第十一届泰迪杯数据挖掘挑战赛-产品订单数据分析B题(完整代码)--数据处理--第一部分
完整代码链接需要的请移至社区获得。
需要解决的问题
1. 请对附件中的训练数据(order_train1.csv)进行深入地分析,可参照但不限于下述主题。
(1) 产品的不同价格对需求量的影响;
(2) 产品所在区域对需求量的影响,以及不同区域的产品需求量有何特性;
(3) 不同销售方式(线上和线下)的产品需求量的特性;
(4) 不同品类之间的产品需求量有何不同点和共同点;
(5) 不同时间段(例如月头、月中、月末等)产品需求量有何特性;
(6) 节假日对产品需求量的影响;
(7) 促销(如618、双十一等)对产品需求量的影响;
(8) 季节因素对产品需求量的影响。
2. 基于上述分析,建立数学模型,对附件预测数据(predict_sku1.csv)中给出的产品,预测未来3月(即2019年1月、2月、3月)的月需求量,将预测结果按照表3的格式保存为文件result1.xlsx,与论文一起提交。请分别按天、周、月的时间粒度进行预测,试分析不同的预测粒度对预测精度会产生什么样的影响。
**本文是运用jupyter notebook来撰写代码**
数据处理
#导入需要的库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
from pandas import Series
from sklearn.metrics import mean_squared_error
from math import sqrt
from statsmodels.tsa.seasonal import seasonal_decompose
import statsmodels
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARIMA
%matplotlib inline
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
import seaborn as snsdf = pd.read_csv("order_train0.csv")#访问数据

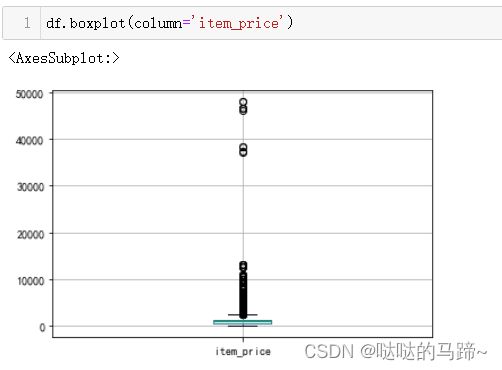
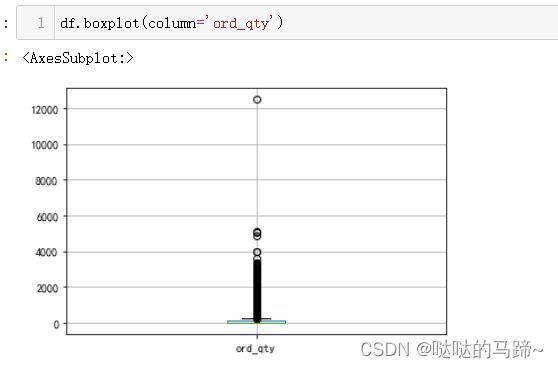
#从上方可以看出,价格最大值去到47911,最大需求去到12480,远大于一般商品
#查看价格分布、需求分布状况
#检验数据是否呈现正态分布
#检验数据是否呈现正态分布
def KsNormDetect(df): # 输出结果是服从正态分布的数据列的名字
from scipy.stats import kstest
list_norm_T = [] # 用来储存服从正态分布的数据列的名字
for col in df.columns:
*********** # 计算均值
*********** # 计算标准差
*********** # 计算P值
if res>=0.05: # 判断p值是否服从正态分布,p<=0.05 则服从正态分布,否则不服从
print(f'{col}该列数据不服从正态分布------')
print('均值为:%.3f,标准差为:%.3f' % (u, std))
print('-'*40)
**************
else: # 这一段实际上没什么必要
print(f'!!!{col}该列数据服从正态分布**********')
print('均值为:%.3f,标准差为:%.3f' % (u, std))
print('*'*40)
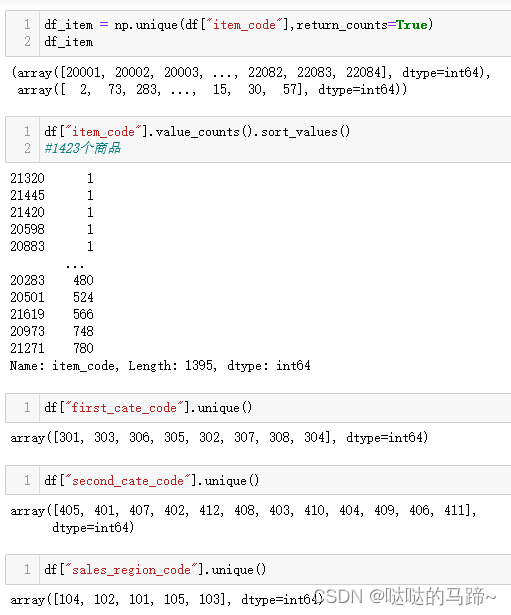
KsNormDetect(df[['item_price', 'ord_qty']]) 
# 对待处理数据中心服从正态分布的数据列
def three_sigma(Ser1): # Ser1:表示传入DataFrame的某一列
rule = []
***********************
***********************
print(len(out))
return out # 返回落在3sigma之外的行索引值
def delete_out3sigma(data, list_norm): # data:待检测的DataFrame;list_norm:服从正态分布的数据列名
out_index = [] # 保存要删除的行索引
for col in list_norm: # 对每一列分别用3sigma原则处理
***************************
***************************
****************** # 去除 out_index 中的重复元素
print(f'\n所删除的行索引共计{len(delete_)}个:\n',delete_)
data = data.drop(delete_,inplace=True) # 根据 delete_ 删除对应行的数据
df = data
return df
delete_out3sigma(df,['item_price','ord_qty'])

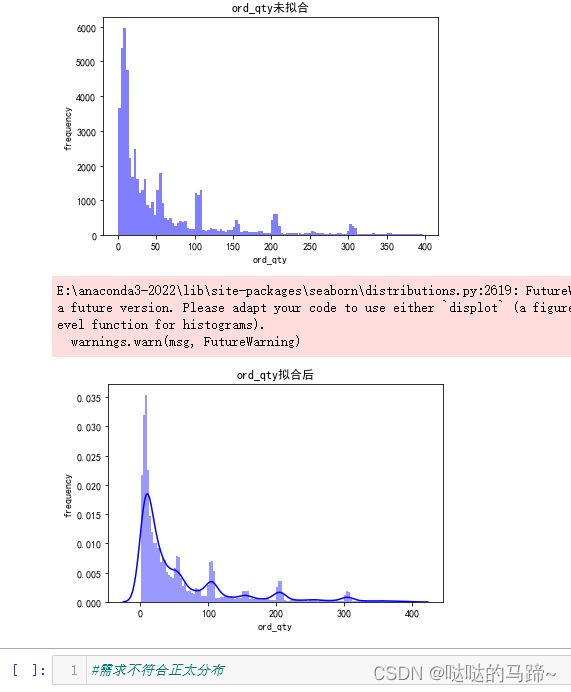
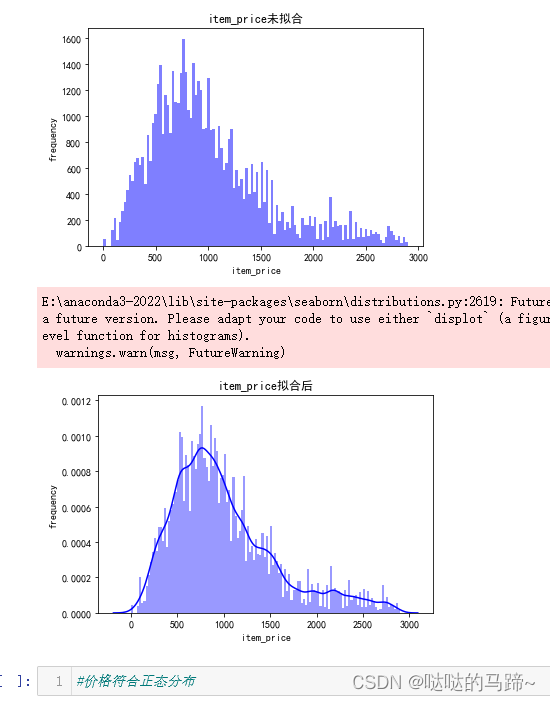
从上图看出数据并不服从正态分布
#再次查看分布状况


#查看数据具体值状况
#更改日期类型为datatime类型
df["order_date"]=df["order_date"].apply(pd.to_datetime,format='%Y-%m-%d')
#查看数据情况
#对sales_chan_name进行处理
dic = {"offline":1,"online":0}
df['sales_chan_name'] = df['sales_chan_name'].map(dic)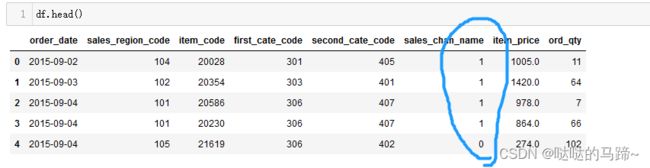
#时间特征添加
对日期时间进行时间特征处理,而时间特征包括年、季度、月、周、天(一年、一月、一周的第几天)
时间戳衍生中,另一常用的方法为布尔特征,即:
是否年初/年末
是否月初/月末
是否周末
是否节假日
是否特殊日期
是否早上/中午/晚上
上述都有具体的函数,可以去pandas官网上查找,有源码解释
这里为了方便处理节假日,需要安装chinesecalendar库
import chinese_calendar
df['Year'] = df.order_date.dt.year
df['Month'] = df.order_date.dt.month
df['day'] = df.order_date.dt.day
df["day of the week"] = df.order_date.dt.dayofweek
def applyer(df_row):
if ******************:
return 1
else:
return 0
temp1 = df["order_date"]
temp2 = df.order_date.********
temp2["weekend"] = temp2
df.index = df["order_date"]
df["quarter"] = *********
df['is_month_start'] = **********
df['is_month_end'] = ************
df['is_quarter_start'] = ********
df['is_quarter_end'] = *********
df['is_year_start'] = **********
df['is_year_end'] =************
df['is_workday']=df['order_date'].map(***********)
df["is_holiday"]=df["order_date"].map(***********)#上述运行后是以布尔值出现的,需要换成0 1 形式
for u in df.columns:
***********
**********
df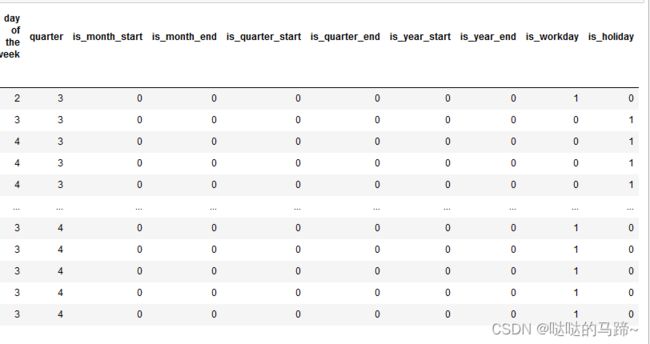
#添加销售额
df["sales"] = (df["ord_qty"])*(df["item_price"])
df.to_csv("df_sales_.csv")#保存文件,方便后续使用数据探索
sales_data = df #养成习惯,每当进行下一环节时,更改变量,以便失误可以返回来调取数据quantitative_variable = **********
sales_data[quantitative_variable].plot(***********,figsize=(15,15))
plt.show()
plt.rcParams['font.sans-serif'] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
#频率分布
*********************************
plt.figure(figsize=(16,8))
region.plot(**********************)
plt.title("地区频率分布",fontsize=20)
plt.show()
#查看时间序列是否完整

可以发现不完整,2015年只有4个月的数据
月度信息将进行进一步分析

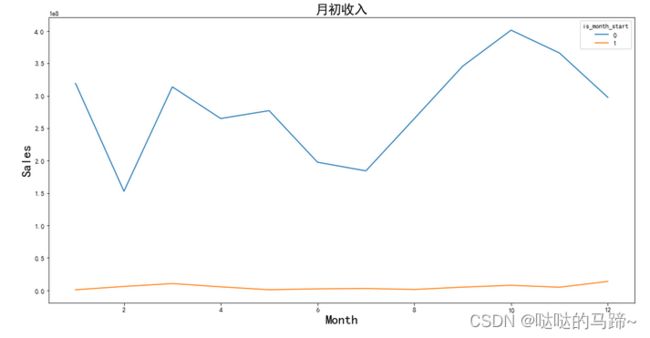
#月收入状况
plt.figure(figsize=(16,8))
monthly_revenue = sales_data.groupby(['Year','Month'])['sales'].sum().reset_index()
sns.lineplot(x="Month", y="sales",hue="Year", data = monthly_revenue)
plt.xlabel('Month',fontsize = 20)
plt.ylabel('Sales',fontsize = 20)
plt.title('月收入',fontsize = 20)
plt.show()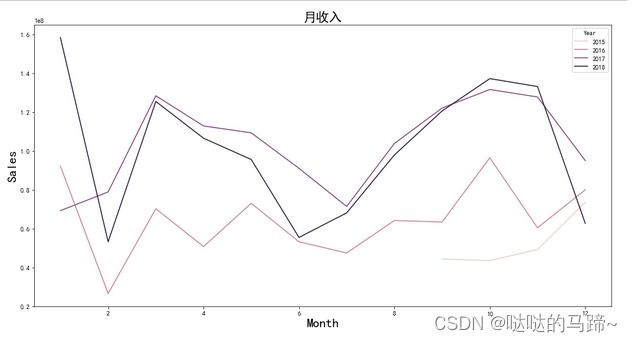
数据显示,2016年,2017年的销售额在10月左右达到峰值,1、3月份也有大幅度回升,2018年在1月达到最大值,3月、10月也有大幅度回升。 这可能是因为当时有许多庆祝活动和节日(感恩节、万圣节、国庆节、春节等)。
我们没有足够的2015年数据,但现有数据显示
plt.figure(figsize=(16,8))
****************************************
['sales'].sum().reset_index()
****************************************
plt.xlabel('Year',fontsize = 20)
plt.ylabel('Sales',fontsize = 20)
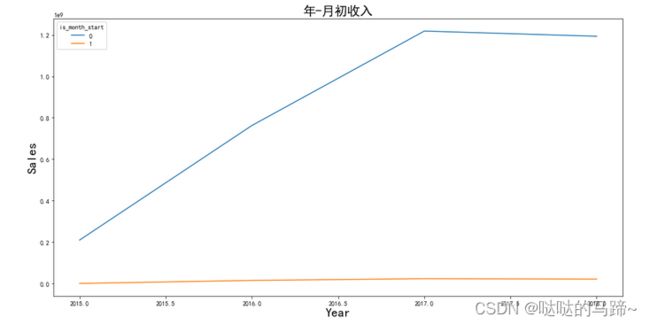
plt.title('年-月初收入',fontsize = 20)
plt.show()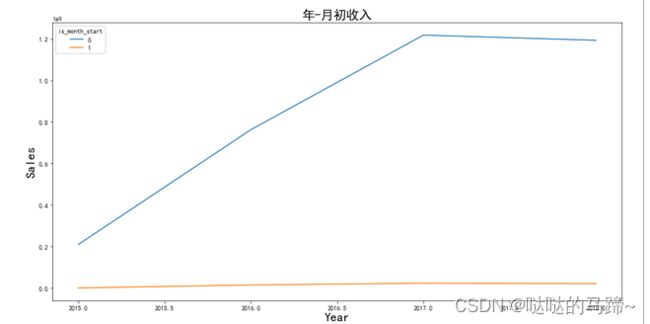
......
......
上述代码可以相同,以此类推,看自己需要去更换变量
#周一到周末的销售情况
sales_data['order_date'].dt.dayofweek
plt.figure(figsize=(16,8))
**************************
plt.title('周一-周日的销售情况',fontsize = 20)
**************************
plt.xlabel('Day of Week')
plt.ylabel('订单')
plt.plot() 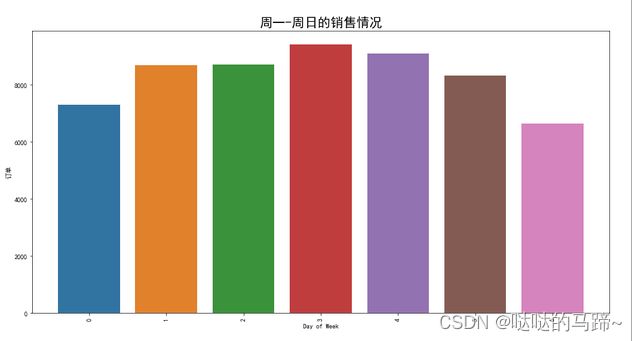
#节假日销售情况
plt.figure(figsize=(16,8))
**************************
**************************
**************************
plt.xlabel('节假日',fontsize = 15)
plt.ylabel('订单',fontsize = 15)
plt.plot()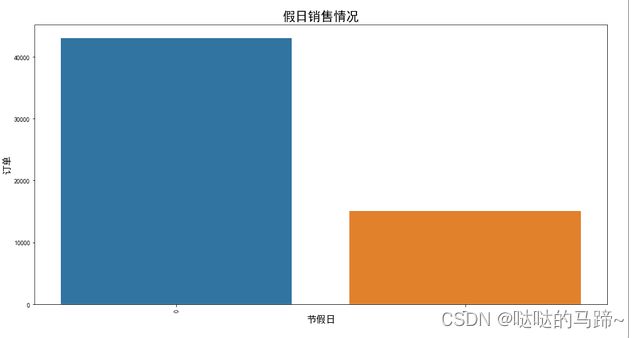
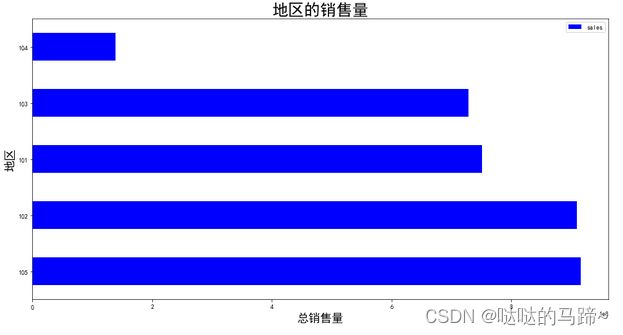
可以看出地区销售量状况中,105销售最多,其次是102,101,103,1104
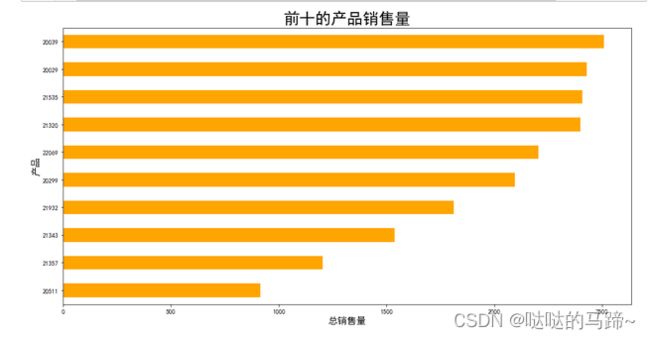
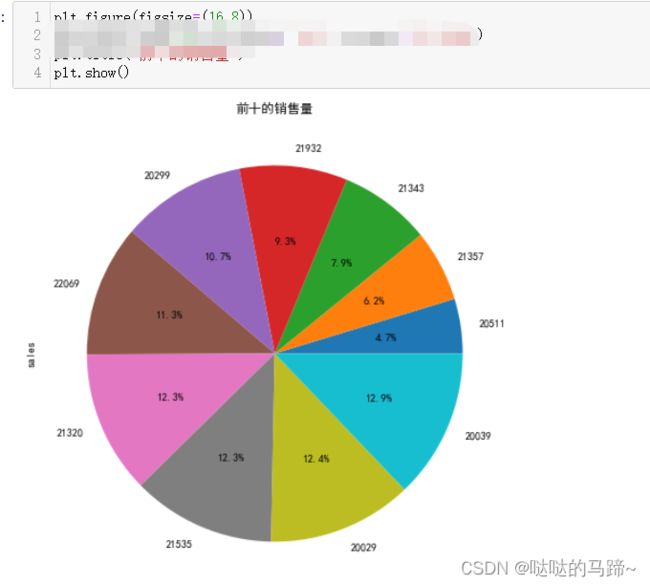

.........
..........
以此类推,根据自己需求去更换变量
##########################################
热编码看个人需要情况,个人觉得热编码后对后续的预测也没多大用处
dic1 = {101:"地区1",102:"地区2",103:"地区3",104:"地区4",105:"地区5"}
dic2 = {301:"大类别1",302:"大类别2",303:"大类别3",304:"大类别4",305:"大类别5",306:"大类别6",307:"类别7",308:"大类别8"}
dic3 = {401:"细类别1",402:"细类别2",403:"细类别3",404:"细类别4",405:"细类别5",406:"细类别6",407:"细类别7",408:"细类别8",409:"细类别9",410:"细类别10",411:"细类别11",412:"细类别12"}
sales_data['sales_region_code'] = ********
sales_data['first_cate_code'] = ***********
sales_data['second_cate_code'] =*********
#热编码
************************************
sales_data_dummies = sales_data_dummies.drop(["sales_chan_name"],axis=1)
#将热编码后的数据与原数据结合
*******************
n_sales_data.columns
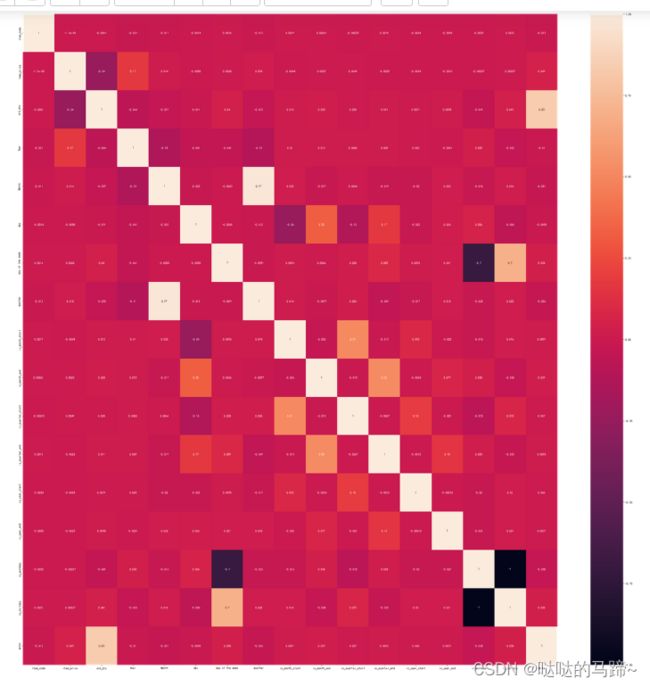
#绘制热力图
plt.figure(figsize = (40,40))
**********************
sns.heatmap(corr_matrix, annot = True)