目录
IO基本概述
IO的分类
Java中IO的介绍
java IO概念
Java中的BIO、NIO、AIO
Java BIO
Java NIO
NIO 的主要组成部分:
Java AIO
Redis的网络通信模型
使用 select 和 poll 机制实现 IO 多路复用
使用 epoll 机制实现 IO 多路复用
IO基本概述
IO的分类
IO 以不同的维度划分,可以被分为多种类型;从工作层面划分成磁盘 IO (本地 IO )和网络 IO; 也从工作模式上划分: BIO、NIO、AIO; 从工作性质上分为阻塞式 IO 与非阻塞式 IO; 从多线程角度也可被分为同步 IO 与异步 IO。
Java中IO的介绍
传统的 java.io 包,它基于流模型实现,提供了最熟知的一些 IO 功能,比如 File 抽象、输入输出流等。交互方式是同步、阻塞的方式。 也把 java.net 下面提供的部分网络 API,比如 Socket、ServerSocket、HttpURLConnection 也归类到同步阻塞 IO 类库,因为 网络通信同样是 IO 行为。
在 Java 1.4 中引入了 NIO 框架(java.nio 包),提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层的高性能数据操作方式。
在实际面试中,从传统 IO 到 NIO、NIO 2,其中有很多地方可以扩展开来,考察点涉及方方面面,比如:
-
基础 API 功能与设计, InputStream/OutputStream 和 Reader/Writer 的关系和区别。
-
NIO、NIO 2 的基本组成。
-
给定场景,分别用不同模型实现,分析 BIO、NIO 等模式的设计和实现原理。
-
NIO 提供的高性能数据操作方式是基于什么原理,如何使用?
java IO概念
-
IO 不仅仅是对文件的操作,网络编程中,比如 Socket 通信,都是典型的 IO 操作目标。
-
输入流、输出流(InputStream/OutputStream)是用于读取或写入字节的,例如操作图片文件。
-
而 Reader/Writer 则是用于操作字符,增加了字符编解码等功能,适用于类似从文件中读取或者写入文本信息。本质上计算机操作的都是字节,不管是网络通信还是文件读取,Reader/Writer 相当于构建了应用逻辑和原始数据之间的桥梁
-
BufferedOutputStream 等带缓冲区的实现,可以避免频繁的磁盘读写,进而提高 IO 处理效率。这种设计利用了缓冲区,将批量数据进行一次操作,但在使用中千万别忘了 flush。
Java中的BIO、NIO、AIO
BIO 是一个同步阻塞 IO, 阻塞 I/O 难以支持高并发的场景。 NIO是一个 非阻塞 I/O,非阻塞的原因就是基于多路复用机制实现,高并发场景下效率非常高。 AIO是一个异步非阻塞IO,理论上讲, AIO的 吞吐量肯定比NIO的要大;但是实际上AIO的底层实现仍使用epoll,没有很好实现AIO,因此在性能上没有明显的优势,而且被JDK封装了一层,不容易深度优化。
Java BIO
BIO 就是Java的传统 IO 模型,与其相关的实现都位于 java.io 包下,其通信原理是客户端、服务端之间通过 Socket 套接字建立管道连接,然后从管道中获取对应的输入/输出流,最后利用输入/输出流对象实现发送/接收信息。 在基本的 Socket 编程模型中,accept 函数只能在一个监听套接字上监听客户端的连接,recv 函数也只能在一个已连接套接字上,等待客户端发送的请求, 只能处理一个客户端连接。
Java NIO
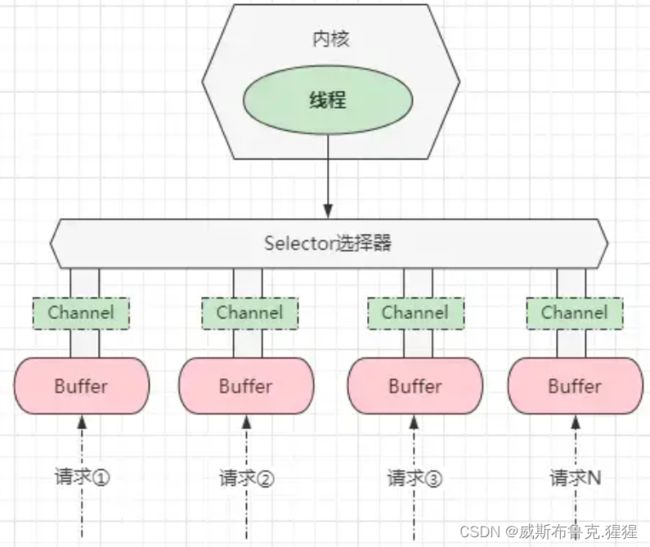
Java-NIO则是JDK1.4中新引入的API;NIO是一种基于通道、面向缓冲区的IO操作,相较BIO而言,它能够更为高效的对数据进行读写操作,同时与原先的BIO使用方式也大有不同。Java-NIO是基于多路复用模型实现的,其中存在 三大核心组成部分:Buffer(缓冲区)、Channel(通道)、Selector(选择器)。 NIO 利用单线程轮询事件的机制,通过高效地定位就绪的 Channel,来决定做什么,仅仅 select 阶段是阻塞的,就可以有效避免大量客户端连接时,频繁线程切换带来的问题,应用的扩展能力有了非常大的提高。
NIO 的主要组成部分:
-
Buffer,高效的数据容器,除了布尔类型,所有原始数据类型都有相应的 Buffer 实现。
-
Channel,类似在 Linux 之类操作系统上看到的文件描述符,是 NIO 中被用来支持批量式 IO 操作的一种抽象。File 或 Socket通常被认为是比较高层次的抽象,而 Channel 则是更加操作系统底层的一种抽象,这也使得 NIO 得以充分利用现代操作系统底层机制,获得特定场景的性能优化,例如,DMA(Direct Memory Access)等。不同层次的抽象是相互关联的,可以通过 Socket 获取 Channel,反之亦然。
-
Selector,是 NIO 实现多路复用的基础,它提供了一种高效的机制,可以检测到注册在 Selector 上的多个 Channel 中,是否有 Channel 处于就绪状态,进而实现了单线程对多 Channel 的高效管理。Selector 同样是基于底层操作系统机制,不同模式、不同版本都存在区别。
缓冲区、通道、选择器三者关系:
简单而言,在这三者之间, Buffer负责存取数据,Channel负责传输数据,而Selector则会决定操作那个通道中的数据。
Java AIO
Java 7 引入 NIO 2 ,增添了一种额外的异步 IO 模式,利用事件和回调,处理 Accept、Read 等操作。 Java-AIO与Java-NIO的主要区别在于:使用异步通道去进行IO操作时,所有操作都为异步非阻塞的,当调用read()/write()/accept()/connect()方法时,本质上都会交由操作系统去完成,比如要接收一个客户端的数据时,操作系统会先将通道中可读的数据先传入read()回调方法指定的缓冲区中,然后再主动通知Java程序去处理。
Redis的网络通信模型
通常系统实现网络通信的基本方法是使用 Socket 编程模型,包括创建 Socket、监听端口、处理连接请求和读写请求。但是,由于基本的 Socket 编程模型一次只能处理一个客户端连接上的请求,所以当要处理高并发请求时,一种方案就是使用多线程,让每个线程负责处理一个客户端的请求。 而 Redis 负责客户端请求解析和处理的线程只有一个,那么如果直接采用基本 Socket 模型,就会影响 Redis 支持高并发的客户端访问。 为了实现高并发的网络通信, Linux提供了 select、poll 和 epoll 三种函数实现多路复用机制,而在 Linux 上运行的 Redis,通常采用 epoll 函数实现多路复用机制进行网络通信。
什么是IO多路复用
I/O多路复用就是通过一种机制,单线程/单进程同时监听多个文件描述 符,一旦某个IO能够读写,通知程序进行相应的读写操作。
I/O多路复用的场合:
-
当客户处理多个描述字时(通常是交互式输入和网络套接字),必须使用I/O复用
-
如果一个TCP服务器既要处理监听套接字,又要处理已连接套接字,一般也要用到I/O复用
-
如果一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用
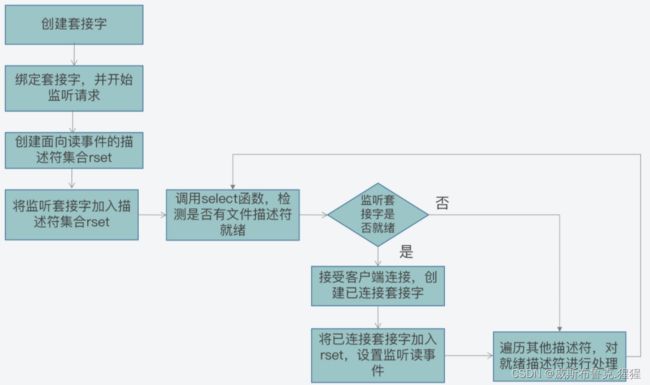
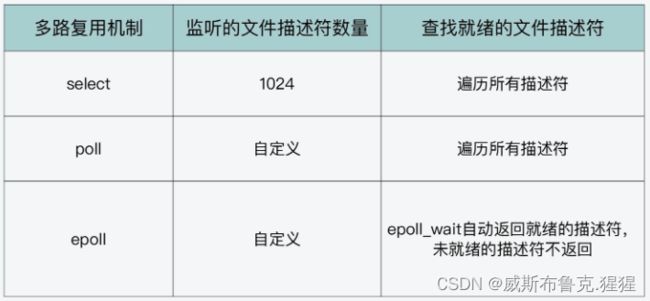
使用 select 和 poll 机制实现 IO 多路复用
select 函数存在两个设计上的不足:
1)select 函数对单个进程能监听的文件描述符数量是有限制的,它能监听的文件描述符个数由 __FD_SETSIZE 决定,默认值是 1024。
2) 当 select 函数返回后,需要遍历描述符集合,才能找到具体是哪些描述符就绪了。这个遍历过程会产生一定开销,从而降低程序的性能。
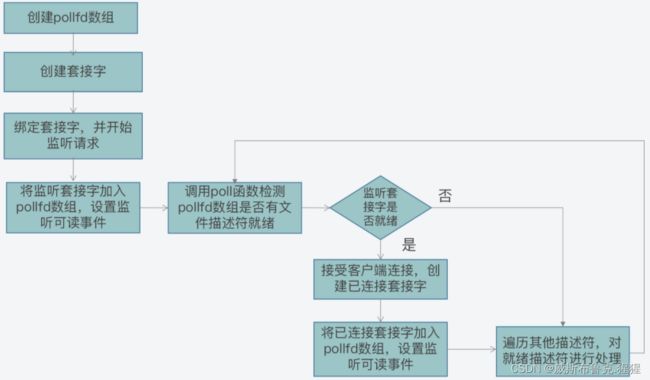
为了解决 select 函数受限于 1024 个文件描述符的不足,poll 函数对此做了改进。
和 select 函数相比,poll 函数的改进之处主要就在于,它允许一次监听超过 1024 个文件描述符。但是当调用了 poll 函数后,仍然需要遍历每个文件描述符,检测该描述符是否就绪,然后再进行处理;这样的轮询效率是很低的。那么,有没有办法可以避免遍历每个描述符呢?就是接下来 的 epoll 机制。
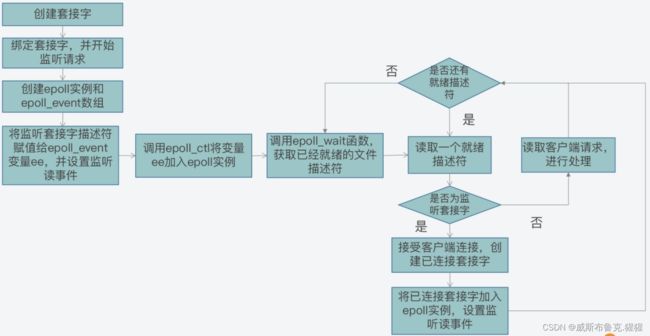
使用 epoll 机制实现 IO 多路复用
epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删查一般时间复杂度是 O(logn),通过对这棵黑红树进行操作,这样就不需要像 select/poll 每次操作时都传入整个 socket 集合,只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,只返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
这次答应我,一举拿下 I/O 多路复用!
正是因为 epoll 能自定义监听的描述符数量,以及可以直接返回就绪的描述符,Redis 在设计和实现网络通信框架时,就基于 epoll 机制中的 epoll_create、epoll_ctl 和 epoll_wait 等函数和读写事件,进行了封装开发,实现了用于网络通信的事件驱动框架,从而使得 Redis 虽然是单线程运行,但是仍然能高效应对高并发的客户端访问。epoll的这种变更触发轮询,变更触发回调直接读取,理论上无上限。下面通过一个例子更好的理解:
假设一个场景:有100万个客户端同时与一个服务器进程保持着TCP连接。而每一时刻,通常只有几百上千个TCP连接是活跃的(事实上大部分场景都是这种情况)。如何实现这样的高并发?
在select/poll时代,服务器进程每次都把这100万个连接告诉操作系统(从用户态复制句柄数据结构到内核态),让操作系统内核去查询这些套接字上是否有事件发生,轮询完后,再将句柄数据复制到用户态,服务器应用程序轮询处理已发生的网络事件,这一过程资源消耗较大。因此,select/poll一般只能处理几千的并发连接。
epoll的设计和实现与select完全不同:epoll通过在Linux内核中申请一个简单的文件系统(文件系统一般由B+树实现) 把原先的select/poll调用分成了3个部分:
调用epoll_create()建立一个epoll对象(在epoll文件系统中为这个句柄对象分配资源);
调用epoll_ctl向epoll对象中添加这100万个连接的套接字;
调用epoll_wait收集发生的事件的连接;
实现上面说是的场景,只需要在进程启动时建立一个epoll对象,然后在需要的时候向这个epoll对象中添加或者删除连接。同时,epoll_wait的效率也非常高,因为调用epoll_wait时,并没有一股脑的向操作系统复制这100万个连接的句柄数据,内核也不需要去遍历全部的连接。
Java中的NIO模型其实就是借用Linux的epoll和select这种多路复用的设计思想;JavaNIO模型中也有一个select函数。既然epoll比select效率高,那为啥Java不支持epoll而支持select模型呢?其实在JDK的源码中,在Linux2.6的JVM内核,JVM、JRE环境会将select模型直接转为epoll模型,虽然JDK中的函数叫select(),但是在Linux2.6的内核以上,它会以epoll模型的方式去运作,而在2.6以下只能用select模型。著名的NIO框架Netty,其实就是基于Java中NIO的select、epoll模型去完成对应的多路复用机制。