ShardingJDBC(读写分离、分库分表、分布式事务)
一、ShardingJDBC
简介
-
在3.0以后改名成了ShardingSphere。
-
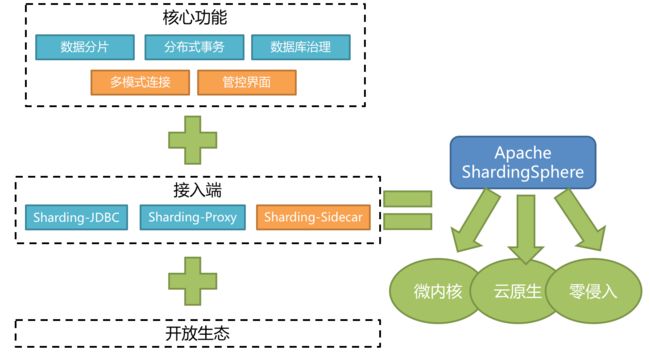
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
-
ShardingSphere-JDBC 采用无中心化架构,适用于 Java 开发的高性能的轻量级 OLTP(连接事务处理) 应用;
-
支持
-
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
-
支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。、
-
支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 等数据库。
功能清单
-
功能列表
-
数据分片
-
分库 & 分表
-
读写分离
-
分片策略定制化
-
无中心化分布式主键
-
-
分布式事务
-
标准化事务接口
-
XA 强一致事务
-
柔性事务
-
数据库治理
-
-
分布式治理
-
弹性伸缩
-
可视化链路追踪
-
数据加密
-
二、mysql主从复制
概念
-
主从复制(也称 AB 复制)允许将一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
-
复制是异步的从库不需要永久连接以接收来自主站的更新。根据配置,可以复制数据库中的所有数据库,所选数据库甚至选定的表。
实现原理
-
主服务器上面的任何修改都会通过自己的 I/O tread(I/O 线程)保存在二进制日志 Binary log 里面。
-
从服务器上面也启动一个 I/O thread,通过配置好的用户名和密码, 连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log(中继日志)里面。
-
从服务器上面同时开启一个 SQL thread 定时检查 Realy log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍。 每个从服务器都会收到主服务器二进制日志的全部内容的副本。
-
从服务器设备负责决定应该执行二进制日志中的哪些语句。除非另行指定,否则主从二进制日志中的所有事件都在从库上执行。
-
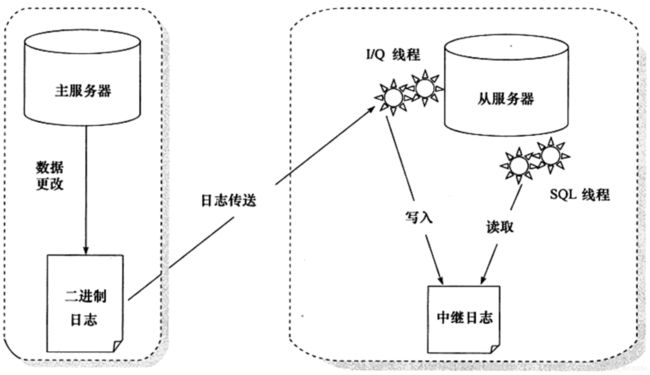
配置主从复制
-
主服务器数据库配置二进制日志
-
[mysqld] ## 同一局域网内注意要唯一 server-id=1 ## 开启二进制日志功能(关键) log-bin=mysql-bin -
从服务器数据库配置二进制日志
-
[mysqld] ## 设置server_id,注意要唯一 server-id=2 ## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用 log-bin=mysql-slave-bin -
在master服务器授权slave服务器可以同步权限(master节点执行)
-
grant replication slave, replication client on *.* to 'root'@'slave服务的ip' identified by 'slave服务器的密码'; -
查询master服务的binlog文件名和位置(master节点执行)
-
show master status; -

-
slave进行关联master节点(slave节点执行)
-
change master to master_host='master服务器ip', master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000002',master_log_pos=2079; -
启动主从复制
-
start slave;
三、shardingJDBC读写分离
-
依赖
-
org.apache.shardingsphere sharding-jdbc-spring-boot-starter ${sharding-sphere.version} org.apache.shardingsphere sharding-core-common ${sharding-sphere.version} -
配置application.yml
-
server: port: 8085 spring: main: allow-bean-definition-overriding: true shardingsphere: # 参数配置,显示sql props: sql: show: true # 配置数据源 datasource: # 给每个数据源取别名,下面的ds1,ds2,ds3任意取名字 names: ds1,ds2,ds3 # 给master-ds1每个数据源配置数据库连接信息 ds1: # 配置druid数据源 type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: mkxiaoer1986. maxPoolSize: 100 minPoolSize: 5 # 配置ds2-slave ds2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: mkxiaoer1986. maxPoolSize: 100 minPoolSize: 5 # 配置ds3-slave ds3: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: mkxiaoer1986. maxPoolSize: 100 minPoolSize: 5 # 配置默认数据源ds1 sharding: # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 default-data-source-name: ds1 # 配置数据源的读写分离,但是数据库一定要做主从复制 masterslave: # 配置主从名称,可以任意取名字 name: ms # 配置主库master,负责数据的写入 master-data-source-name: ds1 # 配置从库slave节点 slave-data-source-names: ds2,ds3 # 配置slave节点的负载均衡均衡策略,采用轮询机制、随机策略 load-balance-algorithm-type: round_robin # 整合mybatis的配置XXXXX mybatis: mapper-locations: classpath:mapper/*.xml type-aliases-package: com.xuexiangban.shardingjdbc.entity -

-

四、shardingJDBC分库分表
-
高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发
-
数据量大的问题。主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量其他,会导致索引树十分庞大,造成查询缓慢。第二,innodb的最大存储限制64TB
-
分库分表目的:解决高并发和数据量大的问题。
-
-
水平拆分:统一个表的数据拆到不同的库不同的表中。可以根据时间、地区、或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致。
-
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
-

分库分表配置
-
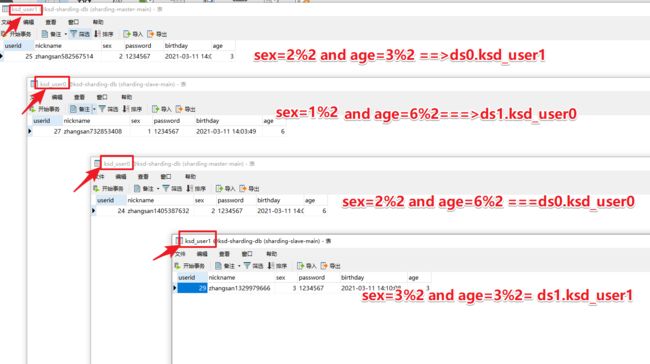
逻辑表:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据用户id%2拆分为2个表,分别是:ksd_user0和ksd_user1。他们的逻辑表名是:ksd_user。
-
数据分片是最小单元。由数据源名称和数据表组成,比如:ds0.ksd_user0。
-
准备两个数据库ksd_sharding-db。名字相同,两个数据源ds0和ds1
-
每个数据库下方ksd_user0和ksd_user1即可。
-
数据库规则,性别为偶数的放入ds0库,奇数的放入ds1库。
-
数据表规则:年龄为偶数的放入ksd_user0库,奇数的放入ksd_user1库。
-
server: port: 8085 spring: main: allow-bean-definition-overriding: true shardingsphere: # 参数配置,显示sql props: sql: show: true # 配置数据源 datasource: # 给每个数据源取别名,下面的ds1,ds1任意取名字 names: ds0,ds1 # 给master-ds1每个数据源配置数据库连接信息 ds0: # 配置druid数据源 type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: mkxiaoer1986. maxPoolSize: 100 minPoolSize: 5 # 配置ds1-slave ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/ksd-sharding-db?useUnicode=true&characterEncoding=utf8&tinyInt1isBit=false&useSSL=false&serverTimezone=GMT username: root password: mkxiaoer1986. maxPoolSize: 100 minPoolSize: 5 # 配置默认数据源ds0 sharding: # 默认数据源,主要用于写,注意一定要配置读写分离 ,注意:如果不配置,那么就会把三个节点都当做从slave节点,新增,修改和删除会出错。 default-data-source-name: ds0 # 配置分表的规则 tables: # ksd_user 逻辑表名 ksd_user: # 数据节点:数据源$->{0..N}.逻辑表名$->{0..N} actual-data-nodes: ds$->{0..1}.ksd_user$->{0..1} # 拆分库策略,也就是什么样子的数据放入放到哪个数据库中。 database-strategy: inline: sharding-column: sex # 分片字段(分片键) algorithm-expression: ds$->{sex % 2} # 分片算法表达式 # 拆分表策略,也就是什么样子的数据放入放到哪个数据表中。 table-strategy: inline: sharding-column: age # 分片字段(分片键) algorithm-expression: ksd_user$->{age % 2} # 分片算法表达式 # 整合mybatis的配置XXXXX mybatis: mapper-locations: classpath:mapper/*.xml type-aliases-package: com.xuexiangban.shardingjdbc.entity -
-

-
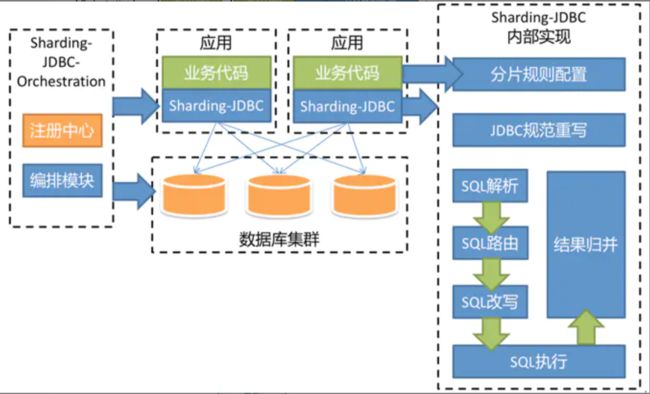
执行流程
-
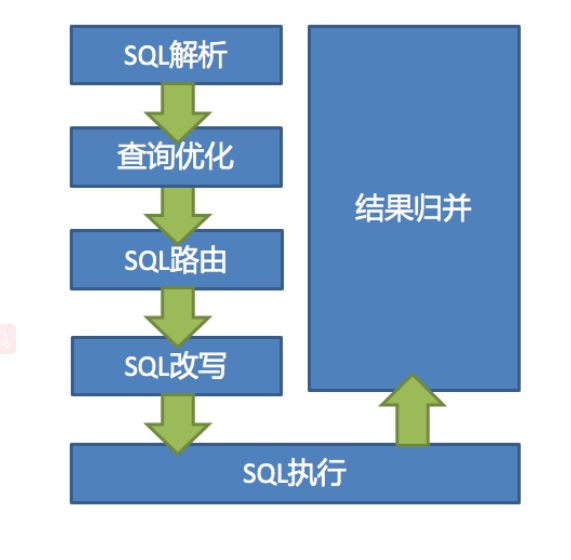
-
SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
-
执行器优化
合并和优化分片条件,如 OR 等。
-
SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
-
SQL 改写
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
-
SQL 执行
通过多线程执行器异步执行。
-
结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
分布式主键
-
ShardingSphere提供灵活的配置分布式主键生成策略方式。在分片规则配置模块配置每个表的主键生成策略。默认使用雪花算法。(snowflake)生成64bit的长整型数据。或UUID。
-
主键列不能自增长。数据类型是:bigint(20)
-
spring: shardingsphere: sharding: tables: # ksd_user 逻辑表名 ksd_user: key-generator: # 主键列名 column: userid # 主键生成策略(雪花算法) type: SNOWFLAKE -

五、分布式事务
-
事务的特性
-
数据库事务需要满足ACID(原子性、一致性、隔离性、持久性)四个特性。
-
原子性(Atomicity)指事务作为整体来执行,要么全部执行,要么全不执行。
-
一致性(Consistency)指事务应确保数据从一个一致的状态转变为另一个一致的状态。
-
隔离性(Isolation)指多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
-
持久性(Durability)指已提交的事务修改数据会被持久保存。
事务的隔离级别
脏读:一个事务在做查询数据时可以读取到别的事务未提交的结果。
不可重复度:一个事务中多次查询出来的数据值不一致。
幻读:一个事务中多次查询出来的数据结果数不一致。
Mysql事务隔离级别:
Read uncommit : 读未提交。会出现脏读情况。
Read commit : 读已提交。解决脏读问题,但会出现不可重复读的情况。
Repeatable read : 可重复读(mysql默认)。解决脏读和不可重复读问题,但会出现幻读情况。
Serializable : 串行化。每行数据操作都会加锁,解决以上所有情况。
事务隔离级别越高,事务并发性就越低。
-
在单一数据节点中,事务仅限于对单一数据库资源的访问控制,称之为本地事务。几乎所有的成熟的关系型数据库都提供了对本地事务的原生支持。 但是在基于微服务的分布式应用环境下,越来越多的应用场景要求对多个服务的访问及其相对应的多个数据库资源能纳入到同一个事务当中,分布式事务应运而生。
-
刚性事务:遵循ACID原则,强一致性,最常见的就是数据库本地事务。
-
柔性事务:遵循BASE理论,最终一致性;与刚性事务不同,柔性事务允许一定时间内,不同节点的数据不一致,但要求最终一致。
-
本地事务
-
完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
-
完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
-
不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提
-
-
两阶段XA分布式事务
-

-
优点:
-
简单易理解,开发较容易
-
两阶段提交保证操作的原子性和数据的强一致性(无法百分百保证)
-
缺点:
-
对资源进行了长时间的锁定,XA无法满足高并发场景。
-
XA目前在商业数据库(Oracle、DB2)支持的比较理想,在mysql数据库中支持的不太理想。
-
不支持服务宕机后,在其它机器上恢复提交/回滚中的数据
-
-
shardingJDBC分布式事务配置
-
io.shardingsphere sharding-transaction-spring-boot-starter 3.1.0 @ShardingTransactionType(TransactionType.XA) @Transactional(rollbackFor = Exception.class) public int saveUserOrder(User user, Order order) { userMapper.addUser(user); int a = 1 / 0; //测试回滚 orderService.addOrder(order); return 1; }
-
柔性分布式事务:
-
消息事务 + 最终一致性
所谓的消息事务就是基于消息中间件的两阶段提交,本质上是对消息中间件的一种特殊利用,它是将本地事务和发消息放在了一个分布式事务里,保证要么本地操作成功成功并且对外发消息成功,要么两者都失败,开源的RocketMQ就支持这一特性
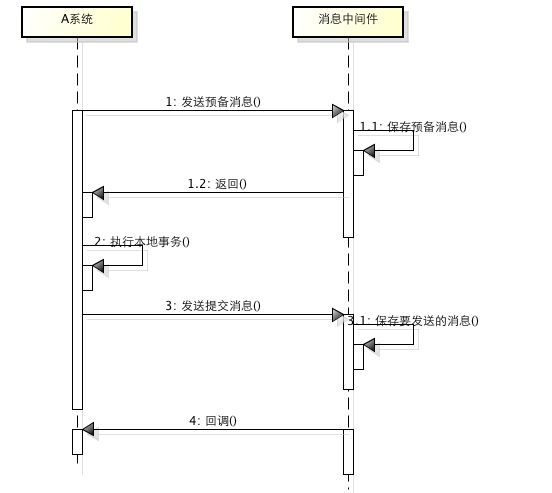
-
1、A系统向消息中间件发送一条预备消息 2、消息中间件保存预备消息并返回成功 3、A执行本地事务 4、A发送提交消息给消息中间件
-
通过以上4步完成了一个消息事务。但每个步骤都可能产生错误:
-
步骤一出错,则整个事务失败,不会执行A的本地操作
-
步骤二出错,则整个事务失败,不会执行A的本地操作
-
步骤三出错,这时候需要回滚预备消息,怎么回滚?答案是A系统实现一个消息中间件的回调接口,消息中间件会去不断执行回调接口,检查A事务执行是否执行成功,如果失败则回滚预备消息
-
步骤四出错,这时候A的本地事务是成功的,那么消息中间件要回滚A吗?答案是不需要,其实通过回调接口,消息中间件能够检查到A执行成功了,这时候其实不需要A发提交消息了,消息中间件可以自己对消息进行提交,从而完成整个消息事务
-
-
基于消息中间件的两阶段提交往往用在高并发场景下,将一个分布式事务拆成一个消息事务(A系统的本地操作+发消息)+B系统的本地操作,其中B系统的操作由消息驱动,只要消息事务成功,那么A操作一定成功,消息也一定发出来了,这时候B会收到消息去执行本地操作,如果本地操作失败,消息会重投,直到B操作成功,这样就变相地实现了A与B的分布式事务。原理如下:
-
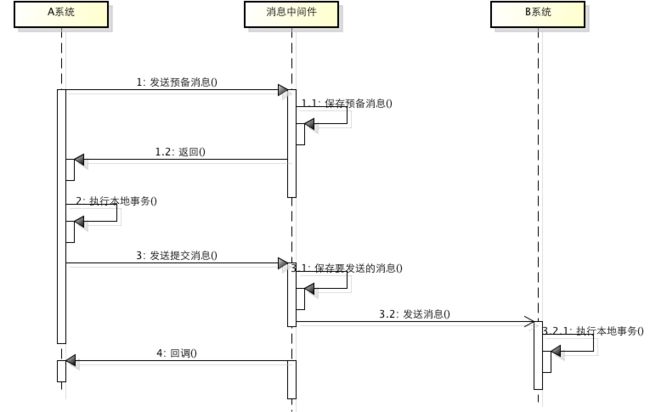
-
TCC3阶段提交的分布式事务
-
所谓的TCC编程模式,也是两阶段提交的一个变种。TCC提供了一个编程框架,将整个业务逻辑分为三块:Try、Confirm和Cancel三个操作。以在线下单为例,Try阶段会去扣库存,Confirm阶段则是去更新订单状态,如果更新订单失败,则进入Cancel阶段,会去恢复库存。总之,TCC就是通过代码人为实现了两阶段提交,不同的业务场景所写的代码都不一样,复杂度也不一样,因此,这种模式并不能很好地被复用。
Seata分布式事务(阿里)
-
完全支持跨库分布式事务
-
支持RC隔离级别
-
通过undo快照进行事务回滚
-
支持服务宕机后的,自动恢复提交中的事务
Saga分布式事务
-
并发度高,不用像XA事务那样长期锁定资源
-
需要定义正常操作以及补偿操作,开发量比XA大
-
一致性较弱,对于转账,可能发生A用户已扣款,最后转账又失败的情况
-
包括两种恢复策略,包括分支事务并发执行
-
SAGA适用的场景较多,长事务适用,对中间结果不敏感的业务场景适用