c# 获取所有的进程的cpu使用率_Centos下CPU、内存、IO监控分析
CPU监控分析
top命令是Linux下常用的性能分析工具,能够实时(默认是3s刷新一次)的显示系统的资源使用情况,以及各种进程的资源使用情况,类似于Windows的任务管理器。
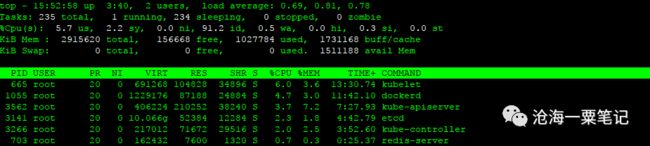
第一行数据相当于uptime命令输出。15:52:58是当前时间,up 0 days,3:40 是系统已经运行的时间,2 users表示当前有6个用户在登录,load average:0.69,0.81,0.78分别表示系统一分钟平均负载,5分钟平均负载,15分钟平均负载。
平均负载
平均负载表示的平均活跃进程数,包括正在running的进程数,准备running(就绪态)的进程数,和处于不可中断睡眠状态的进程数。如果平均负载数刚好等于CPU核数,那证明每个核都得到很好的利用,如果平均负载数大于核数证明系统处于过载的状态,通常认为是超过核数的70%认为是严重过载,需要关注。还需结合1分钟平均负载,5分钟平均负载,15分钟平均负载看负载的趋势,如果1分钟负载比较高,5分钟和15分钟的平均负载都比较低,则说明是瞬间升高,需要观察。如果三个值都很高则需要关注下是否某个进程在疯狂消耗CPU或者有频繁的IO操作,也有可能是系统运行的进程太多,频繁的进程切换导致。
第二行的Tasks信息展示的系统运行的整体进程数量和状态信息。235 total 表示系统现在一共有235个用户进程,1 running 表示1个进程正在处于running状态,234 sleeping表示209个进程正处于sleeping状态,0 stopped 表示 0 个进程正处于stopped状态,0 zombie表示 有0个僵尸进程。
僵尸进程
子进程结束时父进程没有调用wait()/waitpid()等待子进程结束,那么就会产生僵尸进程。原因是子进程结束时并没有真正退出,而是留下一个僵尸进程的数据结构在系统进程表中,等待父进程清理,如果父进程已经退出则会由init进程接替父进程进行处理(收尸)。由此可见,如果父进程不作为并且又不退出,就会有大量的僵尸进程,每个僵尸进程会占用进程表的一个位置(slot),如果僵尸进程太多会导致系统无法创建新的进程,因为进程表的容量是有限的。所以当zombie这个指标太大时需要引起我们的注意。下面的进程详细信息中的S列就代表进程的运行状态,Z表示该进程是僵尸进程。
消灭僵尸进程的方法:
1.找到僵尸进程的父进程pid(pstress可以显示进程父子关系),kill -9 pid,父进程退出后init自动会清理僵尸进程。(需要注意的是kill -9并不能杀死僵尸进程)
2.重启系统。
第三行的%Cpu(s)表示的是总体CPU使用情况。
us |
user |
表示用户态的CPU时间比例 |
sy |
system |
表示内核态的CPU时间比例 |
ni |
nice |
表示运行低优先级进程的CPU时间比例 |
id |
idle |
表示空闲CPU时间比例 |
wa |
iowait |
表示处于IO等待的CPU时间比例 |
hi |
hard interrupt |
表示处理硬中断的CPU时间比例 |
si |
soft interrupt |
表示处理软中断的CPU时间比例 |
st |
steal |
表示当前系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间比例。 |
所以整体的CPU使用率=1-id。当us很高时,证明CPU时间主要消耗在用户代码,需要优化用户代码。sy很高时,说明CPU时间都消耗在内核,要么是频繁的系统调用,要么是频繁的CPU切换(进程切换/线程切换)。wa很高时,说明有进程在进程频繁的IO操作,有可能是磁盘IO,也有可能是网络IO。si很高时,说明CPU时间消耗在处理软中断,网络收发包会触发系统软中断,所以大量的网络小包会导致软中断的频繁触发,典型的SYN Floor会导致si很高。
第4,5行显示的是系统内存使用情况。单位是KiB。total 表示总内存,free 表示没使用过的内容,used是已经使用的内存。buff表示用于读写磁盘缓存的内存,cache表示用于读写文件缓存的内存。avail表示可用的应用内存。
Swap原理是把一块磁盘空间或者一个本地文件当成内存来使用。Swap total表示能用的swap总量,swap free表示剩余,used表示已经使用的。这三个值都为0表示系统关闭了swap功能,由于演示环境是一台虚拟机,虚拟机一般都关闭swap功能。
第6行开始往后表示的是具体的每个进程状态:
PID |
进程ID |
USER |
进程所有者的用户名,例如root |
PR |
进程调度优先级 |
NI |
进程nice值(优先级),越小的值代表越高的优先级 |
VIRT |
进程使用的虚拟内存 |
RES |
进程使用的物理内存(不包括共享内存) |
SHR |
进程使用的共享内存 |
CPU |
进程使用的CPU占比 |
MEM |
进程使用的内存占比 |
TIME |
进程启动后到现在所用的全部CPU时间 |
COMMAND |
进程的启动命令(默认只显示二进制,top -c能够显示命令行和启动参数) |
计算原理
在介绍top命令的各项指标计算原理之前,有必要先介绍下Linux下的proc文件系统,因为top命令的各项数据来源于proc文件系统。proc文件系统是一个虚拟的文件系统,是Linux内核和用户的一种通信方式,Linux内核会通过proc文件系统告诉用户现在内核的状态信息,用户也可以通过写proc的方式设置内核的一些行为。与普通文件不同的是,这些proc文件是动态创建的,也是动态修改的,因为内核的状态时刻都在变化。
top显示的CPU指标都是来源于/proc/stat文件信息:
[root@master1 ~]# cat /proc/stat
cpu 326945 131 115047 2373895 254990 0 11836 0 0 0
cpu0 166369 57 58771 1189571 126833 0 7355 0 0 0
cpu1 160575 74 56276 1184323 128157 0 4481 0 0 0
第一行代表的总的CPU信息,后面的是一个CPU的详细信息。
但是这些具体的后面的列都是什么信息呢,我们可以通过man proc找到答案。
也就是说从第二列开始往后分别是user,nice,system,idle,iowait,irq(硬中断),softirq(软中断),steal,guest,guest_nice的CPU时间,单位通常是10ms。那么top里面的比例又是怎么算出的呢?
由于CPU时间是一个累加值,所以我们要求一个时间段差值来反映当前的CPU情况,top默认是3s。例如现在取一个user值user1,和当前的一个总量的CPU时间total1
其中total等于上面各项相加,也就是total=user+nice+system+idle+iowait+irq+softirq+steal+guest+guest_nice。3秒后再去一个user值user2和一个总量total2。
那么这3秒钟的user平均cpu占比就等于((user2-user1)/ (total2-total1))/ 3 * 100%。另外每个具体的CPU计算方式同理。
top内存相关的指标直接读取/proc/meminfo文件的对应字段。其中total对应于MemTotal,free 对应于MemFree,avail 对应于MemAailable。
使用技巧
1.多U多核CPU监控
在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:逻辑上有4个,实际中只有1个。

2.高亮显示当前运行进程
敲击键盘“b”(打开/关闭加亮效果)
3.进程字段排序
默认进入top时,各进程是按照CPU的占用量来排序的。敲击键盘“x”(打开/关闭排序列的加亮效果)。另外:
(1)查看内存占用情况,按占用内存大小排序:先按 top 命令然后按 大写的 M 键
(2)查看CPU占用情况按大小排序,top 命令然后按 大写的 P键
4.通过”shift + >”或”shift +
按一次”shift + >”的效果图,视图现在已经按照%MEM来排序,再按一次按时间排。
5.top交互命令
k |
终止一个进程 |
i |
忽略闲置和僵死进程。这是一个开关式命令 |
q |
退出程序 |
-n |
表示更新两次后终止更新显示 |
-c |
切换显示命令名称和完整命令行 |
-d |
表示更新周期 |
-p |
指定进程ID |
6.清理内存(效果不是很理想,最终只能强制关闭虚拟机0_0)
# sync
# echo 3 > /proc/sys/vm/drop_caches
7.监控java线程数
ps -eLf | grep java | wc –l
8.监控网络客户连接数
netstat -n | grep tcp | grep 侦听端口 | wc –l
9.常用命令
cat /proc//stat # 获取进程cpu信息
cat /proc//status # 获取进程内存信息
cat /proc//task #task中目录的总数表示在进程中线程的数目
top -Hp 175693 #查看进程使用的工作线程情况,输出的CPU占比需除以CPU核数才是真实值,一个进程某个时间只占用一个CPU内核。
在Linux系统一切都是文件的思想贯彻指导下,所有进程的运行状态都可以用文件来获取。系统根目录/proc中,每一个数字子目录的名字都是运行中的进程的PID,进入任一个进程目录,可通过其中文件或目录来观察进程的各项运行指标,例如task目录就是用来描述进程中线程的,因此也可以通过下面的方法获取某进程中运行中的线程数量(PID指的是进程ID):
ls /proc/PID/task | wc -l
在linux中还有一个命令pmap,来输出进程内存的状况,可以用来分析线程堆栈:
pmap PID
内存监控分析
free命令会显示内存的使用情况,包括实体内存、虚拟的交换文件内存、共享内存区段,以及系统核心使用的缓冲区等。
-b |
以Byte为单位显示内存使用情况 |
-k |
以KB为单位显示内存使用情况 |
-m |
以MB为单位显示内存使用情况 |
-g |
以GB为单位显示内存使用情况 |
-o |
不显示缓冲区调节列 |
-s |
持续观察内存使用状况 |
-l |
显示详细的低和高内存统计信息 |
-t |
显示内存总和列 |
free -m
free -g
free –s 2 –m
CentOS 6及以前
内存的使用分作4部分:
A. 程序使用的;
B. 未被分配的;
C. Buffers (buffer cache)
D. Cached (page cache)
free -m
第一行(Mem):Buffers和Cached被算作used。也就是说,它的free是指 B (未被分配的);它的used是指 A + C + D;
第二行(-/+ buffers/cache):Buffers和Cached被算作free。也就是说,它的used是指 A (程序使用的);它的free是指 B + C + D;行名称“-/+ buffers/cache”的含义就是“把Buffers和Cached从used减下来,加到free里”。
CentOS 7
首先,C (Buffers) 和D (Cached)被和到一起,即buff/cache;
其次,used就是指A (程序使用的);free就是指B (未被分配的);
另外,CentOS 7中加入了一个available,它是什么呢?手册上是这么说的:
MemAvailable: An estimate of how much memory is available for starting new applications, without swapping.
MemAvailable = B (未被分配的) + C (Buffers) + D (Cached) - 不可回收的部分。哪些不可回收呢?共享内存段,tmpfs,ramfs等。
centos系统内存 buff/cache 占用过高
处理步骤:
1.执行sync命令: sync
2.执行释放内存命令:echo 3 > /proc/sys/vm/drop_caches
命令解释:
sync 指令会将存于 buffer 中的资料强制写入硬盘中。
echo 1 > /proc/sys/vm/drop_caches:表示清除pagecache。
echo 2 > /proc/sys/vm/drop_caches:表示清除回收slab分配器中的对象(包括目录项缓存和inode缓存)。
echo 3 > /proc/sys/vm/drop_caches:表示清除pagecache和slab分配器中的缓存
内存实时监控
mem.sh
#!/bin/bash
exec &>> /var/log/mem.log
Free=`free -m|awk 'NR==2 {print $4}'`
if [ $Free -lt 2500 ];then
sync
echo 3 > /proc/sys/vm/drop_caches
fi
vi /etc/crontab
* * * * * /bin/sh /.Script/mem.sh >/dev/null 2>&1
IO监控分析
iostat提供了每个磁盘的使用率、IOPS、吞吐量等各种常见的性能指标,它的输出主要显示磁盘读写操作的统计信息,同时也给出CPU的使用情况。iostat不能对某个进程进行深入分析,仅对操作系统的整体情况进行分析。当然,这些指标实际上来自 /proc/diskstats。
IOTOP用法iostat[参数][间隔时间][次数]
-C |
显示CPU使用情况 |
-d |
显示磁盘使用情况 |
-k |
以 KB 为单位显示 |
-m |
以 M 为单位显示 |
-N |
显示磁盘阵列(LVM) 信息 |
-n |
显示NFS 使用情况 |
-p |
[磁盘] 显示磁盘和分区的情况 |
-t |
显示终端和CPU的信息 |
-x |
显示详细信息 |
iostat -xdm 1 # 个人习惯
CPU 属性值
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
1、如果%iowait的值过高,表示硬盘存在I/O瓶颈
2、%idle值高,表示CPU较空闲
3、如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
4、%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU
磁盘每一列的含义
rrqm/s: 每秒进行 merge 的读操作数目。 即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。 即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为扇区大小为 512 字节
wkB/s: 每秒写 K 字节数。是 wsect/s 的一半
avgrq-sz: 平均每次设备 I/O 操作的数据大小(扇区)
avgqu-sz: 平均 I/O 队列长度。
await: 平均每次设备 I/O 操作的等待时间(毫秒)
svctm: 平均每次设备 I/O 操作的服务时间(毫秒)
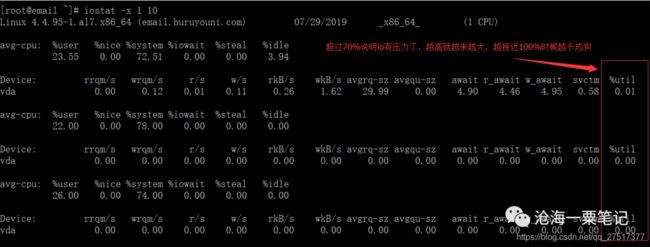
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
1、如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈
2、如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间
3、如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化
4、如果avgqu-sz比较大,也表示有当量io在等待
yum -y install sysstat
yum -y install iotop
一般%util大于70%,I/O压力就开始出现了,如果%util越接近100%,表明I/O压力越大
dm-0、 dm-1、dm-2 从何处来?
1、用lsblk查看
# lsblk2、查看/dev/mapper目录
# ll /dev/mapper/IO性能调优在LINUX系统中,如果有大量读请求,默认的请求队列或许应付不过来,我们可以动态调整请求队列数来提高效率,默认的请求队列数存放在/sys/block/xvda/queue/nr_requests 文件中。注意:/sys/block/xvda ,这里 xvda 写的是你自己的硬盘名,因我的是vps所以是xvda,有可能的参数是 sda hda....等等。如果你不清楚可以,fdisk -l查看一下自己的物理磁盘名称。# fdisk –l# cat /sys/block/xvda/queue/nr_requests通过适当的调整nr_requests 参数可以大幅提升磁盘的吞吐量,缺点就是你要牺牲一定的内存。# lsof -p pid# cat /proc//io1 系统级IO监控# iostat -xdm 1 # 个人习惯%util 代表磁盘繁忙程度。100% 表示磁盘繁忙, 0%表示磁盘空闲。但是注意,磁盘繁忙不代表磁盘(带宽)利用率高 argrq-sz 提交给驱动层的IO请求大小,一般不小于4K,不大于max(readahead_kb, max_sectors_kb),可用于判断当前的IO模式,一般情况下,尤其是磁盘繁忙时, 越大代表顺序,越小代表随机svctm 一次IO请求的服务时间,对于单块盘,完全随机读时,基本在7ms左右,既寻道+旋转延迟时间2 进程级IO监控iotop 顾名思义, io版的toppidstat 顾名思义, 统计进程(pid)的stat,进程的stat自然包括进程的IO状况1、当前系统哪些进程在占用IO,百分比是多少?2、占用IO的进程是在读?还是在写?读写量是多少?iotop参数说明: |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
pidstat -u -r -d -t 1 # -d 只显示IO信息 # -r 缺页及内存信息 # -u CPU使用率 # -t 以线程为统计单位 # 1 1秒统计一次iotop 和 pidstat 用着很爽,但两者都依赖于/proc//io文件导出的统计信息。3 业务级IO监控ioprofile 命令本质上是 lsof + strace。以回答你以下三个问题: 1 当前进程某时间内,在业务层面读写了哪些文件(read, write)? 2 读写次数是多少?(read, write的调用次数) 3 读写数据量多少?(read, write的byte数)ioprofile -p `pidof io_event` -c count # 读写次数ioprofile -p `pidof io_event` -c times # 读写耗时ioprofile -p `pidof io_event` -c sizes # 读写大小ioprofile 仅支持多线程程序,对单线程程序不支持. 对于单线程程序的IO业务级分析,strace足以。ioprofile本质上是strace,因此可以看到read,write的调用轨迹,可以做业务层的io分析(mmap方式无能为力)。4 文件级IO监控文件级IO监控可以配合/补充"业务级和进程级"IO分析。文件级IO分析,主要针对单个文件, 回答当前哪些进程正在对某个文件进行读写操作。 1 lsof 或者 ls /proc//fd 2 inodewatch.stp lsof 告诉你 当前文件由哪些进程打开 lsof ../io # io目录 当前由 bash 和 lsof 两个进程打开 lsof 命令 只能回答静态的信息, 并且"打开" 并不一定"读取", 对于 cat ,echo这样的命令, 打开和读取都是瞬间的,lsof很难捕捉但可以用 inodewatch.stp 来弥补stap inodewatch.stp major minor inode # 主设备号, 辅设备号, 文件inode节点号stap inodewatch.stp 0xfd 0x00 523170 # 主设备号, 辅设备号, inode号,可以通过 stat 命令获得5 其他一句话: 只要磁盘容量不常年保持80%以上,基本上不用担心碎片问题。如果实在担心,可以用 defrag 脚本。blockdev --getbsz /dev/sdc1 # 查看sdc1盘的块大小block blockdev --getra /dev/sdc1 # 查看sdc1盘的预读(readahead_kb)大小blockdev --setra 256 /dev/sdc1 # 设置sdc1盘的预读(readahead_kb)大小,低版的内核通过/sys设置,有时会失败,不如blockdev靠谱