分布式数据库-分库分表01-ShardingJDBC
1.MYSQL分库分表的原理
为什么要分库分表
一般的机器(4核16G),单库的MySQL并发(QPS+TPS)超过了2k,系统基本就完蛋了。最好是并发量控制在1k左右。这里就引出一个问题,为什么要分库分表?
1、高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发,NB的机器除外。
2、数据量大的问题。主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量其他,会导致索引树十分庞大,造成查询缓慢。第二,innodb的最大存储限制64TB
分库分表目的:解决高并发,和数据量大的问题。
分库分表的目的,是将一个表拆成N个表,就是让每个表的数据量控制在一定范围内,保证SQL的性能。 一个表数据建议不要超过500W。

拆表方式
水平拆分:统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。

垂直拆分:业务模块拆分、商品库,用户库,订单库
水平拆分:对表进行水平拆分(也就是我们说的:分表)
表进行垂直拆分:表的字段过多,字段使用的频率不一。(可以拆分两个表建立1:1关系)
不停机分库分表数据迁移
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆成多表。那么我们就看下如何平滑的从MySQL单表过度到MySQL的分库分表架构。
1、利用mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。
2、利用分库分表中间件,全量数据导入到对应的新表中。
3、通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。
4、数据稳定后,将单表的配置切换到分库分表配置上。

2.ShardingJdbc的分库和分表
主要是配置yml
完整的配置如下
- 准备两个数据库ksd_sharding-db。名字相同,两个数据源ds0和ds1
- 每个数据库下方ksd_user0和ksd_user1即可。
- 数据库规则,性别为偶数的放入ds0库,奇数的放入ds1库。
- 数据表规则:年龄为偶数的放入ksd_user0库,奇数的放入ksd_user1库。
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名,下面的ds1,ds1任意取名字
names: ds0,ds1
# 给master-ds1每个数据源配置数据库连接信息
ds0:
# 配置druid数据源
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://47.115.94.78:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# 配置ds1-slave
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.145.201:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT
username: root
password: mkxiaoer1986.
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds0
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: ds0
# 配置分表的规则
tables:
# ksd_user 逻辑表名
ksd_user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: ds$->{sex % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: ksd_user$->{age % 2} # 分片算法表达式
# 整合mybatis的配置XXXXX
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: com.xuexiangban.shardingjdbc.entity
结果如下图:

分解分析如下
2.1创建逻辑表
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:ksd_user0和ksd_user1。他们的逻辑表名是:ksd_user。
在shardingjdbc中的定义方式如下:
spring:
shardingsphere:
sharding:
tables:
# ksd_user 逻辑表名
ksd_user:
2.2 分库分表数据节点 - actual-data-nodes
tables:
# ksd_user 逻辑表名
ksd_user:
# 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 相同表
actual-data-nodes: ds$->{0..2}.ksd_user$->{0..1}
# 数据节点:多数据源$->{0..N}.逻辑表名$->{0..N} 不同表
actual-data-nodes: ds0.ksd_user$->{0..1},ds1.ksd_user$->{2..4}
# 指定单数据源的配置方式
actual-data-nodes: ds0.ksd_user$->{0..4}
# 全部手动指定
actual-data-nodes: ds0.ksd_user0,ds1.ksd_user0,ds0.ksd_user1,ds1.ksd_user1,
数据分片是最小单元。由数据源名称和数据表组成,比如:ds0.ksd_user0。
寻找规则如下:

2.3分库分表5种分片策略
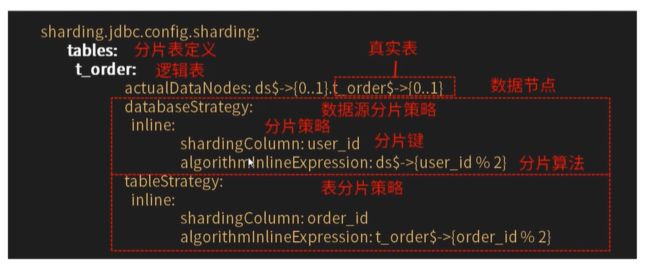
数据源分片分为两种:分片键 分片算法
第一种:none
对应NoneShardingStragey,不分片策略,SQL会被发给所有节点去执行,这个规则没有子项目可以配置。
第二种:inline 行表达时分片策略(核心,必须要掌握)
对应InlineShardingStragey。使用Groovy的表达时,提供对SQL语句种的=和in的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开放,如:ksd_user${分片键(数据表字段)userid % 5} 表示ksd_user表根据某字段(userid)模 5.从而分为5张表,表名称为:ksd_user0到ksd_user4 。如果库也是如此。
server:
port: 8085
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 参数配置,显示sql
props:
sql:
show: true
sharding:
# 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。
default-data-source-name: ds0
# 配置分表的规则
tables:
# ksd_user 逻辑表名
ksd_user:
# 数据节点:数据源$->{0..N}.逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1}
# 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。
database-strategy:
inline:
sharding-column: sex # 分片字段(分片键)
algorithm-expression: ds$->{sex % 2} # 分片算法表达式
# 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。
table-strategy:
inline:
sharding-column: age # 分片字段(分片键)
algorithm-expression: ksd_user$->{age % 2} # 分片算法表达式
algorithm-expression行表达式:
- ${begin…end} 表示区间范围。
- ${[unit1,unit2,….,unitn]} 表示枚举值。
- 行表达式种如果出现连续多个 e x p r e s s s i o n 或 {expresssion}或 expresssion或->{expression}表达式,整个表达时最终的结果将会根据每个子表达式的结果进行笛卡尔组合。
