大数据分析 | 用 Python 做文本词频分析
老师教给我,要学骆驼,沉得住气的动物。看它从不着急,慢慢地走,慢慢地嚼,总会走到的,总会吃饱的。
———《城南旧事》

目录
一、前言
Python 简介
Python 特点
二、基本环境配置
三、分析
Part1介绍
Part2词频分析对象——《“十四五”规划》
Part3文本预处理
Part4中文分词——全都是“干货”
1添加自定义词库(特色词库)
2进行分词
3去除停用词
4按需处理其他词语
Part5生成词频统计表
1统计词频
2将词频统计结果保存为表格
Part6全部代码
Part7总结
获取源码?私信?关注?点赞?收藏?
一、前言
Python 简介
Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。
Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
Python 是一种解释型语言: 这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
Python 是交互式语言: 这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
Python 特点
1.易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
2.易于阅读:Python代码定义的更清晰。
3.易于维护:Python的成功在于它的源代码是相当容易维护的。
4.一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
5.互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
6.可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
7.可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
8.数据库:Python提供所有主要的商业数据库的接口。
9.GUI编程:Python支持GUI可以创建和移植到许多系统调用。
10.可嵌入: 你可以将Python嵌入到C/C++程序,让你的程序的用户获得"脚本化"的能力。
二、基本环境配置
版本:Python3
系统:Windows
相关库:requests,lxml,numpy,Counter,pandas,re,jieba
开发工具:Pycharm
在这里我使用的是 anaconda ,众所周知这是一个大软件,但是它的环境是比较全面的,在之前的学习中,我们用的是这个软件。
anconda,可以理解成运输车,每当下载anconda的时候,里面不仅包含了python,还有180多个库(武器)一同被打包下载下来
下载完anconda之后,再也不用一个个下载那些库了。
三、分析
Part1介绍
文本分析一直都是数据分析的重要组成,研究方向众多,包括但不限于词频分析、情感分析、文本分类、文本可视化等。其中一些方向研究难度不小,存在一定的技术门槛,但在中文文本分析中,大多数的研究方向都和词语息息相关,所以文本词频分析往往是文本分析的“第一步”。
在技术资源和数据资源丰饶的现代,人人都可以自建炉灶,进行自己的文本研究。一些读者可能在技术操作上存在困难,故而本文就来为大家在词频分析方面提供一些微小的帮助。
本文中所有 Python 代码均在集成开发环境 PyCharm 中以及使用交互式开发环境 Jupyter Notebook 编写和运行,使用到的 Python 库有 re(用于文本预处理)、jieba(用于中文分词)、collections(用于词频统计)、pandas (用于词频统计表的制作和保存)。
Part2词频分析对象——《“十四五”规划》
我们以国家指导文件《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》(下文简称为《“十四五”规划》)中的文本内容作为此次词频分析的文本对象。
首先将文本保存为文本文件(txt 文件),正文部分如下图所示。

Part3文本预处理
首先使用 Python 读取文本,代码如下:
with open('十四五规划.txt', 'r', encoding='utf-8') as f:
# encoding 参数需要根据文本文件实际的编码来设置
Text = f.read() # 读取全部内容
f.close() # 关闭文件,必要的操作
# 输出正文的前 200 个字符
Text[2024:2224]
Python 读取文本文件时,会加载所有文本,包括空格和换行符。在文章正文的书写中,我们难以避免地使用换行来让文字连续。这有利于阅读,但使用 Python 读取文档时会读到很多换行符以及其他的空白字符,这严重影响了文本中词语的连续性,所以将换行符和空白符全部去除是一个不错的解决方案,操作代码如下:
import re
# 使用正则表达式去除文本中所有的换行符和空白符
Text = re.sub('\s+', '', Text)
下图是去除换行符后正文(不含目录)的一部分:
小贴士
文本经过预处理后,在后续的分词过程中不会受到干扰字符(换行符,空格)的影响,分词效果更好。
Part4中文分词——全都是“干货”
分词是词频分析最重要的一步,分词的效果和准确性直接影响词频统计的结果,所以在分词方面,需要多做一些工作。
jieba 是 Python 的一个第三方库,可以用于分词,筛选关键词等。Python 有不少分词工具,jieba 的分词效果不一定是最好的,但是它的普适性、易用性、可扩展性一定是非常优秀的,本文就用它作为分词的工具。
1添加自定义词库(特色词库)
jieba 分词以基本词库为标准,一般词语的颗粒度比较小,鲜有某专业领域的特色词。因此我们可以将一些字数较多的词语和专业领域的特色词,添加到我们的特色词库。将特色词库导入后,这些词语的权重要比常规词语高一些,jieba 会优先将他们视作词语进行分词。
添加自定义词语有两种方式,一种是使用 jieba.add_word 添加,代码如下:
import jieba
jieba.add_word('特色词')
另一种是将所有词语存入 txt(编码为UTF-8)中,使用 jieba.load_userdict 添加,我们随意从《“十四五”规划》文本中选取 50 个词语作为特色词保存到 txt 中,词库格式如下图所示:
发展
建设
制度
安全
产业
创新
经济
保障
改革
文化将此 txt 加载到 jieba 特色词库的代码如下:
# Special_words.txt 是特色词语的路径
jieba.load_userdict('Special_words.txt')
2进行分词
使用jieba.lcut 对文章进行分词,所有词语保存为一个列表,代码如下:
Words_list = jieba.lcut(Text) # 进行分词,结果为词语列表
print(len(Words_list)) # 输出词语总数量,结果为 32789
Words_list[:10] # 输出前 10 个词语3去除停用词
停用词一般指文本中一些无实际意义的语气词,助词等用处不大的词语,因此需要在对分解结果进行处理,去除其中的停用词。有许多机构已经收录了很多常见的停用词,我们使用百度收录的停用词库来去除停用词,停用词库(txt 文件)如下图所示:

自身
至
于
若是
莫若
获得
虽
虽则
虽然
去除停用词的原理其实很简单,就是将停用词库加载为一个词语列表,再将分词列表中出现在停用词库中的词语去除即可。将停用词库加载为词列表的代码如下:
Stopwords = open('./停用词/baidu_stopwords.txt', 'r', encoding='utf-8').readlines()
Stopwords = [word.strip() for word in Stopwords]
去除分词列表中停用词的代码如下:
Words_list = [word for word in Words_list if word not in Stopwords]
# 输出去停用词后的总词数
print(len(Words_list)) # 输出:28337, 较去除之前减少了 4452 个词语
4按需处理其他词语
在去除停用词后,词语列表中仍有一些我们不需要的词语,如“新”、“下”、“13” 、“/” 等实际不需要的词语,我们编写代码去除所有不含中文的词语和字数为1的词语,代码如下:
# 去除不含中文的词语
Words_list = [word for word in Words_list if bool(re.search('[\u4e00-\u9fa5]', word)) == True]
# 去除字数为 1 的词语
Words_list = [word for word in Words_list if len(word) != 1]
# 输出剩余词语的数量
print(len(Words_list)) # 输出:21913
经过两轮清洗,词语总数量已经从 32789 减少到 21913 个词语,一共去除 10876 个不需要的词语,剩余的词语均是有意义的词语,对清洗后的结果做词频统计才更加有意义。也可见数据预处理的重要性。
Part5生成词频统计表
1统计词频
对分词结果进行清理后,可以开始对剩余的词语做词频统计了。Counter 是 Python 中 collections 库中的一个函数,可以用于统计列表元素出现频率,词频统计的代码如下:
from collections import Counter # 导入频率统计函数
Word_count = Counter(Words_list) # 统计词频,所得结果为 Counter 对象
Word_count = dict(Word_count) # 将结果转为字典对象
Word_count
2将词频统计结果保存为表格
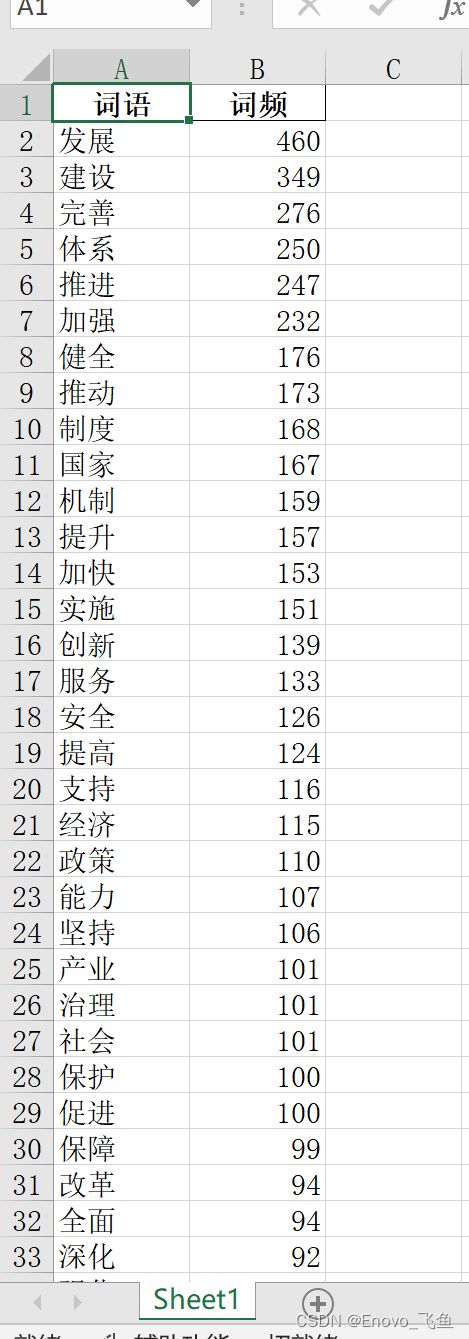
可以使用 pandas 将所有词语及其频率保存到 excel 表中,方便查看,生成以及保存到表的代码如下:
import pandas as pd
Table = pd.DataFrame(columns=['词语', '词频']) # 生成空表
Table['词语'] = list(Word_count.keys()) # 词语字段保存词语
Table['词频'] = list(Word_count.values()) # 词频字段保存词语对应的词频
Table = Table.sort_values(by=['词频'], ascending=False) # 按照词频降序排序
Table.to_excel('十四五规划词频统计表.xlsx', index=False) # 将结果保存为 excel 表
另外我们也可以提取我们添加的特色词,获取一个只包含特色词的词频统计表,代码如下:
# 读取特色词库为词列表
Specialwords = open('Special_words.txt', 'r', encoding='utf-8').readlines()
Specialwords = [word.strip() for word in Stopwords]
# 获取分词处理结果中所有的特色词,这个结果可以直接用来制作词云图
Special_words = [word for word in Words_list if word in Specialwords]
# 对特色词做词频统计
Special_count = dict(Counter(Special_words))
# 生成词频统计表并保存
Table_special = pd.DataFrame(columns=['特色词语', '词频'])
Table_special['特色词语'] = list(Special_count.keys())
Table_special['词频'] = list(Special_count.values())
Table_special = Table_special.sort_values(by=['词频'], ascending=False)
Table_special.to_excel('十四五规划特色词语词频统计表.xlsx', index=False)
我们还可以根据特色词语列表(不去重)来制作词云图,也就是文章顶部的那张词云图了。
Part6全部代码
# 导入工具包
import re, jieba
import pandas as pd
from collections import Counter
# 读取文本
with open('十四五规划.txt', 'r', encoding='utf-8') as f:
# encoding 参数需要根据文本文件实际的编码来设置,也可以
# 事先对 txt 进行转码
Text = f.read() # 读取全部内容
f.close() # 关闭文件,必要的操作
# 使用正则表达式去除文本中所有的换行符和空白符
Text = re.sub('\s+', '', Text)
# 导入特色词库
jieba.load_userdict('Special_words.txt')
# 进行分词,所得结果为词语列表
Words_list = jieba.lcut(Text)
# 加载停用词、去除停用词
Stopwords = open('./停用词/baidu_stopwords.txt', 'r', encoding='utf-8').readlines()
Stopwords = [word.strip() for word in Stopwords]
Words_list = [word for word in Words_list if word not in Stopwords]
# 去除不含中文的词语
Words_list = [word for word in Words_list if bool(re.search('[\u4e00-\u9fa5]', word)) == True]
# 去除字数为 1 的词语
Words_list = [word for word in Words_list if len(word) != 1]
# 统计词频
Word_count = dict(Counter(Words_list))
# 生成词频统计表
Table = pd.DataFrame(columns=['词语', '词频']) # 生成空表
Table['词语'] = list(Word_count.keys()) # 词语字段保存词语
Table['词频'] = list(Word_count.values()) # 词频字段保存词语对应的词频
Table = Table.sort_values(by=['词频'], ascending=False) # 按照词频降序排序
Table.to_excel('十四五规划词频统计表.xlsx', index=False) # 将结果保存为 excel 表
Part7总结
本文为大家介绍了如何使用 Python 进行文本分分析中的词频分析。从文本读取,到词频统计表的生成,讲解了每一步的代码和作用。
最后,希望大家可以提出宝贵的建议和意见,我会认真聆听,并努力实现。
在我之前的博客中,有一些关于Python程序设计的博客,感兴趣的同学们可以看一看,感谢支持!!!
以上就是本篇文章的全部内容了
~ 关注我,点赞博文~ 每天带你涨知识!
1.看到这里了就 [点赞+好评+收藏] 三连 支持下吧,你的「点赞,好评,收藏」是我创作的动力。
2.关注我 ~ 每天带你学习 :各种前端插件、3D炫酷效果、图片展示、文字效果、以及整站模板 、HTML模板 、C++、数据结构、Python程序设计、Java程序设计、爬虫等! 「在这里有好多 开发者,一起探讨 前端 开发 知识,互相学习」!
3.以上内容技术相关问题可以相互学习,可 关 注 ↓公 Z 号 获取更多源码 !
获取源码?私信?关注?点赞?收藏?
+✏️+⭐️+
有需要源码的小伙伴可以 关注下方微信公众号 " Enovo开发工厂 ",回复 关键词 " a-python1"