JAVA-高频面试题汇总:字符串
前言
为了让小伙伴们更好地刷题,我将所有leetcode常考题按照知识点进行了归纳。
目录:
JAVA-高频面试题汇总:动态规划
JAVA-高频面试题汇总:字符串
JAVA-高频面试题汇总:二叉树(上)
JAVA-高频面试题汇总:二叉树(下)
JAVA-高频面试题汇总:回溯
JAVA-高频面试题汇总:字符串
接下来还会进行其他模块的总结,有一起在准备暑期实习的JAVA软开伙伴可以一起交流!
小编微信: Apollo___quan
1.最长回文串

思路
1.每个字母要么出现了奇数次要么偶数次
2.最长长度为所有字母都是偶数次加上一次奇数次(如果有奇数的话)
3.综上,算法总体思路即记录每个字母出现次数,遍历字母,对出现次数取偶数累加,再在最后一步加上奇数次的一次(若ans为1,则有奇数)
注意,JAVA有自动提升数据类型的机制,比如int+char结果就是int,int+String结果就是String
‘z’-'a’也会转化为int
class Solution {
public int longestPalindrome(String s) {
int[] count = new int[128]; //0~127是标准ASCII码,具体看补充,数组初始化后全为0
int length = s.length();
for (int i = 0; i < length; ++i) {
char c = s.charAt(i);
count[c]++; //char自动转化为int,有出现的字母对应的count[ASCII码]值累加,其他没出现的值为0
}
int ans = 0; //标记是否有出现过奇数
for (int v: count) {
ans += v / 2 * 2;
if (v % 2 == 1 && ans % 2 == 0) { //若ans为1,则有奇数,加上最后一次
ans++;
}
}
return ans;
}
}
补充
ASCII 码使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。标准ASCII 码也叫基础ASCII码,使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符 [1] 。其中:
0~31及127(共33个)是**控制字符****或通信专用字符(其余为可显示字符),**如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;ASCII值为8、9、10 和13 分别转换为退格、制表、换行和回车字符。它们并没有特定的图形显示,但会依不同的应用程序,而对文本显示有不同的影响 [1] 。
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
2.字母异位词分组

思路
1.字母异位词指字母相同,但排列不同的字符串。通过字母排序即可将字母异位词分组,当作map的key。例如"bca"和"cab"排序后都是"abc"
2.map.getOrDefault(a, b) 若map中存在key a,则得到key a 的value(之前的list), 否则得到b
3.将本字符串加入到该list,list即为map的value值。最后map的形式为<“abc”,list[“bca”,“cab”,“cba”]>
4.构造ArrayList(),值为map的value
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<String, List<String>>();
for (String str : strs) { //假设str = "cba"
char[] array = str.toCharArray();
Arrays.sort(array);
String key = new String(array); //重新排序后的字符串,"bca"和"cab"排序后都是"abc"
List<String> list = map.getOrDefault(key, new ArrayList<String>());//如果key存在("abc"存在),list 就等于map中key对应的值(list["bca","cab"])
list.add(str); //将"cba"加入list
map.put(key, list); //<"abc",list["bca","cab","cba"]>
}
return new ArrayList<List<String>>(map.values());
}
}
3.最长不含重复字符的子字符串(剑指)

思路
1.HashMap记录每次字符出现的最新坐标
2.当字符重复出现时,通过当时坐标与HashMap中的值(上一次出现坐标)做差,计算出长度
3.此时有两种情况:
一、前一个字符结尾的字符串的范围dp[i-1],若在当前字符串之外,则只能以当前字符串长度记录
二、前一个字符结尾的字符串的范围dp[i-1],若在当前字符串之内,则以dp[i-1]+1计算
class Solution {
public int lengthOfLongestSubstring(String s) {
Map<Character, Integer> dic = new HashMap<>();
int res = 0, tmp = 0;
for(int j = 0; j < s.length(); j++) {
int i = dic.getOrDefault(s.charAt(j), -1); // 获取索引 i, 若字符出现过则为字符上一次出现下标,否则为-1
dic.put(s.charAt(j), j); // 更新哈希表
tmp = tmp < j - i ? tmp + 1 : j - i; // dp[j - 1] 与 j - i (以j结尾的不重复字符串长度)判断大小 如果dp[j-1]小于,说明dp[j-1]的左边界在j此次与上一次区间内, dp[j]=dp[j-1]+1
res = Math.max(res, tmp); // max(dp[j - 1], dp[j])
}
return res;
}
}
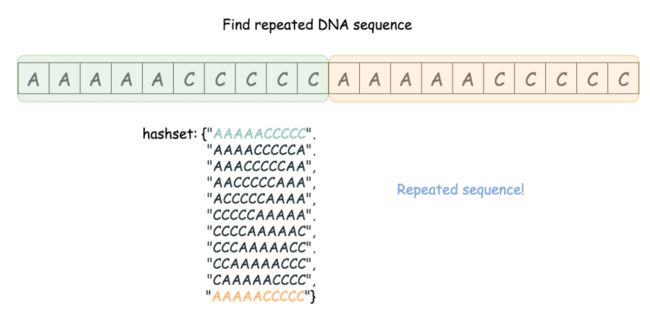
4.重复的DNA序列

思路
将长度为10的字符串全部存入HashSet,有重复存入的即为答案
class Solution {
public List<String> findRepeatedDnaSequences(String s) {
int L = 10;
HashSet<String> map = new HashSet(), res = new HashSet();
for (int i = 0; i < s.length() - L + 1; i++) {
String tmp = s.substring(start, start + L);
if (map.contains(tmp)) res.add(tmp); //如果已经存在,则加入res
map.add(tmp);
}
return new ArrayList<String>(res);
}
}
5.替换空格(剑指)

思路
把字符串变成字符数组遍历,利用StringBuilder重新构造字符串即可,注意StringBuilder.append()方法的参数类型!
class Solution {
public String replaceSpace(String s) {
char[] str = s.toCharArray();
StringBuilder strs = new StringBuilder();
for(char c:str){ //必须是Character不能是char
if(c == ' '){
strs.append("%20");
}
else strs.append(c); //或者也可char变成String类,String.valueOf()方法
}
return strs.toString();
}
}
6.字符串的排列(剑指)

思路
dfs(x)固定第x个(将x与x,x+1,x+2交换,轮流固定,此时需要注意排除重复),然后递归固定第x+1个,
public class Solution {
ArrayList<String> res = new ArrayList<>();
char[] c;
public ArrayList<String> Permutation(String str) {
c = str.toCharArray(); //转化为字符数组c
dfs(0);
Collections.sort(res);
return res;
}
void dfs(int x){ //固定第x个字母
if(x==c.length-1) //最后一个字符,则直接将当前数组转化为string并加入res
{res.add(String.valueOf(c));
return;
}
HashMap<Character,Boolean> hash=new HashMap<>(); //创建HashMap,避免当前位置字母重复
for(int i=x;i<c.length;i++){ //遍历本身,下一个,下下个
if(hash.containsKey(c[i])) //如果有重复的了,跳过,例如“abb”,固定过了“a”,“b”,又到了“b”,则跳过
continue;
else hash.put(c[i],true); //第一次遇到则加入
swap(i,x); //交换
dfs(x+1); //固定下一个
swap(i,x); //交换回来
}
}
void swap(int a,int b){
char temp=c[a];
c[a]=c[b];
c[b]=temp;
}
}
7.第一个只出现一次的字符(剑指)

class Solution {
public char firstUniqChar(String s) {
Map<Character, Boolean> dic = new LinkedHashMap<>();
char[] sc = s.toCharArray();
for(char c : sc)
dic.put(c, !dic.containsKey(c));
for(Map.Entry<Character, Boolean> d : dic.entrySet()){
if(d.getValue()) return d.getKey();
}
return ' ';
}
}
8.左旋转字符串(剑指)

public String LeftRotateString(String str,int n) {
StringBuilder string=new StringBuilder();
for(int i=n;i<n+str.length();i++){
char c = str.charAt(i%str.length()); //全部加n后求余,相当于最开头n个调到了末尾
string.append(c);
}
String str1=string.toString();
return str1;
}
9.翻转单词顺序(剑指)
思路
双指针重建字符,i和j分别指向单词头尾
class Solution {
public String reverseWords(String s) {
s = s.trim(); // 删除首尾空格
int j = s.length() - 1, i = j;
StringBuilder res = new StringBuilder();
while(i >= 0) {
while(i >= 0 && s.charAt(i) != ' ') i--; // 搜索首个空格
res.append(s.substring(i + 1, j + 1) + " "); // 添加单词,注意substring左闭右开
while(i >= 0 && s.charAt(i) == ' ') i--; // 跳过单词间空格
j = i; // j 指向下个单词的尾字符
}
return res.toString().trim(); // 转化为字符串,去掉头尾空格
}
}
10.圆圈中最后剩下的数字

思路
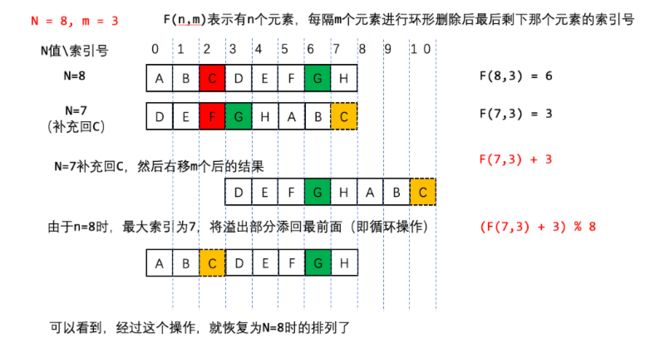
这一篇题解写的非常好。
比如删除了一次后,你知道最终留下来的数字在此时队列的位置,那么你就可以求出这个数字在删除前的位置。
删除操作将前面m个全都放到了队列末尾(不包括m,删掉了),新队列开头是原本的m+1。
此时将新队列下标+m,再对原本的长度n求余,即相当于把后面m个又放到了队列前,求出了删除前的位置。
如下图中,我知道了N=7时G的位置,那么就可以得出在N=8时G对应的位置(把后面m个补到前面)
class Solution {
public int lastRemaining(int n, int m) {
int tmp = 0;
for (int i = 2; i != n + 1; ++i) {
tmp = (m + tmp) % i;
}
return tmp;
}
}
总结
字符串题型整理完毕,其余类型
JAVA-高频面试题汇总:动态规划
JAVA-高频面试题汇总:二叉树(上)
JAVA-高频面试题汇总:二叉树(下)
JAVA-高频面试题汇总:回溯