大数据时代来临了,你需要了解什么是大数据
现在的社会是一个高速发展的社会,科技发达,信息流通,人们之间的交流越来越密切,生活也越来越方便,大数据就是这个高科技时代的产物。
大数据又称巨量资料,指的是需要新处理模式才能具有更强的决策力、洞察力和流程优化能力的海量、高增长率和多样化的信息资产。

大数据的特点有:
大量:数据量的大小决定所考虑的数据的价值和潜在的信息。
高速:提高获得数据的速度。
多样:数据类型多样性。
价值:合理运用大数据,以低成本创造高价值。

大数据应用于计算机、数学、金融、统计学等多个领域,人工智能的发展也与大数据密不可分。
大数据的价值体现在这几个方面:
第一,对大量消费者提供产品或服务的企业可以利用大数据进行精准营销;
第二,做小而美模式的中长尾企业可以利用大数据做服务转型;
第三,面临互联网压力之下必须转型的传统企业需要与时俱进充分利用大数据的价值。

大数据技术的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。换句话说,如果把大数据比作一种产业,那么这种产业实现盈利的关键,在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
想要在大数据这个领域汲取养分,让自己壮大成长。分享方向,行动以前先分享下一个大数据交流分享资源群870097548,欢迎想学习,想转行的,进阶中你加入学习。
要成为大数据工程师,那么就需要循序渐进的掌握整个大数据系统里所包含的知识,你可以一个系列一个系列的学。比如说,你先学了数据分析挖掘所需掌握的技能MATLAB、SPSS和SAS后,找到数据分析师的工作,然后继续学其他的技能,最后成为大数据工程师。
我们想要告诉大家的是成为大数据工程师需要掌握的知识体系,而作为初学者,你可以先从简单的入手,慢慢在学更深的知识,拿出高考的恒心和坚持来,肯定能行。
值得一提的是,目前大数据工程师的月薪都是20K起,月收入两万的薪资是不是很诱人?而且大数据工程师是非常容易找到工作的,所以……Why not?
不扯犊子了,由于篇幅所限,这一部分内容主要包括数据可视化、机器学习和算法三个分支。
数据可视化
R
R不仅是编程语言,同时也R具有强大的统计计算功能和便捷的数据可视化系统。在此,推荐大家看一本书,这本书叫做《R数据可视化手册》。
《R数据可视化手册》重点讲解R的绘图系统,指导读者通过绘图系统实现数据可视化。书中提供了快速绘制高质量图形的150多种技巧,每个技巧用来解决一个特定的绘图需求。读者可以通过目录快速定位到自己遇到的问题,查阅相应的解决方案。同时,作者在大部分的技巧之后会进行一些讨论和延伸,介绍一些总结出的绘图技巧。 《R数据可视化手册》侧重于解决具体问题,是R数据可视化的实战秘籍。《R数据可视化手册》中绝大多数的绘图案例都是以强大、灵活制图而著称的R包ggplot2实现的,充分展现了ggplot2生动、翔实的一面。从如何画点图、线图、柱状图,到如何添加注解、修改坐标轴和图例,再到分面的使用和颜色的选取等,本书都有清晰的讲解。
此书在网上就可以购买得到,当然也有电子版。在此,我们放出一张用R做出来的可视化作品。

D3.js
D3 (Data-Driven Documents)是基于数据的文档操作javascript库,D3能够把数据和HTML、SVG、CSS结合起来,创造出可交互的数据图表。
ECharts
ECharts是一款数据可视化的纯JavaScript图标库,其拥有混搭图表、拖拽重计算、制作数据视图、动态类型切换、图例开关、数据区域选择、值域漫游、多维度堆积等非常丰富的功能。
ECharts (Enterprise Charts 商业产品图表库)是基于HTML5 Canvas的一个纯Javascript图表库,提供直观,生动,可交互,可个性化定制的数据可视化图表。创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
ECharts提供商业产品常用图表库,底层基于ZRender,创建了坐标系,图例,提示,工具箱等基础组件,并在此上构建出折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)、地图、力导向布局图,同时支持任意维度的堆积和多图表混合展现。

Excel
Excel中大量的公式函数可以应用选择,使用Microsoft Excel可以执行计算,分析信息并管理电子表格或网页中的数据信息列表与数据资料图表制作,可以实现许多方便的功能,带给使用者方便。与其配套组合的有:Word、PowerPoint、Access、InfoPath及Outlook,Publisher
事实上,Excel完全可以满足大家日常工作中图表制作和数据可视化的需求,所以,想要进入大数据行业,学好Excel是基础。
Python
Python 的科学栈相当成熟,各种应用场景都有相关的模块,包括机器学习和数据分析。数据可视化是发现数据和展示结果的重要一环,只不过过去以来,相对于 R 这样的工具,发展还是落后一些。
幸运的是,过去几年出现了很多新的Python数据可视化库,弥补了一些这方面的差距。matplotlib 已经成为事实上的数据可视化方面最主要的库,此外还有很多其他库,例如vispy,bokeh, seaborn, pyga, folium 和 networkx,这些库有些是构建在 matplotlib 之上,还有些有其他一些功能。
报表类:FineReport
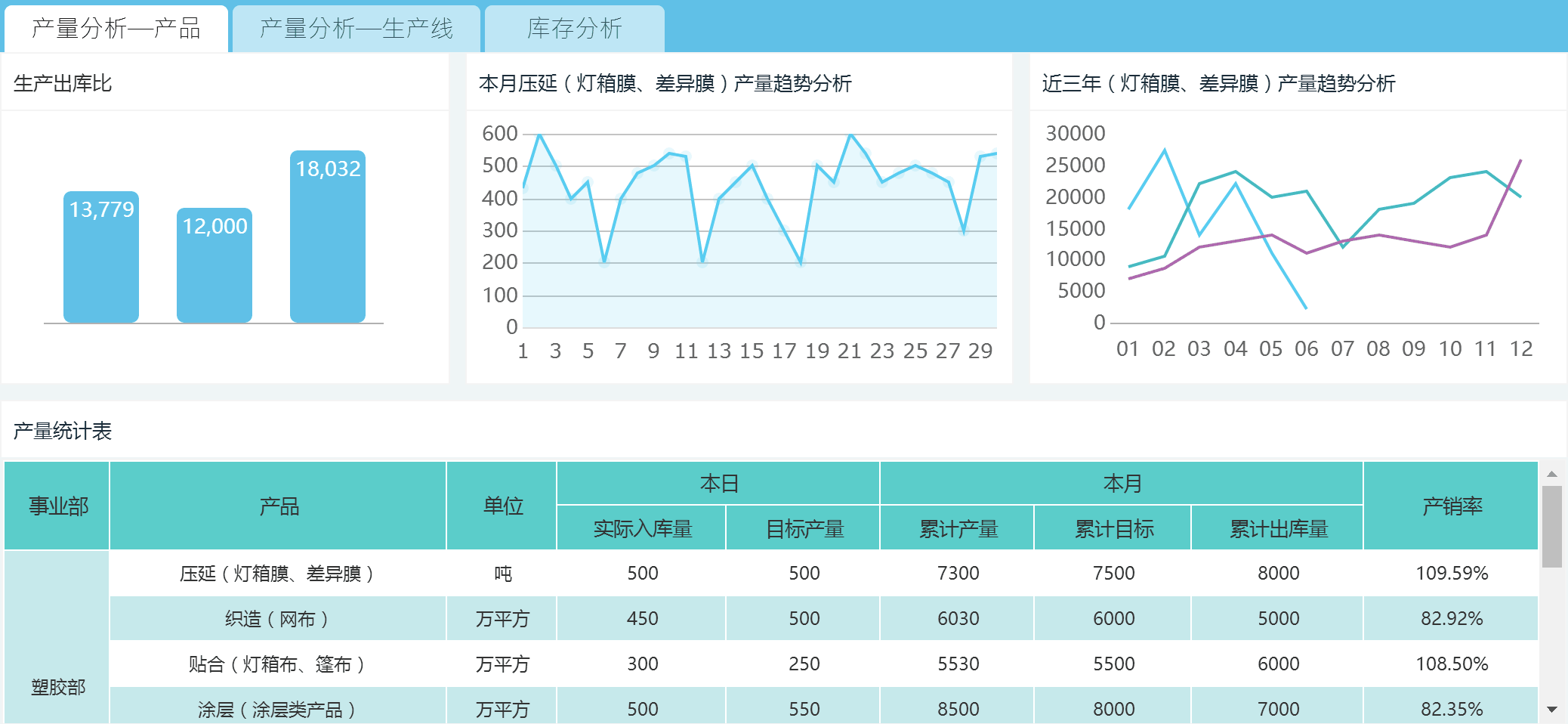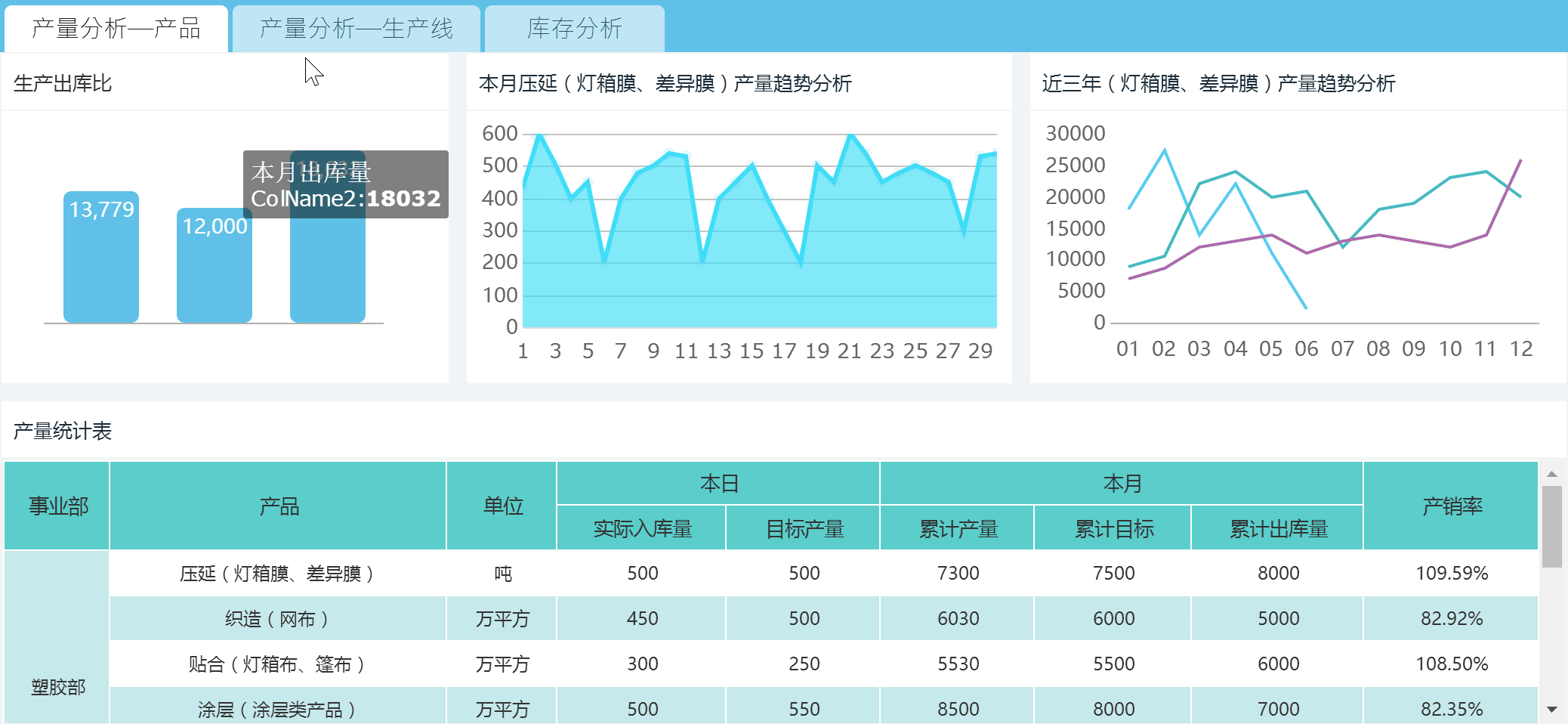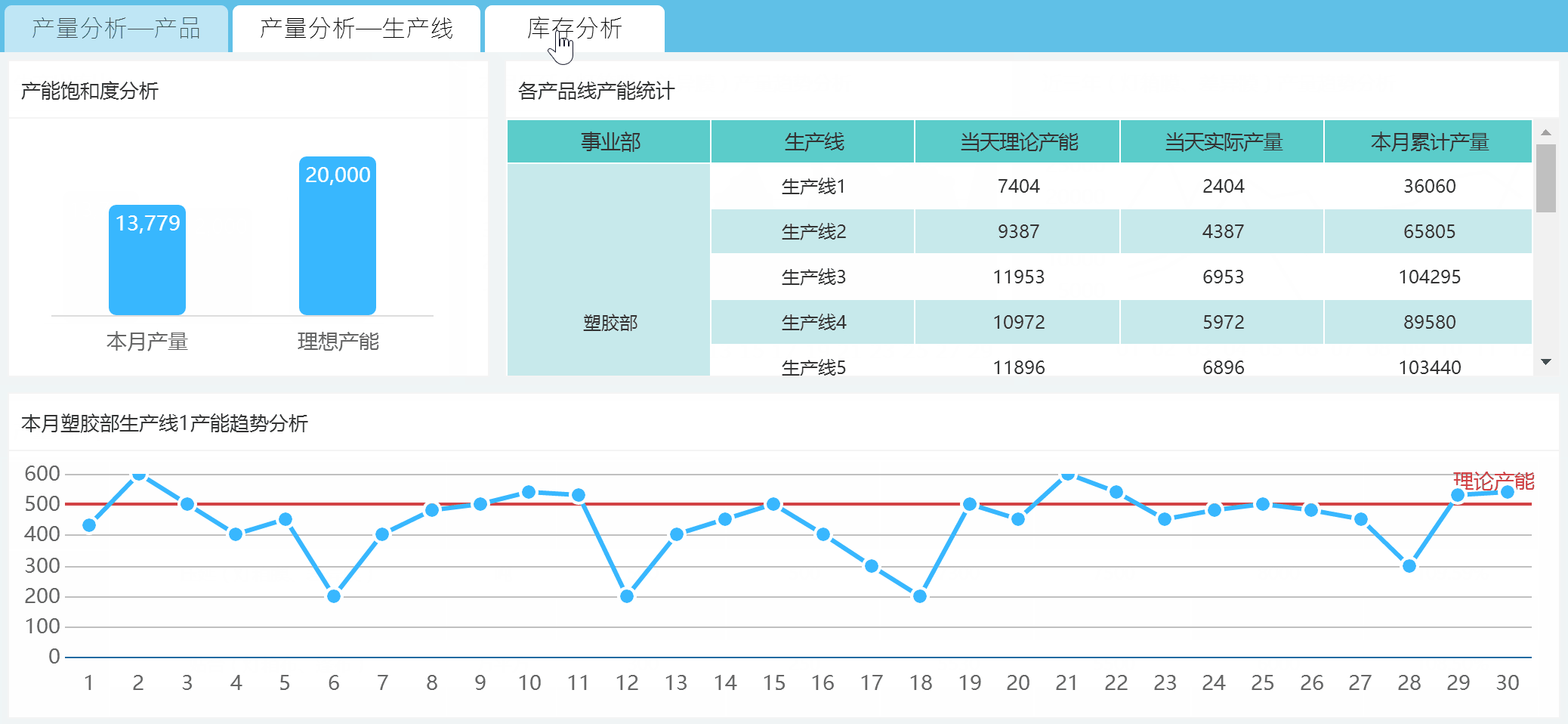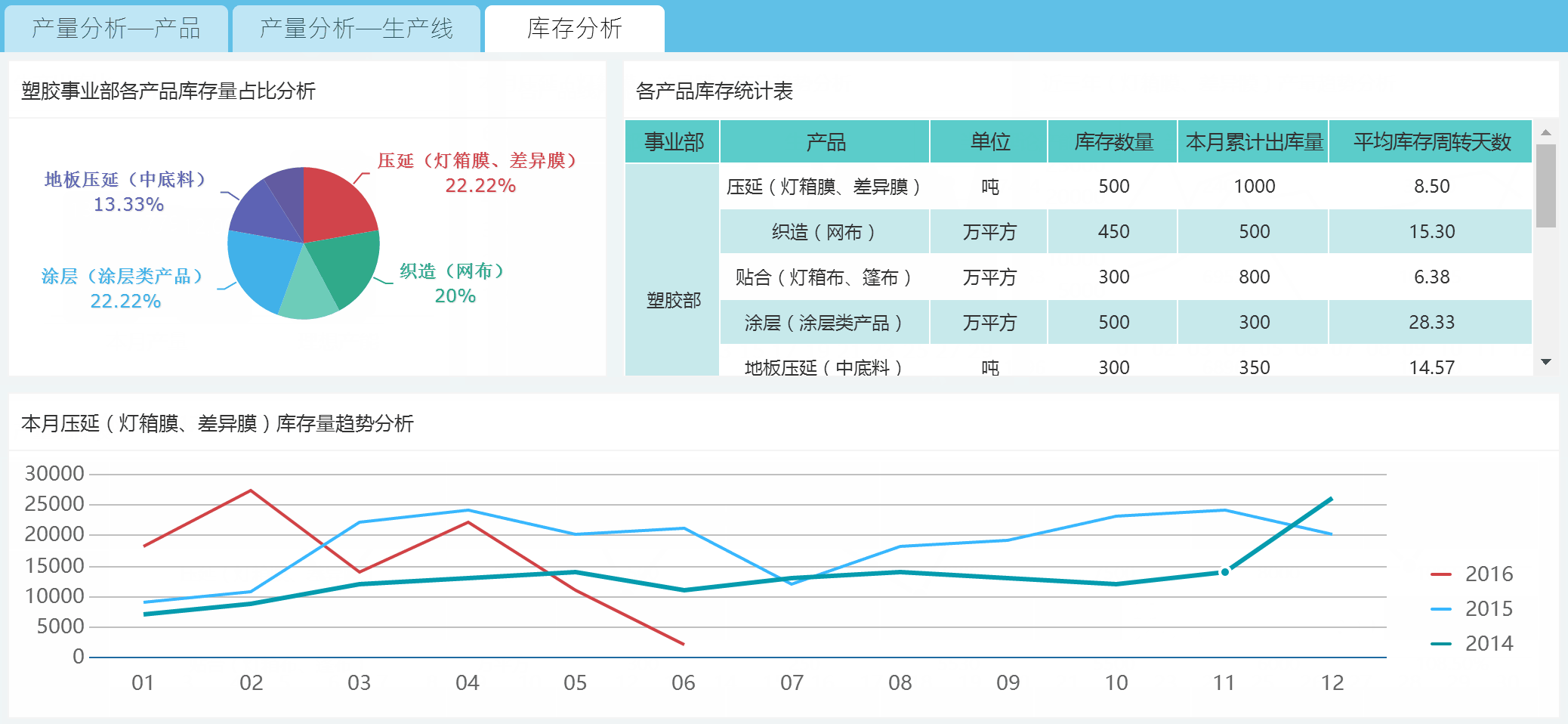
工作中数据可视化呈现的最多场景就是报表了。大数据工程师要做的可视化可不单单是表格数据展示,还有将数据从数据仓库中抽取得到实时呈现和展示。
FineReport是国内数一数二的报表工具,功能之强大已经完全覆盖掉大部分企业日常办公数据呈现的需求,与excel不同的是,FineReport的部署结果是一个数据展现分析平台,背后是数据中心,能够实现数据的全管理,而excel专注于单机的数据分析。
机器学习
机器学习基础
聚类
将物理或抽象对象的集合分成由类似的对象组成的多个类的过程被称为聚类。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。聚类分析又称群分析,它是研究(样品或指标)分类问题的一种统计分析方法。聚类分析起源于分类学,但是聚类不等于分类。聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类分析内容非常丰富,有系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法、聚类预报法等。
在数据挖掘中,聚类也是很重要的一个概念。
传统的聚类分析计算方法主要有如下几种:
1、划分方法(partitioning methods)
2、层次方法(hierarchical methods)
3、基于密度的方法(density-based methods)
4、基于网格的方法(grid-based methods)
5、基于模型的方法(model-based methods)
当然聚类方法还有:传递闭包法,布尔矩阵法,直接聚类法,相关性分析聚类,基于统计的聚类方法等。
时间序列
时间序列(或称动态数列)是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。时间序列分析的主要目的是根据已有的历史数据对未来进行预测。构成要素:长期趋势,季节变动,循环变动,不规则变动。
种类:
绝对数时间序列
时期序列:由时期总量指标排列而成的时间序列 。
相对数时间序列
把一系列同种相对数指标按时间先后顺序排列而成的时间序列叫做相对数时间序列。
平均数时间序列
平均数时间序列是指由一系列同类平均指标按时间先后顺序排列的时间序列。
保证序列中各期指标数值的可比性
(一)时期长短最好一致
(二)总体范围应该一致
(三)指标的经济内容应该统一
(四)计算方法应该统一
(五)计算价格和计量单位可比
推荐系统
定义:它是利用电子商务网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”。
推荐系统有3个重要的模块:用户建模模块、推荐对象建模模块、推荐算法模块。通用的推荐系统模型流程如图。推荐系统把用户模型中兴趣需求信息和推荐对象模型中的特征信息匹配,同时使用相应的推荐算法进行计算筛选,找到用户可能感兴趣的推荐对象,然后推荐给用户。
回归分析
回归分析(regression analysis)是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。运用十分广泛,回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;在线性回归中,按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。如果在回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且自变量之间存在线性相关,则称为多元线性回归分析。
文本挖掘
文本挖掘有时也被称为文字探勘、文本数据挖掘等,大致相当于文字分析,一般指文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生,如模式识别。文本挖掘通常涉及输入文本的处理过程(通常进行分析,同时加上一些衍生语言特征以及消除杂音,随后插入到数据库中) ,产生结构化数据,并最终评价和解释输出。’高品质’的文本挖掘通常是指某种组合的相关性,新颖性和趣味性。典型的文本挖掘方法包括文本分类,文本聚类,概念/实体挖掘,生产精确分类,观点分析,文档摘要和实体关系模型(即,学习已命名实体之间的关系) 。
决策树
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
支持向量机
支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。
贝叶斯分类
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。贝叶斯分类是统计学的分类方法,其分析方法的特点是使用概率来表示所有形式的不确定性,学习或推理都要用概率规则来实现。
神经网络
神经网络可以指向两种,一个是生物神经网络,一个是人工神经网络。人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
人工神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。在工程与学术界也常直接简称为“神经网络”或类神经网络。
机器学习工具
Mahout
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外,通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到云中。
Spark Mlib
MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等(可以在 Machine learning 上查看Toptal的文章,来获取更过的信息)。其中一些算法也可以应用到流数据上,例如使用普通最小二乘法或者K均值聚类(还有更多)来计算线性回归。Apache Mahout(一个针对Hadoop的机器学习库)已经脱离MapReduce,转而加入Spark MLlib。
TensorFlow (Google 系)
TensorFlow是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从图象的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
TensorFlow可被用于语音识别或图像识别等多项机器深度学习领域,对2011年开发的深度学习基础架构DistBelief进行了各方面的改进,它可在小到一部智能手机、大到数千台数据中心服务器的各种设备上运行。TensorFlow将完全开源,任何人都可以用。
Amazon Machine Learning
Amazon Machine Learning 是一项面向各个水平阶层开发人员的服务,可以帮助他们利用机器学习技术。Amazon Machine Learning 提供可视化的工具和向导,指导您按部就班地创建机器学习模型,而无需学习复杂的机器学习算法和技术。当您的模型准备好以后,Amazon Machine Learning 只要使用简单的 API 即可让您的应用程序轻松获得预测能力,而无需实现自定义预测生成码或管理任何基础设施。
Amazon Machine Learning 采用与 Amazon 内部数据科学家社区多年来一直使用的机器学习技术相同的技术,具有稳定可靠、容易扩展的特点。此服务使用强大的算法通过发现已有数据中的规律来创建机器学习模型。然后,Amazon Machine Learning 会使用这些模型来处理新数据并为应用程序生成预测结果。
Amazon Machine Learning 具有极强的可扩展性,每天可以生成数十亿条预测结果,并以高吞吐量实时地将其送出。使用 Amazon Machine Learning 不需要对硬件或软件事先投入资金,只需要根据使用量付费,所以不妨先从小规模做起,然后根据应用程序的发展情况再酌情进行扩展。
DMTK (微软分布式机器学习工具)
DMTK 是微软分布式机器学习工具包。
DMTK 包括以下几个项目:
DMTK framework(Multiverso): 参数服务器架构的机器学习
LightLDA: 用于大规模主题模型的可扩展、快速、轻量级系统.
Distributed word embedding:文字嵌入分布式算法.
Distributed skipgram mixture: 多义文字嵌入分布式算法
算法
一致性
数据一致性通常指关联数据之间的逻辑关系是否正确和完整。而数据存储的一致性模型则可以认为是存储系统和数据使用者之间的一种约定。如果使用者遵循这种约定,则可以得到系统所承诺的访问结果常用的一致性模型有:
a、严格一致性(linearizability, strict/atomic Consistency):读出的数据始终为最近写入的数据。这种一致性只有全局时钟存在时才有可能,在分布式网络环境不可能实现。
b、顺序一致性(sequential consistency):所有使用者以同样的顺序看到对同一数据的操作,但是该顺序不一定是实时的。
c、因果一致性(causal consistency):只有存在因果关系的写操作才要求所有使用者以相同的次序看到,对于无因果关系的写入则并行进行,无次序保证。因果一致性可以看做对顺序一致性性能的一种优化,但在实现时必须建立与维护因果依赖图,是相当困难的。
d、管道一致性(PRAM/FIFO consistency):在因果一致性模型上的进一步弱化,要求由某一个使用者完成的写操作可以被其他所有的使用者按照顺序的感知到,而从不同使用者中来的写操作则无需保证顺序,就像一个一个的管道一样。 相对来说比较容易实现。
e、弱一致性(weak consistency):只要求对共享数据结构的访问保证顺序一致性。对于同步变量的操作具有顺序一致性,是全局可见的,且只有当没有写操作等待处理时才可进行,以保证对于临界区域的访问顺序进行。在同步时点,所有使用者可以看到相同的数据。
f、 释放一致性(release consistency):弱一致性无法区分使用者是要进入临界区还是要出临界区, 释放一致性使用两个不同的操作语句进行了区分。需要写入时使用者acquire该对象,写完后release,acquire-release之间形成了一个临界区,提供 释放一致性也就意味着当release操作发生后,所有使用者应该可以看到该操作。
g、最终一致性(eventual consistency):当没有新更新的情况下,更新最终会通过网络传播到所有副本点,所有副本点最终会一致,也就是说使用者在最终某个时间点前的中间过程中无法保证看到的是新写入的数据。可以采用最终一致性模型有一个关键要求:读出陈旧数据是可以接受的。
h、delta consistency:系统会在delta时间内达到一致。这段时间内会存在一个不一致的窗口,该窗口可能是因为log shipping的过程导致。这是书上的原话。。我也搞不很清楚。。 数据库完整性(Database Integrity)是指数据库中数据的正确性和相容性。数据库完整性由各种各样的完整性约束来保证,因此可以说数据库完整性设计就是数据库完整性约束的设计。包括实体完整性。域完整性。参照完整性。用户定义完整性。可以主键。check约束。外键来一一实现。这个使用较多
paxos
Paxos算法是莱斯利·兰伯特(Leslie Lamport,就是 LaTeX 中的”La”,此人现在在微软研究院)于1990年提出的一种基于消息传递的一致性算法。这个算法被认为是类似算法中最有效的。
Paxos 算法解决的问题是一个分布式系统如何就某个值(决议)达成一致。一个典型的场景是,在一个分布式数据库系统中,如果各节点的初始状态一致,每个节点执行相同的操作序列,那么他们最后能得到一个一致的状态。为保证每个节点执行相同的命令序列,需要在每一条指令上执行一个“一致性算法”以保证每个节点看到的指令一致。一个通用的一致性算法可以应用在许多场景中,是分布式计算中的重要问题。因此从20世纪80年代起对于一致性算法的研究就没有停止过。节点通信存在两种模型:共享内存(Shared memory)和消息传递(Messages passing)。Paxos 算法就是一种基于消息传递模型的一致性算法。
raft
Raft是由Stanford提出的一种更易理解的一致性算法,意在取代目前广为使用的Paxos算法。目前,在各种主流语言中都有了一些开源实现,比如本文中将使用的基于JGroups的Raft协议实现。
在Raft中,每个结点会处于下面三种状态中的一种:
-
follower:所有结点都以follower的状态开始。如果没收到leader消息则会变成candidate状态
-
candidate:会向其他结点“拉选票”,如果得到大部分的票则成为leader。这个过程就叫做Leader选举(Leader Election)
-
leader:所有对系统的修改都会先经过leader。每个修改都会写一条日志(log entry)。leader收到修改请求后的过程如下,这个过程叫做日志复制(Log Replication):
-
复制日志到所有follower结点(replicate entry)
-
大部分结点响应时才提交日志
-
通知所有follower结点日志已提交
-
所有follower也提交日志
-
现在整个系统处于一致的状态
-
gossip
Gossip算法如其名,灵感来自办公室八卦,只要一个人八卦一下,在有限的时间内所有的人都会知道该八卦的信息,这种方式也与病毒传播类似,因此Gossip有众多的别名“闲话算法”、“疫情传播算法”、“病毒感染算法”、“谣言传播算法”。
但Gossip并不是一个新东西,之前的泛洪查找、路由算法都归属于这个范畴,不同的是Gossip给这类算法提供了明确的语义、具体实施方法及收敛性证明。
Gossip算法又被称为反熵(Anti-Entropy),熵是物理学上的一个概念,代表杂乱无章,而反熵就是在杂乱无章中寻求一致,这充分说明了Gossip的特点:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,当然这也是疫情传播的特点。
要注意到的一点是,即使有的节点因宕机而重启,有新节点加入,但经过一段时间后,这些节点的状态也会与其他节点达成一致,也就是说,Gossip天然具有分布式容错的优点。
常用算法
1.排序
将杂乱无章的数据元素,通过一定的方法按关键字顺序排列的过程叫做排序。假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。
插入排序
有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
插入排序的基本思想是:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。
桶排序
桶排序 (Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将数组分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
堆排序
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
2.快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
3,最大子数组
最大和子数组是数组中和最大的子数组,又名最大和子序列。子数组是数组中连续的n个元素,比如a2,a3,a4就是一个长度为3的子数组。顾名思义求最大和子数组就是要求取和最大的子数组。
n个元素的数组包含n个长度为1的子数组:{a0},{a1},…{an-1};
n个元素的数组包含n-1个长度为2的子数组:{a0,a1},{a1,a2},{an-2,an-1};
………………………………………………………………………………………………
n个元素的数组包含1个长度为n的子数组:{a0,a1,…,an-1};
所以,一个长度为n的数组包含的子数组个数为n+(n-1)+…+1=n*(n-1)/2。
4.最长公共子序列
一个数列 ,如果分别是两个或多个已知数列的子序列,且是所有符合此条件序列中最长的,则 称为已知序列的最长公共子序列。
最长公共子序列,英文缩写为LCS(Longest Common Subsequence)。其定义是,一个序列 S ,如果分别是两个或多个已知序列的子序列,且是所有符合此条件序列中最长的,则 S 称为已知序列的最长公共子序列。而最长公共子串(要求连续)和最长公共子序列是不同的。
最长公共子序列是一个十分实用的问题,它可以描述两段文字之间的“相似度”,即它们的雷同程度,从而能够用来辨别抄袭。对一段文字进行修改之后,计算改动前后文字的最长公共子序列,将除此子序列外的部分提取出来,这种方法判断修改的部分,往往十分准确。简而言之,百度知道、百度百科都用得上。
5.最小生成树
一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。最小生成树可以用kruskal(克鲁斯卡尔)算法或prim(普里姆)算法求出。
最短路径
用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。
6.矩阵的存储和运算
列矩阵(column major)和行矩阵(row major)是数学上的概念,和电脑无关,它只是一套约定(convention),按照矢量和矩阵的乘法运算时,矢量是列矢还是行矢命名,这里只说4×4矩阵。齐次矢量可以看成是一个1×4的矩阵,就是行矢;或者4×1的矩阵,就是列矢。
云计算
云计算(Cloud Computing)是分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(Utility Computing)、[5] 网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)、热备份冗余(High Available)等传统计算机和网络技术发展融合的产物。
云计算(cloudcomputing)是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。
云服务
SaaS
SaaS是Software-as-a-Service(软件即服务)的简称,随着互联网技术的发展和应用软件的成熟, 在21世纪开始兴起的一种完全创新的软件应用模式。它与“on-demand software”(按需软件),the application service provider(ASP,应用服务提供商),hosted software(托管软件)所具有相似的含义。它是一种通过Internet提供软件的模式,厂商将应用软件统一部署在自己的服务器上,客户可以根据自己实际需求,通过互联网向厂商定购所需的应用软件服务,按定购的服务多少和时间长短向厂商支付费用,并通过互联网获得厂商提供的服务。
SaaS 应用软件的价格通常为“全包”费用,囊括了通常的应用软件许可证费、软件维护费以及技术支持费,将其统一为每个用户的月度租用费。
PaaS
PaaS是Platform-as-a-Service的缩写,意思是平台即服务。 把服务器平台作为一种服务提供的商业模式。通过网络进行程序提供的服务称之为SaaS(Software as a Service),而云计算时代相应的服务器平台或者开发环境作为服务进行提供就成为了PaaS(Platform as a Service)。
所谓PaaS实际上是指将软件研发的平台(计世资讯定义为业务基础平台)作为一种服务,以SaaS的模式提交给用户。因此,PaaS也是SaaS模式的一种应用。但是,PaaS的出现可以加快SaaS的发展,尤其是加快SaaS应用的开发速度。在2007年国内外SaaS厂商先后推出自己的PAAS平台。
IaaS
IaaS(Infrastructure as a Service),即基础设施即服务。
消费者通过Internet 可以从完善的计算机基础设施获得服务。这类服务称为基础设施即服务。基于 Internet 的服务(如存储和数据库)是 IaaS的一部分。Internet上其他类型的服务包括平台即服务(Platform as a Service,PaaS)和软件即服务(Software as a Service,SaaS)。PaaS提供了用户可以访问的完整或部分的应用程序开发,SaaS则提供了完整的可直接使用的应用程序,比如通过 Internet管理企业资源。
Openstack
OpenStack是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作。OpenStack支持几乎所有类型的云环境,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。OpenStack通过各种互补的服务提供了基础设施即服务(IaaS)的解决方案,每个服务提供API以进行集成。
OpenStack是IaaS(基础设施即服务)组件,让任何人都可以自行建立和提供云端运算服务。
此外,OpenStack也用作建立防火墙内的“私有云”(Private Cloud),提供机构或企业内各部门共享资源。
Docker
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker 使用客户端-服务器 (C/S) 架构模式,使用远程API来管理和创建Docker容器。Docker 容器通过 Docker 镜像来创建。容器与镜像的关系类似于面向对象编程中的对象与类。