【手把手】教你搭建Sharding-JDBC
Apache ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,由JDBC、Proxy和Sidecar(规划中)这3款相互独立却又能混合部署配合使用的产品组成,它们均提供标准化的数据分片、分布式事务和数据库治理能力。定位于关系型数据库中间件,旨在充分合理地在分布式场景下利用关系型数据库的计算和存储能力,并非实现一个全新的关系型数据库。
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
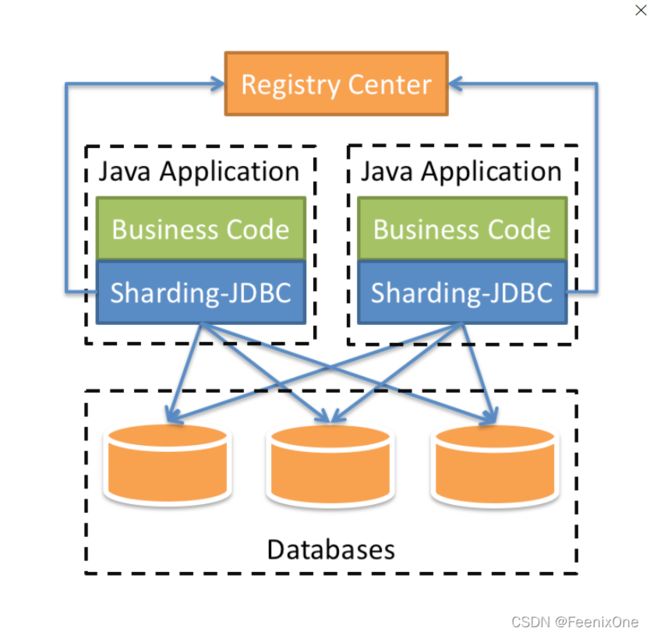
Sharding-Proxy定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。

不使用Spring
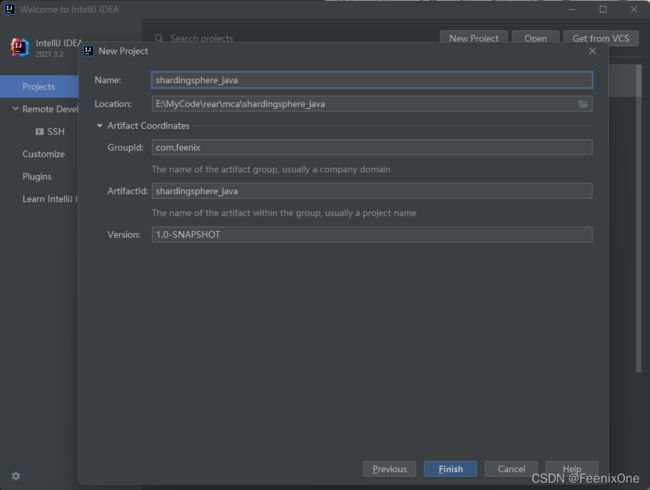
1、使用IDEA创建一个maven项目
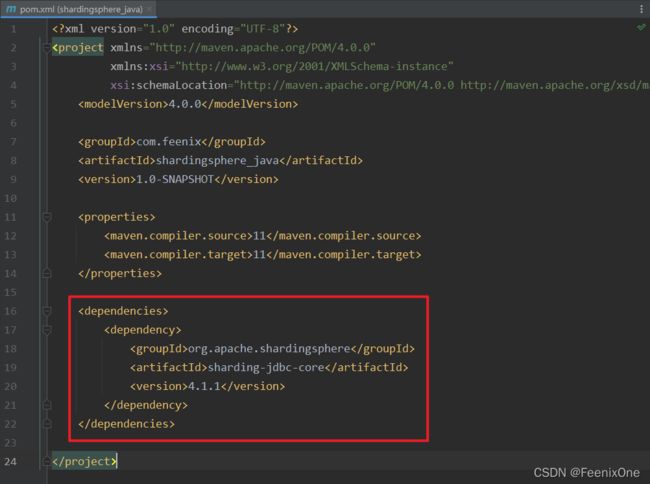
2、引入相关maven依赖
引入Sharding-JDBC依赖
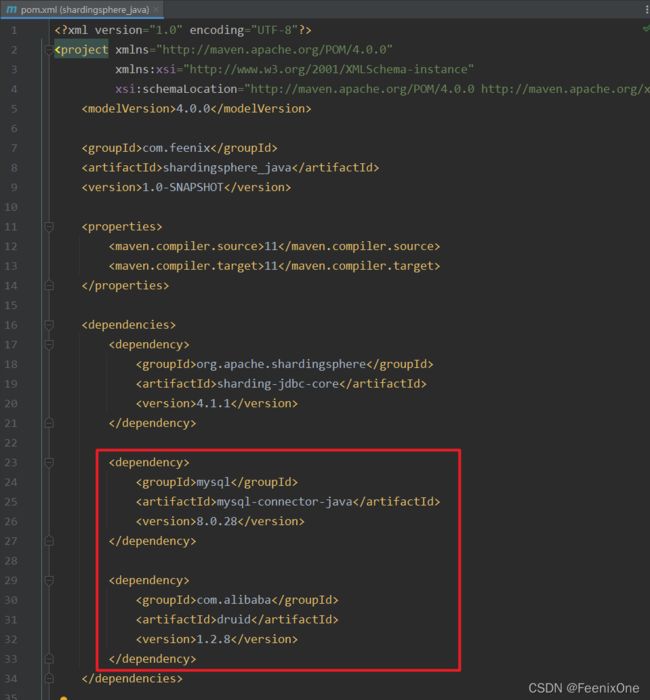
引入MySQL连接依赖
3、测试代码
public static void main(String[] args) {
// 配置真实数据源
Map dataSourceMap = new HashMap<>();
// 配置第一个数据源
DruidDataSource druidDataSource1 = new DruidDataSource();
druidDataSource1.setDriverClassName("com.mysql.cj.jdbc.Driver");
druidDataSource1.setUrl("jdbc:mysql://192.168.159.137:3306/jy_universe?serverTimezone=UTC");
druidDataSource1.setUsername("root");
druidDataSource1.setPassword("Lee@0629");
dataSourceMap.put("ds1", druidDataSource1);
// 配置第二个数据源
DruidDataSource druidDataSource2 = new DruidDataSource();
druidDataSource2.setDriverClassName("com.mysql.cj.jdbc.Driver");
druidDataSource2.setUrl("jdbc:mysql://192.168.159.139:3306/jy_universe?serverTimezone=UTC");
druidDataSource2.setUsername("root");
druidDataSource2.setPassword("Lee@0629");
dataSourceMap.put("ds2", druidDataSource2);
// 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("orders","ds${1..2}.orders_${1..2}");
// 配置分库 + 分表策略
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("customer_id", "ds${customer_id % 2 + 1}"));
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("id", "orders_${id % 2 + 1}"));
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
// 省略配置order_item表规则...
// ...
// 获取数据源对象
try {
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
// 获取数据库连接
Connection connection = dataSource.getConnection();
PreparedStatement preparedStatement = connection.prepareStatement("insert into orders values(?,?,?,?)");
for (int i = 0; i < 10; i++) {
preparedStatement.setInt(1, i);
preparedStatement.setInt(2, i);
preparedStatement.setInt(3, new Random().nextInt(10));
preparedStatement.setDouble(4, i * 100.0);
preparedStatement.execute();
}
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
4、查看执行结果
ds1(192.168.159.137)库中数据:
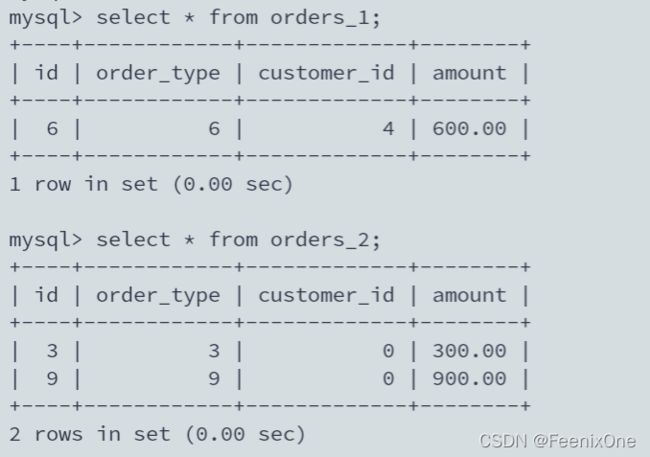
ds2(192.168.159.139)库中数据:

可以看到,数据的拆分完全和代码中的逻辑一致:
先以 customer_id 的值分库,再以 id 的值分表。
5、内部结构
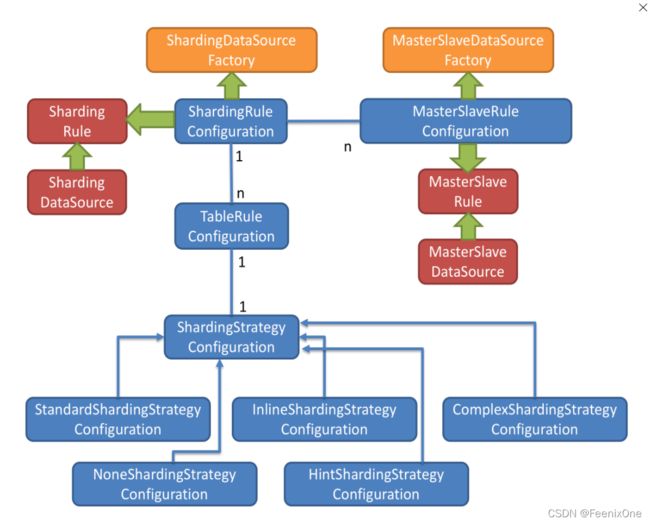
ShardingDataSourceFactory: DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new Properties());
而 MasterSlaveDataSourceFactory 则更多倾向于读写分离方面。
TableRuleConfiguration:
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("orders","ds${1..2}.orders_${1..2}");
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
使用Spring
1、使用IDEA创建一个SpringBoot项目
2、引入相关maven依赖

3、配置application.properties文件
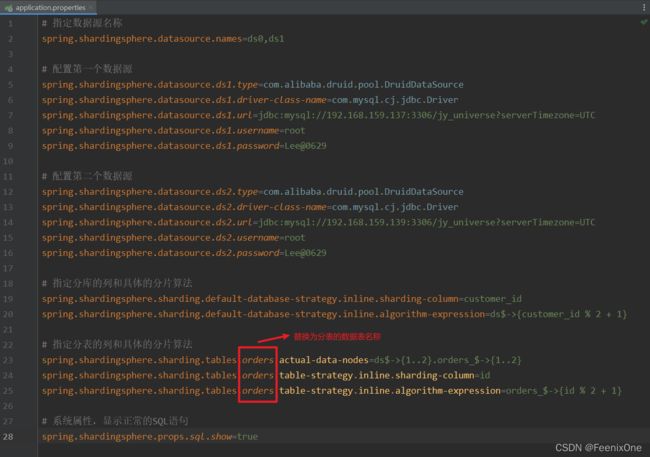
4、执行完之后查看操作的数据源


在查询的时候,当查询条件不包含分库的列时,就会将所有库中的列都做一次筛选,如果有包含则直接去对应的库中查询。
值得一提的是, 官网中特别有指出对于部分SQL是不支持的:


本身分库分表的目的就是将大量无用的数据进行物理隔离,如果在SQL中不考虑任何限制,那么分库分表的意义也将不复存在。
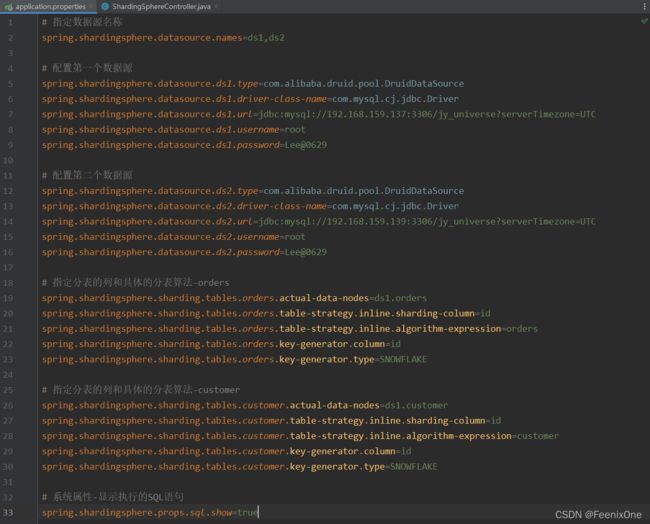
5、配置垂直分库的application.properties文件
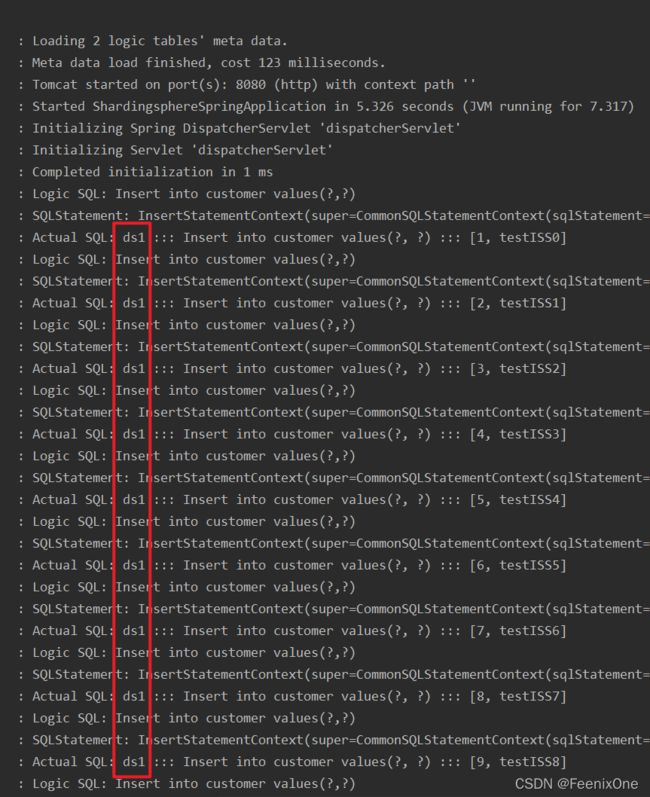

6、配置广播表的application.properties文件
所谓广播表指的是,当指定一张表为广播表时,在配置的每个数据源的库中都会有这么一张表,每次在执行插入操作的时候,每个数据源中的表都会执行相同的操作。

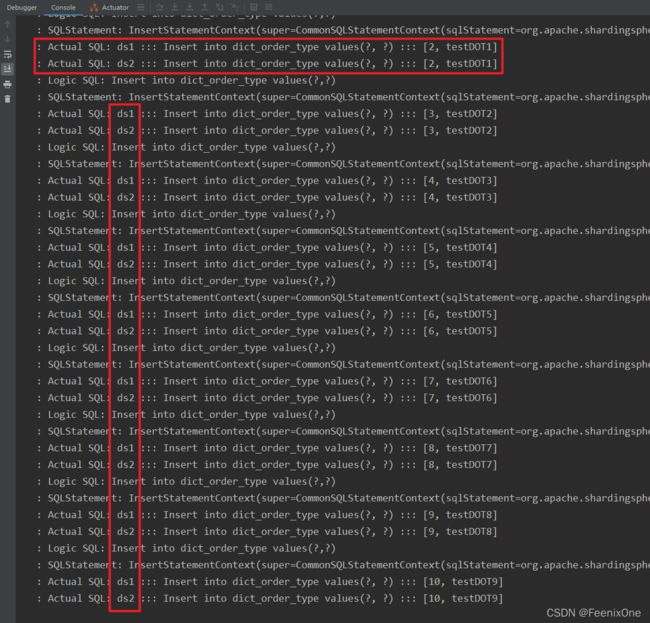
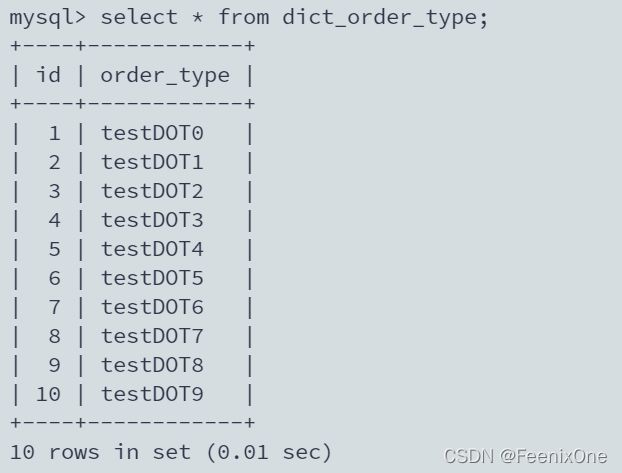
可以看到,在配置的每一个数据源中都进行了数据的插入。可能有的小伙伴会奇怪为什么广播表还要进行配置,直接放到每个库中不行吗?当在使用Sharding-JDBC时候,执行的所有的SQL语句都会经过Sharding-JDBC的拦截,拦截之后会读取相关的配置,然后发送到对应的物理节点。如果没有配置的话,Sharding-JDBC怎么会知道这张表是个广播表,就会将数据进行随机插入。
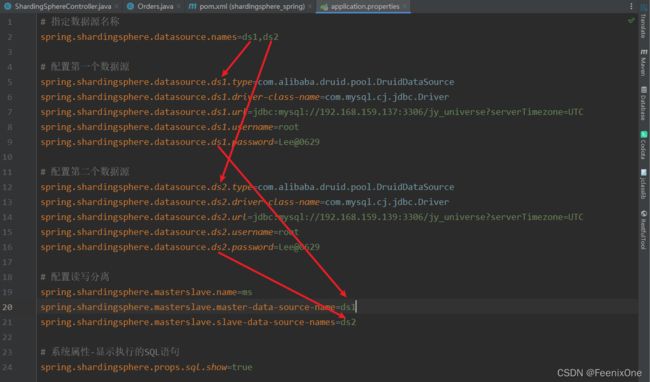
7、基于MySQL主从复制的读写分离管理
引入maven依赖
8、配置主从复制application.properties文件
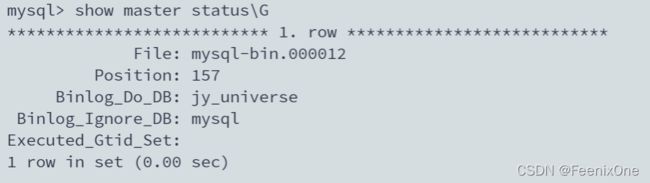
9、确认MySQL主从复制已开启
Master(192.168.159.137)执行:show master status\G
Slave(192.168.159.139) 执行:
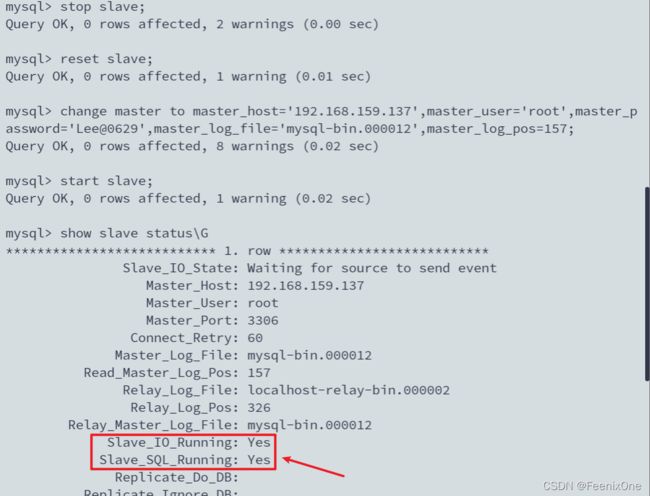
stop slave;
reset slave;
change master to master_host='192.168.159.137',master_user='root',master_password='Lee@0629',master_log_file='mysql-bin.000012',master_log_pos=157;
show slave status\G
 10、查看数据插入结果
10、查看数据插入结果
Master(192.168.159.137)

Slave(192.168.159.139)
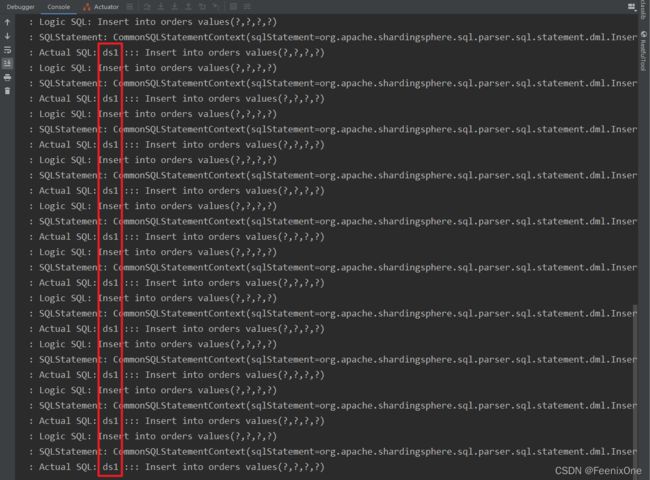
两台服务中的数据完全一致,Sharding-JDBC将数据全都插入到配置的Master库中从而实现读写分离:
可以看到Sharding-JDBC管理主从复制的前提还是要先将MySQL的主从配置好,再设置到配置文件中即可,而不是在Sharding-JDBC中自动去配置主从服务器。