Elasticsearch,head插件,kibana以及ik分词器的安装与简单使用
Elasticsearch
- 是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;
- 使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的Restful API来隐藏Lucence的复杂性,从而让全文搜索变得简单。
SQL:like %查询内容%,如果是大数据,就算有索引也十分慢
1.安装
- 开发工具:Postman、Curl、head、Google浏览器插件
(安装包可以自行下载,找不到可留言领取安装软件)
1、安装ElasticSearch
https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
下载解压即可
bin:启动文件
config:配置文件
log4j2:日志配置文件
jvm.options java虚拟机相关配置
elesticsearch.yml 配置文件!默认9200端口
plugins:插件
启动:点击bin/elasticsearch.bat,然后再浏览器访问http://127.0.0.1:9200/,出现以下
{
"name" : "DESKTOP-0U1AJ4S",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "AzTUTxy6Sbq1-j-jU1A2rw",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2、安装可视化界面(head插件)
下载地址:https://github.com/mobz/elasticsearch-head/ (需要先安装npm)
- 解压后,在该目录下打开cmd,
#使用cnpm安装依赖
cnpm install
或者npm install
#启动
npm run start
- 解决跨域问题
#打开C:\tools\ES\elasticsearch-7.2.0\config\elasticsearch.yml,在最后追加
http.cors.enabled: true
http.cors.allow-origin: "*"
#保存,重启ES服务,访问http://localhost:9100/
点击连接,显示:集群健康值: green (0 of 0)
- 也可以使用Google插件
3、安装Kibana
版本要一致https://mirrors.huaweicloud.com/kibana/7.2.0/?C=N&O=D
-
解压后打开bin/kibana.bat,访问 http://localhost:5601
-
汉化
C:\tools\ES\kibana-7.2.0-windows-x86_64\config\kibana.yml中追加
i18n.locale: "zh-CN"
4、安装ik分词器
与ES版本一致https://github.com/medcl/elasticsearch-analysis-ik/tree/v7.2.0
- 解压:如果IK与ES版本不对应,运行ES时会报错说两者版本不对,导致无法启动。下载了IK分词器表面是7.2.0版本的,得到的处理过后的zip解压开是7.0.0版本的,只需要修改路径下的pom.xml里面的版本改成7.2.0即可。
- 在此目录下打开dos窗口,执行命令mvn clean package进行打包。然后进入\target\releases下看到zip包
- 在你安装es的所在目录下的的plugins下创建analysis-ik文件夹, 然后将上面打的zip包拷贝到analysis-ik文件夹下并将zip压缩包解压到此
- 然后重新启动ES,可以看到ik分词器安装成功
2.ES核心概念
- elasticsearch是面向文档,其和关系型数据库对比:(一切都是JSON)
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) (就和数据库一样) |
| 表(tables) | types (逐渐会被弃用) |
| 行(rows) | documents (文档) |
| 字段(columns) | fields |
- 索引
索引是映射类型的容器,es中的索引是一个非常大的集合。索引存储了映射类型的字段和其他设置,然后它们被存储到各个分片上
- 一个集群至少有一个节点,而一个节点就是一个es进程,节点可以有多个默认索引,如果创建索引,那么索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片都会有一个副本(replica shard,又称复制分片
- 主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
- 实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得ES在不扫描全部文档的情况下,就能告诉我们哪些文档包含特定的关键字
- 倒排索引
- ES使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层,这种结构适用于快速的全文搜索。
- 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表
如通过博客标签来搜索博客文章,那么倒排索引就是这样一个结构
| 博客文章(原始数据) | 索引列表(倒排索引) | ||
|---|---|---|---|
| 博客文章ID | 标签 | 标签 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
如果要搜索含有puthon标签的文章,那相对于查找所有的原始数据而言,查找倒排索引后的数据会快得多,只需要查看标签这一栏,然后获取相关的文章ID即可,完全过滤掉无关的所有数据,提高效率
倒排索引级文档分词成关键字与文档id之间的映射
3.IK分词器
分词:即把一段中文或者别的划分成一个个关键字,我么在搜素时会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每一个分词看成一个词,比如"好好学习"会被分为"好",“好”,“学”,“习”,这显然是不符合要求得,所以我们需要安装中文分词器IK来解决问题。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
使用kibana测试,查看不同的分词效果
ik_smart

ik_max_word

自己需要的词,需要手动加入到分词器的字典中
IK分词器增加自己的配置
- 添加my.dic配置
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">my.dicentry>
<entry key="ext_stopwords">entry>
properties>
- 在当前目录下创建my.dic文件,里面写入自己加入的词
- 然后重启ES
4.Rest风格说明
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/文档id/_search | 查询所有数据 |
基本测试
1、索引操作
- 1、创建索引
#在kibana中创建命令并执行
PUT /索引名/类型名/id
{请求体}
#执行后可在head插件中查看到创建的索引
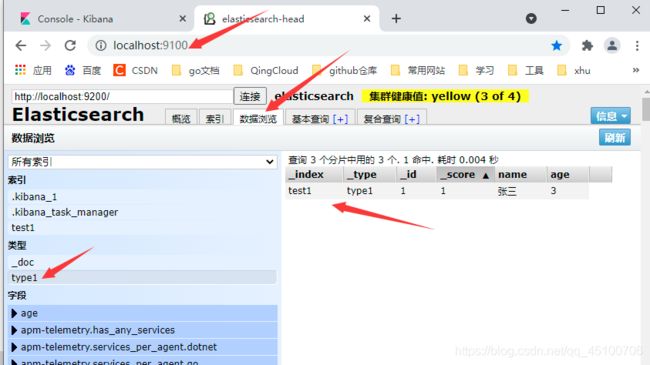
-
2、类型
- 字符串:text、keyword
- 数值:long、integer、short、byte、double、float、half float、scaled float、
- 日期:date
- 布尔值:boolean
- 二进制:binary
- …
-
指定类型(创建规则)
#创建索引但没有创建字段,创建规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
#获取,可以查看具体的信息
GET test2
- 查看默认的信息
#_doc默认类型,具体类型在未来将会被弃用
PUT /test3/_doc/1
{
"name": "李四",
"age": 3,
"birth": "1993-2-11"
}
GET test3
#如果自己的文档没有指定,那么es就会给我们默认配置字段类型
#扩展:通过命令elasticsearch索引情况
GET _cat/health
- 3、修改
1、还是使用PUT即可,然后执行覆盖(但是如果数据丢失,覆盖后会只有覆盖的数据)
2、使用POST
- 4、删除索引
#通过DELETE命令实现删除,根据请求判断是删除索引还是删除文档记录
DELETE test1
2、文档操作
基本操作
#1、添加记录
POST /test3/user/2
{
"name": "李四",
"age": 24,
"birth": "1993-2-11",
"tags": ["直男","成绩好"]
}
#2、获取,简单搜索(通过id)
GET /test3/user/1
#通过search
GET test3/user/_search?q=name:张三
#3、修改(推荐使用update的形式)
PUT /test3/user/3
{
"name": "anan",
"age": 23,
"birth": "1999-2-11",
"tags": ["美丽","成绩好"]
}
POST /test3/user/3/_update
{
"doc": {
"name": "anan123"
}
}
注意:

3、查询详解
复杂查询搜索
#1、默认查询所有
GET test3/user/_search
{
"query": {
"match": {
"name": "李四"
}
}
}
#多个条件之间用空格隔开,只要满足其中一个就可以查出,这个时候可以通过score进行基本判断
GET test3/user/_search
{
"query": {
"match": {
"tags":"男 美丽"
}
}
}
#查询到的hit表示索引和文档的信息,查询的结果总数,然后就是查询出来的具体的文档,数据中的数据都可以遍历出来了
#2、结果过滤,只查询name,age
GET test3/user/_search
{
"query": {
"match": {
"name": "李四"
}
}
, "_source": ["name","age"]
}
#3、排序
#如按照年龄倒排并分页
GET test3/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
#一般分页实现为/search/{current}/{pagesize}

#4、多条件查询
#must相当于and,should相当于or
GET test3/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
},
{
"match": {
"age": 24
}
}
]
}
}
}
#5、not 查询name不是李四的人
GET test3/user/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"name": "李四"
}
}
]
}
}
}
#6、过滤器filter
gt大于 gte大于等于 lt小于 lte小于等于
#将查询结果按照年龄最大30,最小20的进行过滤
GET test3/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "李四"
}
}
],
"filter": {
"range": {
"age": {
"gte": 20,
"lte": 30
}
}
}
}
}
}
精确查询!
关于分词
关于分词*
- term,直接通过倒排索引指定的词条进程精确查找
- match,会使用分词器解析(先分析文档,然后在通过分析的文档进行查询)
两个类型:text keyword
#1、创建索引
PUT testdb
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
#2、put数据
PUT testdb/_doc/2
{
"name": "张三学习英语 name",
"desc": "张三学习英语 desc2"
}
#3、text没有被分词器解析,keyword表示一个整体
GET _analyze
{
"analyzer": "keyword",
"text": "张三学习英语name"
}
#将会被拆分
GET _analyze
{
"analyzer": "standard",
"text": "张三学习英语name"
}
#4、精确查询
#keyword类型的字段不会被分词器解析
GET testdb/_search
{
"query": {
"term": {
"name": "三"
}
}
}
GET testdb/_search
{
"query": {
"term": {
"desc": "张三学习英语 desc1"
}
}
}
#5、精确查询多个值
PUT testdb/_doc/3
{
"test1": "22",
"test2": "2021-5-19"
}
PUT testdb/_doc/4
{
"test1": "33",
"test2": "2021-5-20"
}
GET testdb/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"test1": "22"
}
},
{
"term": {
"test1": "33"
}
}
]
}
}
}
高亮查询
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1BpmTter-1625021445261)(C:\Go\笔记\images\1621404848937.png)]
#采用自定义高亮条件
GET test3/user/_search
{
"query": {
"match": {
"name": "李四"
}
},
"highlight": {
"pre_tags": ""
,
"post_tags": "",
"fields": {
"name": {}
}
}
}