“./spdk/module”目录下的代码也基于这些提供的接口和功能实现了更多更复杂的特性逻辑。rpc可以看作表明这种相对关系的一个点,可以看到提供的rpc功能大部分都是针对各个特性来实现,例如“create bdev”、“attach nvme controller”等等。
SPDK支持或提供的主要特性是以subsystem的数据结构来进行组织,这些实现主要存在于 “./spdk/module/event/subsystem” 目录下。
在SPDK基础实现的代码中,“./spdk/lib/event”和“./spdk/lib/env_dpdk”这两个子目录值得特别关注。前者提供了SPDK初始化流程相关的实现以及reactor的机制,后者则主要是包含了基于DPDK提供的接口封装出来的被SPDK广泛使用的基本功能。
SPDK中主要基础机制分析
SPDK中的分核并行、免锁及“Run to completion” 的编程特性,主要是由reactor、events、poller和io channel的机制构成。在这些基本的机制的基础上,SPDK开发提供了丰富的特性并形成了各个subsystem的子系统。
Reactors

SPDK Reactor的实现主要依赖了DPDK中的线程模型和跨线程通信的机制来实现。
rte thread loop
当DPDK中rte_eal_init函数被执行时,其会在除当前运行的CPU核(main core)外的各个指定可用的CPU核(slave core)上创建线程,并通过修改线程的亲和参数将其绑定在对应的CPU核上运行。每个线程的执行函数是eal_thread_loop,一直在等待从pipe中接收数据并执行。
rte_mempool 和 rte_ring
DPDK中提供了 rte_mempool 和 rte_ring 的机制来支持针对内存方面的需求。
1)每个rte_mempool实例都是一个些由大页内存组成的内存池,并且以特定的数据结构进行组织,其中支持的每个分配和使用的单元可以用于存储调用者的数据。
2)rte_ring则是用于传递消息的队列,每个在rte_ring中传递的单元是一个内存指针,可以参见 spdk_thread_send_msg函数中的使用。并且rte_ring使用了无锁的队列模型,支持多生产者多消费者的模式,当前SPDK中使用的是多生产者单消费者的模式。
3)当创建rte_mempool时会同时在各个可用的CPU创建cache buffers(一些从rte_mempool中预先分配的单元),以便当调用rte_mem_get时直接从cache buffer中获取,加速分配的过程。
4)在使用rte_mempool_create函数创建rte_mempool时需要指定每个buffer分配单元的大小。使用 rte_mem_get函数会返回单个的buffer单元,而通过rte_mempool_get_blk可以获取多个buffer的单元。
5)rte_mempool和rte_ring通常一起用于内存分配和内存传递,其二者之间本身没有必然的依赖。后文会讲到,SPDK中的events机制就主要利用了这两个功能。
spdk reactor
SPDK启动后,在每个指定可用的CPU核上均会运行一个reactor,且在除主核外的CPU核上,SPDK的reactor 和 eal_thread_loop有一一对应的关系。
1)在spdk_app_start函数中,运行在非主CPU核上的reactor都是通过eal_thread_loop来“远程”启动的。
2)SPDK 中reactor的执行函数是 reactor_run 。该函数会循环运行,除非接收到 “退出” 信号才会返回。所有的SPDK业务逻辑都是在各个reactor_run函数中来完成。
3)spdk_reactores_init调用的流程会在函数spdk_thread_lib_init_ext中将g_new_thread_fn赋值为reactor_thread_op,从而实现后续以spdk_create_thread创建的逻辑层面的thread都和具体的reactor相关联。
events机制
“reactor->events”是基于rte_ring来实现的,可以用于在reactors之间传递消息。通过调用spdk_event_allocate和spdk_event_call可以向任一spdk使用的CPU核(包括自身---当前逻辑运行所在的CPU核)来发送需消息,以便运行私有的逻辑操作。一般会使用到这个events机制的情形有:其一,需要在当前CPU核上延迟地做某个动作,但还有没有对应的spdk_thread可使用;其二,需要在其他SPDK使用地CPU核上做某个动作,但还没有关联的spdk_thread可用。
如果没有一个关联的spdk_thread数据结构,无法通过spdk_thread_send_msg来发送消息。所以当新的spdk_thread创建时,就会使用spdk_event_call机制来将创建的spdk_thread挂到指定CPU核对应reactor的threads链表中。
对于每个从“reactor->events”中取出的event, 默认会尝试使用“reactor->threads”链表中的第一个来执行其具体的逻辑。当然,如果“reactor->threads”链表是空的,调用spdk_set_thread时传递的值就是NULL。
SPDK 的调度策略
SPDK默认的调度策略是static类型,即reactor和thread都运行在polling模式。也可以尝试通过rpc命令来修改SPDK的调度策略为dynamic类型。在dynamic类型调度策略下,reactor和thread可能会有polling和interrupt两种运行模式。本文所有的描述均基于static类型调度策略下的情况进行。
SPDK的线程模型

spdk_thread逻辑线程
spdk_thread 不是常规意义下的线程,实际是个逻辑上的概念,它没有具体的执行函数,其所有相关的操作均在reactor的执行函数中来执行。spdk_thread和reactor的关系是N:1的对应关系,即每个reactor上可以有很多的spdk_thread,但每个spdk_thread需要属于且只能属于一个具体的reactor,具体参见图4所示。
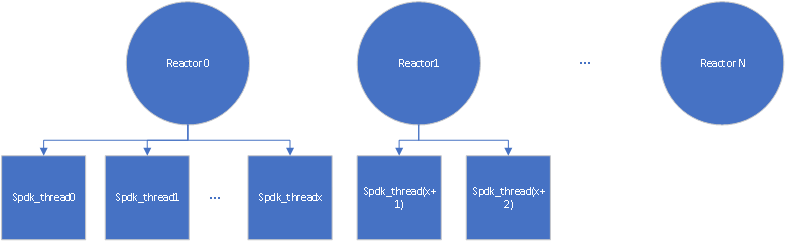
图4. SPDK中reactor和spdk_thread的关系示意
tls_thread
每个spdk_thread数据结构有一个扩展的成员“spdk_thread->ctx[0]”。这个扩展结构的分配和使用均是按照struct spdk_lw_thread的数据结构。正是通过这个扩展的数据结构将spdk_thread和 reactor关联起来。
如前所述,当创建一个新的spdk_thrad时,会通过reactor_thread_op函数将新的spdk_thread添加到“reactor->threads”链表中,其中添加的就是lw_thread的数据结构。
在reactor的执行过程中,其运行针对各个spdk_thread相关的指定操作前,会使用spdk_set_thread来设置即将运行的操作(如poller/message的执行函数)的上下文,执行完成后又会清除。这样同一个reactor下的各个spdk_thread之间就可以独立运行,互不影响。
Poller

spdk_poller
每个注册的spdk_poller存放于“spdk_thread->timed_pollers”的红黑树结构或者“spdk_thread->active_pollers”链表中。所以如果想要使用poller,那首先需要创建一个spdk_thread。
有了spdk_thread后就可以通过注册spdk_poller来重复或者周期性的运行某个函数。如果注册poller时的周期指定为0,那么poller对应的执行函数就会在每个reactor的循环中均进行调用;如果周期不为0,那各次reactor的循环中就会检查是否满足执行的周期时才执行。
spdk_thread的消息队列
当创建了spdk_thread后,就可以使用spdk_thread_send_msg函数来执行具体的函数。通过选择合适的spdk_thread可以实现在当前CPU核或其他SPDK使用的CPU核上去执行操作,并且这种情况下的操作是一次性的。这个函数中传递的msg就是从g_spdk_msg_mempool (一个rte_mempool实例) 中分配的,传递时就使用了rte_ring的无锁队列。
可以简要描述reactor、events、spdk_thread和poller之间的相互关系如下图5中所示。

图5. reactor、events、spdk_thread和poller之间的关系示意
IO channel

创建IO channel
IO channel 是一个用于在每个可用的CPU核上分别单独执行相同操作的抽象机制。它实际需要注册的对象“io device” 并不要求是传统意义上的IO设备,其对应的数据结构定义为 “void *” 的类型,可以支持任意私有的数据结构。这个机制下每个CPU核相关的数据结构是 “struct spdk_io_channel” 。这个数据结构有一个扩展区域可以自由定义。每个CPU核上执行的操作就使用spdk_io_channel来归集。
当使用spdk_io_device_register函数注册一个私有的“io device”时,需要同时指定spdk_io_channel_create_cb和spdk_io_channel_destroy_cb的实现。在spdk_get_io_channel第一次被调用时,就会创建spdk_io_channel数据结构并添加到对应“spdk_thread->io_channels”红黑树结构中。
spdk_thread、spdk_io_channel和 “io device” 的相互关系可以简要表述如下图中所示。
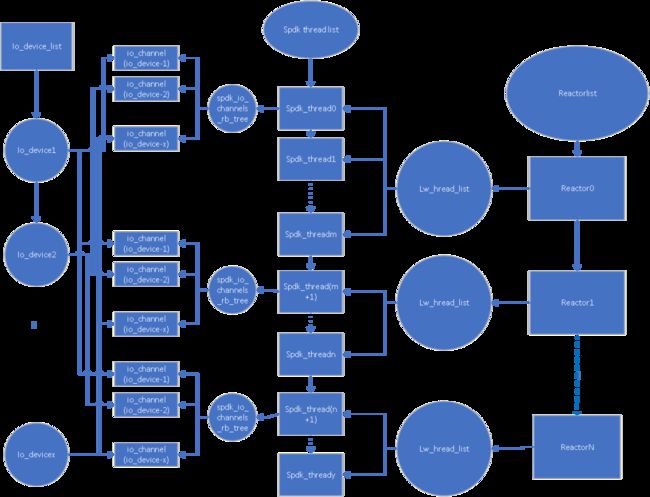
图6. spdk_io_channel机制各个相关数据结构间的关系示意
spdk_for_each_channel遍历机制
注册了“io device”后,就可以调用spdk_for_each_channel来遍历该“io device”对应的各个已创建的spdk_io_channel(在不同的CPU核上)并执行指定的操作函数,且在所有CPU核上相关的spdk_io_channel都遍历完成后再回调传入的回调函数。
spdk_for_each_channel函数有4个参数:第一个是 “io device” 用于匹配注册的IO设备的数据结构;第二个是计划要在匹配到的spdk_io_channel上执行的函数;第三个是前边执行函数的参数;最后一个是当所有遍历和执行都完成后的回调函数。
在上述过程中,当匹配到一个spdk_io_channel时,是通过取出spdk_io_channel对应的spdk_thread然后调用spdk_thread_send_msg来执行传入的具体函数。需要注意的是,在第二个参数指定的操作函数中,需要在返回前执行spdk_for_each_channel_continue的操作,否则遍历将无法完成。
SPDK中的subsystem和其中的依赖关系

这里讨论的subsystem和NVMf Target中的subsystem是不同的概念,这里主要是指SPDK中的主要特性归集的一个子系统或者模块。并且这里的subsystem通过SPDK_SUBSYSTEM_REGISTER 注册到SPDK的框架中。
目前SPDK框架中有10个已经注册的subsystem:accel、bdev、iscsi、nbd、nvmf_tgt、schedule、scsi、sock、vhost和vmd。它们之间有一些依赖关系需要注意。每个subsystem使用SPDK_SUBSYSTEM_DEPEND来定义它对其他subsystem的依赖,比如需要被依赖的subsystem完成初始化后才能运行本subsystem的初始化。
一般情况下当未使用json配置文件时,在bootstrap_fn函数中会执行spdk_subsystem_init来执行subsystem的初始化。
subsystem的初始化顺序可以参考如下:schedule→accel→vmd→sock→bdev→nvmf→nbd→scsi→iscsi→vhost。
有一个点需要特别注意,就是在每个注册的subsystem的初始化函数返回前需要执行 spdk_subsystem_init_next(0)的操作以便剩下的sbusystem能被继续初始化。
初始化流程分析
前已提及,一个SPDK的应用程序初始化可以被简单划分成两个部分:一个是spdk框架的初始化;另一个是私有的初始化流程。
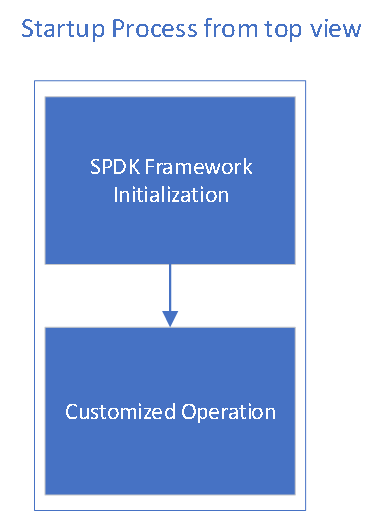
图7. SPDK应用程序初始化过程划分示意
深入到具体的SPDK框架初始化的流程中,可以简单列举其中的初始化过程如下图中所示。
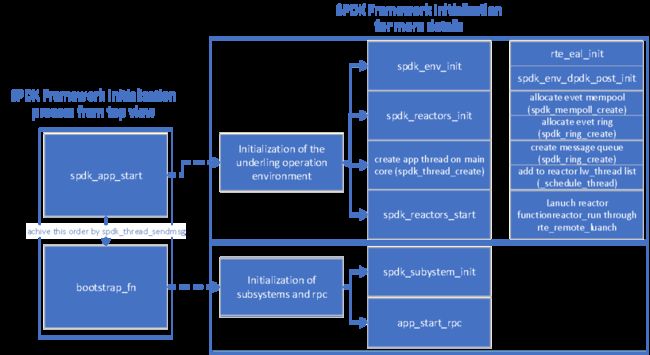
图8. SPDK 框架初始化过程示意
有几个点需要注意:
1. 当g_app_thread创建时,_schedule_thread是通过spdk_event_call的机制异步执行的,并且_schedule_thread的执行是在函数bootstrap_fn之前。
2. 函数bootstrap_fn函数 在spdk_app_start返回后执行。
3. 当spdk应用程序启动时指定了json配置文件时,初始化的流程中会通过spdk_subsystem_init_from_json_config来执行rpc模式的初始化,并在这个调用流程中来执行spdk_subsystem_init的操作。
参考信息
1. https://spdk.io/doc/
2. 初识SPDK
3. SPDK负载均衡初探
4. SPDK配置文件从INI到JSON的转换

转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
DPDK社区安全问题处理流程介绍
SPDK NVMe-oF多路径结合Delay Bdev使用场景
SPDK发布v22.05版本
从SPDK Blobstore到 Blob FS


点点“赞”和“在看”,给我充点儿电吧~