关于Java中哈希结构的相关集合类总结
1. 概述
笔记主要记录HashMap & Hashtable & ConcurrentHashMap & HashSet & LinkedHashMap 等Java中有关哈希结构的相关集合类,主要目的是对相关集合有一个全局的了解。
两张图主要概括相关集合类的继承或实现关系,以及相关Hash键值对的使用。


Hashtable,HashMap,Properties继承关系如下:
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
public class HashMap<K,V>extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
Properties 类 继承了 Hashtable 类,而 Hashtable 类则继承Dictionary 类
TreeMap通过红黑树实现Map接口的类,key不可以为null,会报NullPointerException异常,value可以为null。
2. HashMap
HashMap(最常用的Map)。根据键的HashCode值存储数据,根据键可直接获取它的值,具有很快的访问速度。
底层数据结构:
HashMap (<=JDK1.7)数组+链表
HashMap (>=JDK1.8)数组+链表/红黑树 : 当链表长度大于等于8的时候链表会变成红黑树
TreeMap 红黑树
HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null不支持线程同步,即任一时刻可有多个线程同时写HashMap,可能会导致数据不一致。
如需同步,可用Collections的synchronizedMap方法使HashMap具有同步的能力或使用ConcurrentHashMap。
HashMap 的三种遍历方法
不支持用for-each 那种:的形式遍历 。
Map这个类没有继承Iterable接口所以不能直接通过map.iterator来遍历(list,set就是实现了这个接口,所以可以直接这样遍历),所以就只能先转化为set类型,用entrySet()方法,for-each编译时也是会转换为iterator。
Map.Entry是Map声明的一个内部接口,此接口为泛型,定义为Entry
Map提供了一些常用方法,如keySet()、entrySet()等方法。
entrySet() 返回 hashMap 中所有映射项的集合,即,键值对的集合。
keySet() 返回 hashMap 中所有 key 组成的集合。
values() 返回 hashMap 中存在的所有 value 值。
Map.Entry接口中有getKey(),getValue方法。
// 三种遍历
public void hmap() {
// HashMap
HashMap<String, String> m = new HashMap<String, String>();
// 三种遍历
// ctrl + 1 是快速补救办法快捷键
// 1.可以遍历Key, Value
Set<Entry<String, String>> entry = m.entrySet();
//entrySet() 返回 hashMap 中所有映射项的集合,即,键值对的集合
// Map 不能直接放在:后面进行遍历
for (Entry<String, String> a : entry) {// 节点
System.out.println(a.getKey() + " " + a.getValue());
}
//2.只能遍历Key
Set<String> keys = m.keySet();
//keySet() 返回 hashMap 中所有 key 组成的集合
for (String ss : keys) {
System.out.println(ss);
}
//3.只能遍历Value
Collection<String> vals = m.values();
//values() 返回 hashMap 中存在的所有 value 值
for (String ss : vals) {
System.out.println(ss);
}
}
解答了HashMap底层相关的问题
这个也是
3. LinkedHashMap
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序
在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。
在LinkedHashMap中,是通过双链表的结构来维护节点的顺序的,看到下图中的before、next
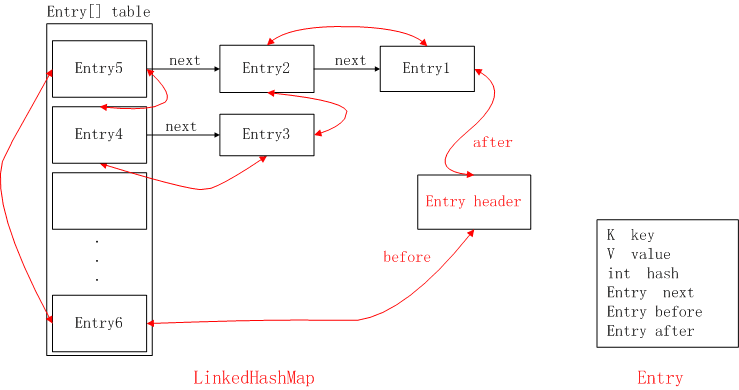
LinkedHashMap 简洁又明了的一篇讲解,我找了很久!
4. LinkedHashMap 与 HashMap 比较
LinkedHashMap在遍历的时候会比HashMap慢,不过有种情况例外,
当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
一般情况下,使用最多的是HashMap,在Map中插入、删除和定位元素,HashMap是最好的选择。
若要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
若要输出的顺序和输入的相同,那么可以用LinkedHashMap,还可按读取顺序排列.
5. Hashtable
Hashtable 与HasMap类似,它继承自Dictionary类,
不同处:
不允许键或值为null;
支持线程同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtable在写入时会比较慢。
6. HashMap与HashTable的区别与联系
HashMap实现Map接口,它允许任何类型的键和值对象,并允许将NULL用作键或值。
Hashtable中,Key和Value都不能是null。
Hashtable:
(1)Hashtable 是一个哈希表,它存储的内容是键值对(key-value)映射。
(2)Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。
(3)HashTable直接使用对象的hashCode。
HashMap:
(1)由数组+链表组成的,基于哈希表的Map实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的。
(2)不是线程安全的,HashMap可以接受为null的键(key)和值(value)。 null 可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为 null
(3)HashMap重新计算hash值
(4)HashMap的实例有俩个参数影响其性能: “初始容量” 和 装填因子
(5)HashMap中的key-value都是存储在Entry中的
(6)HashMap是采用拉链法解决哈希冲突的
HashTable中hash数组默认大小是11,增加的方式是old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
7. TreeMap
在Map集合框架中,除了HashMap以外,TreeMap也是我们工作中常用到的集合对象之一。
与HashMap相比,TreeMap是一个能比较元素大小的Map集合,会对传入的key进行了大小排序。其中,可以使用元素的自然顺序,也可以使用集合中自定义的比较器来进行排序;
不同于HashMap的哈希映射,TreeMap底层红黑树的结构,形成了一颗二叉树。
8. HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
HashMap 和 HashSet 的区别与联系
二者底层结构一致。HashSet也是用Hash Map实现的。
list有序(默认添加顺序与迭代遍历顺序相同) 有索引 可重复
HashSet无序(默认添加顺序与迭代遍历顺序不同) 无索引 不重复
HasMap也是无序。
//HashSet的遍历,因为无索引,所以采用foreach。迭代器也可以。
HashSet<String> hs = new HashSet<String>();
for(String s : hs) {
System.out.println(s);
}
9. ConcurrentHashMap
HashMap线程不安全,所以出现了ConcurrentHashMap。当然,上文也讲到了HashTable,HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为对于Hashtable而言,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占。相当于所有线程进行读写时都去竞争一把锁,导致效率非常低下。
ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁ReentrantLock,在ConcurrentHashMap里扮演锁的角色,HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
 从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作,第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部,因此,这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长,但是带来的好处是写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上),所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
ConcurrentHashMap的开发度 : Segment数量大小
ConcurrentHashMap详解,这个网站讲的确实详细
10. ConcurrentSkipListMap
跳表就能让链表拥有近乎的接近二分查找的效率的一种数据结构。所以查询时间是log(n)。
ConcurrentSkipListMap是在JDK 1.6中新增的,为了对高并发场景下的有序Map提供更好的支持,它有几个特点:
- 高并发场景
- key是有序的
- 添加、删除、查找操作都是基于跳表结构(Skip List)实现的
- key和value都不能为null
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。

图很清晰