Mysql提升篇
关联查询
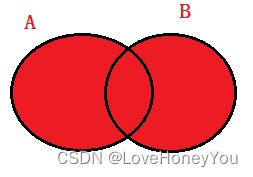
内连接:A∩B
select <字段列表> from A inner join B on A.关联字段 = B.关联字段;
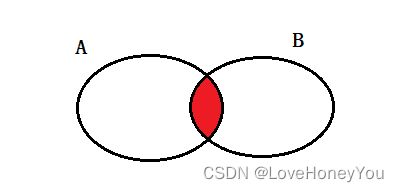
外连接:A / B
select <字段列表> from A left join B on A.关联字段 = B.关联字段;

select <字段列表> from A right join B on A.关联字段 = B.关联字段;
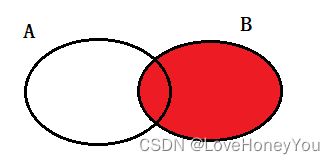
A U B
select <字段列表> from A left join B on A.关联字段 = B.关联字段
union
select <字段列表> from A right join B on A.关联字段 = B.关联字段
//union默认去重,all union表示显示所有重复值
A - A∩B
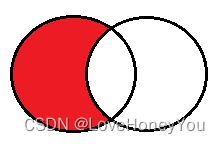
select <字段列表> from A left join B on A.关联字段 = B.关联字段
where 字段字段 is NULL
B - A∩B
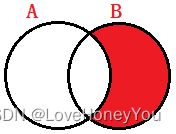
select <字段列表> from A right join B on A.关联字段 = B.关联字段
where 字段字段 is NULL
A∪B - A∩B
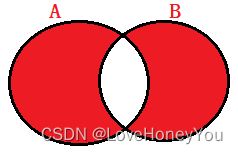
select <字段列表> from A left join B on A.关联字段 = B.关联字段
where 字段字段 is NULL
union
select <字段列表> from A right join B on A.关联字段 = B.关联字段
where 字段字段 is NULL
自连接:物理上一张表,逻辑上两张表
内连接查询:区分大表和小表,按照数量来区分,小表永远是整表扫描,然后去大表搜索
对于内连接而言,过滤条件写在where后面 和 on 连接条件里面,效果是一样的
select 7大子句
1)from:从哪些表中筛选
2)on: 关联多表查询,去除笛卡尔积
3)where:从表中筛选
4)group by:分组依据
5)having:在统计结果中筛选(with rollup)
6)order by:排序
7)limit:分页
group by
1.合计,with rollup,加在group by后面,合计总数
select did,count(*) from t_employee group by did with rollup;
2.分组统计时,select 后面只写和分组统计有关的字段,其他无关字段不要出现
having
having子句也写条件,where条件是针对原表中的记录的筛选,where后不能加分组函数
having子句是对统计结果的筛选,可以加分组函数
order by
默认:升序
asc:代表升序
desc:代表降序
limit m n
m = (page - 1)*n
每页5条数据,显示第8页
limit 35 5;
子查询
select的select中嵌套子查询
SELECT did,AVG(salary),
AVG(salary)-(SELECT AVG(salary) FROM t_employee)
FROM t_employee
GROUP BY did;select的where中嵌套子查询
SELECT ename,salary
FROM t_employee
WHERE salary > (SELECT AVG(salary) FROM t_employee) AND gender = '男';select的having中嵌套子查询
SELECT t_department.did,dname,AVG(salary)
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
GROUP BY t_department.did
HAVING AVG(salary) >(SELECT AVG(salary) FROM t_employee)
ORDER BY AVG(salary);select的from中嵌套子查询
SELECT t_department.did ,dname,AVG(salary)
FROM t_department LEFT JOIN (SELECT did,AVG(salary) FROM t_employee GROUP BY did) temp
ON t_department.did = temp.did;一个查询还是多行多列的结果,那么就可以把这个查询结果当成一张临时表,
放在from后面进行再次筛选