干货分享 | spdk技术简介和一些实践经验

01
导读
与机械硬盘相比,NVMe-ssd在性能、功耗和密度上都有巨大的优势,并且随着固态存储介质的高速发展,其价格也在大幅下降,这些优势使得NVMe-ssd在分布式存储中使用越来越广泛。由于NVMe-ssd的性能比传统磁盘介质高出很多,使得在整个IO处理过程中,软件部分占用的时间比例大大提升,成为制约存储系统性能的主要因素。为了充分发挥后端NVMe-ssd的性能,intel开发出了存储性能开发工具包-SPDK(Storage Performance Development Kit),和RDMA一样,SPDK也采用了kernel bypass的思想,它提供了一整套工具和库,以实现高性能、全用户态、扩展性强的存储应用程序,旨在大幅缩减存储I/O栈的软件开销,将固态存储介质的性能发挥到极致。
本文先对SPDK 技术进行介绍,更好的了解其实现原理,深入理解其带来性能大幅提升的原因,然后给大家分享下中国移动云能力中心块存储团队将SPDK应用到分布式块存储软件BC-EBS上做的一些工作和使用经验。
02
SPDK技术简介
1、SPDK的整体架构

图1 / SPDK的架构(图片源自网络)
https://new.qq.com/omn/20190712/20190712A03GFB00.html
SPDK架构整体分为三层:
存储协议层:SPDK支持的存储应用类型。NVMe-oF target实现了NVMe-oF规范,对外提供基于NVMe协议的存储服务端,支持RDMA和TCP网络;iSCSI Target对外提供基于SCSI协议的存储服务端;vhost-scsi或vhost-blk对qemu提供后端存储服务,qemu可以基于SPDK提供的后端存储为虚拟机挂载virtio-scsi或virtio-blk磁盘。
存储服务层:SPDK bdev相当于内核通用块层,为不同后端设备(NVMe、AIO、RBD、VIRTIO 、ISCSI等)驱动提供通用的API接口。SPDK还在通用块层实现了QoS、磁盘阵列、逻辑卷管理等功能。
驱动层:为不同的后端存储设备提供驱动。图中把驱动细分成两层,和块设备强相关的放到了存储服务层,而把和硬件强相关部分放到了驱动层。
2、SPDK的工作机制
为了更好理解SPDK能实现高性能的原因,我们以下图中的场景为例,分析SPDK工作过程,详解工作过程中用到的关键技术。

图2 / SPDK的工作机制
在图中,一台服务器上插了一张NVMe-ssd卡,划分两个namespace(对操作系统而言,每个namespace相当于一块独立的盘),分别分配给两个虚机使用,采用的vhost-blk方式。根据vhost-user协议,qemu不再进行I/O的转发,只进行控制面的管理工作,如feature的协商、virtqueue初始化等,虚机的前端驱动和宿主机存储后端vhost通过共享内存来进行数据交互,具体的交互过程是基于virtio vring 环来实现的。
假如vm1要下发数据时,虚机将数据的内存地址(guest physical address,简称PGA)放在vring环上,vhost的reactor线程通过poller机制不断的轮询vring环,发现有新添数据时,根据qemu记录的PGA到宿主机虚拟地址(vhosthost virtual address,简称VVA)内存映射关系,使用rte_vhost_va_from_guest_pa函数将GPA转换为VVA供vhost处理。
vhost拿到数据后,经过SPDK bdev层的处理(如io拆分合并、对齐等),根据注册的设备驱动,找到具体的NVMe-ssd设备。为了防止多个thead操作同一个设备引起的资源竞争,SPDK提供了I/O channel的概念,每一个thead拥有不同的I/O channel,在NVMe 中,一个I/O channel就对应NVMe的一个队列(queue pair),这样数据最终就交由NVMe的队列来处理。在创建vhost-blk设备时,会选择reactor的一个线程进行绑定,这样,整个I/O处理过程都在同一个线程中完成。
SPDK能实现高性能,主要得益于以下几种技术:
(1)全用户态:把驱动移到用户态,避免了系统调用的开销,且真正实现了内存零拷贝。
在传统的存储I/O栈中,应用程序和磁盘驱动分别处于用户态和内核态,应用程序为了和磁盘进行交互,需要进行多次的系统调用,并且数据需要在用户空间和内核空间之间拷贝,这两个动作都增加了系统开销,当后端是高速设备时,这部分开销就表现的很突出。
而在SPDK中,将驱动程序移到用户态,在执行调用时避免了用户态和内核态来回切换,将节省大量的处理器时间开销,从而有更多的时钟周期来进行真正的存储工作。虚拟机的前端驱动和宿主机存储后端vhost通过共享内存传递数据,避免了大量的内存拷贝。I/O在宿主机上绕过了内核,路径更短。
(2)SPDK独立的线程模型:一个core只拥有一个thread,该thread上可以执行很多poller(轮询函数),满足run-to-completion(一个线程最好执行完所有的任务)的需求。
vhost进程启动时,可以配置多个轮询线程(SPDK称reactor),每个线程绑定一个core。在创建一个vhost-blk设备时,也需要为该设备绑定一个core,绑定的core和前面reactor的core一致。在每个线程上,SPDK提供了poller的机制,来处理具体的事务。SPDK提供的poller分两种:基于定时器的poller和非定时器的poller。在reactor的while(1)循环中,它会不停的check这些poller的状态,进行相应的调用,同时I/O也会得到相应的处理。由于单个core上只有一个reactor thread,所以同一个reactor thread 中不需要一些锁的机制来保护资源。
(3)线程间的通信方式:Event事件机制,一种轻量型的线程交互方式。
在传统存储模型中,多个线程操作同一个资源,往往是通过锁机制来实现的。为了使同一个thread只执行自己所管理的资源,SPDK提供了Event (事件调用) 机制。该机制的本质是每个reactor对应的数据结构 (struct SPDK_reactor) 维护了一个Event事件的ring (环)。这个环是多生产者和单消费者模型,即每个Reactor thread可以接收来自任何其他Reactor thread 的事件消息进行处理。当然,Event ring处理的同时也在执行reactor的SPDK_poller轮询函数。
每个Event事件的数据结构 (struct SPDK_event) 包括了需要执行的函数、相应的参数以及要执行的core。例如,Reactor A 向Reactor B通信,其实就是需要Reactor B代替Reator A执行函数F(X),这样他们只执行自己管理的资源,更加的高效 。
(4)数据路径的无锁化机制:在I/O路径上采用io_channel技术,避免采用锁机制,能降低时延和提升性能。
对于类似NVMe的多队列设备,SPDK提供一个I/O channel的概念 (即thread和device的一个mapping关系),封装在SPDK_vhost_blk_session结构中。不同的thread 操作同一个device应该拥有不同的I/O channel,每个I/O channel在I/O路径上使用自己独立的资源就可以避免资源竞争,从而去除锁的机制。如上图,后端是NVMe-ssd设备时,一个I/O channel对应NVMe的一个queue pair。
03
目前块存储团队在SPDK上的一些工作
学习更多dpdk视频
DPDK 学习资料、教学视频和学习路线图 :https://space.bilibili.com/1600631218
Dpdk/网络协议栈/ vpp /OvS/DDos/NFV/虚拟化/高性能专家 上课地址: https://ke.qq.com/course/5066203?flowToken=1043799
DPDK开发学习资料、教学视频和学习路线图分享有需要的可以自行添加学习交流q 群909332607备注(XMG) 获取
1、ceph场景下使用SPDK遇到的性能问题
在虚拟化qemu+SPDK+librbd使用场景下,SPDK采用 vhost-blk或vhost-scsi协议,在虚机中,我们发现性能很差,不能充分发挥出后端ceph集群性能。通过排查发现,该问题的原因是当前SPDK的架构是为了发挥NVMe类设备的性能而设计的,其特点是SPDK下发的I/O会直接到达硬件,I/O的收割也是SPDK直接轮询硬件,而ceph场景下需要有额外的ceph线程介入来下发收割I/O。当前SPDK线程与ceph线程跑在同一个CPU上,造成了资源竞争,导致IO性能下降。解决方法是将这些ceph线程移到在非SPDK使用的CPU上。经过优化后,性能大幅提升,最大提升了16倍,均接近后端集群的性能。
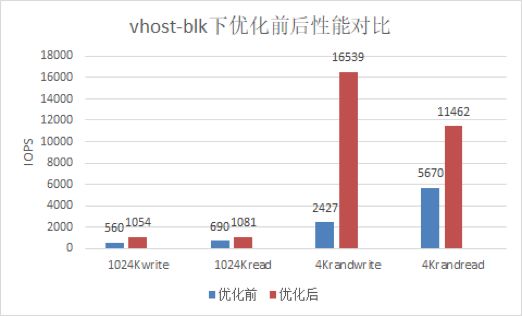
图3 / 优化前后vhost-blk设备性能对比

图4 / 优化前后vhost-blk设备时延对比
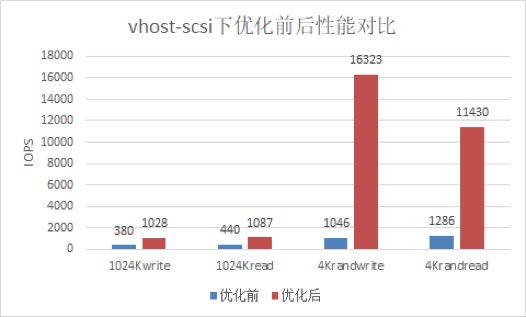
图5 / 优化前后vhost-scsi设备性能对比
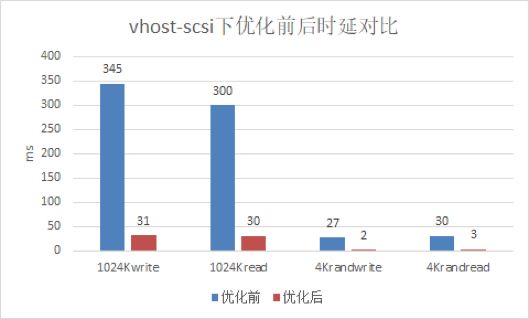
图6 / 优化前后vhost-blk设备性能对比
2、SPDK和ceph线程最优绑核方案探索
SPDK能有优异的性能,离不开它优异的线程模型,实际使用过程中核的分配相当重要,从上面可以看出,在后端是ceph的场景下,ceph线程运行的核如果没有规划,性能也可能会很差。在虚机场景下,qemu节点核资源更是有限,使得我们不得不考虑,在qemu+SPDK_vhost_iscsi+librbd方案下, 怎样将qemu节点有限的核资源分配给SPDK reactor和ceph线程, 才能达到最优的性能。下面我们就单SPDK线程、ceph卷占用的CPU核数不同时,对性能的影响,及在后端是ceph场景下,单reactor可发挥的最大性能进行了测试和分析。
(1)测试环境:
测试环境共4台服务器,SPDK和qemu共用一台机器,SPDK采用的vhost-scsi方式。

(2)单SPDK线程,ceph卷占用的CPU核数不同时,对性能的影响:
a、1个ceph卷的场景下,ceph卷绑不同数目的核时能发挥出的性能。其中横坐标表示ceph卷的绑核情况,纵坐标表示ceph卷能发挥的iops性能,单位为K。

图7 / 1个image下ceph线程绑核对性能的影响
b、2个ceph卷的场景下,ceph卷绑不同数目的核时能发挥出的性能。其中横坐标表示2个ceph卷的绑核情况,纵坐标表示2个ceph卷能发挥的总共iops性能,单位为K。

图8 / 2个image下ceph线程绑核对性能的影响
c、3个ceph卷的场景下,ceph卷绑不同数目的核时能发挥出的性能。其中横坐标表示3个ceph卷的绑核情况,纵坐标表示3个ceph卷能发挥的总共iops性能,单位为K。
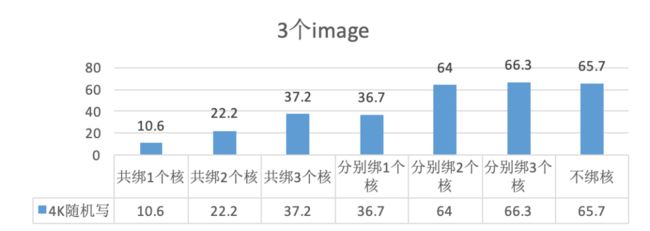
图9 / 3个image下ceph线程绑核对性能的影响
(3)在后端是ceph场景下,单个reactor可发挥的最大性能(ceph集群随机写性能在140K iops左右):
a、每个卷绑定两个core,增加ceph卷的个数,单reactor下可发挥的最大性能。
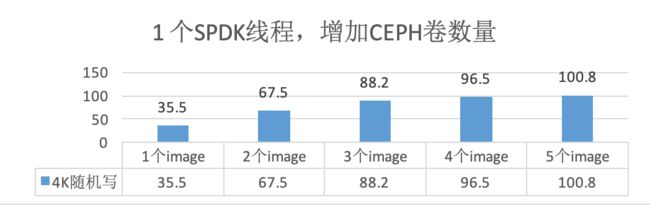
图10 / 增加卷数,单reactor可发挥的最大性能
b、在上一步的基础上,5个卷时,增加每个卷绑核的数量,对性能的影响。
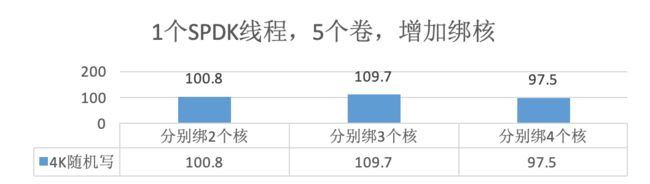
图11 / 单个reactor,5个卷,增加绑核可发挥的性能
c、增加reactor个数,和单reactor下的性能进行比较。

图12 / 2个reactor,5个卷,增加绑核可发挥的性能
(4)测试结果分析
a、从图7、8、9 可以看出,单reactor下,增加卷的绑核数,性能发挥出的越好。
b、从图10可以看出,单reactor下,每个卷绑两个核,增加卷的个数,性能发挥的越好,但随着卷的个数增加,性能趋于稳定。
c、由a得出的结论,增加卷的绑核数可以增加性能,在未达到集群最大性能的情况下,尝试5个卷时,增加绑核数,但性能并未增加,说明此场景下,单reactor的性能可能到了瓶颈。
d、为了进一步验证c中单个reactor是否到了性能瓶颈,增加reactor个数后,5个卷,相同的绑核数,可以看出性能发挥的更好,更接近集群最大性能。说明在后端为ceph集群,vhost_scsi+librbd的使用场景下,单reactor可发挥的最大性能在100K左右。
04
结尾
SPDK凭借其优秀的架构和性能获得各个存储厂家的青睐,但目前社区还不太成熟,在和各自的产品融合时,用户态的工作模式与传统内核态I/O模型有较大差异,可参考的使用经验不多,往往会遇到各种各样的问题。中国移动块存储团队目前也在积极的将SPDK引入到我们的块存储产品中,进行性能的优化提升,后续会将更多的使用和优化经验分享给大家,与大家一起进步。