shardingjdbc简单使用之分库分表
2、shardingjdbc简单使用之分库分表综合使用
shardingjdbc作为shardingsphere中的一部分,提供了分库分表、读写分离、数据治理等功能
分库分表
分库就是按数据库来分:将不同或者相同结构的表分别放在不同的数据库中(例如用户表和订单表放在不同的库)
分表就是按表来分:将相同结构的水平拆分成多个不同名称的表(例如将user表分为user_0、user_1…)
分片键:不管分库还是分表,最终都是存储在表中,分片键就是按照表的某一个字段和分库分表策略进行分配
逻辑表:比如数据库中表是user_0,user_1…,而在代码里sql操作的表是逻辑表,底层会按照分片键和分片策略解析出对应具体的表(如果sql中包含分片键),如果没有分片键就会向所有实际存储表中做对应的操作
文章目录
-
-
- 分库
- 分表
-
分库
springboot+shardingsphere简单使用分库
数据库操作使用mybatisplus
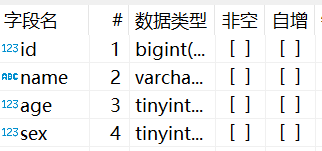
创建两个database并创建相同结构的表,本文分库只使用table_1,table_2用于分表

表结构:sex字段存0和1
mybatis配置省略
分库的yml文件配置
spring:
shardingsphere:
props:
sql:
show: true #开启sql日志
datasource:
names: db1,db2
db1:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://localhost:3306/db1?serverTimezone=GMT%2b8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
db2:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://localhost:3306/db2?serverTimezone=GMT%2b8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
sharding:
tables:
#逻辑表名,数据库中表名叫table_1,代码中的sql查询就使用逻辑表名
user:
#实际存储的数据库表,行表达式等价于db1.table_1,db2.table_1
actual-data-nodes: db$->{1..2}.table_1
key-generator:
column: id #自定填充字段
type: SNOWFLAKE
database-strategy: #分库策略
inline: #分片策略(inline,hint,standard,complex,none)
sharding-column: sex #分片键 按sex字段分库(0:女 1:男)
algorithm-expression: db$->{sex % 2 + 1} # 性别女存db1,男存db2
测试插入数据:
@Test
void insert() {
User user = new User();
user.setName("mary");
user.setAge(19);
user.setSex(0);
userMapper.insert(user);
System.out.println(user.getId());
}
存入的数据sex值时0,应该被存到db1;

那么如果操作数据时不包含分片键字段会怎么样?这里就是sex字段
插入时不指定sex字段会怎么样
@Test
void inserts() {
User user = new User();
user.setName("jack");
user.setAge(22);
//user.setSex(0);
userMapper.insert(user);
System.out.println(user.getId());
}
sql日志就能看出结果:
![]()
如果sql操作中不包含分片键字段 会向所有的实际存储节点插入数据
分表
这里所说的分表是水平分表,即按照分片键将数据存入多个表中。而垂直分表则是按字段将表拆分。
在同一数据库下创建两个结构相同的表用于分表测试:

spring:
shardingsphere:
datasource:
names: db
db:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://localhost:3306/db?serverTimezone=GMT%2b8
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 123456
sharding:
tables:
#逻辑表名
user:
actual-data-nodes: db.table_$->{[1,2]} #事件存储数据的表
#actual-data-nodes: db.table_1,db.table_2
key-generator:
column: id #自定填充字段
type: SNOWFLAKE #雪花算法 UUID、SNOWFLAKE两种(实现ShardingKeyGenerator接口)
table-strategy: #分表策略
inline:
sharding-column: id #分片键
algorithm-expression: table_$->{id % 2 + 1} #分片具体策略
sharding-column: id
algorithm-expression: table_$->{id % 2 + 1}
这里是按id进行分片,id值由SNOWFLAKE(雪花算法)生成,奇数id存table_2,偶数id存table_1
测试插入数据:
User user = new User();
user.setName("green");
user.setAge(19);
user.setSex(0);
userMapper.insert(user);
System.out.println(user.getId());
由控制台日志可以看出,生成的id是偶数存入到table_1中
Actual SQL: db ::: INSERT INTO table_1 (id, age, name, sex) VALUES (?, ?, ?, ?) ::: [1475275875025264642, 19, green, 0]