【MySQL】MySQL索引优化——从原理分析到实践对比
目录
使用TRACE分析MySQL优化
开启TRACE
TRACE 结果集
ORDER BY & GROUP BY 优化
优化方式
分页优化
不同场景的优化方式
JOIN关联优化
算法介绍
优化方式
COUNT优化
优化方式
使用TRACE分析MySQL优化
某些情况下,MySQL是否走索引是不确定的=[,,_,,]:3,那、我就想确定。。。咋办?
首先,在FROM 表名后加上FORCE INDEX(索引名称)可以强制MySQL走索引
举个
SELECT name FROM app_user FORCE INDEX(index_age) WHERE age > 9;当然本着尊重以及信赖MySQL的原则,还是不要强迫他(˶‾᷄ ⁻̫ ‾᷅˵)。。毕竟MySQL有自己的一套很靠谱的优化方式,针一条SQL语句,我们可以通过TRACE来查看他的优化结果
开启TRACE
使用下面的语句开启TRACE(开启会影响性能,因此默认关闭,只会在做分析的时候开启)
set session optimizer_trace="enabled=on",end_markers_in_json=on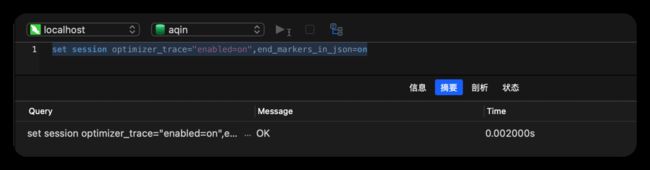
在执行语句下面加一行,举个
SELECT name FROM app_user WHERE age > 9;
SELECT * FROM information_schema.OPTIMIZER_TRACE;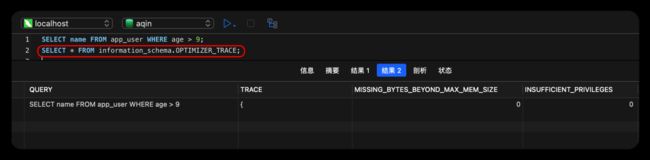
TRACE 结果集
如下是一个trace结果集的示例(完整版太长,部分省略)
{
"steps": [
{
"join_preparation": {
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `app_user`.`name` AS `name` from `app_user` where (`app_user`.`age` > 9)"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": {
"select#": 1,
"steps": [
{……},
{
"substitute_generated_columns": {} /* substitute_generated_columns */
},
{
"table_dependencies": [……] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [
{
"table": "`app_user`",
"range_analysis": {
"table_scan": {
"rows": 992599,
"cost": 102998
} /* table_scan */,
"potential_range_indexes": [
{
"index": "PRIMARY",
"usable": false,
"cause": "not_applicable"
},
{
"index": "id_app_user_name",
"usable": false,
"cause": "not_applicable"
},
{
"index": "index_age",
"usable": true,
"key_parts": [
"age",
"id"
] /* key_parts */
}
] /* potential_range_indexes */,
"setup_range_conditions": [
] /* setup_range_conditions */,
"group_index_range": {
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"skip_scan_range": {
"potential_skip_scan_indexes": [
{
"index": "index_age",
"usable": false,
"cause": "query_references_nonkey_column"
}
] /* potential_skip_scan_indexes */
} /* skip_scan_range */,
"analyzing_range_alternatives": {
"range_scan_alternatives": [……]
/* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"usable": false,
"cause": "too_few_roworder_scans"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */
} /* range_analysis */
}
] /* rows_estimation */
},
{
"considered_execution_plans": [
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`app_user`",
"best_access_path": {
"considered_access_paths": [
{
"rows_to_scan": 992599,
"access_type": "scan",
"resulting_rows": 992599,
"cost": 102996,
"chosen": true
}
] /* considered_access_paths */
} /* best_access_path */,
"condition_filtering_pct": 100,
"rows_for_plan": 992599,
"cost_for_plan": 102996,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": {……} /* attaching_conditions_to_tables */
},
{
"finalizing_table_conditions": [……] /* finalizing_table_conditions */
},
{
"refine_plan": [
{
"table": "`app_user`"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */
},
{
"join_execution": {
"select#": 1,
"steps": [
] /* steps */
} /* join_execution */
}
] /* steps */
}主要字段含义
-
"steps":步骤
-
"join_preparation"
- 第一阶段:准备阶段,会进行SQL格式化
-
"join_optimization"
- 第二阶段:优化阶段
-
"condition_processing" 条件处理
- 联合索引的顺序优化就是在这一步
- "table_dependencies" 表依赖详情
-
"rows_estimation" 预估表的访问成本(选择依据)
-
"table_scan" 全表扫描情况
- "rows" 扫描行数
-
"cost" 查询成本
- 主要依据,除了扫描行数还会考虑回表等别的消耗,无单位,MySQL一般会选小的)
-
"potential_range_indexes" 查询可能使用到的索引
-
"index"
- "PRIMARY" 主键索引
- 其他的表示辅助索引
-
-
"analyzing_range_alternatives" 分析各个索引的成本
- "rowid_ordered" 使用该索引获取的记录是否按照主键排序
- "index_only" 是否使用覆盖索引
- "rows" 扫描行数
- "cost" 索引使用成本
- "chosen" 是否确认选择该索引
-
-
"considered_execution_plans"
-
"best_access_path" 最优访问路径
-
"considered_access_paths" 最终选择的访问路径
- "rows_to_scan" 扫描行数
- "access_type" 访问类型
-
"range_details"
- "used_index" 使用索引
- "resulting_rows" 扫描行数
- "cost" 查询成本
- "chosen" 确定选择
-
-
-
ORDER BY & GROUP BY 优化
Extra中的值表示了ORDER BY是否走索引,Extra中的值是Using index condition表示ORDER BY走索引,Extra中的值是Using filesort表示ORDER BY未走索引;ORDER by默认升序,如果ORDER by使用降序(与索引的排序方式不同),于是会产生Using filesort(MySQL8.0以上的版本有降序索引可以支持这种查询优化)
GROUP BY和ORDER by很类似,其实质是先排序后分组
Using filesort 原理
排序方式
-
单路排序:一次性取出满足条件的所有字段,然后在sort buffer中进行排序
-
双路排序(回表排序模式):首先根据相应的条件取出相应字段的排序字段和ID,然后在sort buffer中进行排序,排序完需要再次取回其他需要的字段
如果使用了Using filesort,那么使用上面介绍的TRACE工具就会有相应的信息,即sort_mode信息
如果是单路排序sort_mode字段的信息为sort_mode字段的信息为
那么,如何MySQL是如何判断是否使用了Using filesort的?
自问自答:通过比较系统变量max_length_for_sort_data(默认1024字节)的大小来判断使用哪种排序
-
字段总长度小于
max_length_for_sort_data,使用单路 -
字段总长度大于
max_length_for_sort_data,使用双路
优化方式
- MySQL支持两种方式的排序:filesort(效率低)和index(效率高),
Using index是指MySQL扫描索引本身就能完成排序 -
ORDER by满足两种情况会使用Using indexORDER by使用索引最左前列- 使用
WHERE子句和ORDER by子句条件列组合满足索引最左前列
- 尽量在索引列上完成排序,遵循索引建立(索引创建的顺序)时的最左前缀法则,如果
ORDER by的条件不在索引列上,就会产生Using filesort - 尽量使用覆盖索引
- 遵循索引创建的最左前缀法则,对于
GROUP BY的优化如果不需要排序的可以加上ORDER by null禁止排序,注意WHERE高于HAVING,能写在WHERE中就不要使用HAVING
分页优化
由于limit的查询方式,因此使用limit进行分页效率并不高
我们举个:limit 1000,10
实际执行的时候,会从头开始查询到1010条数据,然后再舍弃掉前1000条。。。没错就手笔是这么阔(˶‾᷄ ⁻̫ ‾᷅˵)
既然limit效率不高,那么如何进行优化呢?
不同场景的优化方式
-
自增且连续的主键(要求数据中间无缺失)
WHERE id LIMIT 1000,10可以优化为WHERE id>1000 LIMIT 10
-
不一定连续且非按主键进行排序
举个
优化前
select * from app_user ORDER BY name limit 100000,5;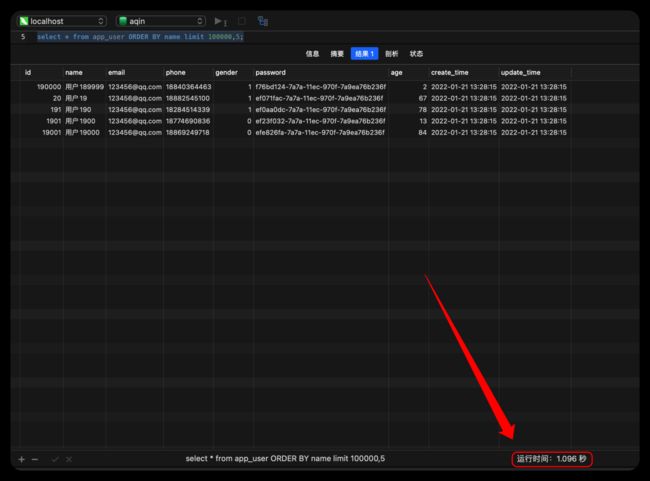
优化后
select * from app_user a inner join (select id from app_user order by name limit 100000,5) b on a.id = b.id;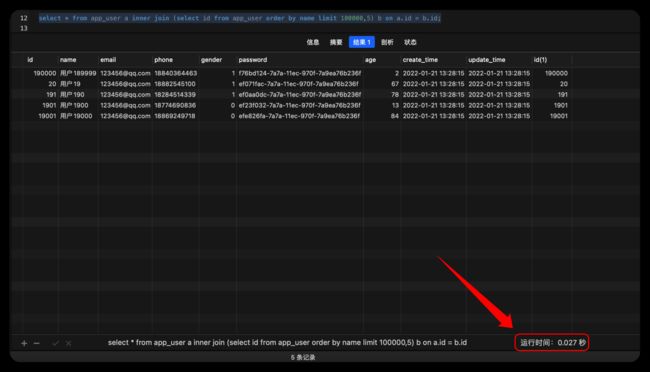
分别使用Explain分析下

优化前,也用到了索引,但是是使用了range进行范围扫描
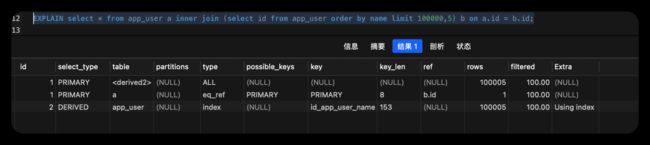
优化后, 有三行数据,第一行看着虽然走的是全局扫描,但是他是由第三行派生出的,即只有一“页”(本案例中只有5行数据),第二行可以看出使用的是主键进行关联索引,type是eq_ref比ref的速度还快,第三行虽然是遍历索引,但是没有进行回表,而且只查询五个值即可,因而优化后速度快很多
JOIN关联优化
先介绍下驱动表和被驱动表的概念( ̄∇ ̄)/
简单理解先执行的就是驱动表,不同的join类型MySQL选择的驱动表不同
inner join不确定,MySQL会自行判断(一般选数据量小的表做驱动表)left join左边的是驱动表right join右边的是驱动表
算法介绍
-
嵌套循环连接算法 Nested-Loop Join(NLJ)
使用索引字段进行关联的关联查询一般会使用NLJ
简单理解就是拿一张表(驱动表)中的所有数据,一次一次的去另一张表(被驱动表)中查找对应行,最后取出两张表的结果合集
EXPLAIN select * from app_user a inner join app_user_copy1 b on a.id = b.id;
上面SQL执行的大致流程如下:
- 把b表中读取一行数据(b表有过滤条件会从过滤后的结果中读取)
- 取出关联字段(id)去a表中查找较
- 取出a表中满足条件的行,和b表中获取到的结果合并,返回
- 重复上面3个步骤
-
基于块的嵌套循环连接算法 Block Nested Loop Join(BNL)
使用非索引字段进行关联的关联查询一般会使用BNL
EXPLAIN select * from app_user a inner join app_user_copy1 b on a.age = b.age;
Extra中Using join buffer (hash join)表示使用BNL,可以看到两张表进行的都是全表扫描
上面SQL执行的大致流程如下:
- 把b表中的所有数据放入到join_buffer中(join_buffer是内存中的一块区域,默认大小256k,放不下就分段放)
- 把a表中的每一行数据取出来,跟join_buffer中的全部数据做比较
- 返回满足join条件的数据
为什么MySQL会根据关联字段是否有索引而使用不同的算法
首先,我们大致量化下两个算法总消耗
NLJ总消耗(有索引)
- 磁盘扫描:a表行数 * 2(会先扫描索引之后直接扫描符合条件的数据行)
- 内存判断:a表行数 * b索引
BNL总消耗(无索引)
- 磁盘扫描:a表行数 + b表行数
- 内存判断:a表行数 * b表行数(由于join_buffer中的数据是无序的,因此判断次数=a表行数 * b表行数)
如果在没索引的情况下使用NLJ,会导致磁盘扫描=a表行数 * b表行数,由于内存判断要比磁盘扫描快的多,因此在没索引的情况下,MySQL一般会选择BNL,而有索引则选择NLJ
优化方式
- 关联字段加索引
-
减少不必要的字段查询
-
加大join_buffer_size的大小(一次缓存的越多,内层扫描的次数就越少)
-
小表驱动大表(Explain结果集中小表在上)
- 可使用
straight join设置左表驱动右表,不过只适用于inner join - 尽量让MySQL的优化器自行判断(MySQL的优化器还是很稳的)
-
关于
in和exsits:-
当后半部分筛选出的结果集小于前面半部分,一般用
inin可以理解为以后面部分的结果集的大小作为外层循环的遍历次数,做个简单的代换就是a IN b就相当于for(b.size){a},因此in会先执行b部分,b部分越小,也就相当于for循环次数越少
-
当后半部分筛选出的结果集大于前面半部分,一般用
exsitsexsits会先执行exsits前面的部分,做个简单的代换就是a EXSITS b就相当于for(a.size){b},即a部分越小,for循环次数越少
-
- 可使用
值得注意的是,这里的小表的“小”是指关联的表们分别按照各自的过滤条件进行过滤后,参与join的数据量,而非原始数据量
说白了就是先执行的那部分所得到的结果集越小,执行效率越高
COUNT优化
关于count(*)、count(1)、count(id)、count(字段)哪种效率最高?
自问自答:
-
字段有索引
count(*)约等于count(1)>count(字段)>count(id)- 二级索引存储的数据比主键索引小
count(1)无需取字段,count(字段)需要取字段,理论上来说count(1)会比count(字段)快一点count(*)被特别优化了下,按行累加,效率很高
- 字段无索引
count(*)约等于count(1)>count(id)>count(字段)
但其实MySQL优化到现在的版本,这四个的执行效率基本差不多,explain下
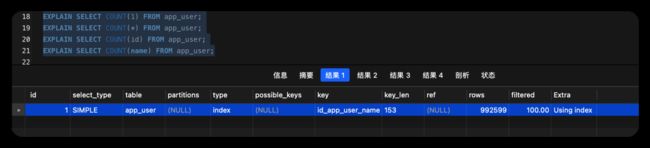



可以看到四条执行结果完全一致,SO你懂的(o^^o)/
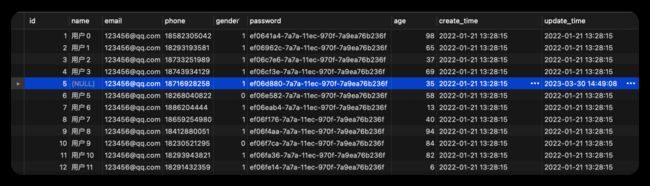
不过count(字段)跟其他3个有个很大的区别,当字段中有NULL时(如下图id为5的数据行name的值为NULL)
我们分别执行下count(*)、count(1)、count(id)、count(name)
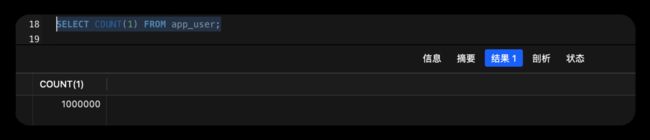

可以看到,当count某个字段时,如果该字段为NULL,则不会被统计到(其他三个都会统计到)
优化方式
-
查询MySQL自己维护的总行数
- 使用myisam存储引擎的表的总行数(不带
WHERE的)会被myisam存储到磁盘上,查询无需计算,超级快 - innodb存储引擎由于MVCC机制,获取总行数需要实时计算
- 使用myisam存储引擎的表的总行数(不带
-
模糊获取
- 使用
show table status like '表名'获取近似值,不准确,但很快并且无需额外操作
- 使用
-
在Redis中维护总行数
- 插入删除操作都需要额外维护Redis,而且并非完全准确的
-
在数据库增加计数表
- 准确,但成本较高,插入删除操作都需要额外维护这张表