多模态 |COGMEN: COntextualized GNN based Multimodal Emotion recognitioN论文详解
论文:COGMEN: COntextualized GNN based Multimodal Emotion recognitioN
COGMEN: 基于GNN的多模态情感识别技术
论文实现可参考另外一篇论文:
本文主要分为俩部分,一是对论文的简单概括,二是对论文的翻译。
论文总结
论文翻译
摘要
情绪是人类行动的一个固有部分,因此,开发能够理解和识别人类情绪的人工智能系统势在必行。在涉及不同人的对话中,一个人的情绪会受到其他说话者的言语和他们自己在言语中的情绪状态的影响。在本文中,我们提出了基于 COntex- tualized Graph Neural Network的多模态情感识别COGMEN)系统,该系统利用了本地信息(即说话人之间的内/外依赖性)和全局信息(上下文)。建议的模型使用基于图谱神经网络 (GNN) 的架构来模拟对话中的复杂关系(本地和全局信息)。我们的模型在IEMOCAP和MOSEI数据集上给出了最先进的 (SOTA)结果,详细的消融实验显示了在两个层面上对信息进行建模的重要性、
1.介绍
情绪是人类固有的,指导着他们的行为,并表明了基本的思维过程 (Minsky. 2007)。因此,理解和识别情绪对于开发与人类直接互动的人工智能技术(如个人数字助理) 至关重要。在一些人的对话中,每个人所经历和表达的情绪不断起伏。多模态情感识别任务解决的问题是监测个人在不同场合(如对话) 所表达的情感(通过各种模态,如视频(面部)、音频(语音))。
情绪是对认知处理的刺激物的生理、行为和交流反应(Planalp等人,2018)。情绪是内部生理变化的结果,而这些生理反应可能不会被其他人注意到,因此是个人内部的。例如,在对话环境中,情绪可能是一种交际反应,它在另一个人所说的句子中作为一种刺激。语篇中表达的情绪状态与语境直接相关;例如,如果基本语境是关于一个简介快乐的话题,如庆祝节日或描述一个假期,就会有更多的积极情绪,如喜悦和惊喜。考虑到图1所示的例子,其中的语境描述了一个令人理解和识别情绪对于开发与人类直接互动的兴奋的对话。说话人1对他的录取感到兴奋,这影响了语境中的情绪流动。

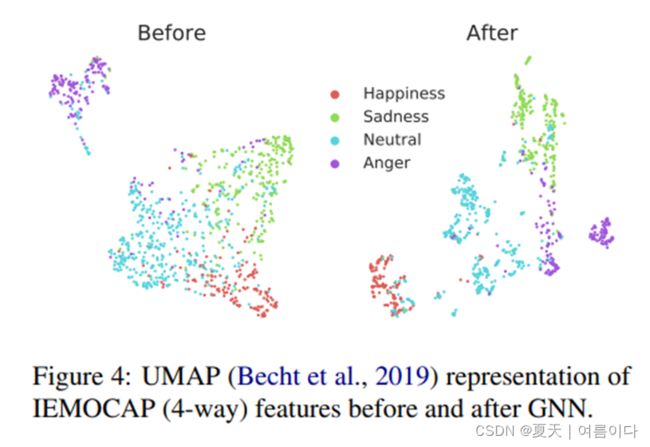
图1:两个说话者之间的对话实例,每句话都有相应的情绪被唤起。
整个语境发言人2的情绪状态在,2,4,6中显示了对发言人1的依赖性,并,4 中通过发言人反应感到好奇而保特了个人內部状态。这个对话例子描绘了 全局信息以及说话人之间和内部的依赖性对话语的情绪状态的影响。此外,情绪是一种多模态现象;一个人从不同的模态(如音频、视频)中获取线索来推断他人的情绪,因为,很多时候,在不同的情况下,不同的模式中形成相互补充。
在本文中,我们利用这些直觉,提出了cogmen:基于语境化图神经网络的多模式情感识别架构,该架构解决了语境对话语的影响以及用于预测对话期间每个说话人每句话情感的相互依存和内部依存。
关于单模态(仅使用文本)预测已经有很多工作,但我们的重点是多峰情感预测。正如在多模态情绪预测的文献中所做的那样,我们不关注与单峰模型的比较。实验和消融研究表明,我们的模型利用了信息的来源(即局部和全局),在多模式情感识别数据集iemocap和mosei上给出了最先进的(sota)结果。
我们提出了一种基于语境图神经网络(GNN)的多模式情感识别架构,用于预测对话中每个说话人的每个话语的情感。我们的模型在对话中利用了局部和全局信息。我们使用图形变换(SHI等人,2021)对多模式情感识别系统中的说话人关系进行建模。
- 我们的模型在IEMOCAP和MOSEI的多模式情感识别数据集上给出了SOTA结果。
- 我们对模型及其不同组件进行了彻底分析,以显示局部和全局信息的重要性以及 GNN组件的重要性。
2.相关工作
3.提出模型
本地信息
全局信息
3.1.全局框架
图2显示了详细的体系结构。输入的话语作为语境提取器模块的输入,该模块负责捕获全局语境。语境提取器为每个话语(utterance)提取的特征形成了一个基于说话人之间交互的图(Graph Formation)。该图作为Relational - GCN的输入,然后是graph transformer,graph transformer使用形成的图来捕捉话语之间的内部和内部关系。最后,作为情感分类器的两个线性层使用所有话语获得的特征来预测相应的情感。

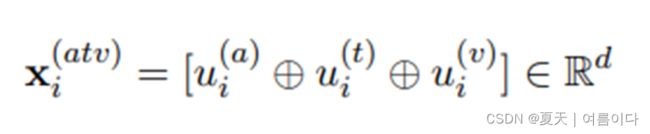

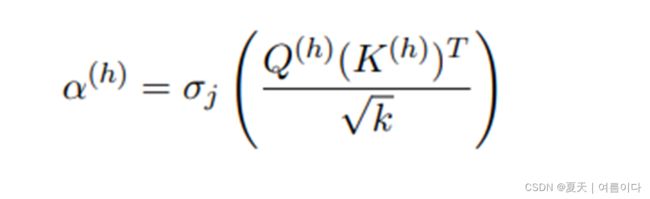
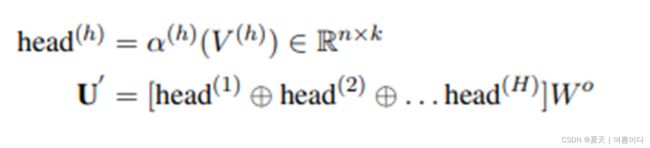
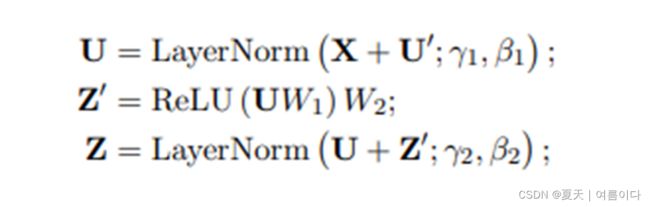
图的形成 Graph Formation:
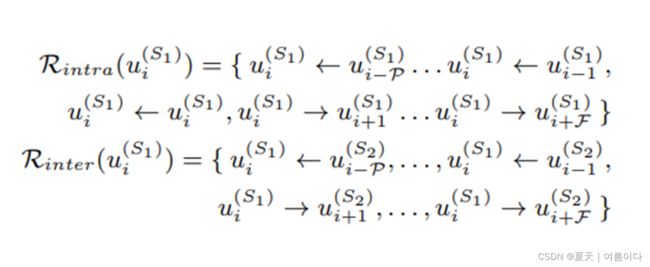
关系图卷积网络 Relational Graph Convolutional Network (RGCN):

图转换器(GraphTransformer):


我们在两个广泛使用的数据集上进行情感识别任务的实验:IEMOCAP(BUSSO等人,2008)和MOSEI(ZADEH等人,2018B)。数据集统计数据如表1所示。
IEMOCAP是一个二元多模式情感识别数据集,其中对话中的每个话语都被标记为六种情感类别之一:愤怒、兴奋、悲伤、幸福、沮丧和中性。在文献中,两种IEM OCAP设置用于测试,一种具有4种情绪(愤怒、悲伤、幸福、中性),另一种具有6种情绪。我们对这两种设置都进行了实验。
MOSEI是一个多模式情绪识别数据集,由7种情绪(-3(高度消极)到+3(高度积极))和6种情绪标签(幸福、悲伤、厌恶、恐惧、惊讶和愤怒)注释。注意,不同数据集的情绪标签不同。我们使用加权F1分数和准确性作为评估指标(详见附录C)。
情感分类器:在由图转换器 hi 提取特征上的线性层,预测与词相应的情绪。
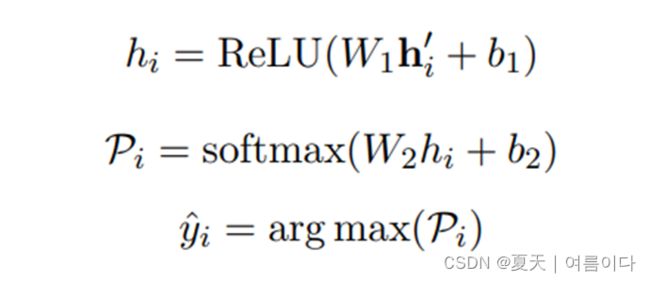
其中 yi 是对 的utternce ui的情感标签预测。
4.实验
实验细节:对于IEMOCAP,使用OPENSMILE提取音频特征(尺寸100)(EYBEN等人,2010),从BALTRUSAITIS等人(2018)提取视频特征(尺寸512),使用SBERT提取文本特征(尺寸768)(REIMERS和GUREVYCH,2019)。
MOSEI数据集的音频特征取自DELBROUCK等人(2020),使用80个滤波器组的LIBROSA(MCFEE等人,2015)提取,使特征向量大小为80。视频特征(尺寸35)取自ZADEH等人(2018B)。使用SBERT获得文本特征(大小768)。语篇特征是句子层面的静态特征。对于音频和视觉模式,我们通过平均所有标记级特征来使用句子/话语级特征。
我们通过级联融合了所有可用模式(a(音频)+t(文本)+v(视频):atv)的功能。我们还探讨了其他融合机制(附录g.1)。然而,级联提供了最好的性能。我们使用贝叶斯优化技术对我们提出的模型进行了超参数搜索(详见附录a)。
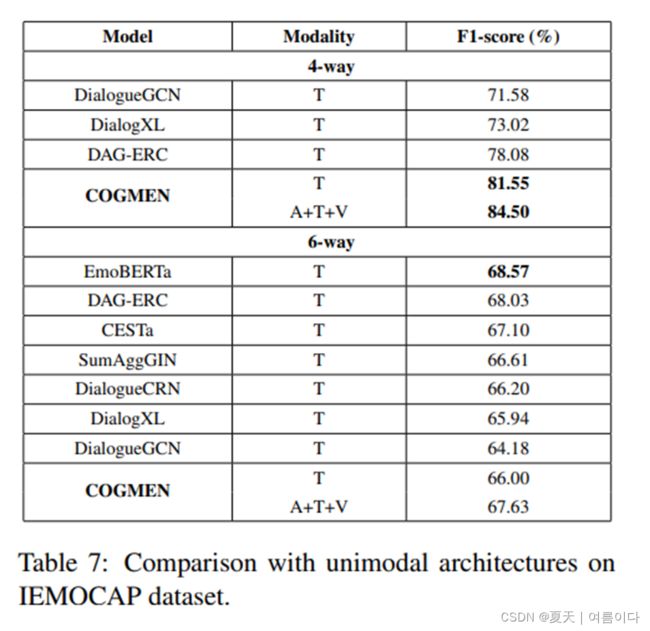
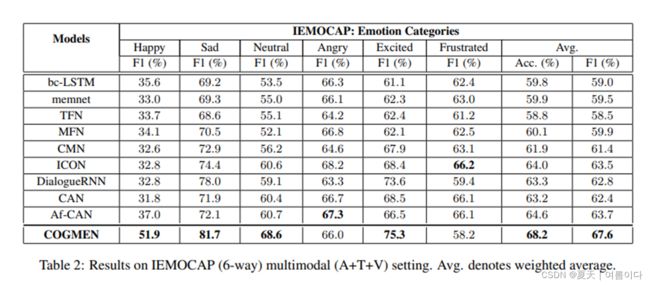
通过将COGMEN与许多基线模型进行比较,我们对COGMEN进行了全面评估。对于IEMOCAP,我们将我们的模型与现有的多模式框架进行比较(表2),其中包括DIALOGUERNN(MAJUMDER等人,2019)、 BC-LSTM(PORIA等人,2017)、CHFUSION(MAJUMDER等人,2018)、MEMNET(SUKHBATAR等人,2015)、TFN(ZADEH等人,2017)、MFN(ZADEH等人,2018A)、CMN(HAZARIKA等人,2018B)、ICON(HAZARIKA等人,2018A)和AF-CAN(王等人,2021B)。
对于MOSEI,COGMEN与多模式模型进行了比较(表4),包括多模式网络(SHENOY和SARDANA,2020年)和TBJE(DELBROUCK等人,2020年)(关于基线的详细信息和分析,见§6)。

5.结果和分析