89、HexPlane: A Fast Representation for Dynamic Scenes
简介
主页:https://caoang327.github.io/HexPlane/

HexPlane 动态3D场景可以由六个学习到的特征平面显式表示
简单而言,作者出发点是使用TensoRF思想来解决动态NeRF中存在的高内存消耗和空间稀疏问题
实现流程
内存问题
如果使用4D体素表示3D动态场景,那么 t 时刻动态场景可以表示为 { V 1 , V 2 , ⋯ , V T } \{V_1,V_2,\cdots,V_T\} {V1,V2,⋯,VT},需要的内存为 O ( N 3 T F ) O(N^3TF) O(N3TF),如果F=3,N=512,T=32,使用float32数据格式,就需要48G内存
稀疏视图问题
稀疏视图不足以独立地对每个时间步骤建模,因此必须在时间步骤之间共享信息
论文借鉴了TensoRF,3D场景可以表示为:

其中 R = R 1 + R 2 + R 3 < < N R = R_1+R_2+R_3 << N R=R1+R2+R3<<N,那么内存消耗从 O ( N 3 T F ) O(N^3TF) O(N3TF) 压缩为 O ( R N 2 T ) O(RN^2T) O(RN2T)
将 t 时刻的三维体积Vt表示为一组共享的三维基体积 { V ^ 1 , … … , V ^ R t } \{\hat{V}_1,……, \hat{V}_{R_t}\} {V^1,……,V^Rt}

每个 V ^ i \hat{V}_i V^i 都表示为一个TensoRF,那么每个共享卷都是一个TensoRF,所以它有自己独立的 M r X Y , V r Z M^{XY}_r,V^Z_r MrXY,VrZ,并在所有共享卷之间共享这些低级别组件
那么3D体素 V t V_t Vt 在时间 t 表示为:
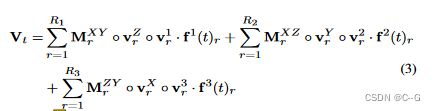
f i ( t ) ∈ R R i f^i(t) \in R^{R_i} fi(t)∈RRi 给出了每个时刻 t 的低秩成分的权重向量,捕获了模型对时间的依赖性
上面对每个时刻 t 建立一个TensoRF的做法,完全解耦了场景的空间和时间建模。然而在现实场景中,空间和时间是纠缠在一起的;
例如,一个圆周运动的粒子很难在方程3下建模,因为它的 x 和 y 位置最好分别作为 t 的函数建模。
所以,作者使用 t 和 z 的联合函数替换方程3中的 v r z ⋅ f 1 ( t ) r v^z_r \cdot f^1(t)_r vrz⋅f1(t)r,通过双线性插值到形状为 Z × T × R 1 Z × T × R_1 Z×T×R1 的学习张量来实现,动态3D场景可以表示为四维特征体积 V ∈ R X Y Z T F V \in R^{XYZTF} V∈RXYZTF
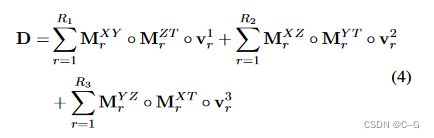
通过流程图可以更好理解
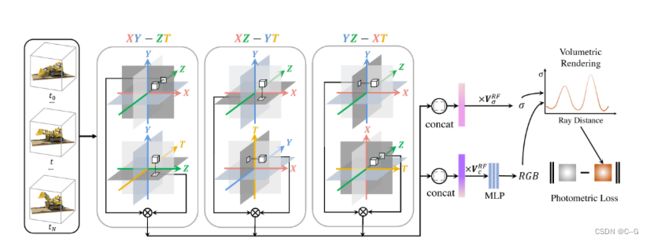
可以看到,图的中间的上三个图类似TensoRF对3D体素的分解,而下面三个图则是分别将 X Y Z 替换为时间 T。
也就是说,3D场景可以分为静态场和动态场,动态场考虑时间对静态场的影响。
以 XY-ZT 为例,对于空间中的一个采样点 p ,通过双线性插值得到其特征向量,直接使用乘法得到维度不变的特征向量,分别应用三次,得到的三个特征向量后进行拼接,最后通过小MLP或显示球谐函数得到颜色和密度。
公式简化表示为:

每个粗体张量的上标表示其形状,下标中的•表示切片,因此每一项都是向量矩阵乘积
内存消耗压缩为 O ( N 2 R + N T R + R F ) O(N^2R+NTR+RF) O(N2R+NTR+RF)
公式5表示为:
![]()
;表示矩阵拼接
损失函数为:

在平面上应用总变分(TV)损失来强制时空连续性,在应用深度平滑损失来减少伪影
也采用粗到细的方案,网格的分辨率在训练过程中逐渐增长。这种设计加速了训练,并在附近网格上提供了隐式正则化
保留一个微小的3D体素,表示场景区域的空白,并在空白区域中跳过点。由于许多区域是空的,这有助于加速。为了得到这个体素,评估点在时间步长的不透明性,并将它们减少到一个具有最大不透明性的单体素。尽管在不同的时间间隔中保留几个体素可以提高速度,但为了简单起见,只保留一个体素。
实验
使用小MLP解码或球谐函数解码


