大数据——Hive基础
Hive基础
- 什么是Hive
- Hive的优势和特点
- Hive的发展里程碑和主流版本
- Hive与MapReduce
- Hive的基本架构
-
- Hive元数据管理
- Hive体系架构
- Hive操作
-
- Hive Interface-命令窗口模式(1)
- Hive Interface-命令窗口模式(2)
- Hive工具操作
- Hive Interface-其他使用环境
- Hive数据类型
-
- 原始类型
- 复杂数据类型
- Hive元数据结构
-
- 数据库(Database)
- 数据表(Tables)
-
- Hive建表语句
-
- 示例
- Hive建表-分隔符
- Hive建表-Storage SerDe
- Hive建表高阶语句-CTAS and WITH
-
- 示例
- 创建临时表
- 表操作-删除/修改表
-
- 示例
- Hive分区(Partition)
-
- Hive分区操作-定义分区
-
- 示例
- Hive分区操作-动态分区
-
- 示例
- 分桶(Buckets)
-
- 分桶抽样(Sampling)
-
- 示例
- Hive视图(Views)
-
- Hive视图操作
-
- 示例
- Hive侧视图(Lateral View)
-
- 示例
什么是Hive
基于Hadoop的数据仓库解决方案
- 将结构化的数据文件映射为数据库表
- 提供类sql的查询语句HQL(Hive Query Language)
- Hive让更多的人使用Hadoop
Hive成为Apache顶级项目 - Hive始于2007年的Facebook
- 官网:Hive官网

Hive的优势和特点
- 提供了一个简单的优化模型
- HQL类SQL语法,简化MapReduce开发
- 支持在不同的计算框架上运行
- 支持在HDFS和Hbase上临时查询数据
- 支持用户自定义函数、格式
- 成熟的JDBC和ODBC驱动程序,用于ETL(可视化的数据处理)和BI(数据智能)
- 稳定可靠(真实生产环境)的批处理
- 有庞大活跃的社区
Hive的发展里程碑和主流版本
Hive发展历史及版本
- 07年8月——始于Facebook
- 13年5月——0.11 Stinger Phase 1 ORC HiveServe2
- 13年10月——0.12.0 Stinger Phase 2-ORC improvement
- 14年4月——Hive 0.13.0 as Stinger Phase 3
- 14年11月——Hive 0.14.0
- 15年2月——Hive 1.0.0
- 15年5月——Hive 1.2.0(1.2.1重点版本)
- 16年2月——Hive 2.0.0(添加HPLSQL,LLAP)
- 16年6月——Hive 2.1.0(2.1.0补充版本)
Hive与MapReduce
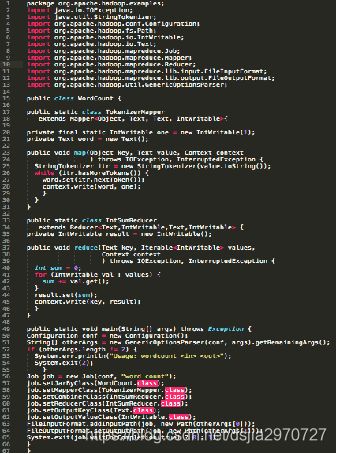
MapReduce执行效率更快
Hive开发效率更快
Hive的基本架构
Hive元数据管理
记录数据仓库中模型的定义、各层级间的映射关系
存储在关系数据库中
-
默认Derby,轻量级内嵌SQL数据库
Derby非常适合测试和演示 存储在.merastore_db目录中 -
实际生产一般存储在MySQL中
修改配置文件hive-site.xml
HCatalog
- 将Hive元数据共享给其他应用程序
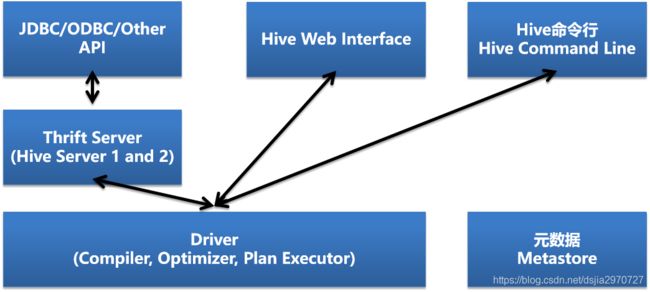
Hive体系架构
Hive操作
Hive Interface-命令窗口模式(1)
- 有两种工具:Beeline和Hive命令行(CLI)
- 有两种模式:命令模式和交互模式
- 命令行模式
| 操作 | HiveServer2 Beeline | HiveServer1 CLI |
|---|---|---|
| Server Connection | beeline -u |
hive -h |
| Help | beeline -h or beeline --help | hive -H |
| Run Query | beeline -e |
hive -e |
| Define Variable | beeline --hivevar key=value | hive --hivevar=value |
Hive Interface-命令窗口模式(2)
交互模式
| 操作 | HiveServer2 Beeline | HiveServer1 CLI |
|---|---|---|
| Enter Mode | beeline | hive |
| Connect | !connect |
N/A |
| List Tables | !table | show tables; |
| List Columns | !column |
desc table_name; |
| Save Result | !record |
N/A |
| Run Shell CMD | !sh ls | !ls; |
| Run DFS CMD | dfs -ls | dfs -ls |
| Run SQL File | !run |
source |
| Check Version | !dbinfo | !hive --version; |
| Quit Mode | !quit | quit; |
Hive工具操作
检查Hive服务是否已经正常启动
使用Hive交互方式(输入hive即可)
- hive
使用beeline
- 需启动HiveServer2服务
nohup hive --service metastore &(非必须)
nohup hive --service hiveserver2 &
- 输入beeline进入beeline交互模式
!connect jdbc:hive2://hadoop101:10000
- 或先启动HiveServer2服务,直接使用以下命令
beeline -u "jdbc:hive2://localhost:10000/default"
Hive Interface-其他使用环境
Hive Web Interface(As part of Apache Hive)
Hue(Cloudera)
Ambari Hive View(Hortonworks)
JDBC/ODBC(ETL工具,商业智能工具,集成开发环境)
- Information,Talend等
- Tableau,QlikView,Zeppelin等
- Oracle SQL Developer,DB Visualizer等
Hive数据类型
原始类型
类似于SQL数据类型
| 类型 | 示例 |
|---|---|
| TINYINt | 10Y |
| INT | 10 |
| FLOAT | 1.342 |
| DECIMAL | 3.14 |
| BOOLEAN | TRUE |
| CHAR | ‘YES’ or “YES” |
| DATE | ‘2013-01-31’ |
| SMALLINT | 10S |
| BIGINT | 100L |
| DOUBLE | 1.234 |
| BINARY | 1010 |
| STRING | ‘Book’ or “Book” |
| VARCHAR | ‘Book’ or “Book” |
| TIMESTAMP | ‘2013-01-31 00:13:00:345’ |
复杂数据类型
ARRAY:存储的数据为相同类型
MAP:具有相同类型的键值对
STRUCT:封装了一组字段
| 类型 | 格式 | 定义 | 示例 |
|---|---|---|---|
| ARRAY | [‘Apple’,’Orange’,’Mongo’] | ARRAY | a[0] = ‘Apple’ |
| MAP | {‘A’:’Apple’,’O’:’Orange’} | MAP |
b[‘A’] = ‘Apple’ |
| STRUCT | {‘Apple’, 2} | STRUCT |
c.weight = 2 |
Hive元数据结构
| 数据结构 | 描述 | 逻辑关系 | 物理存储(HDFS) |
|---|---|---|---|
| Database | 数据库 | 表的集合 | 文件夹 |
| Table | 表 | 行数据的集合 | 文件夹 |
| Partition | 分区 | 用于分割数据 | 文件夹 |
| Buckets | 分桶 | 用于分布数据 | 文件 |
| Row | 行 | 行记录 | 文件中的行 |
| Columns | 列 | 列记录 | 每行中指定的位置 |
| Views | 视图 | 逻辑概念,可跨越多张表 | 不存储数据 |
| Index | 索引 | 记录统计数据信息 | 文件夹 |
数据库(Database)
表的集合,HDFS中表现为一个文件夹
- 默认为在hive.metastore.warehouse.dir属性目录下
如果没有指定数据库,默认使用default数据库
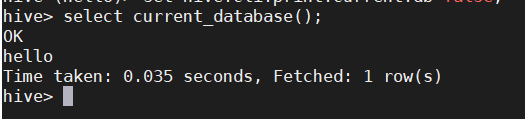
如何知道和显示的当前所在数据库
- 可以在hive命令行执行以下语句显示当前数据库:
select current_database();
- 可以在设置显示当前所在的数据库。
#设置前
hive> use hello;
OK
Time taken: 0.102 seconds
hive>
# 设置后
hive> set hive.cli.print.current.db=true;
hive (hello)>
# 恢复设置前
hive (hello)> set hive.cli.print.current.db=false;
hive>
- 查看数据库
hive> show databases;

- 创建数据库
hive> create database testhive2;

- 使用数据库
hive> use testhive;

数据表(Tables)
分为内部表和外部表
内部表(管理表)
- HDFS中为所属数据库目录下的子文件夹
- 数据完全由Hive管理,删除表(元数据)会删除数据
外部表(External Tables)
- 数据保存在指定位置的HDFS路径中
- Hive不完全管理数据,删除表(元数据)不会删除数据
Hive建表语句
//if not exists可选,如果表存在,则忽略
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external (
//列出所有列和数据类型
name string,
work_place ARRAY<string>,
sex_age STRUCT<sex:string,age:int>,
skills_score MAP<string,int>,
depart_title MAP<STRING,ARRAY<STRING>>
)
//comment可选
COMMENT 'This is an external table'
ROW FORMAT DELIMITED
//如何分隔列(字符)
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY ','
//如何分隔集合和映射
MAP KEYS TERMINATED BY ':'
//文件存储格式
STORED AS TEXTFILE
//文件存储路径(HDFS)
LOCATION '/user/root/employee';
示例
- employee.txt
Michael|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead
Will|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shelley|New York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|Vancouver|Female,57|Sales:89|Sales:Lead
- employee_id.txt
Michael|100|Montreal,Toronto|Male,30|DB:80|Product:DeveloperLead
Will|101|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Steven|102|New York|Female,27|Python:80|Test:Lead,COE:Architect
Lucy|103|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Mike|104|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shelley|105|New York|Female,27|Python:80|Test:Lead,COE:Architect
Luly|106|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Lily|107|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Shell|108|New York|Female,27|Python:80|Test:Lead,COE:Architect
Mich|109|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dayong|110|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Sara|111|New York|Female,27|Python:80|Test:Lead,COE:Architect
Roman|112|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Christine|113|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Eman|114|New York|Female,27|Python:80|Test:Lead,COE:Architect
Alex|115|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Alan|116|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Andy|117|New York|Female,27|Python:80|Test:Lead,COE:Architect
Ryan|118|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Rome|119|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Lym|120|New York|Female,27|Python:80|Test:Lead,COE:Architect
Linm|121|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
Dach|122|Montreal|Male,35|Perl:85|Product:Lead,Test:Lead
Ilon|123|New York|Female,27|Python:80|Test:Lead,COE:Architect
Elaine|124|Vancouver|Female,57|Sales:89,HR:94|Sales:Lead
- employee_hr.txt
Matias McGrirl|1|945-639-8596|2011-11-24
Gabriela Feldheim|2|706-232-4166|2017-12-16
Billy O'Driscoll|3|660-841-7326|2017-02-17
Kevina Rawet|4|955-643-0317|2012-01-05
Patty Entreis|5|571-792-2285|2013-06-11
Claudetta Sanderson|6|350-766-4559|2016-11-04
Bentley Oddie|7|446-519-0975|2016-05-02
Theressa Dowker|8|864-330-9976|2012-09-26
Jenica Belcham|9|347-248-4379|2011-05-02
Reube Preskett|10|918-740-2357|2015-03-26
Mary Skeldon|11|361-159-8710|2016-03-09
Ethelred Divisek|12|995-145-7392|2016-10-18
Field McGraith|13|149-133-9607|2015-10-06
Andeee Wiskar|14|315-207-5431|2012-05-10
Lloyd Nayshe|15|366-495-5398|2014-06-28
Mike Luipold|16|692-803-9373|2011-05-14
Tallie Swaine|17|570-709-6561|2011-08-06
Worth Ledbetter|18|905-586-2348|2012-09-25
Reine Leyborne|19|322-644-5798|2015-01-05
Norby Bellson|20|736-881-5785|2012-12-31
Nellie Jewar|21|551-505-3957|2017-06-18
Hoebart Deeth|22|780-240-0213|2011-09-19
Shel Haddrill|23|623-169-5495|2014-02-04
Christalle Cervantes|24|275-309-7794|2017-01-01
Dorita Miche|25|476-242-9769|2014-10-26
Conny Bowmen|26|398-181-4961|2011-10-21
Sabra O' Donohoe|27|327-773-8515|2015-01-28
Rahal Ashbe|28|561-777-0202|2012-12-13
Tye Greenstreet|29|499-510-1700|2012-01-17
Gordy Cristoforetti|30|955-110-7073|2015-10-09
Marsha Sharkey|31|221-696-5744|2017-01-29
Corbie Cruden|32|979-583-4252|2011-08-20
Anya Easen|33|428-602-5117|2011-08-16
Clea Brereton|34|909-198-4992|2018-01-08
Kimberley Pinnijar|35|608-177-4402|2015-06-03
Wilma Mackriell|36|637-304-3580|2012-06-23
Mitzi Gorman|37|134-675-2460|2017-07-16
Ashlin Rennick|38|816-635-9974|2014-04-20
Whitaker Shedd|39|614-792-6663|2016-05-19
Mandi Stronack|40|753-688-2327|2016-04-24
Niki Driffield|41|225-867-0712|2014-02-15
Regine Agirre|42|784-395-9982|2017-05-01
Evelina Craddy|43|274-850-6569|2017-06-14
Yasmin Ubsdall|44|679-739-9660|2012-03-10
Vivianna Shoreman|45|873-271-7100|2014-09-06
Chance Murra|46|248-160-3759|2017-12-31
Ferdy Adriano|47|735-447-2642|2013-11-11
Nikolos Tichner|48|869-871-9057|2014-02-15
Doro Rushman|49|861-337-3364|2011-08-27
Lela Hinzer|50|147-386-3735|2011-06-03
Hoyt Winspar|51|120-561-6266|2016-05-05
Vicki Rimington|52|257-204-8227|2014-11-21
Louis Dalwood|53|735-885-8087|2014-02-17
Joseph Zohrer|54|178-152-4726|2015-11-04
Kennett Senussi|55|182-904-2652|2017-05-20
Letta Musk|56|534-353-2038|2013-11-04
Giulietta Glentz|57|761-390-2806|2011-09-08
Wright Frostdyke|58|932-838-9710|2015-07-15
Bat Hannay|59|404-841-2981|2015-04-04
Devlen Hutsby|60|830-520-6401|2015-07-12
Lynnea Bembrigg|61|408-264-4116|2013-02-24
Udall Nelle|62|485-420-4327|2011-07-01
Kyle Matheson|63|153-149-2140|2011-07-03
Jarid Sprowell|64|848-408-9569|2017-11-08
Jeanie Griffitt|65|442-599-1231|2018-03-09
Joana Sleith|66|264-979-0388|2017-02-13
Doris Ilyushkin|67|877-472-3918|2015-08-03
Michaelina Rennels|68|949-522-9333|2012-07-05
Onofredo Butchard|69|392-833-3926|2017-11-05
Beatrice Amis|70|963-487-6585|2015-01-24
Joyan O'Hanlon|71|952-969-7279|2017-09-22
Mikaela Cardoo|72|960-275-3958|2015-01-24
Lori Dale|73|530-116-2773|2017-07-05
Stevena Roloff|74|241-314-8328|2015-12-21
Fayth Carayol|75|907-502-3752|2012-12-04
Carita Bruun|76|117-771-8056|2017-05-31
Darnell Hardwell|77|718-247-8505|2012-05-09
Jonathon Grealy|78|136-515-3637|2014-03-29
Laurice Rosini|79|352-594-3238|2017-02-15
Emelia Auten|80|311-899-1782|2014-09-10
Trace Fontelles|81|414-607-8366|2016-03-09
Hope Sket|82|461-595-7667|2017-09-30
Cilka Heijne|83|772-704-7366|2011-08-27
Maurise Gallico|84|546-158-7983|2011-12-21
Casey Greenfield|85|204-108-7707|2012-03-18
Wes Jaffrey|86|848-465-5131|2016-02-14
Jilly Eisikowitz|87|431-355-2777|2017-02-18
Auguste Kobel|88|562-494-1360|2012-02-29
Zackariah Pietrusiak|89|810-738-9846|2012-02-25
Pearline Marcq|90|200-835-9497|2016-02-10
Sayre Osbaldeston|91|340-132-2361|2011-11-30
Floyd Cano|92|133-768-6535|2016-02-27
Ciro Arendt|93|792-967-0588|2015-11-07
Auguste Kares|94|230-184-3438|2014-03-13
Skipp Spurden|95|747-133-1382|2012-03-15
Alyssa Prydden|96|963-170-0545|2014-11-07
Orlando Pallatina|97|354-125-1208|2012-07-12
Zoe Adacot|98|704-987-0702|2015-09-29
Blaine Fawdry|99|477-109-9014|2012-07-14
Cleon Haresnape|100|625-338-3965|2014-12-04
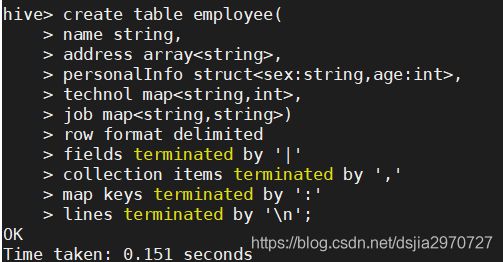
- 建表employee
create table employee(
name string,
address array<string>,
personalInfo struct<sex:string,age:int>
technol map<string,int>,
job map<string,string>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
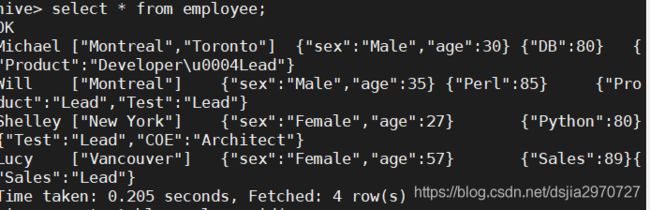
- 查询表employee数据
hive> select * from employee;
- 建表employee_id
create table employee_id(
name string,
id int,
address array<string>,
`info` struct<sex:string,age:int>,
technol map<string,int>,
jobs map<string,string>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
- 查询表employee_id数据
hive> select * from employee_id;
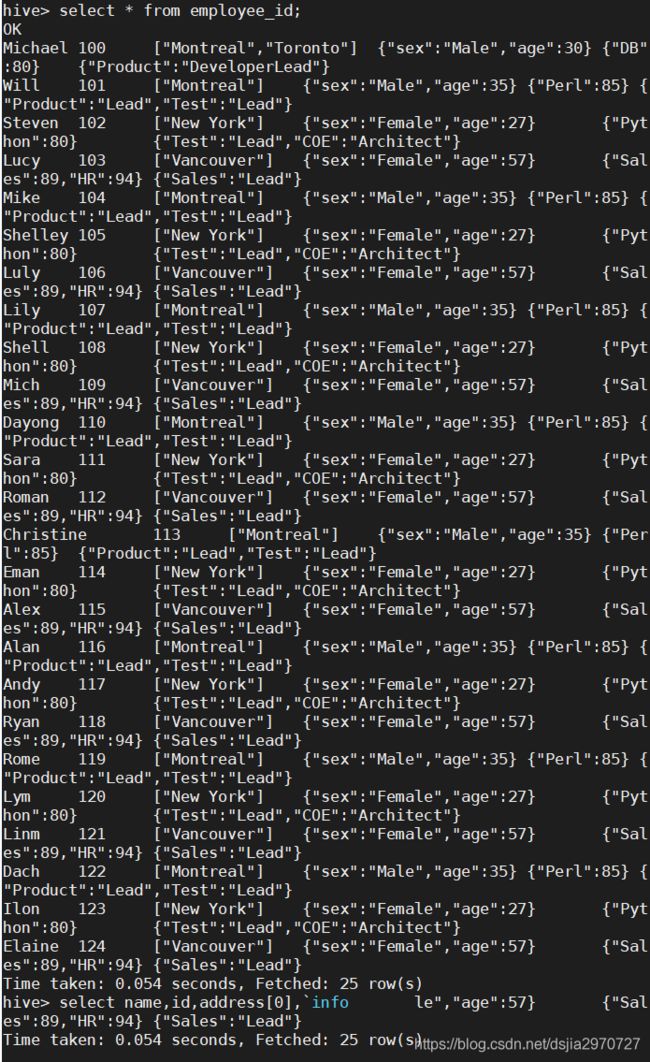
- 查询表具体字段数据
hive> select name,id,address[0],`info`.sex,`info`.age,jobs["Sales"] from employee_id;
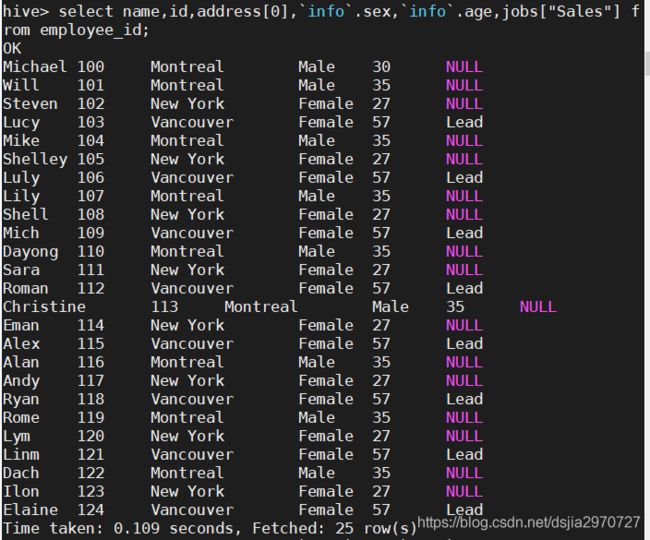
- 查询表具体字段数据去掉NULL值
hive> select name,id,address[0],`info`.sex,`info`.age,jobs["Sales"] from employee_id where jobs["Sales"] is not null;
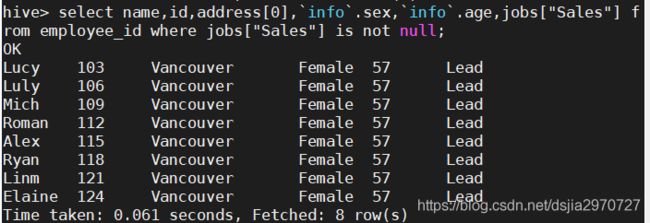
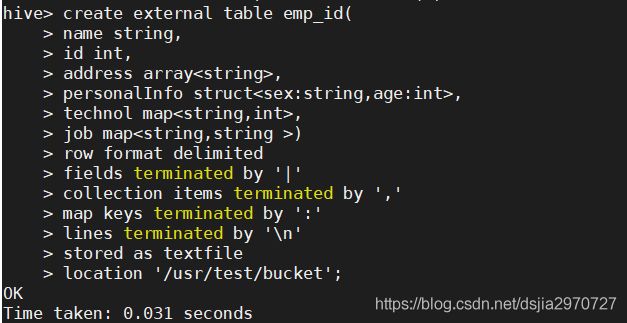
- 创建外部表
create external table emp_id(
name string,
id int,
address array<string>,
personalInfo struct<sex:string,age:int>,
technol map<string,int>,
job map<string,string >)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
location '/usr/test/bucket';
Hive建表-分隔符
Hive中默认分隔符
- 字段:Ctrl+A或^A(\001)
- 集合:Ctrl+B或^B(\002)
- 映射:Ctrl+C或^C(\003)
注意:
-
建表时指定分隔符只能用于非嵌套类型
-
嵌套类型由嵌套级别决定
数组中嵌套数组-外部数组时 ^B,内部数组是 ^C 映射中嵌套数组-外部映射是 ^C,内部数组时 ^D
Hive建表-Storage SerDe
SerDe:Serializer and Deseralizer
Hive支持不同类型的Storage SerDe
- LazySimpleSerDe: TEXTFILE
- BinarySerializerDeserializer: SEQUENCEFILE
- ColumnarSerDe: ORC, RCFILE
- ParquetHiveSerDe: PARQUET
- AvroSerDe: AVRO
- OpenCSVSerDe: for CST/TSV
- JSONSerDe
- RegExSerDe
- HBaseSerDe
CREATE TABLE my_table(a string, b string, ...)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = "\t",
"quoteChar" = "'",
"escapeChar" = "\\"
)
STORED AS TEXTFILE;
CREATE TABLE test_serde_hb(
id string,
name string,
sex string,
age string
)
ROW FORMAT SERDE
'org.apache.hadoop.hive.hbase.HBaseSerDe'
STORED BY
'org.apache.hadoop.hive.hbase. HBaseStorageHandler'
WITH SERDEPROPERTIES (
"hbase.columns.mapping"=
":key,info:name,info:sex,info:age"
) TBLPROPERTIES("hbase.table.name" = "test_serde");
Hive建表高阶语句-CTAS and WITH
CTAS-as select方式建表
CREATE TABLE ctas_employee as SELECT * FROM employee;
- CTAS不能创建partition,external,bucket table
CTE(CTAS with Comment Table Expression)
CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name = 'Michael'),
r2 AS (SELECT name FROM employee WHERE sex_age.sex= 'Male'),
r3 AS (SELECT name FROM employee WHERE sex_age.sex= 'Female')
SELECT * FROM r1 UNION ALL SELECT * FROM r3;
Like
CREATE TABLE employee_like LIKE employee;
示例
- 创建以employee_partition为基础的表
creat table tmp_employee as select * from employee_partition;
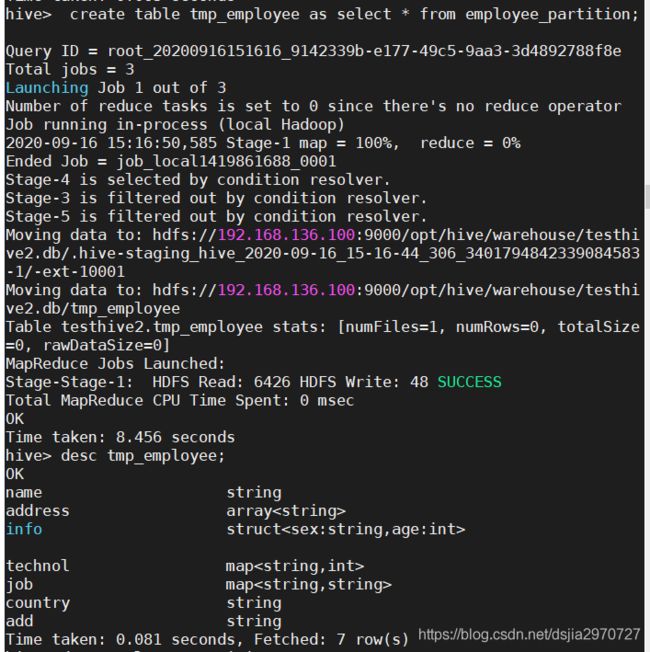
- CTE建表
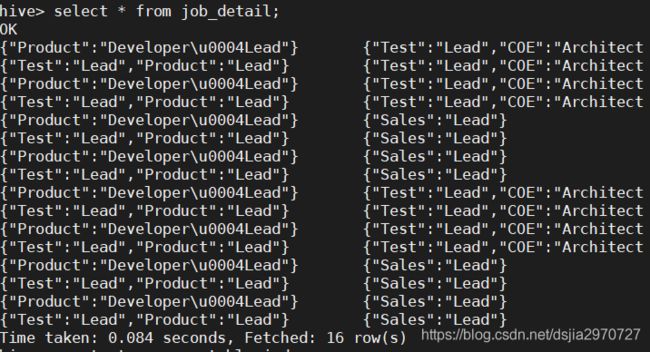
create table job_detail as
with
tmp as (select job from employee_partition where info.sex='Male')
t2 as (select job from employee_partition where info.sex='Female'
select tmp.job male_job,t2.job female_job from tmp,t2;
select * from job_detail;
创建临时表
临时表是应用程序自动管理在复杂查询期间生成的中间数据的方法
- 表只对当前session有效,session退出后自动删除
- 表空间位于/tmp/hive-
(安全考虑) - 如果创建的临时表表名已存在,实际用的是临时表
CREATE TEMPORARY TABLE tmp_table_name1 (c1 string);
CREATE TEMPORARY TABLE tmp_table_name2 AS..
CREATE TEMPORARY TABLE tmp_table_name3 LIKE..
表操作-删除/修改表
删除表
DROP TABLE IF EXISTS employee [With PERGE];
TRUNCATE TABLE employee; -- 清空表数据
//With PERGE直接删除(可选),否则就会放到.Trash目录
修改表(Alter针对元数据)
//修改表常用于数据备份
ALTER TABLE employee RENAME TO new_employee;
ALTER TABLE c_employee SET TBLPROPERTIES ('comment'='New name, comments');
ALTER TABLE employee_internal SET SERDEPROPERTIES ('field.delim' = '$’);
ALTER TABLE c_employee SET FILEFORMAT RCFILE; -- 修正表文件格式
-- 修改表的列操作
ALTER TABLE employee_internal CHANGE old_name new_name STRING; -- 修改列名
ALTER TABLE c_employee ADD COLUMNS (work string); -- 添加列
ALTER TABLE c_employee REPLACE COLUMNS (name string); -- 替换列
示例
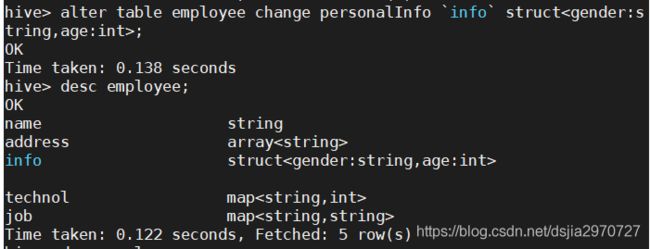
- 修改表
hive> alter table employee change personalInfo `info` struct<gender:string,age:int>;
hive> desc employee;
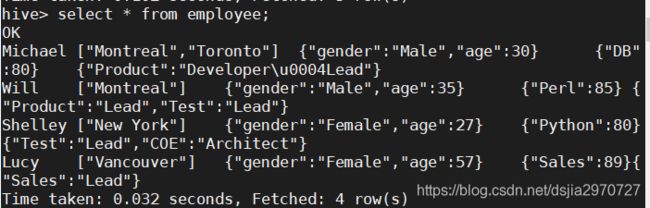
- 查看数据
hive> select * from employee;
Hive分区(Partition)
分区主要用于提供性能
- 分区列的值将表划分为segments(文件夹)
- 查询时使用“分区”列和常规列类似
- 查询时Hive自动过滤掉不用于提高性能的分区
分为静态分区和动态分区
Hive分区操作-定义分区
CREATE TABLE employee_partitioned(
//建表时定义分区
name string,
work_place ARRAY<string>,
sex_age STRUCT<sex:string,age:int>,
skills_score MAP<string,int>,
depart_title MAP<STRING,ARRAY<STRING>> )
//通过PARTITIONED BY定义分区
PARTITIONED BY (year INT, month INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':';
静态分区操作
//ALTER TABLE的方式添加静态分区
//ADD添加分区, DROP删除分区
ALTER TABLE employee_partitioned ADD
PARTITION (year=2019,month=3) PARTITION (year=2019,month=4);
ALTER TABLE employee_partitioned DROP PARTITION (year=2019, month=4);
示例
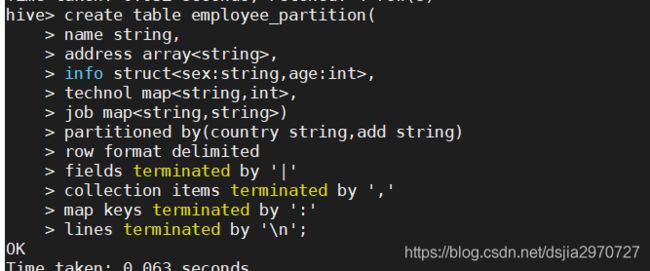
- 创建表时定义分区
create table employee_partition(
name string,
address array<string>,
info struct<sex:string,age:int>,
technol map<string,int>,
job map<string,string>)
partitioned by(country string,add string)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n';
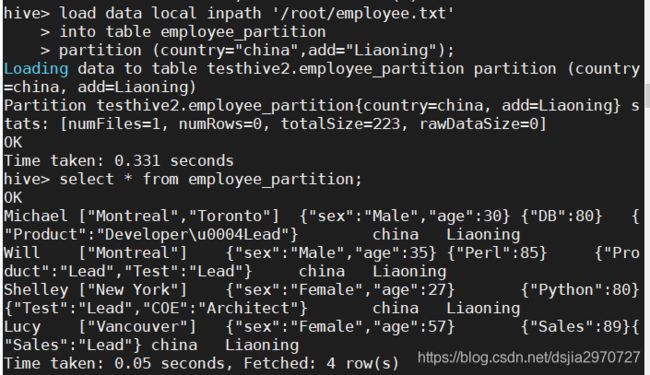
- 从本地添加分区
local data local inpath 'root/employee.txt'
into table employee_partition
partition (country="china",add="Liaoning");
select * from employee_partition;
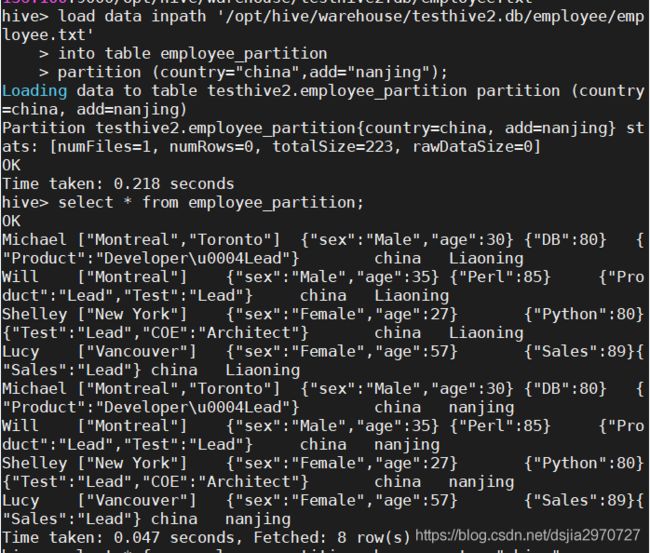
- 从hdfs端添加分区
local data inpath '/opt/hive/warehouse/testhive2.db/employee/employee.txt'
into table employee_partition
partition (country="china",add="nanjing");
select * from employee_partition;
- 动态分区
create table a_p(
aname string)
partitioned by(test string);
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition=nonstrict;
insert into a_p partition(test="abc") values("hello");
insert into a_p partition(test) select "def" aname,"sam" xxx;
select * from a_p;

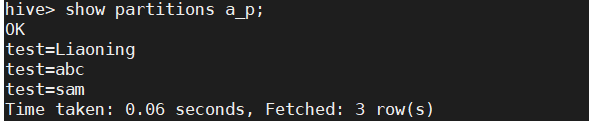
- 查看分区名
insert into a_p partition(test) select name aname,add from employpartition;
show partitions a_p;
- 添加分区名,删除分区名
alter table a_p add partition(test="123") partition(test="234");
alter table a_p drop partition(test="123"),partition(test="234");
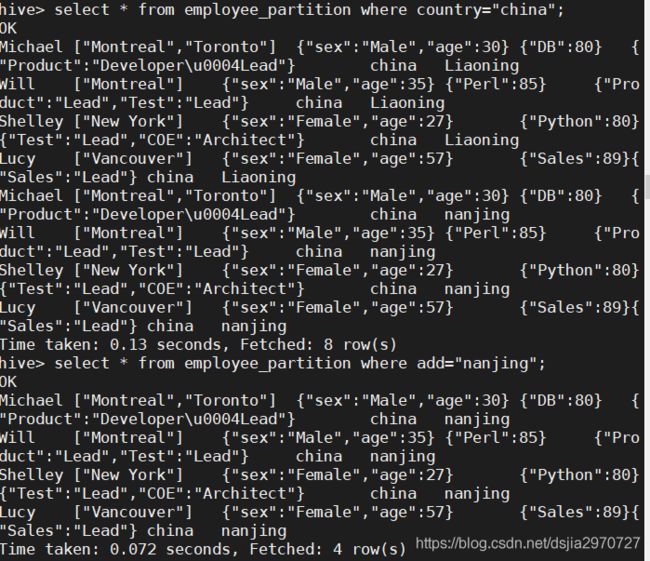
- 查询以分区为列的数据
select * from employee_partition where country="china";
select * from employee_partition where add="nanjing";
Hive分区操作-动态分区
使用动态分区需设定属性
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.modenonstrict;
动态分区设置方法
//insert方式添加动态分区
insert into table employee_partitioned partition(year, month)
select name,array('Toronto') as work_place,
named_struct("sex","male","age",30) as sex_age,
map("python",90) as skills_score,
map("r&d", array('developer')) as depart_title,
year(start_date) as year,month(start_date) as month
from employee_hr eh ;
示例
- 动态添加分区
//建表时定义分区
create table p_test(
pid int,
pname string)
partitioned by (person string)
row format delimited
fields terminated by ','
lines terminated by '\n';
//添加分区内容
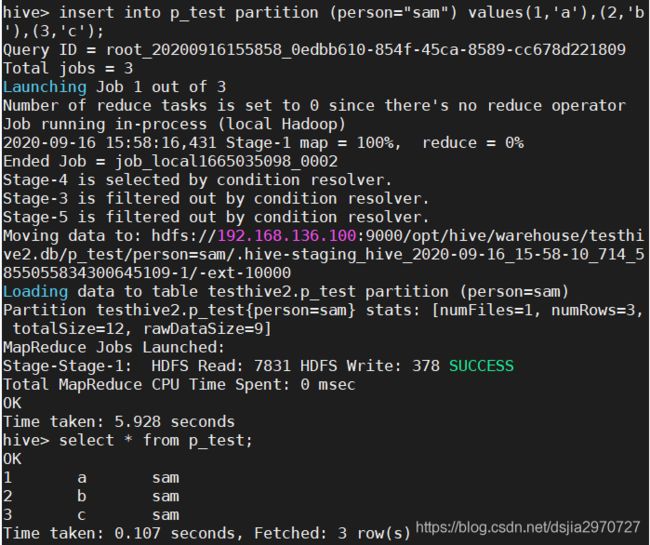
insert into p_test partition (person="sam") values(1,'a'),(2,'b'),(3,'c');
//查询数据
select * from p_test;
- 添加分区
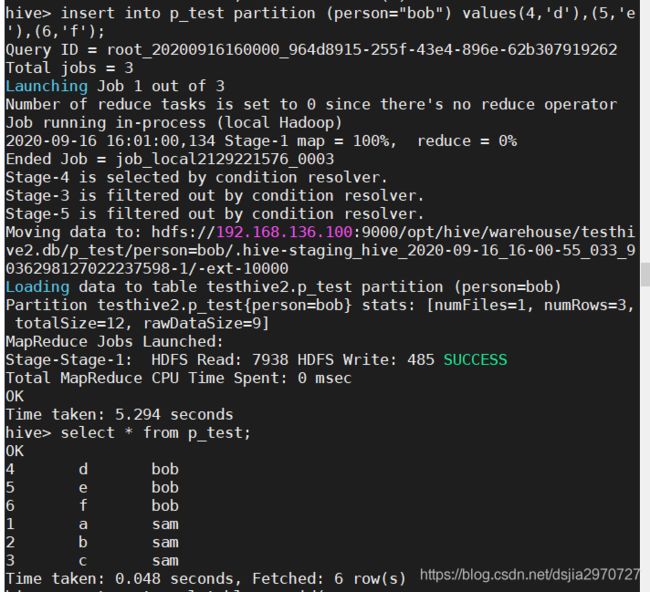
insert into p_test partition (person="bob") values(4,'d'),(5,'e'),(6,'f');
select * from p_test;
分桶(Buckets)
分桶对应于HDFS中的文件
- 更高的查询处理效率
- 使抽样(sampling)更高效
- 根据“桶列”的哈希函数将数据进行分桶
分桶只有动态分桶
SET hive.enforce.bucketing = true;
定义分桶
//分桶的列是表中已有的列
//分桶数最好是2的n次方
CLUSTERED BY (employee_id) INTO 2 BUCKETS
必须使用INSERT方式加载数据
分桶抽样(Sampling)
随机抽样基于整行数据
SELECT * FROM table_name TABLESAMPLE(BUCKET 3 OUT OF 32 ON rand()) s;
随机抽样基于指定列(使用分桶列更高效)
SELECT * FROM table_name TABLESAMPLE(BUCKET 3 OUT OF 32 ON id) s;
随机抽样基于block size
SELECT * FROM table_name TABLESAMPLE(10 PERCENT) s;
SELECT * FROM table_name TABLESAMPLE(1M) s;
SELECT * FROM table_name TABLESAMPLE(10 rows) s;
示例
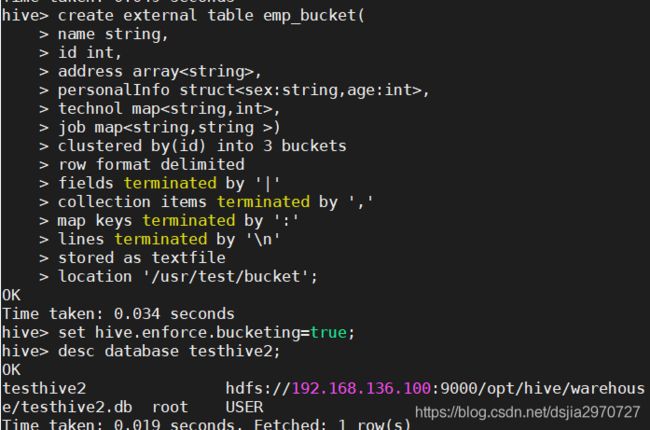
- 分桶建表
create external table emp_bucket(
name string,
id int,
address array<string>,
personalInfo struct<sex:string,age:int>,
technol map<string,int>,
job map<string,string >)
clustered by(id) into 3 buckets
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
lines terminated by '\n'
stored as textfile
location '/usr/test/bucket';
set hive.enforce.bucketing=true;
Hive视图(Views)
视图概述
- 通过隐藏子查询、连接和函数来简化查询的逻辑结构
- 虚拟表,从真实表中选取数据
- 只保存定义,不存储数据
- 如果删除或更改基础表,则查询视图将失败
- 视图是只读的,不能插入或装载数据
应用场景
- 将特定的列提供给用户,保护数据隐私
- 查询语句复杂的场景
Hive视图操作
视图操作命令:CREATE、SHOW、DROP、ALTER
CREATE VIEW view_name AS SELECT statement; -- 创建视图
-- 创建视图支持 CTE, ORDER BY, LIMIT, JOIN, etc.
SHOW TABLES; -- 查找视图 (SHOW VIEWS 在 hive v2.2.0之后)
SHOW CREATE TABLE view_name; -- 查看视图定义
DROP view_name; -- 删除视图
ALTER VIEW view_name SET TBLPROPERTIES ('comment' = 'This is a view');
--更改视图属性
ALTER VIEW view_name AS SELECT statement; -- 更改视图定义,
示例
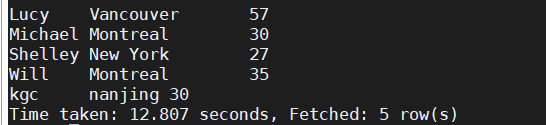
- 创建视图并查看
create view v_e_p as select distinct name,address[0],info.age from employee_partition e join a_p a on e.add=a.test;
select * from v_e_p;
Hive侧视图(Lateral View)
常与表生成函数结合使用,将函数的输入和输出连接
OUTER关键字:即使output为空也会生成结果
select name,work_place,loc from employee lateral view outer explode(split(null,',')) a as loc;
支持多层级
select name,wps,skill,score from employee
lateral view explode(work_place) work_place_single as wps
lateral view explode(skills_score) sks as skill,score;
通常用于规范或解析JSON
示例
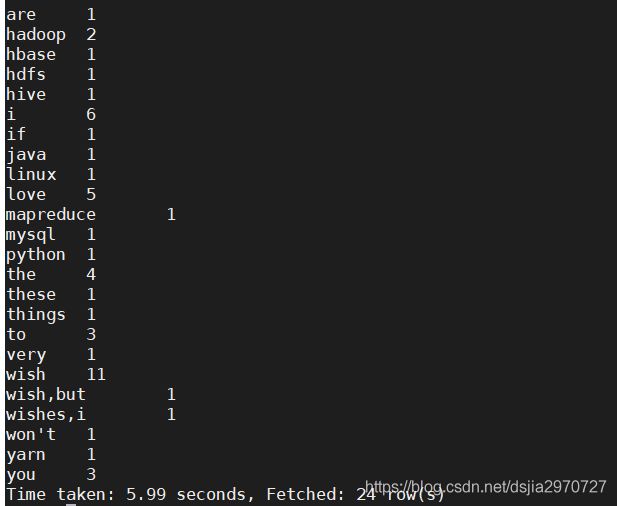
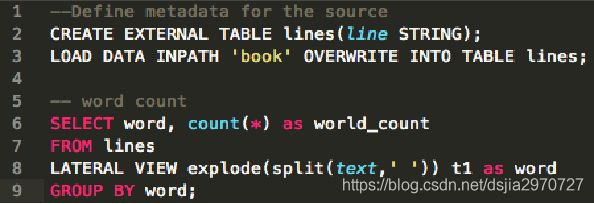
- 实现wordcount
//创建文件夹,并把数据放入文件夹中
[root@hadoop100 ~]# hdfs dfs -mkdir /wctest
[root@hadoop100 ~]# hdfs dfs -put a.txt /wctest
//创建外部表放入文件夹
create external table wctest(line string) stored as textfile location '/wctest';
select word,count(word) from wctest lateral view explode(split(line,' ')) a as word group by word;