工作流flowable框架搭建及剖析
前言
搭建flowable并没有想象中难,我自身纯手动搭建也就花了1个小时整合到spring boot框架中,简单地实现了一些接口,至于要整合到实际项目中要看实际项目的需求,建议是往通用的方向实现,这样可以做到一劳永逸,不至于每个新的流程都要另起一套接口。
点击获取项目demo
准备工作
- 创建一个maven项目,pom文件如下:
4.0.0
org.example
workflow
1.0-SNAPSHOT
org.springframework.boot
spring-boot-starter-parent
2.2.6.RELEASE
org.springframework.boot
spring-boot-starter
org.springframework.boot
spring-boot-starter-web
org.apache.httpcomponents
httpclient
org.flowable
flowable-spring-boot-starter
6.3.0
org.flowable
flowable-cmmn-engine
6.3.0
mysql
mysql-connector-java
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.1
com.alibaba
fastjson
org.slf4j
slf4j-api
org.slf4j
slf4j-log4j12
io.springfox
springfox-swagger2
2.9.2
io.springfox
springfox-swagger-ui
2.9.2
org.springframework.boot
spring-boot-starter-aop
kr.motd.maven
os-maven-plugin
1.5.0.Final
org.apache.maven.plugins
maven-compiler-plugin
11
11
UTF-8
org.springframework.boot
spring-boot-maven-plugin
true
repackage
org.apache.maven.plugins
maven-resources-plugin
UTF-8
- 创建项目目录结构
- 下载actiBPM插件
actiBPM插件下载参考
actiBPM插件是在idea工具上使用的,如果你使用的eclipse开发工具,用flowable designer可视化插件 - 流程画图
下面是我画的一个对账单流程图,示例如下:

流程画图分几部分:- 流程开始、结束节点
- 用户任务节点
- 流程指向箭头(附带流程条件)
- 网关(控制流程指向哪个节点)
其实,这个文件生成的是一个xml,有几处参数需要去配置:
整个流程的ID与名称配置

节点配置ID和名称
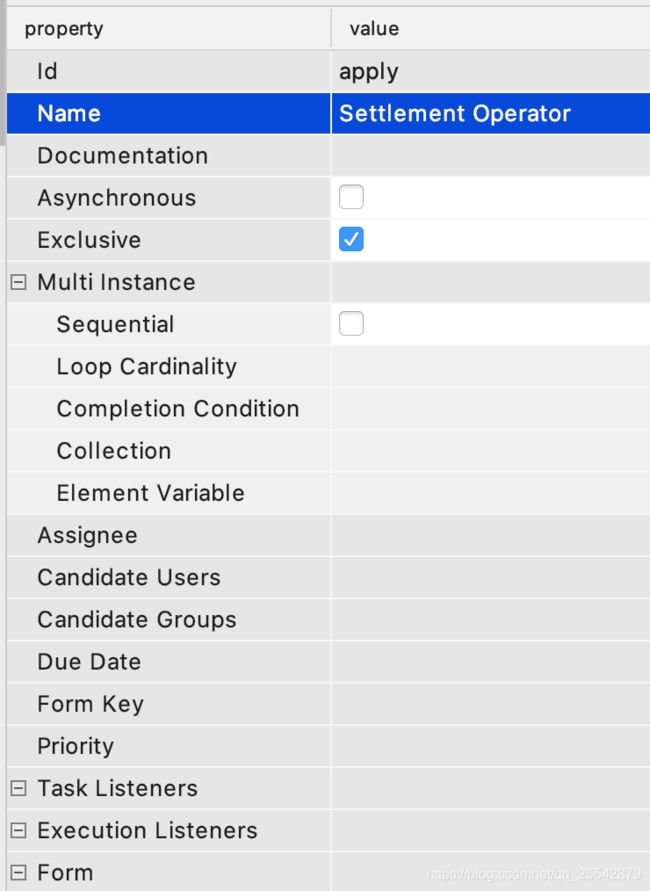
节点指定用户或用户组可以在文件生成之后在通过文本编辑器上修改,因为这个插件支持activiti,并不完全支持flowable,所以展示不了flowable的标签

流程指向箭头配置流程条件和名称
- approved && !((total_amount - advance_amount) >= 300000000 || adjust_amount >= 20000000 || (adjust_amount * 50) >= total_amount)
这种就是流程条件,里面的每个变量都是流程变量,后续会通过代码层面将流程变量添加进来。 - 流程条件是支持计算表达式的
基本的流程画图完成之后,我们需要为每个节点指定一个节点权限,因为是flowable的标签在流程设计器上看不到,所以需要打开文本编辑器,这里使用sublime打开。

上图中有两个节点对应两种场景,一种是为节点指定用户,一种是为节点指定用户组。这里为节点指定用户,这个用户是可变的,因为使用的是流程变量,而不是写死的值,当然也可以是写死的值,但是不推荐,这样做的目的是为以后人员变动预留空间。为节点指定用户组,按照上图这种写法即可,在查询待办的时候需要根据这个值进行匹配则可以获取当前的待办信息。
-
编写流程接口,运行项目
1.配置application.yml文件,接通mysql数据源。
application.yml文件spring: profiles: active: dev aop: # spring aop 开启cglig proxy-target-class: true jackson: property-naming-strategy: CAMEL_CASE_TO_LOWER_CASE_WITH_UNDERSCORES jpa: database: mysql show-sql: true hibernate: ddl-auto: update properties: hibernate: dialect: org.hibernate.dialect.MySQL5Dialect format_sql: false flowable: #关闭定时任务JOB async-executor-activate: false history-level: full # FinancialAuditProcess 对账单流程启动key #mybatis扫描包 mybatis: mapper-locations: classpath:mapper/*Mapper.xml type-handlers-package: guoyu.com.service.workflowsrv.common server: port: 9090application-dev.yml
spring: datasource: driver-class-name: com.mysql.jdbc.Driver url: 'jdbc:mysql://localhost/workflow?useUnicode=true&characterEncoding=utf-8&useSSL=true&nullCatalogMeansCurrent=true' username: root password: 123456789 #日志打印sql logging: level: com: example: mapper : INFO # swagger扫描包 base: package: guoyu.com.controller # httpclient配置 http: maxTotal: 100 #最大连接数 defaultMaxPerRoute: 20 #并发数 connectTimeout: 1000 #创建连接的最长时间 connectionRequestTimeout: 500 #从连接池中获取到连接的最长时间 socketTimeout: 10000 #数据传输的最长时间 staleConnectionCheckEnabled: true #提交请求前测试连接是否可用FlowableApplication.java springboot启动入口
package guoyu.com; import org.mybatis.spring.annotation.MapperScan; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import springfox.documentation.swagger2.annotations.EnableSwagger2; @MapperScan("guoyu.com.service.workflowsrv.mapper") @SpringBootApplication @EnableSwagger2 public class FlowableApplication { public static void main(String[] args) { SpringApplication.run(FlowableApplication.class, args); } }entry目录里的BaseResponse.java,只是用来做一个返回响应的结构体
package guoyu.com.entry; import io.swagger.annotations.ApiModel; import io.swagger.annotations.ApiModelProperty; import liquibase.pro.packaged.E; import java.io.Serializable; /** * 响应基类 * @author jack guo * * @param*/ @ApiModel(value="BaseResponse", description = "响应信息") public class BaseResponse implements Serializable{ @ApiModelProperty(value = "是否响应成功") private boolean success = false; @ApiModelProperty(value = "响应结果") private T result; @ApiModelProperty(value = "错误处理") private Error error = null; public boolean isSuccess() { return success; } public void setSuccess(boolean success) { this.success = success; } public T getResult() { return result; } public void setResult(T result) { this.result = result; } public Error getError() { return error; } public void setError(Error error) { this.error = error; } @ApiModel(value="Error", description = "错误处理") public static class Error { @ApiModelProperty(value = "错误码") private String code = ""; @ApiModelProperty(value = "错误信息") private String message = ""; public Error(String code, String msg){ this.code = code; this.message = msg; } public String getCode() { return code; } public void setCode(String code) { this.code = code; } public String getMessage() { return message; } public void setMessage(String message) { this.message = message; } @Override public String toString() { return "Error [code=" + code + ", message=" + message + "]"; } } public BaseResponse(boolean isSuccess, T result, Error error){ this.success = isSuccess; this.result = result; this.error = error; } public static BaseResponse success(Object result){ return new BaseResponse(true, result, null); } public static BaseResponse fail(String code, String msg){ return new BaseResponse(false, null, new Error(code, msg)); } @Override public String toString() { return "BaseResponse [success=" + success + ", result=" + result + ", error=" + error + "]"; } } 其实我搭建的demo里service都可以不写,直接调用flowable提供的service.所以最主要的还是看controller目录里的核心代码。
WorkflowController.java,代码块如下:package guoyu.com.controller; import com.mysql.cj.xdevapi.JsonArray; import guoyu.com.entry.BaseResponse; import io.swagger.annotations.ApiOperation; import liquibase.pro.packaged.A; import org.flowable.bpmn.model.BpmnModel; import org.flowable.engine.*; import org.flowable.engine.repository.Deployment; import org.flowable.engine.runtime.Execution; import org.flowable.engine.runtime.ProcessInstance; import org.flowable.image.ProcessDiagramGenerator; import org.flowable.task.api.Task; import org.flowable.task.api.TaskQuery; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RequestMethod; import org.springframework.web.bind.annotation.RequestParam; import org.springframework.web.bind.annotation.RestController; import javax.servlet.http.HttpServletResponse; import java.io.InputStream; import java.io.OutputStream; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * Created by guoyu on 2020/7/1 */ @RestController @RequestMapping(value = "/workflow") public class WorkflowController { private final Logger logger = LoggerFactory.getLogger(WorkflowController.class); @Autowired private RepositoryService repositoryService; @Autowired private RuntimeService runtimeService; @Autowired private TaskService taskService; @Autowired private ProcessEngine processEngine; /** * 部署流程 * @param processName 流程定义名 * @param resourcePath 如flowable/process.bpmn * @return */ @RequestMapping(value = "/create/process", method = RequestMethod.GET) public BaseResponsecreateProcess(String processName, String resourcePath){ Deployment deployment = repositoryService.createDeployment().name(processName).addClasspathResource(resourcePath).deploy(); return BaseResponse.success("部署流程成功"); } /** * 发起流程 * @return */ @RequestMapping(value = "/apply", method = RequestMethod.GET) public BaseResponse applyProcess(){ String processName = "FinancialAuditProcess"; Map tasks = taskService.createTaskQuery().taskCandidateOrAssigned(user).orderByTaskCreateTime().desc().list(); List controller里的接口如下:
- 流程部署
- 流程发起
- 流程待办
- 流程审核(执行下一步节点)
- 流程撤回(节点任意跳转)
- 获取流程变量
- 流程图展示
- 删除流程实例
- 流程申领
- 取消申领任务
- 查询流程活动历史
这些接口支持普通的业务场景,有一些比较复杂的应用场景,光靠flowable的接口无法实现,那就需要去探索flowable特有的60张表,只有摸清楚框架里的表是干嘛的,你才能对这个框架了解透彻,demo我会挂在博客上。可以下载下来跑一下项目。
扩展
-
待办列表api的复杂使用
Listtasks = taskService.createTaskQuery().taskCandidateGroupIn(roleCodes).orderByTaskCreateTime().desc().list(); 以上这段代码只是查询过滤出多个用户组的待办信息,并根据执行任务创建时间倒序排序。
在实际项目中,一个用户查询到的待办信息很多,假设有1000条待办信息,那么我们在界面上不能全部展示出来,而是需要分页,而且还需要加上一些过滤条件方便在数据量多的情况下过滤出想要及时处理的数据。可以参照下面的写法://创建一个查询任务 TaskQuery taskQuery = taskService.createTaskQuery(); //后面可以接上各种查询条件,因为是链式调用 ListroleCodes = new ArrayList<>(); roleCodes.add("角色code1"); roleCodes.add("角色code2"); //查询角色code集合 taskQuery = taskQuery.taskCandidateGroupIn(roleCodes); String startTime = "2020-06-10 11:48:10"; String endTime = "2020-06-20 23:00:00"; //根据任务的起止时间查询 taskQuery = taskQuery.processVariableValueLessThan("create_time", endTime).processVariableValueGreaterThan("create_time", startTime); //根据业务类型查询 String businessType = "finance"; //财务审批类型 taskQuery = taskQuery.processVariableValueEquals("business_type", businessType); //根据任务时间排序并分页, 分页10条 int pageIndex = 0; int pageSize = 10; List tasks = taskQuery.orderByTaskCreateTime().desc().listPage(pageIndex, pageSize); //根据以上条件查询出来的结果计算总条数 long total = taskQuery.count(); -
flowable数据表详解
我们在接入flowable框架的时候,运行项目如果数据库没有flowable自带的表会自动创建出来,总共60张表,每张表都有其作用,下面会具体介绍表的用途。- 数据表的命名规则
ACT_RE_*
’RE’表示repository(存储)。RepositoryService接口操作的表。带此前缀的表包含的是静态信息,如,流程定义,流程的资源(图片,规则等)。
ACT_RU_*
’RU’表示runtime。这是运行时的表存储着流程变量,用户任务,变量,职责(job)等运行时的数据。flowable只存储实例执行期间的运行时数据,当流程实例结束时,将删除这些记录。这就保证了这些运行时的表小且快。
ACT_ID_*
’ID’表示identity(组织机构)。这些表包含标识的信息,如用户,用户组,等等。
ACT_HI_*
’HI’表示history。就是这些表包含着历史的相关数据,如结束的流程实例,变量,任务,等等。
ACT_GE_*
普通数据,各种情况都使用的数据。 - 数据表的介绍
表分类 表名 描述 运行实例表(10) ACT_RU_DEADLETTER_JOB 正在运行的任务表 ACT_RU_EVENT_SUBSCR 运行时事件 ACT_RU_EXECUTION * 运行时流程执行实例 ACT_RU_HISTORY_JOB 历史作业表 ACT_RU_IDENTITYLINK 运行时用户关系信息 ACT_RU_JOB 运行时作业表 ACT_RU_SUSPENDED_JOB 暂停作业表 ACT_RU_TASK * 运行时任务表 ACT_RU_TIMER_JOB 定时作业表 ACT_RU_VARIABLE * 运行时变量表 流程历史记录(8) ACT_HI_ACTINST * 历史的流程实例,记录流转的流程组件(节点、网关) ACT_HI_ATTACHMENT 历史的流程附件 ACT_HI_TASKINST * 历史的任务实例 ACT_HI_VARINST * 历史的流程运行中的变量信息 ACT_HI_COMMENT 历史的流程操作信息记录 ACT_HI_DETAIL * 历史的流程变量记录表 ACT_HI_IDENTITYLINK 历史的流程身份认证记录 ACT_HI_PROCINST 历史的流程定义实例记录 资源表(2) ACT_GE_BYTEARRAY * 存储部署的流程文件 ACT_GE_PROPERTY * 记录系统相关属性 身份认证表(9) ACT_ID_BYTEARRAY 二进制数据表 ACT_ID_GROUP 用户组信息表 ACT_ID_INFO 用户信息详情表 ACT_ID_MEMBERSHIP 人与组关系表 ACT_ID_PRIV 权限表 ACT_ID_PROPERTY 属性表 ACT_ID_TOKEN 系统登录日志表 ACT_ID_USER 用户表 ACT_ID_PRIV_MAPPING 私有人与组关系表 流程定义表(3) ACT_RE_DEPLOYMENT * 部署单元信息 (记录部署时间) ACT_RE_MODEL 模型信息 ACT_RE_PROCDEF * 已部署的流程定义(记录部署的资源路径) CMMN流程引擎数据表(11) ACT_CMMN_CASEDEF ACT_CMMN_DATABASECHANGELOGLOCK ACT_CMMN_DATABASECHANGELOG ACT_CMMN_DEPLOYMENT ACT_CMMN_DEPLOYMENT_RESOURCE ACT_CMMN_HI_CASE_INST ACT_CMMN_HI_MIL_INST ACT_CMMN_RU_CASE_INST ACT_CMMN_RU_MIL_INST ACT_CMMN_RU_PLAN_ITEM_INST ACT_CMMN_RU_SENTRY_PART_INST DMN流程引擎数据表(6) ACT_DMN_DATABASECHANGELOGLOCK ACT_DMN_DATABASECHANGELOG ACT_DMN_DECISION_TABLE ACT_DMN_DEPLOYMENT ACT_DMN_DEPLOYMENT_RESOURCE ACT_DMN_HI_DECISION_EXECUTION 表单引擎数据表(6) ACT_FO_DATABASECHANGELOG ACT_FO_FORM_DEFINITION ACT_FO_FORM_DEPLOYMENT ACT_FO_FORM_INSTANCE ACT_FO_FORM_RESOURCE ACT_FO_DATABASECHANGELOGLOCK 内容引擎数据表(3) ACT_CO_DATABASECHANGELOGLOCK ACT_CO_DATABASECHANGELOG ACT_CO_CONTENT_ITEM 其他表(2) ACT_EVT_LOG 事件日志记录 ACT_PROCDEF_INFO 流程定义信息 - 数据表的命名规则
-
Flowable引擎
- 流程引擎 (流程部署、待办查询、历史任务、身份认证、流程展示) *
- CMMN引擎(支持异步服务、手动激活规则、自动完成、用户事件监听器)
- DMN引擎(决策引擎, 如排他网关设置条件可以进行识别并决定走向) *
- IDM身份识别引擎 (自带一套身份认证体系)
- 表单引擎 (自带一套组件编辑器,可在界面画表单,实现流程流转)
- 内容引擎 (在mybatis上封装获取表元数据、流程模型等)
-
自定义sql
如果你的业务对于flowable的api接口还不满足,那么你可以写一些自定义的sql。如下代码示例://查询待办信息 public ListQueryTask(String businessType, List businessIds) { if(StringUtils.isEmpty(businessType) || ListUtil.isEmpty(businessIds)) { logger.warn("QueryTaskRecord请求参数为空. businessType:"+businessType+" businessIds:"+businessIds); return new ArrayList<>(); } StringBuffer businessIdsSb = new StringBuffer(); for(int i = 0;i < businessIds.size(); i++) { String businessId = businessIds.get(i); if (i == businessIds.size() - 1) { businessIdsSb.append("'" + businessId + "'"); } else { businessIdsSb.append("'" + businessId + "',"); } } StringBuffer sb = new StringBuffer(); sb.append("SELECT RES.*FROM ACT_RU_TASK RES " + "LEFT JOIN ACT_RU_VARIABLE VAR ON RES.`PROC_INST_ID_` = VAR.`PROC_INST_ID_`" + "WHERE RES.`PROC_INST_ID_` IN (" + "SELECT `PROC_INST_ID_` FROM ACT_RU_VARIABLE " + "WHERE `PROC_INST_ID_` IN (" + "SELECT `PROC_INST_ID_` FROM ACT_RU_VARIABLE " + "WHERE `NAME_` = 'business_id' AND `TEXT_` IN (" + businessIdsSb.toString() + ")" + ") AND `NAME_` = 'business_type' AND `TEXT_` = '" + businessType + "'" + ") group by VAR.`PROC_INST_ID_`" + "order by RES.`CREATE_TIME_` desc"); //通过传入自定义sql,返回的结果必须是ACT_RU_TASK的结果集,因为Task对应的表是ACT_RU_TASK,传入 List tasks = taskService.createNativeTaskQuery().sql(sb.toString()).parameter("business_type", businessType).list(); return tasks; } 当然你也可以使用mybatis等orm框架去实现自定义sql,但是使用TaskService和HistoryService服务提供自定义sql的api是有一定区别。这点需要注意,flowable框架的自定义sql的api在执行方法的时候有事务的隔离性,它允许节点执行跳转到下一个节点操作的时候查询待办可以到下一节点的待办信息,而使用orm框架则无法做到在同一方法里执行节点跳转再去查询下一节点的待办信息,因为此时的下一节点的数据还没存入到db中所以查询不到。
所以,我认为flowable框架是对自定义sql的api做了一些处理,做了事务的隔离性读取到未提交的数据,这里推荐使用它的api,虽然字符串拼接的sql属于硬编码,也不太雅观。