OWASP Top 10 2021简介
欢迎来到 OWASP Top 10 的最新一期!OWASP Top 10 2021 是全新的,具有新的图形设计和可用的一页信息图,您可以打印或从我们的主页获取。
非常感谢为本次迭代贡献时间和数据的所有人。没有你,这一期就不会发生。谢谢。
2021 年前 10 名发生了什么变化
有三个新类别,四个类别的命名和范围发生了变化,并在 2021 年的前 10 名中进行了一些合并。
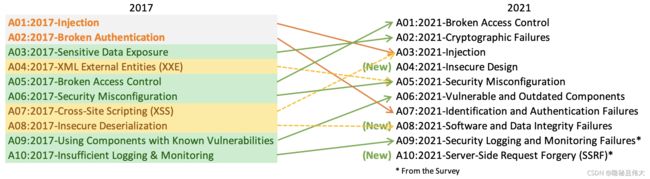
2017 年 Top 10 与新的 Top 10 2021 之间关系的映射
A01:2021-损坏的访问控制:从第五位上升;94% 的应用程序都经过了某种形式的破坏访问控制的测试。映射到 Broken Access Control 的 34 个 CWE 在应用程序中出现的次数比任何其他类别都多。
A02:2021-加密失败:上移一位至 #2,以前称为敏感数据暴露,这是广泛的症状而不是根本原因。此处重新关注与密码学相关的故障,这些故障通常会导致敏感数据暴露或系统受损。
A03:2021-注入:下滑到第三位。94% 的应用程序都针对某种形式的注入进行了测试,映射到此类别的 33 个 CWE 在应用程序中出现次数第二多。跨站点脚本编写现在是此版本中此类别的一部分。
A04:2021-不安全设计是2021 年的一个新类别,重点关注与设计缺陷相关的风险。如果我们真的想作为一个行业“向左移动”,就需要更多地使用威胁建模、安全设计模式和原则以及参考架构。
A05:2021-安全配置错误从上一版的第 6 位上升;90% 的应用程序都经过了某种形式的错误配置测试。随着更多转向高度可配置的软件,看到这一类别上升也就不足为奇了。XML 外部实体 (XXE) 的前一个类别现在属于此类别。
A06:2021-易受攻击和过时的组件:之前的标题是 使用具有已知漏洞的组件,在行业调查中排名第二,但也有足够的数据通过数据分析进入前 10 名。该类别从 2017 年的第 9 位上升,是我们难以测试和评估风险的已知问题。它是唯一没有任何 CVE 映射到包含的 CWE 的类别,因此默认的利用和影响权重 5.0 被计入他们的分数。
A07:2021-身份验证失败:以前是 Broken Authentication并且从第二位下滑,现在包括与识别失败更多相关的 CWE。这个类别仍然是前 10 名的一个组成部分,但标准化框架的可用性增加似乎有所帮助。
A08:2021-软件和数据完整性故障是 2021 年的一个新类别,专注于在不验证完整性的情况下做出与软件更新、关键数据和 CI/CD 管道相关的假设。CVE/CVSS 数据的最高加权影响之一映射到此类别中的 10 个 CWE。2017 年的不安全反序列化现在是这一更大类别的一部分。
A09:2021-安全日志记录和监控失败以前是 日志记录和监控不足,是从行业调查 (#3) 中添加的,从之前的 #10 上升。此类别已扩展为包括更多类型的故障,难以测试,并且在 CVE/CVSS 数据中没有得到很好的体现。但是,此类故障会直接影响可见性、事件警报和取证。
A10:2021-服务器端请求伪造 (SSRF):是从行业调查 (#1) 中添加的。数据显示发生率相对较低,测试覆盖率高于平均水平,并且利用和影响潜力的评级高于平均水平。此类别代表行业专业人士告诉我们这很重要的场景,即使目前数据中没有说明。
方法
前 10 名的这一部分比以往任何时候都更受数据驱动,但并非盲目地受数据驱动。我们从贡献的数据中选择了十个类别中的八个,从高水平的行业调查中选择了两个类别。我们这样做的根本原因是,查看贡献的数据就是回顾过去。AppSec 研究人员花时间寻找新的漏洞和测试它们的新方法。将这些测试集成到工具和流程中需要时间。当我们能够可靠地大规模测试弱点时,可能已经过去了很多年。为了平衡这种观点,我们使用行业调查来询问一线人员他们认为数据可能尚未显示的基本弱点。
我们采用了一些关键的变化来继续使前 10 名变得成熟。
类别的结构
与上一期的 OWASP 前十名相比,一些类别发生了变化。以下是类别更改的高级摘要。
以前的数据收集工作集中在大约 30 个 CWE 的规定子集上,并有一个要求额外发现的领域。我们了解到,组织将主要关注那 30 个 CWE,很少添加他们看到的其他 CWE。在本次迭代中,我们将其打开并仅询问数据,对 CWE 没有限制。我们询问了给定年份(从 2017 年开始)测试的应用程序数量,以及在测试中发现至少一个 CWE 实例的应用程序数量。这种格式使我们能够跟踪每个 CWE 在应用程序群体中的流行程度。为了我们的目的,我们忽略频率;虽然在其他情况下可能有必要,但它仅隐藏了应用程序群体中的实际流行率。一个应用程序是否有四个 CWE 或 4 个实例,000 个实例不是前 10 名计算的一部分。我们从大约 30 个 CWE 增加到近 400 个 CWE,以在数据集中进行分析。我们计划在未来做额外的数据分析作为补充。CWE 数量的显着增加需要改变类别的结构。
我们花了几个月的时间对 CWE 进行分组和分类,并且本可以再持续几个月。我们不得不在某个时候停下来。CWE有根本原因和症状类型,其中根本原因类型如“加密失败”和“错误配置”,与“敏感数据暴露”和“拒绝服务”等症状类型形成对比 。我们决定尽可能关注根本原因,因为提供识别和补救指导更合乎逻辑。关注根本原因而不是症状并不是一个新概念。前十名是症状和根本原因的混合体。 ; 我们只是更加深思熟虑并大声疾呼。本部分中每个类别平均有 19.6 个 CWE,下限为A10: 2021-服务器端请求伪造 (SSRF) 的1 个 CWE 到A04: 2021-不安全设计中的40 个 CWE 。这种更新的类别结构提供了额外的培训好处,因为公司可以专注于对语言/框架有意义的 CWE。
如何使用数据选择类别
2017 年,我们按发生率选择类别来确定可能性,然后根据数十年的可利用性、可检测性(也是可能性)和技术影响的经验,通过团队讨论对它们进行排名。对于 2021 年,如果可能,我们希望将数据用于可利用性和影响。
我们下载了 OWASP Dependency Check 并提取了 CVSS Exploit 和按相关 CWE 分组的影响分数。由于所有 CVE 都有 CVSSv2 分数,因此需要进行大量研究和努力,但 CVSSv2 中存在 CVSSv3 应该解决的缺陷。在某个时间点之后,所有 CVE 也会被分配一个 CVSSv3 分数。此外,在 CVSSv2 和 CVSSv3 之间更新了评分范围和公式。
在 CVSSv2 中,Exploit 和 Impact 都可以达到 10.0,但公式会将它们降低到 Exploit 的 60% 和 Impact 的 40%。在 CVSSv3 中,Exploit 的理论最大值限制为 6.0,Impact 的理论最大值限制为 4.0。考虑到权重,Impact 得分上升了,在 CVSSv3 中平均下降了近一个半点,而可利用性平均下降了近半个点。
OWASP Dependency Check提取的NVD数据中有125k条CVE映射到CWE的记录,映射到CVE的唯一CWE有241条。62k CWE 地图有一个 CVSSv3 分数,大约是数据集中人口的一半。
对于前十名,我们按以下方式计算平均利用和影响分数。我们按 CWE 将所有具有 CVSS 分数的 CVE 分组,并按具有 CVSSv3 的人口百分比 + 剩余的 CVSSv2 分数对漏洞利用和影响评分进行加权,以获得总体平均值。我们将这些平均值映射到数据集中的 CWE,以用作风险等式另一半的利用和影响评分。
为什么不只是纯粹的统计数据?
数据中的结果主要限于我们可以以自动化方式测试的内容。与经验丰富的 AppSec 专业人士交谈,他们会告诉您他们发现的东西和他们看到的尚未在数据中的趋势。人们需要时间为某些漏洞类型开发测试方法,然后需要更多时间让这些测试自动化并针对大量应用程序运行。我们发现的一切都是回顾过去,可能会遗漏去年的趋势,而这些趋势在数据中并不存在。
因此,我们只从数据中挑选了十个类别中的八个,因为它是不完整的。其他两类来自行业调查。它允许一线从业者投票选出他们认为可能没有在数据中(并且可能永远不会在数据中表达)的最高风险。
为什么是发生率而不是频率?
有三个主要数据来源。我们将它们识别为人工辅助工具 (HaT)、工具辅助人工 (TaH) 和原始工具。
Tooling 和 HaT 是高频查找生成器。工具将寻找特定的漏洞并不知疲倦地尝试找到该漏洞的每个实例,并将为某些漏洞类型生成高发现计数。看看跨站点脚本,它通常是两种风格之一:它要么是更小的、孤立的错误,要么是系统性问题。当这是一个系统性问题时,一个应用程序的发现计数可能会达到数千个。这种高频率淹没了报告或数据中发现的大多数其他漏洞。
另一方面,TaH 会发现更广泛的漏洞类型,但由于时间限制,发现频率要低得多。当人们测试应用程序并看到诸如跨站点脚本之类的东西时,他们通常会找到三四个实例并停止。他们可以确定一个系统性的发现,并用建议将其写下来,以在应用程序范围内进行修复。没有必要(或时间)找到每个实例。
假设我们采用这两个不同的数据集并尝试按频率合并它们。在这种情况下,工具和 HaT 数据将淹没更准确(但更广泛)的 TaH 数据,这也是为什么跨站点脚本之类的东西在许多列表中排名如此之高的原因,而影响通常是低到中等。这是因为发现的数量庞大。(Cross-Site Scripting 也相当容易测试,因此还有更多测试)。
2017 年,我们引入了使用发生率来重新审视数据,并将 Tooling 和 HaT 数据与 TaH 数据干净地合并。发生率询问应用程序群体中至少有一个漏洞类型实例的百分比。我们不在乎它是一次性的还是系统性的。这与我们的目的无关;我们只需要知道有多少应用程序至少有一个实例,这有助于更清晰地了解测试结果,而不会淹没在高频结果中的数据。
你的数据收集和分析过程是怎样的?
我们在 2017 年开放安全峰会上正式确定了 OWASP 前 10 名数据收集流程。 OWASP 前 10 名领导者和社区花了两天时间制定了透明数据收集流程的正式化。2021 版是我们第二次使用这种方法。
我们通过我们可用的社交媒体渠道发布数据征集,包括项目和 OWASP。在OWASP 项目页面上,我们列出了我们正在寻找的数据元素和结构以及如何提交它们。在GitHub 项目中,我们有用作模板的示例文件。我们根据需要与组织合作,以帮助确定结构并映射到 CWE。
我们从按行业测试供应商的组织、漏洞赏金供应商和贡献内部测试数据的组织那里获取数据。获得数据后,我们将其加载在一起,并对 CWE 映射到风险类别的内容进行基本分析。一些 CWE 之间存在重叠,而另一些则非常密切相关(例如加密漏洞)。任何与提交的原始数据相关的决定都会被记录和发布,以公开和透明地说明我们如何标准化数据。
我们查看了前 10 名中发生率最高的八个类别。我们还查看了行业调查结果,看看哪些类别可能已经存在于数据中。数据中尚未出现的前两名投票将被选为前 10 名中的其他两个名额。一旦全部 10 个名额都被选中,我们将应用广义的可利用性和影响因素;帮助按顺序排列前 10 名。
数据因素
前 10 个类别中的每一个都列出了数据因素,它们的含义如下:
映射的 CWE:前 10 名团队映射到某个类别的 CWE 数量。
发生率:发生率是该组织当年测试的人群中易受该 CWE 影响的应用程序的百分比。
(测试)覆盖率:所有组织针对给定 CWE 测试的应用程序的百分比。
加权漏洞利用:分配给 CVE 的 CVSSv2 和 CVSSv3 分数中的漏洞利用子分数映射到 CWE,归一化,并放置在 10 分的范围内。
加权影响:分配给 CVE 的 CVSSv2 和 CVSSv3 分数的影响子分数映射到 CWE,归一化,并放置在 10pt 范围内。
Total Occurrences:发现的将 CWE 映射到类别的应用程序总数。
Total CVEs:NVD DB 中映射到 CWEs 的 CVEs 总数,映射到一个类别。
2017 年的品类关系
有很多关于十大风险之间重叠的讨论。根据每个(包括 CWE 列表)的定义,确实没有任何重叠。但是,从概念上讲,可能存在基于更高级别命名的重叠或交互。维恩图多次用于显示这样的重叠。
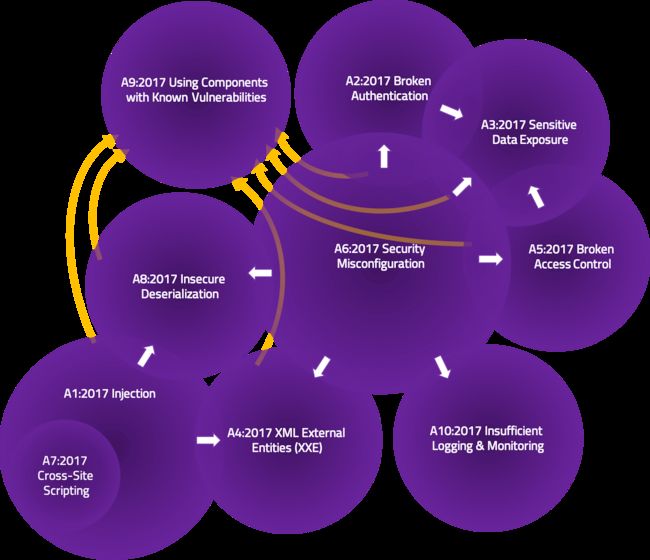
上面的维恩图代表了 2017 年十大风险类别之间的相互作用。这样做时,几个要点变得明显:
有人可能会争辩说,跨站点脚本最终属于注入,因为它本质上是内容注入。看看 2021 年的数据,XSS 需要进入注入变得更加明显。
重叠仅在一个方向。我们通常会根据最终表现或“症状”而不是(可能很深的)根本原因对漏洞进行分类。例如,“敏感数据暴露”可能是“安全配置错误”的结果;但是,您不会从另一个方向看到它。因此,在交互区域中绘制了箭头以指示发生的方向。
有时这些图表是用A06:2021 Using Components with known Vulnerabilities 中的所有内容绘制的。虽然其中一些风险类别可能是第三方漏洞的根本原因,但它们的管理方式和责任通常不同。其他类型通常代表第一方风险。