老系统如何重构之最全总结
目录
1. 重构的概念
1.1 重构的定义
1.2 重构的分类
2 为什么重构
3 如何重构
3.1 说服业务方
3.2 确定重构的目标
3.3 老系统的熟悉与梳理
3.4 数据库的重构
3.5 前后端的系统重构
3.6 数据迁移与检查
3.7 系统检查联调测试
3.8 系统切换
1. 重构的概念
1.1 重构的定义
首先我们在多年的开发过程中,接触过也并参与过各种类型的重构,先不谈定义。
拿我们具体的案例来说,
1. 支付原来没有卡券功能的,后续加入了卡券逻辑,这算重构么?
2. 一个小系统原来是PHP开发的,后面全面升级到了java语言,这算重构么?
3.系统中一个模块的代码充斥着大量的IFelse,后面使用设计模式进行了改造, 这算重构么?
好,我们看下重构的定义:

前提是 不改变软件的外部行为,那上面例子中的第一条就被否定了,属于增加了新需求,改变了软件的外部行为。后面的第二、三条都属于重构,改变了内部的结构,而未改变外部的行为。
重构后使得代码更优雅,更易于维护、性能更高等。
1.2 重构的分类
重构分类可大致分为如下4大部分,
平台级、架构级、业务级、模块代码级,再实际重构工作中,4个部分并非完全割裂的,而可能会存在相互重叠的部分。
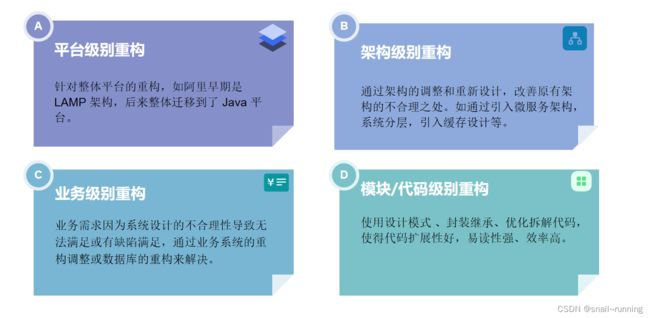
1.2.1 平台级-如很多平台最早使用的 LAMP - Linux Apache Mysql PHP 模式 - 更新成了 java平台 ,我们最早使用过一套Groovy语言开发系统 -也更新成了java
1.2.2 架构级-例如我们对单体服务的拆分- 或者为提升系统性能引入缓存设计,比如我们之前的一个单体服务-拆分成 dubbo微服务的架构模式
1.2.3 业务级-业务升级过程中会存在一些瓶颈导致迭代困难,-可以重新考虑设计底层的数据结构或业务模式,例如我们最近上线的商户档案的一个重构,本来系统中是存在 商户和代理两个主体概念,老系统却把 商户和代理耦合到一个表中,这次重构
进行了拆分。通过表进行关联。
1.2.4 代码级- 针对不合理的地方引入设计模式等进行升级拓展,-比如之前我接触过的一段路由算法,有几十个ifelse判断,最终得出路由的结果,每次升级这块都提心吊胆,后来升级使用责任链模式,在去迭代就清晰很多了。
2 为什么重构
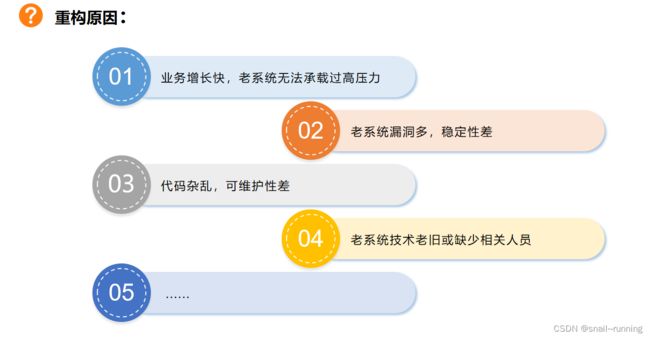
重构的原因多种多样,但不外乎这几个:
1、业务增长太快了,老系统之前的设计无法承载过高的压力,亟需重构解决
2、系统稳定性差,漏洞很多,有时候经常要靠重启解决
3、经过多年的发展,充斥着大量的不合理的代码,杂乱,难以维护
4、老系统使用的语言无人维护了
5、业务需求满足起来很困难或无法满足
等等
3 如何重构
如何进行是一个比较大的话题了,我们从如下几个步骤来说
3.1 说服业务方
其实业务最关注的是什么时候上线他们的新需求,什么时候可以开展新业务,而会觉得系统内部的改造和他们没啥关系,一般不会由他们来推动进行系统重构的。
而重构又会耗费大量的人力物力,以及时间,还有可能导致现在的业务迭代暂停,影响业务的开展。所以,我们需要极力的说服业务,陈述利弊。
不去重构有可能导致系统瘫痪,需求迭代慢,等,
而重构的好处就太多了
例如 1.可以提升系统的三高、高并发、高可用、高性能 2. 趁着重构的过程 可以优先现有不合理的业务流程 3. 重构完成后非常快的满足新的业务诉求

3.2 确定重构的目标
本次重构达成的最终目的是什么?引入合理架构,?微服务拆分?优化代码?达到更高的性能?等

3.3 老系统的熟悉与梳理
重构是基于老系统,而不能脱离老系统,这就需要对老系统了如指掌,特别是关键的环节步骤不能有任何差错。
知己知彼,百战不殆。 1、先收集所有老系统的资料 2、分类整理 ,梳理业务线流程 3、关键的流程或缺失资料的流程,review 老代码 4、老系统的坑,疑难点等和相关人员、沟通记录。

3.4 数据库的重构
首先我们要熟悉老系统的数据库中不合理之处,该拆的表没拆,该合的表没合,不合理的字段、等
新系统数据库设计考虑范式,若数据量过大,分库分表等。

3.5 前后端的系统重构
首先最核心的还是设计,设计文档应参与多轮评审,并反复和大家宣贯,避免存在盲区或模糊的地方。
开发阶段可以采用迭代模式针对相对独立的模块 进行 开发-自测-Review-测试
3.6 数据迁移与检查
新系统开发好,避免不了要处理 老系统存储的数据,这就涉及到了老系统的数据迁移
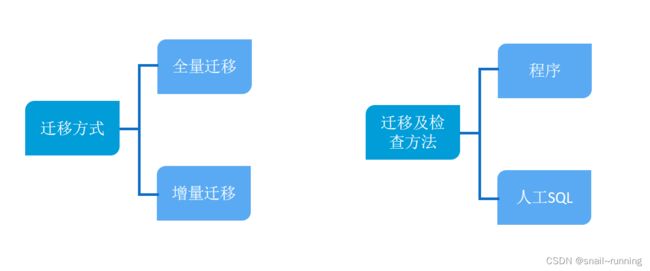
迁移方式可以全量迁移-增量迁移。 而迁移方式又和切换方案关联比较强- 如果我们选择直接切换,老系统停机,就可以使用全量迁移即可。
若新老系统并行,就会存在 全量迁移历史终态数据,再增量迁移变化数据。
迁移以及校验的方式:可以依据具体情况使用系统或手工SQL的方式。
3.7 系统检查联调测试
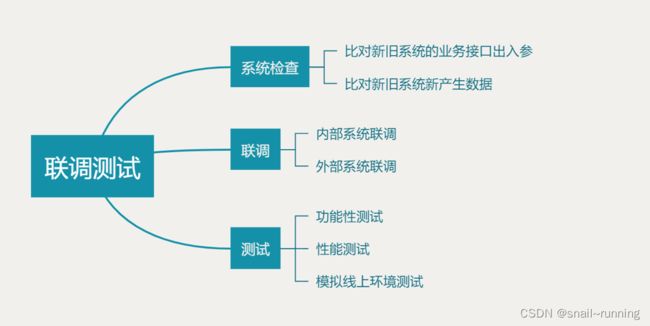
1. 系统检查- 会比对 出入参,新产生的数据
2、重构后的系统,存在内部之间微服务 相关的接口调用,进行联调。 与外部系统之间相互调用,进行联调。并要约定好上线及切换时间。
3、测试,从功能性、性能等方面。最核心的还是要比较新系统与老系统的差异
稍后我们引入一个流量回放的工具。
3.7.1 重点介绍下,测试阶段-流量回放的工具使用。
流量回放的概念是 :测试数据不再由人为制造,而是直接复制线上的流量数据,将复制好的部分流量打到被测集群中,相当于线上流量在测试环境的一次重放。
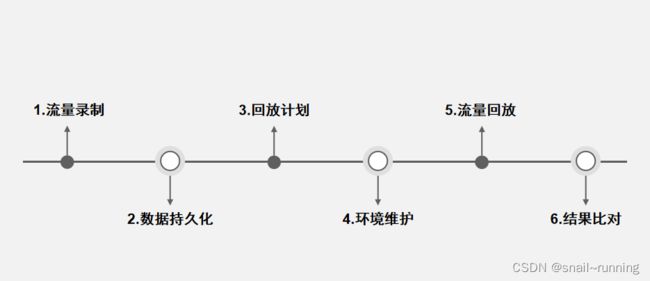
流量回放的步骤-
1. 针对生产需要测试的接口 ,进行流量的录制,数据收集。接口出入参等信息
2、将收集的数据进行持久化存储,可以使用数据库或其他缓存工具
3、制订回放计划,什么时候 回放哪些接口,等
4、将回放环境维护,相应的基础数据与生产保持一致,调用第三方的,无法模拟的,可选用mock
5、回放流量
6、对比生产结果和回放结果,哪些是合理的差异,哪些是异常的差异。
3.7.2 流量回放工具的选择
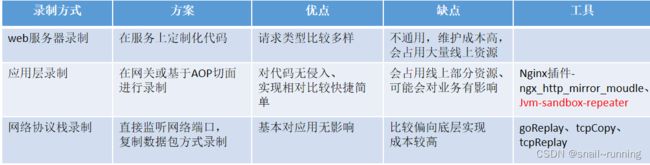
1、web服务,自定义开发,例如 账户重构,可以相关接口开发AOP切面,将接口流量引出一份到新系统,根据新系统产生的结果,与老系统产生的结果进行比对,
2、预留资源, 单体服务-TCPCopy 适用些 复杂分布式服务-适用 Jvm-sandbox-repeater
3.7.3 Jvm-sandbox-repeater
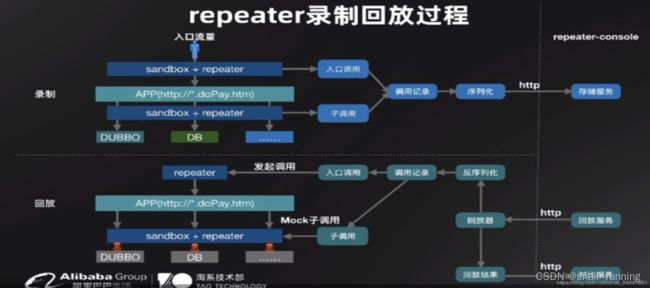
3.7.4 Console
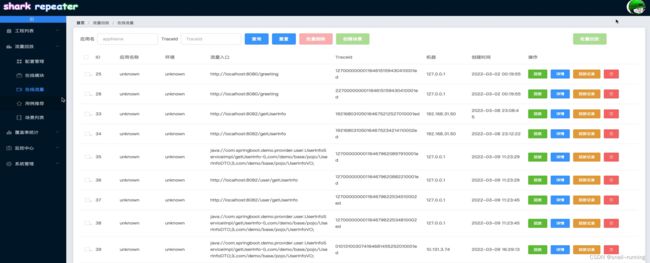
3.8 系统切换
3.8.1 使用流量切换方式 系统切换阶段,可以使用流量逐批切换的方案。
1.1首先要确定好切换的业务主体维度,例如根据用户的地域,或活跃度等计算出的 用户ID,根据商户沟通程度,业务量大小等计算出的商户ID,规划好主体ID切换批次。
1.2根据选定好的主体ID ,老系统进行白名单配置,新系统进行流量切换
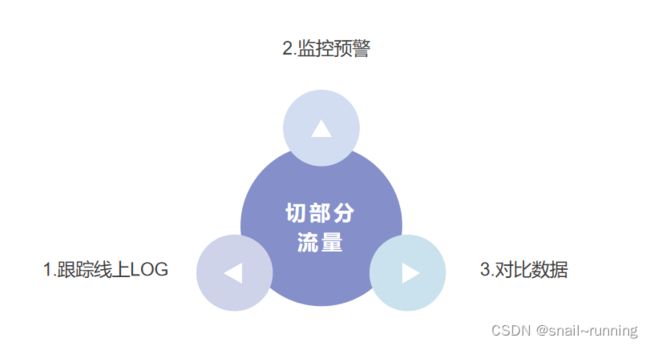
1.3 持续跟踪线上日志,可以针对相关接口进行新老系统的出入参对比
1.4 对错误日志,及异常数据等进行监控并预警到相应的人员
1.5 针对切入新系统流量产生的数据,可以与老系统之前的数据进行比对,看有无出入。
3.8.2 使用全量切换方式
2.1 首先确定好系统切换方案,-是使用直接的全部流量切换, 还是小批次验证后再进行全量切换,还是将之前的批次切换分成具体多少批切换完成。包括切换的时间,参与的人员,验证的步骤,拉出清单,并在测试环境进行模拟演练。
2.2 提前确定好回滚方案- 若流量全部切换完成,发现生产问题并无法及时处理,需要及时进行回滚。 包括回滚的内容,数据,系统,顺序,各参与人的职责,回滚后的数据验证,是否有后遗症。并在测试环境进行模拟演练。
2.3 切换后生产系统验证无误,核心逻辑正常运转,无异常数据,标志着 系统切换完成。若存在一些非核心的小问题,历史债,及时排期修复,并做好系统监控,保证新系统的平稳运行。