C语言——程序实现过程
C语言——程序实现过程
一段代码要实现,会经过编译,汇编,链接,变成可执行程序,由我们用户使用。程序的执行过程中有两个环境存在,一个是翻译程序环境,一个是执行代码环境,两个环境的不同就在于,先将代码翻译成我们的二进制文件供计算机阅读,然后计算机根据翻译的内容,执行相应的操作。
程序的编译
程序的编译分为几个阶段,总结一下,就是将C代码转换成汇编代码,然后会进行代码的分析,就像语法分析,词法分析,语义分析,符号分析,而就是这几种分析,当我们编写程序的时候,遇见语法错误提示,便是编译阶段出了问题,在编译过程中,我们会将代码中注释部分去除,以便机器阅读效率更高。
这里要特别了解一下**#define在编译阶段,#define定义的字符的值**会直接在代码中进行替换,然后定义的这行代码会被去除,使得代码简洁。
而#define可不止这一个功能,他不但可以定义字符,还可以用于定义宏,在计算结构体空间大小时,我们用到了一个函数offsetof这个函数在库函数中就是由宏定义的。
#define OFFSETOF(struct,struct member) &((struct*)0)-struct member
宏是一种由#define定义的,可以使用函数的功能,他在编译阶段会被识别然后进行替换。
程序的汇编
进行完程序的编译就是程序的汇编,汇编的主要功能就是把汇编指令变成二进制指令,供机器识别。
在这里我们可以打开vs编译器查看下面代码的反汇编。
#include打开反汇编方法

根据这个步骤,我们可以查看到该段代码的反汇编代码。
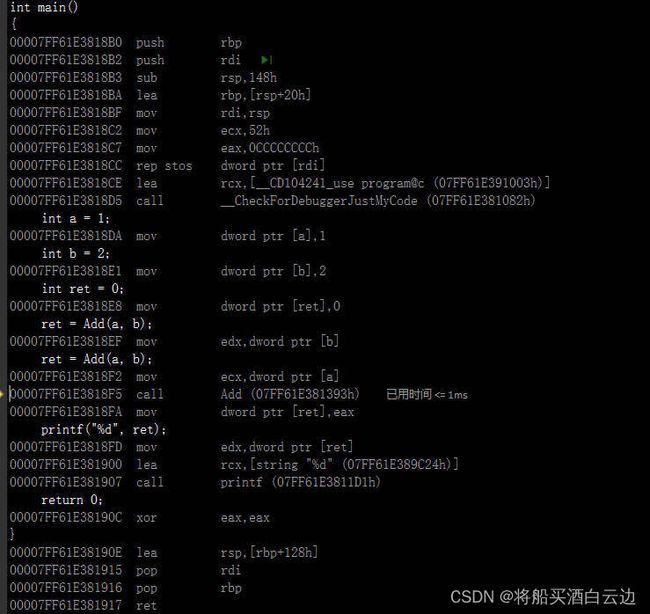
可以发现,其中的一些还是可以识别的代码,这就是在汇编时,我们写的代码会转换成的二进制指令,供计算机阅读形成相应的符号表。
程序的链接
在我们经常出现的错误未找到定义的函数时,就是程序的链接出现了错误,俗称链接错误,在链接时,程序会合并段表,主要会发生符号表定义和重定位。经过链接才会生成可执行文件,也就是产生*.exe文件。存在我们的Debug文件夹中。
#的大用处
在简述程序的实现过程就免不了会看见#,这个符号的用处不光是在头文件和define有关系,还跟打印有关,当我们在屏幕上打印东西的时候不可避免是会使用printf函数,在使用该函数打印字符串时,两个相邻被引用的字符串可以相互连接。
#include
可见当我们隔开字符时,字符打印时会自动连接,而我们的#是如何使用的。
在我们打印个人信息时,经常会需要多行代码分开打印,而#可以代替变量的存在,减少代码冗余。
#include
这个宏既可以打印整型也可以打印浮点型,就是利用的#可以将后面跟随的值变成字符串,所以在打印时也可以输出,因为字符串和字符串之间可以相互连接。
##(双#号)
这个符号的作用有点奇葩!!!
是将左右两边的字符串相结合,然后变成一个新的字符串,但前提是这个字符串被定义,否则会被判定不合法!
#include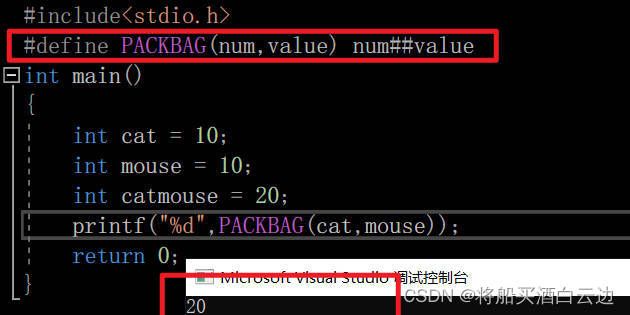
该符号在定义宏时并不常见,这里也是分享一下该符号。
在给函数或者宏传参时,传参也是有讲究的,在参数中还有带着副作用的参数!我们在传递参数时,是根据该参数是否会改变而判断他是否会对函数产生副作用。
#include如此乱的关系,真的是难以处理,所以在给宏传参时,应该避免使用带有副作用的参数。
程序的预处理
其实在程序编译期间会出现一个程序预处理阶段,在这个阶段我们会对#定义的一些预处理符号进行替换和判断,例如
#undef
#undef STRINGNAM
//取消对该字符的所有定义
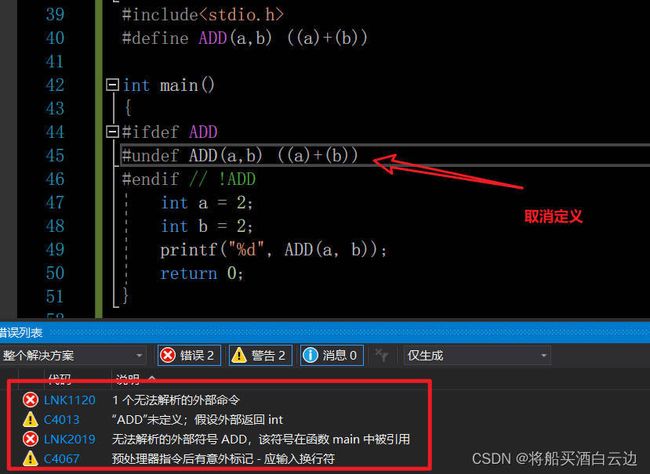
该指令是用于取消上一条宏定义的。如果你需要将宏取消又不想删除他,可以用该指令,而这种指令又被称为条件编译。
在编译一个程序时,当我们觉得该代码无用或者是只适用于调试阶段,不想让该代码消失我们就可以使用条件编译,最常用的条件编译如下:
#if 常量表达式(满足条件执行,不满足退出)
#endif
//结束时一定要加该条件
//常量表达式与预处理一起使用
#define _expression_
#if _expression_
//……执行
#endif
//多分支
#if 常量表达式
//……执行
#elif
//……执行
#else
//……执行
#endif
常见使用方法
#include文件包含方法也会影响程序
在我们使用库函数时,经常性的会使用一些头文件的包含,头文件的包含方法有两种,一种是使用<>,还有一种是使用“ ”,前者这是我们最常用的头文件包含方法,而后者虽然我们现在不常用,但是在开发时是会经常使用的。
这两种头文件的包含分别有什么不同,两者的索引方式不同,使用" "引用的头文件在查找相关文件时会先在所在文件目录中查找是否含有该头文件,然后再会去库函数目录下查找。而由<>包含的文件会直接去库函数中查找。两者之间的效率不言而喻。有时候我们会因为方便引用将一些头文件放到一个文件中,在引用时不小心调用了很多次,为了避免这类事件发生,我们可以用到:
//判定是否定义,如果没有定义则执行
#ifndef
#define
#endif
案例:
#include当你上机调试后就可以发现这个条件编译符,他既可以判定#define也可以对头文件进行判定。
#ifndef stdio.h
#include当你上机调试后就可以发现这个条件编译符,他既可以判定#define也可以对头文件进行判定。
#ifndef stdio.h
#include