ASMLP: An Axial Shifted MLP Architecture for Vision
本文也是通过偏移操作来提高局部信息提取能力,具体将偏移通过每个feature map沿H和W方向分别偏实现。此外,结构上引入了深细结构,分析上类比卷积感受野做分析(图3)。
Abstract
本文提出了一种轴向移位MLP结构(AS-MLP)。与MLP-Mixer中通过矩阵转置和一个token-mixing MLP对信息流进行全局空间特征编码不同,我们更关注局部特征通信。通过对特征图的通道进行轴向移动,AS-MLP能够获得来自不同轴向的信息流,从而捕获局部依赖关系。这样的操作使我们能够利用纯MLP架构来实现与CNN类似的架构相同的局部接受域。我们也可以像设计卷积核一样设计AS-MLP块的接受域大小和扩张等。使用本文提出的AS-MLP架构,我们的模型在ImageNet1K数据集上获得了83.3%的Top-1精度,参数为88M, GFLOPs为15.2。这种简单而有效的架构优于所有基于MLP的架构,并实现了与基于Transformer的架构(例如Swin Transformer)相比具有竞争力的性能,即使具有略低的FLOPs。此外,AS-MLP也是第一个应用于下游任务(如对象检测和语义分割)的基于MLP的体系结构。实验结果也令人印象深刻。我们提出的AS-MLP在COCO验证集上获得了51.5 mAP,在ADE20K数据集上获得了49.5 MS mIoU,这与基于Transformer的架构相比是有竞争力的。代码可在https://github.com/svip-lab/AS-MLP上找到。
1 Introduction
在过去的十年中,卷积神经网络(CNNs) (Krizhevsky et al.,2012;He et al.,2015)得到了广泛的关注,并已成为计算机视觉事实上的标准。此外,随着对自注意的深入探索和研究,基于Transformer的架构也逐渐出现,并在自然语言处理(如Bert (Devlin et al.,2018))和视觉理解(如ViT (Dosovitskiy et al.,2020)、DeiT (Touvron et al.,2018)等方面超越了基于CNN的架构,2020)),在大量的训练数据的前提下。最近,Tolstikhin等人(2021)首先提出了基于MLP的体系结构,其中几乎所有的网络参数都是从MLP (linear layer)中学习的,并取得了惊人的效果,可以与类似CNN的模型相媲美。
这些有前景的结果推动了我们对基于MLP架构的探索。在MLP-Mixer (Tolstikhin et al.,2021)中,该模型通过矩阵置换和token-mixing投影获得全局接受域,从而覆盖了远程依赖。然而,这很少能充分利用本地信息,而这在类似CNN的架构中非常重要(Simonyan & Zisserman, 2014;He at al.,2015),因为不是所有像素都需要远程依赖,局部信息更多的集中在低水平特征的提取上。在基于Transformer的架构中,已经有一些论文强调了局部接受域的优势,并在Transformer中引入了局部信息,如Localvit (Li et al.,2021)、NesT (Zhang et al.,2021)等。在这些思想的驱动下,我们主要探讨局部性对基于MLP架构的影响。
为了引入locality到MLP-based架构,一种最简单、最直观的想法是给MLP-Mixer添加一个窗口,然后对窗口内的特征进行局部信息的token-mixing投影,就像在Swin Transformer(Liu et al ., 2021 b)。然而,对于基于MLP的体系结构,如果我们分割窗口(如7×7),并在窗口中进行token-mixing投影,则只使用了49×49共享的linear层,这大大限制了模型的容量,从而影响参数的学习和最终结果。因此,我们为基于MLP的体系结构提出了一种轴向转移策略,即在水平和垂直方向上空间转移特征。轴向位移可以将不同空间位置的特征安排在同一位置上。然后利用信道混合MLP将这些特性结合起来,该方法简单而有效。这种方法可以使模型获得更多的局部依赖关系,从而提高性能。它还使我们能够设计出与卷积核相同的MLP结构,例如设计核的大小和膨胀率。
基于轴向偏移策略,我们设计了轴向偏移MLP架构,命名为AS-MLP。在ImageNet1K数据集中,我们的AS-MLP在没有任何额外训练数据的情况下,使用88M参数和15.2 GFLOPs获得了83.3%的Top-1准确率。这种简单而有效的方法优于所有基于MLP的体系结构,并取得了与基于Transformer的体系结构具有竞争力的性能。AS-MLP体系结构也可以转移到下游任务(例如,对象检测)。据我们所知,这也是将基于MLP的体系结构应用到下游任务的第一个工作。在ImageNet-1K数据集中使用预先训练的模型,AS-MLP在COCO验证集上获得了51.5 mAP,在ADE20K数据集上获得了49.5 MS mIoU,这与基于Transformer的架构相比是有竞争力的。
2 Related Work
CNN-based架构。自从AlexNet (Krizhevsky et al.,2012)在2012年ImageNet竞赛中胜出以来,基于CNN的架构逐渐被用来自动提取图像特征,而不是手工制作特征。随后,提出了VGG网络(Simonyan & Zisserman, 2014),该网络纯粹使用了一系列3×3卷积和全连接层,在图像分类方面取得了出色的性能。此外,提出了ResNet (He et al.,2015),利用残差连接在不同层间传递特征,从而缓解了梯度消失的问题,获得了优越的性能。之后,残差模块成为网络设计的重要组成部分,在后续的基于Transformer的架构和基于MLP的架构中也被采用。一些论文对基于CNN架构的卷积运算做了进一步的改进,如扩张卷积(Yu & Koltun, 2015)和变形卷积(Dai et al.,2017)。这些架构构建了CNN家族,并广泛用于计算机视觉任务。
Transformer-based架构。Transformer最早提出于(Vaswani et al.,2017),利用注意机制对不同空间位置的特征之间的关系进行建模。随后,BERT (Devlin et al.,2018)在NLP中的普及也推动了视觉领域对Transformer的研究。ViT (Dosovitskiy et al.,2020)采用纯Transformer框架提取视觉特征,将图像分割为16×16大小的patches,完全放弃卷积层。结果表明,基于Transformer的体系结构可以在大规模数据集(如JFT-300M)中表现良好。之后,DeiT (Touvron et al.,2020)仔细设计了训练策略和数据增强,以进一步提高在小数据集(如ImageNet-1K)上的性能。DeepViT (Zhou et al.,2021)和CaiT (Touvron et al.,2021b)考虑网络深化时的优化问题,并训练更深层的Transformer网络。CrossViT (Chen et al.,2021)使用两个视觉Transformer将局部patch和全局patch结合起来。CPVT (Chu et al.,2021b)使用条件位置编码对空间位置进行有效编码。LeViT (Graham et al.,2021)从卷积嵌入、额外非线性投影、批处理归一化等方面对ViT进行了改进。Transformer-LS (Zhu et al.,2021)提出了对语言和视觉任务的长序列建模的长期注意和短期注意。一些文章也在不同尺度设计层次骨干提取空间特征,如PVT(王et al ., 2021),Swin Transformer(Liu et al., 2021 b),Twins(Chu et al ., 2021)和NesT(Zhang et al ., 2021),可应用于下游任务(例如,对象检测和语义分割)。
MLP-based架构。MLP-Mixer (Tolstikhin et al.,2021)设计了一个非常简洁的框架,利用矩阵置换和MLP在空间特征之间传递信息。利用MLP、层间跳跃连接和归一化层,MLP-Mixer得到了很好的实验结果。并发工作FF (Melas-Kyriazi, 2021)也采用了类似的网络架构,并得出了类似的结论。这些实验结果令人惊讶,表明基于MLP的体系结构也达到了与基于CNN的体系结构和基于Transformer的体系结构相当的性能。随后,提出了Res-MLP (Touvron et al.,2021a),该算法也仅在ImageNet1K上训练resMLP,获得了令人印象深刻的性能。gMLP (Liu et al.,2021a)和EA (Guo et al.,2021)分别引入了空间门控单元(Spatial Gating Unit, SGU)和外部关注,以提高纯基于MLP架构的性能。最近,Container (Gao et al.,2021)提出了一种统一卷积、Transformer和MLP-Mixer的通用网络。与我们工作最接近的并行方法是S2-MLP (Y u et al.,2021)和ViP (Hou et al.,2021)。S2-MLP使用空间移位MLP进行功能交换。ViP提出了一个用于空间信息编码的Permute-MLP层,以捕获远程依赖关系。与他们的工作不同的是,我们关注的是在空间维度上捕捉具有轴向移动特征的局部依赖关系,从而获得更好的性能,可以应用到下游任务中。
3 The AS-MLP Architecture
3.1 Overall Architecture
图1显示了我们的轴向移位MLP (AS-MLP)体系结构。给定一个RGB图像![]() ,其中H和W分别为图像的高度和宽度。AS-MLP首先执行patch分区操作,将原始图像分割成多个patch tokens,patch大小为4×4,因此所有token的组合大小为
,其中H和W分别为图像的高度和宽度。AS-MLP首先执行patch分区操作,将原始图像分割成多个patch tokens,patch大小为4×4,因此所有token的组合大小为![]() 。ASMLP共有四个阶段,不同阶段的AS-MLP区块数量不同。图1只显示了AS-MLP的小版本,其他变体将在第3.4节中讨论。上一步中的所有token都将经过这四个阶段,最终输出的特征将用于图像分类。在阶段1中,每个token采用线性嵌入和AS-MLP块。输出的维度为
。ASMLP共有四个阶段,不同阶段的AS-MLP区块数量不同。图1只显示了AS-MLP的小版本,其他变体将在第3.4节中讨论。上一步中的所有token都将经过这四个阶段,最终输出的特征将用于图像分类。在阶段1中,每个token采用线性嵌入和AS-MLP块。输出的维度为![]() ,其中C表示通道的数量。第2阶段首先对上一阶段输出的特征进行patch合并,将临近的2×2的patches分组得到一个大小为
,其中C表示通道的数量。第2阶段首先对上一阶段输出的特征进行patch合并,将临近的2×2的patches分组得到一个大小为![]() 的特征,然后采用线性层对特征大小转为为
的特征,然后采用线性层对特征大小转为为![]() ,然后是级联的AS-MLP块。阶段3和阶段4具有与阶段2相似的结构,层次表示将在这些阶段中生成。
,然后是级联的AS-MLP块。阶段3和阶段4具有与阶段2相似的结构,层次表示将在这些阶段中生成。
 图1:整体轴向移位MLP (AS-MLP)架构的一个小版本,最终输出用于图像分类。
图1:整体轴向移位MLP (AS-MLP)架构的一个小版本,最终输出用于图像分类。
3.2 AS-MLP Block
AS-MLP体系结构的核心操作是AS-MLP块,如图2(a)所示。它主要由Norm层、轴向移位操作、MLP和residual连接组成。在轴向移位操作中,我们利用通道投影、垂直移位和水平移位来提取特征,其中通道投影将特征映射为线性层。垂直位移和水平位移负责特征沿空间方向的平移。
如图2(b)所示,我们以水平位移为例。输入的维度为![]() ,为方便起见,我们在图中省略h并且假设C=3,w=5。当移位大小为3时,将输入特征分为三个部分,每个部分沿水平方向分别移位{-1,0,1}单元。在这个操作中,执行了零填充(用灰色块表示),我们也在第4节讨论了使用其他填充方法的实验结果。之后,虚线框中的特征将被取出,用于下一个通道投影。同样的操作也在垂直移动中进行。在水平位移和垂直位移的过程中,由于特征在两个方向上执行不同的位移单元,当特征重组(虚线框中的特征)时,可以将来自不同空间位置的信息组合在一起。在下一个通道投影操作中,来自不同空间位置的信息可以充分流动和交互。AS-MLP块的代码列在Alg.1中。
,为方便起见,我们在图中省略h并且假设C=3,w=5。当移位大小为3时,将输入特征分为三个部分,每个部分沿水平方向分别移位{-1,0,1}单元。在这个操作中,执行了零填充(用灰色块表示),我们也在第4节讨论了使用其他填充方法的实验结果。之后,虚线框中的特征将被取出,用于下一个通道投影。同样的操作也在垂直移动中进行。在水平位移和垂直位移的过程中,由于特征在两个方向上执行不同的位移单元,当特征重组(虚线框中的特征)时,可以将来自不同空间位置的信息组合在一起。在下一个通道投影操作中,来自不同空间位置的信息可以充分流动和交互。AS-MLP块的代码列在Alg.1中。
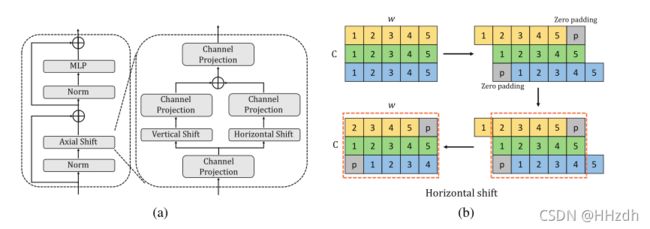 图2:(a)显示了AS-MLP块的结构;(b)表示水平位移,箭头表示步骤,每个框中的数字是特征的索引(最好用彩色显示)。
图2:(a)显示了AS-MLP块的结构;(b)表示水平位移,箭头表示步骤,每个框中的数字是特征的索引(最好用彩色显示)。
复杂性。在基于Transformer的体系结构中,通常采用多头自注意(MSA),计算token之间的注意。Swin Transformer (Liu et al.,2021b)引入了一个窗口对图像进行分割,并提出了窗口多头自注意(window multi-head self-attention, W-MSA),该窗口只考虑该窗口内的计算。它大大降低了计算复杂度。然而,在AS-MLP块中,没有窗口的概念,我们只轴向移动(AS)前一层的特性,不需要任何乘法和加法操作。此外,轴向移位的时间成本非常低,几乎与移位大小无关。给定一个维度为C×h×w的特征图(通常称为Transformer中的patch),图2(a)中的每个轴向移位操作只有四个通道投影操作,其计算复杂度为![]() 。如果Swin Transformer (Liu et al.,2021b) 中的窗口大小是M,则MSA、W-MSA和AS的复杂性如下:
。如果Swin Transformer (Liu et al.,2021b) 中的窗口大小是M,则MSA、W-MSA和AS的复杂性如下:
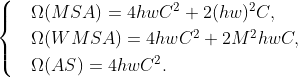
因此,AS-MLP体系结构的复杂性略低于Swin Transformer。各层的具体复杂度计算如附录A所示。
# Algorithm 1Code of AS-MLP Block in a PyTorch-like style.
#norm:normalizationlayer
#proj:channelprojection
#actn:activationlayer
import torch
import torch.nn.functional as F
def shift(x, dim):
x = F.pad(x, "constant", 0)
x = torch.chunk(x, shift_size, 1)
x = [ torch.roll(x_c, shift, dim) for x_s, shift in zip(x, range(-pad, pad+1))]
x = torch.cat(x, 1)
return x[:, :, pad:-pad, pad:-pad]
def as_mlp_block(x):
shortcut = x
x = norm(x)
x = actn(norm(proj(x)))
x_lr = actn(proj(shift(x, 3)))
x_td = actn(proj(shift(x, 2)))
x = x_lr + x_td
x = proj(norm(x))
return x + shortcut3.3 Comparisons Between AS-MLP,Convolution,Transformer and MLP-Mixer
在本节中,我们将AS-MLP与计算机视觉中使用的最近不同的架构进行比较。标准卷积,SwinTransformer和MLP-Mixer。虽然这些架构探索的角度完全不同,但从计算的角度来看,它们都是基于给定的输出定位点,其值取决于不同采样位置特征的加权和(乘加运算)。这些采样位置特性包括本地依赖(如卷积)和远程依赖(如MLP-Mixer)。图3显示了这些模块在采样位置上的主要差异。
卷积。给定一个特性图X,在X上执行一个形状为k×k的滑动内核,以获得输出![]() :
:
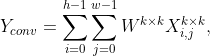
其中W为可学习权值。h和w分别表示x的高度和宽度。如图3所示,卷积运算具有局部接受域,因此更适合于提取具有局部依赖性的特征。
Swin Transformer。Swin Transformer为基于Transformer的架构引入了一个窗口,以覆盖局部关注。来自窗口的输入X被内嵌成Q, K, V矩阵,而在窗口内注意特征组合输出![]() :
:
![]()
局部性的引入进一步提高了基于Transformer的体系结构的性能,降低了计算复杂度。
MLP-Mixer。MLP-Mixer放弃了注意操作。首先对输入X进行转置,然后附加一个token-mixing MLP,得到输出![]() :
:
![]()
其中![]() 为token-mixing MLP中的可学习权值。MLP-Mixer仅通过矩阵换位和MLP来感知全局信息。
为token-mixing MLP中的可学习权值。MLP-Mixer仅通过矩阵换位和MLP来感知全局信息。
AS-MLP。AS-MLP轴向移动特征图如图2(b)所示。在给定输入x和位移大小的情况下,首先将X在水平和垂直方向上分为两部分,分别表示为![]() 和
和![]() 。图2(b)轴向位移后,输出为
。图2(b)轴向位移后,输出为![]() :
:
![]()
其中![]() 和
和![]() 为信道在水平和垂直方向上投影的可学习权值,
为信道在水平和垂直方向上投影的可学习权值,![]() 和
和![]() 表示轴向位移。与MLP-Mixer不同,我们更关注通过特征轴向移动和通道投影的局部依赖性。
表示轴向位移。与MLP-Mixer不同,我们更关注通过特征轴向移动和通道投影的局部依赖性。
 图3:卷积、Swin Transformer、MLP-Mixer和ASMLP的不同采样位置。AS-MLP (s = 3, d = 1)表示位移大小为3,膨胀为1时的采样位置。
图3:卷积、Swin Transformer、MLP-Mixer和ASMLP的不同采样位置。AS-MLP (s = 3, d = 1)表示位移大小为3,膨胀为1时的采样位置。
3.4 Variants of AS-MLP Architecture
图1只显示了我们的AS-MLP体系结构的小版本。根据DeiT (Touvron et al ., 2020)和Swin Transformer(Liu et al ., 2021 b),我们也堆栈不同数量的AS-MLP块(四个阶段)块的数量,扩大渠道维度(图1中的C)获得变异AS-MLP架构不同的模型的大小,这是AS-MLP-Tiny (ASMLP-T),AS-MLP-Small (AS-MLP-S)和AS-MLP-Base (AS-MLP-B)。具体配置如下:
- AS-MLP-T:C= 96, the number of blocks in four stages ={2, 2, 6, 2};
- AS-MLP-S:C= 96, the number of blocks in four stages ={2, 2, 18, 2};
- AS-MLP-B:C= 128, the number of blocks in four stages ={2, 2, 18, 2}.
实验部分的表1显示了AS-MLP不同变体体系结构的Top-1精度、模型大小(Params)、计算复杂度(FLOPs)和吞吐量。
4 Experiments
5 Conclusion and Future Work
在本文中,我们提出了一个轴向转移的MLP体系结构,命名为AS-MLP。与MLP-Mixer相比,我们更注重局部特征提取,通过简单的特征轴向移动,充分利用不同空间位置之间的通道相互作用。通过提出的AS-MLP,我们进一步提高了基于MLP的体系结构的性能,实验结果令人印象深刻。我们的模型在ImageNet-1K数据集上使用88M参数和15.2 GFLOPs获得了83.3% Top-1精度。这种简单而有效的方法优于所有基于MLP的体系结构,并实现了与基于Transformer的体系结构相比具有竞争力的性能,即使具有略低的FLOPs。我们也是第一个将AS-MLP应用到下游任务(例如,对象检测和语义分割)的工作。与基于变压器的体系结构相比,结果也具有竞争力,甚至更好,这显示了基于MLP的体系结构处理下游任务的能力。
在未来的工作中,我们将研究AS-MLP在自然语言处理中的有效性,并进一步探讨AS-MLP在下游任务中的性能。