Linux内存分配器(页面/slab/per-CPU)API
一、pglist_data(物理内存节点)、zone_type(物理内存区域)和page(物理内存页)
1)pglist_data
二种物理内存模型如下所示,其中UMA模型中所有内存空间对系统中的处理器而言具有相同的访问特性,也即系统中所有处理器对这些内存的访问具有相同的速度;而在NUMA中处理器与处理器之间通过总线连接起来以支持对其他处理器本地内存的访问,处理器访问本地内存的速度要快于其他处理器本地内存。
在Linux中以struct pglist_data数据结构来标识单个node,对于NUMA模型,多个node通过链表串联起来;UMA模型只有一个node,因为不存在这样的链表。

2)zone_type
考虑到系统的各个模块对分配的物理内存有不同的要求,因此将每个node管理的物理存储划分为不同的zone
/*在内核启动过程中调用paging_init()进行初始化。在初始化每个Zone的时时候会调用init_page_count
函数将每个页帧引用计数设置为1。因为此时此时内存还处于BootMem管理器的控制下,这些页帧尚未转交
到伙伴系统(内存页帧管理器),不是自由页帧(自由页帧的引用计数为1),不可以被伙伴系统的页帧分配函数
分配*/
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*包括所有物理地址小于16M的页面,设置这个区的目的是为ISA/LPC等DMA能力只有24bit地址的设备
服务*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*包括ZONE_DMA区之外的物理地址小于4GB的页面,设置这个区的目的是为DMA能力只有32bit地址
的设备服务。为什么需要这二种DMA区域?因为DMA使用总线地址(从设备角度看到的地址,也叫DMA地址,
在没有iommu的情况下等于物理地址/DDR上的地址,在有iommu的情况下经过转换得到物理地址),该地址
并不经过MMU,,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空
间专门划分一段区域用于DMA*/
ZONE_DMA32,
#endif
/*常规内存访问区域由ZONE_NORMAL表示,如果DMA设备可以在此区域,作内存访问,也可以使用该
区域*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*该区域无法从内核态虚拟地址空间直接作线性映射,所以为访问该区域必须经内核作特殊的页映射。
对于32bit的CPU,当内核空间被划分1GB的线性地址表达范围时,除了线性映射,比如一对一线性映
射DMA、NORMAL这些zone后,剩下的线性地址范围就不多了,可能不足以再线性映射剩余的物理内存
区域(ZONE_HIGHMEM),对此内核采取了动态映射的方法,即按需的将ZONE_HIGHMEM里的物理页面
映射到内核空间剩余的虚拟地址空间里,使用完之后释放映射关系,以供其它物理页面映射。虽然这样
存在效率的问题,但是内核毕竟可以正常的访问所有的物理地址空间了。
对于64bit的CPU,一般内核虚拟地址空间够大,远大于物理内存,这个时候也就不需要ZONE_HIGHMEM了
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};3)page
也叫page frame,是物理内存管理中的最小单位,Linux将系统物理内存的每个页都创建一个struct page对象,系统用统一全局变量struct page *mem_map来存放所有物理页page对象的指针。页的大小取决于MMU
二、伙伴系统分配器(页面分配器)
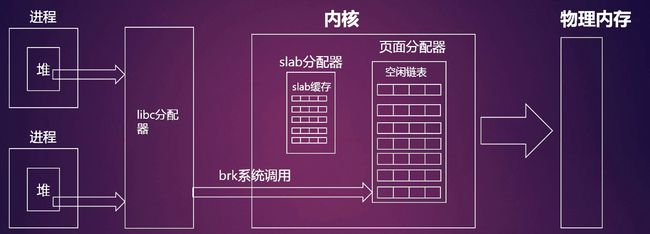
对物理内存进行分配的核心建立在页面级的伙伴系统之上。在系统初始化期间,伙伴系统负责对物理内存页面进行追踪,记录哪些是已经被内核使用的页面,哪些是空闲页面。有了伙伴系统就可以让系统分配单个物理页面或者连续的几个物理页面。
在驱动开发时可以利用页面分配器提供的接口函数的gfp_mask参数来决定在不同的zone上分配的行为。通常这些以"__"打头的GFP掩码只限于在内存管理组件内部的代码使用,对于提高给外部的接口,比如驱动程序中所使用的页面分配函数,gfp_mask掩码以"GFP_"的形式出现,例如内核为外部模块提供的最常用的几个掩码如下:
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOIO (__GFP_RECLAIM)
#define GFP_NOFS (__GFP_RECLAIM | __GFP_IO)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_DMA __GFP_DMA
#define GFP_HIGHUSER (GFP_USER | __GFP_HIGHMEM)
......1)alloc_pages()和__free_pages()
/*分配2^order个连续的物理页面并返回起始页的struct page实例*/
static inline struct page *alloc_pages(gfp_t gfp_mask, unsigned int order)
{
return alloc_pages_node(numa_node_id(), gfp_mask, order);
}
/*参数page为alloca_pages()时的返回的page对象指针*/
void __free_pages(struct page *page, unsigned int order)
{
if (put_page_testzero(page))
free_the_page(page, order);
else if (!PageHead(page))
while (order-- > 0)
free_the_page(page + (1 << order), order);
}2)__get_free_pages()/get_zeroed_page()/__get_dma_pages()和free_pages()
/*分配2^order个连续的物理页面,返回起始页面所在内核线性地址(位于内核虚拟地址空间的直接映射区,
通常ZONE_NORMAL和ZONE_DMA是直接映射的?)。*/
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{
struct page *page;
/*由以下代码可以看出不能从ZONE_HIGHMEM这个zone中分配物理页*/
page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);
if (!page)
return 0;
/*通过page_address来返回这些页面中起始页面的内核线性地址*/
return (unsigned long) page_address(page);
}
/*用于分配一个物理页同时将对应的内存填充为0,函数返回页面所在的内核线性地址*/
unsigned long get_zeroed_page(gfp_t gfp_mask)
{
return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}
/*用于从ZONE_DMA这个zone中分配物理页,返回页面所在的线性地址*/
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA, (order))
/*参数addr为__get_free_pages()返回的内核线性地址*/
void free_pages(unsigned long addr, unsigned int order)
{
if (addr != 0) {
VM_BUG_ON(!virt_addr_valid((void *)addr));
__free_pages(virt_to_page((void *)addr), order);
}
}三、slab分配器(这里将slab, slob和slub统称为slab分配器)
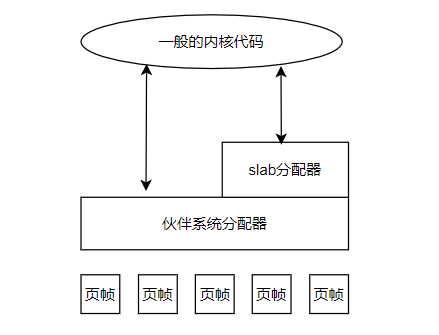
Linux内核在物理页分配的基础上实现了对小于page大小的物理内存的分配。它的基本思想是先利用页面分配器分配出单个或者一组连续的物理页面,然后在此基础上将整块页面分割成多个相等的小内存单元。slab分配器的数据结构如下所示:
//linux-6.1/include/linux/slab_def.h
struct kmem_cache {
......
/*指明该kmem_cache中每个slab占用的页面数量,为2^gfporder个页*/
unsigned int gfporder;
......
/*构造函数。当在kmem_cache中分配一个新的slab时,用来初始化slab中的所有内存对象*/
void (*ctor)(void *obj);
/*kmem_cache的名字,会导出到/proc/slabinfo中*/
const char *name;
/*系统中的slab分配器并不是孤立的,内核通过一个全局的双向链表cache_chain将
每一个slab分配器链接起来(通过slab分配器keme_cache中的struct list_head list成员)*/
struct list_head list;
struct kmem_cache_node *node[MAX_NUMNODES];
};另外注意还有一个struct slab结构,struct kmem_cache和struct slab在一个slab分配器中形成分级管理。如下图所示便为slab分配器框架,通过struct kmem_cache_node中的三个链表成员slabs_full(表示链表中的每一个slab所在的物理内存都已经分配完)、slabs_partial(表示链表中每一个slab所在的物理内存页还有部分空间可继续用于分配)和slabs_free(表示链表中每一个slab所在的物理内存页完全空闲,没有分配任何内存对象)将其下的所有struct slab实例加入对应链表。
struct slab结构用于管理一块连续的物理页面中内存对象的分配。在实际的代码实现中,struct slab的实例存放位置有二种:一种是如下图所示将struct slab的实例放在物理页面首页的开始处;另一种是放在物理页面的外部(通过kmalloc()函数来分配slab的实例)。内核将从性能优先的角度出发来决定slab实例的存放位置,源码中CFLGS_OFF_SLAB宏用户表示slab对象存放于外部。

从上图可以看出,每一个slab分配器,都需要一个struct kmem_cache实例,那么在slab系统尚未完全建立起来时,kmem_cache实例所在的空间从哪里分配?答案是在系统初始化期间提供了一个特殊的slab分配器kmem_cache_boot,专门用来分配struct kmem_cache空间。因为kmem_cache_boot在slab系统还未完备时就被创建了出来,所以这个struct kmem_cache结构采用了静态内存分配的方法。
#define BOOT_CPUCACHE_ENTRIES 1
/* internal cache of cache description objs */
static struct kmem_cache kmem_cache_boot = {
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.shared = 1,
.size = sizeof(struct kmem_cache),
/*这个最早的keme_cache的名字叫"kmem_cache",告诉我们它所领衔的slab分配器专门用来分配
struct kmem_cache这样的内存对象,这点从上面的".size = sizeof(struct kmem_cache)"
可以看出*/
.name = "kmem_cache",
};
void __init kmem_cache_init(void)
{
kmem_cache = &kmem_cache_boot;
......
list_add(&kmem_cache->list, &slab_caches);
......
}1)kmalloc() / kzalloc()和kfree()
/*
分配出来的物理内存是连续的,函数不负责把发呢配出的内存空间中的内容清零。
参数gfp未分配掩码,前面的页面分配器函数一样,会影响到伙伴系统对zone中空闲页的查找行为
*/
void *kmalloc(size_t size, gfp_t gfp);
/*会用0来填充分配出来的物理内存空间*/
static inline void *kzalloc(size_t size, gfp_t gfp)
{
return kmalloc(size, gfp | __GFP_ZERO);
}
/*释放上面所分配的内存*/
void kfree(const void *object)2)kmem_cache_create()和kmem_cache_destroy()
提供小内存分配并不是slab分配器的唯一用途。在某些情况下,有些内核模块可能需要频繁地分配和释放相同的内核对象;slab分配器在这种情况下可以作为一种内核对象的缓存:对象在slab中被分配,当释放对象时,slab分配器并不会将对象占用的空间返回给伙伴系统,如此,当再次分配该对象时,可以从slab中直接得到对象的内存。
/*
创建内核对象缓存,新分配的kmem_cache对象最终会被加入到kmem_chain所表示的链表中。可以通过
/proc/slabinfo查看当前系统中有多少活动的kmemc_cache。
1)参数name用来表示生成的kmem_cache的名称,该名称多导出到/proc/slbinfo文件,需要注意的是
创建出来的kmem_cache对象会用一个指针指向该name,因此函数的调用者必须确保传入的name指针在
kmem_cache的整个生命周期都有效,否则可能导致无效的引用。
2)参数size用来指定在缓存中分配对象的大小。
3)参数align用于指定数据对齐时的便宜量。内核代码的调用中这个参数几乎全为0,也即它的默认值。
4)参数flags是用于创建kmem_cache时的标志位掩码,0表示默认值,驱动中常用的标志位有:
SLAB_HWCACHE_ALIGN
该标志要求slab分配器中的所有内存对象跟处理器的cache line对齐,如果能将一些会被频繁
访问的对象放入到高速缓存行中,将会大幅提升内存访问性能。但是对齐的要求会在对象与对象
之间造成无用的填充,从而造成内存的浪费。
SLAB_CACHE_DMA
在slab分配器调用伙伴系统获得内存页时,告诉伙伴系统在ZONE_DMA这个zone获得内存页。
SLAB_PANIC
在kmem_cache分配失败时将导致系统panic。
5)最后一个参数ctor是个函数指针,称为kmem_cache的构造函数。如果函数的调用者提供了该函数,那么
当slab分配器分配一块新的页面时,会对该页面中的每个内存对象调用此处的构造函数。所以此处的构造函数
并不是在每次分配一个对象时都会被调用。
*/
struct kmem_cache *kmem_cache_create(const char *name, unsigned int size,
unsigned int align, slab_flags_t flags, void (*ctor)(void *))
{
return kmem_cache_create_usercopy(name, size, align, flags, 0, 0, ctor);
}
/*把kmem_cache_create创建的kmem_cache对象销毁。*/
void kmem_cache_destroy(struct kmem_cache *s)3)kmem_cache_alloc()和kmem_cache_free()
/*
在上面创建了一个kmem_cache对象之后,就可以通过如下函数在kmem_cache中分配对象了。
1)参数cachep就是kmem_cache_create函数返回的kmem_cache对象的指针。
2)参数flags是页面分配器使用的掩码。只有kmem_cahce_alloc在内部需要与页面分配器交互时才会用到
这个参数。
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
return __kmem_cache_alloc_lru(cachep, NULL, flags);
}
/*
把kmem_cache_alloc分配的对象释放掉。
1)参数cachep是kmem_cache对象的指针。
2)参数objp是要释放的内存对象的指针。
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp)四、vmalloc()和vfree()和ioremap()和iounmap()
/*分配的虚拟地址空间所映射的物理内存不一定连续,效率没有kmalloc高。它的实现主要包括三步:
step1: 在内核虚拟地址空间的vmalloc区域分配出一块连续的虚拟内存区域(通过红黑树)
step2:通过伙伴系统获得zone上的物理页。
step3:通过对页表的操作将step1中分配的虚拟内存映射到步骤2中获得的物理页上。
*/
void *vmalloc(unsigned long size
/*释放vmalloc获得的虚拟地址和块,它执行的是vmalloc的反操作*/
void vfree(const void *addr)
/*ioremap实现与体系结构有关,例如x86下的函数如下,另外还有一些变体ioremap_xxx(),这些变体
的主要功能是通过加入一些映射标志位来影响相关内核页表项的设置。
1)此时的__iomem的作用只是提醒调用者返回的是一io类型的地址,如同__user, __percpu一样,某些
工具软件有可能会利用这些定义符做一些诸如代码质量等方面的检查。
2)ioremap函数及其变种用来将内核虚拟地址空间的vmalloc区域的某段虚拟地址映射到I/O空间,其实现
原理与vmalloc()函数基本一样,都是通过在vmalloc区域分配虚拟地址快,然后修改内核页表的方式将
其映射到设备的内存区,也就是设备的I/O地址空间。与vmalloc不同的是ioreamp并不通过伙伴系统去分配
物理内存,因为ioremap要映射的目标地址是I/O空间,而不是物理内存。
*/
void __iomem *ioremap(resource_size_t phys_addr, unsigned long size)
/*将内核虚拟地址空间vmalloc区中分配的虚拟内存块返回给vmlloc区,清除对应的页表页目录项等*/
void iounmap(volatile void __iomem *addr)五、per-CPU内存分配器的使用
per-CPU变量的核心思想是通过为操作系统中每个处理器都分配一个CPU特定的变量副本。这样做的好处是,在多处理器系统中,当处理器操作属于它的变量副本时,不需要考虑与其他处理器竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓存以提高访问速度。例如在网络系统中,内核需要跟踪已经接收到的各类数据包的数量,让系统中每个处理器都使用属于自己的该变量的副本,这样在变量更新时就无需考虑多处理器的锁定问题,可以提高性能。如果需要统计出系统接收数据包的总量,只要将各处理器副本中的值相加即可。
1)静态per-CPU变量使用示例
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
#define get_cpu_var(var) \
(*({ \
preempt_disable(); \
this_cpu_ptr(&var); \
}))
#define put_cpu_var(var) \
do { \
(void)&(var); \
preempt_enable(); \
} while (0)
.......................................................................
struct birth_day {
int day;
int month;
int year;
};
/*定义一个静态per-CPU变量my_birthdy,变量类型为struct birth_day*/
static DEFINE_PER_CPU(struct birth_day, my_birthday) = {24, 03, 94};
/*通过get_cpu_var访问该变量,其会调用preempt_disable()来关闭内核可抢占性,这是因为
对于可抢占的内核而言,即使是在单处理器上,仍会有竞争的情况出现。关闭可抢占性可确保在
对per-CPU变量操作的临界区中,当前进程不会被换出处理器。由于这个因素的存在,需要一个
和get_cpu_var配对使用的宏put_cpu_var来恢复内核调度器的可抢占性。*/
get_cpu_var(my_birthday).year++,
put_cpu_var(my_birthday);如果要读取其他处理器的副本,可以使用如下API
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))2)动态per-CPU变量使用实例
#define per_cpu_ptr(ptr, cpu) ({ (void)(cpu); VERIFY_PERCPU_PTR(ptr); })
#define alloc_percpu(type) \
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), \
__alignof__(type))
...................................................................
/*Linux-6.1/drivers/dma/dmaengine.c*/
struct dma_chan_tbl_ent {
struct dma_chan *chan;
};
static struct dma_chan_tbl_ent __percpu *channel_table[DMA_TX_TYPE_END];
/*动态分配一类型为struct dma_chan_tbl_ent的per-CPU变量,channel_table[cap]为指向
变量所在空间的地址*/
channel_table[cap] = alloc_percpu(struct dma_chan_tbl_ent);
/*通过per_cpu_ptr得到特定CPU上的变量指针*/
for_each_possible_cpu(cpu)
per_cpu_ptr(channel_table[cap], cpu)->chan = NULL;
...
/*程序不再需要使用该变量,释放其所在空间*/
free_percpu(channel_table[cap])如果考虑到内核的抢占性可能造成的问题,那么在使用per_cpu_ptr的时候需要用get_cpu和put_cpu来关闭和开启内核的可抢占性,如下面的代码所示
/*__smp_processor_id()可以返回当前活动处理器的ID*/
#define get_cpu() ({ preempt_disable(); __smp_processor_id(); })
#define put_cpu() preempt_enable()
......................................................................
/*获取当前处理器并禁止抢占*/
int cpu = get_cpu();
struct dma_chan_tbl_ent *ptr = per_cpu_ptr(channel_table[cap], cpu);
/*开始使用ptr*/
L0:
......
L1:
/*结束ptr的使用,激活内核抢占*/
put_cpu();这里关于可抢占性的问题在于,假设内核启动了调度器的可抢占性,如果在L0与L1之间发生中断的话,当前进程可能被切换出处理器CPU0,那么等到下次该进程被调度执行时,调度器在极端情况下可能把该进程提交到另一个处理器CPU1上运行,CPU1拥有一个指向CPU0本地变量副本的指针,此时当初per-CPU变量被设计出来的初衷就被坏了。更深层次探讨本例中出现的问题,貌似是把ptr的获得和使用分散开造成的,然而,若不能保证对per_cpu_ptr使用的原子性,这个问题总是存在的。
所以为了安全起见,per_cpu_ptr结合get_cpu和put_cpu的配对使用,总是没错的。
六、内存池
总体思想是:预先为将来要使用的数据对象(比如a)分配几个内存空间,把这些空间地址放在内存池对象中。当代码真正需要为a分配空间时就可以使用从内存池中取得预先分配好的a的地址空间。
reference:
https://blog.csdn.net/weixin_45030965/article/details/126289230
http://linux.laoqinren.net/kernel/percpu-var/
https://www.bilibili.com/video/BV1iY4y1B7A2