【C/C++】内存管理(一):shared_ptr
智能指针是
侯捷在他的教程中提到:C++中一个 class type 的对象可能有两种特殊的情况:像一个指针(pointer-like class,迭代器、智能指针),或者像一个类(仿函数)。为什么要做一个“像指针”的类?因为可能语言的设计者觉得,承接自C语言的普通指针,其功能已经无法满足C++在C语言之外扩展的新功能的需求了。因此现在需要一种新的指针,它首先是个指针,却能比指针做更多。
其实智能指针就是指针之外的一层封装,这些智能指针类都重载了 * 和 -> 运算符,因此完全可以当成普通指针去用(这跟迭代器其实有一些相似,都是C++中的一些特殊的指针)。一个 pointer-like class 最基本的特点也就很清晰了:
- 有一个数据成员是真正的指针;
- 重载了 * 和 -> 运算符;
- 它的构造函数需要接收一根真正的指针去为数据成员赋初值。
本文作为智能指针系列的第一部分,主要记录 shared_ptr 相关用法。
shared_ptr
通常来说,动态申请了一片内存之后,可能会在多个地方会用到。对于裸指针,你需要自己记住在什么地方释放内存,不能在有别的地方还在使用的时候,你就释放,也不能忘记释放。而shared_ptr 对象里,不但有一个真正的指针,还有一个用于维护计数的 count 。有人用到这块内存的时候,count 增加 1,而不用的时候(离开作用域或者生命周期外),count 减少 1,如果一块内存的引用计数为 0,则自动释放内存。
所谓 share ,就是指这个智能指针指向的内存同时可以被多个 shared_ptr 所指(当然就会产生类似多线程的问题,姑且按住不表)。count 就负责统计当前时刻指向这块内存的 shared_ptr 的个数。很容易想到,这个 count 一定是所有 shared_ptr 共同维护的一个值,因此是 static 的,然而这是极其错误的理解!
如果这个 count 仅仅是一个 static int ,那么一个 share_ptr 的实例化类,比如 share_ptr 就只有这一个 count,所有 share_ptr 类对象共同维护一个 count,而不管这些对象分别指向哪块内存。这显然是不合理的。
事实上,通过观察数据结构可知,当指向一块内存的第一个智能指针创建的时候,也会为这块内存在堆上创建一个控制块。即引用计数这个东西是在堆上的,多个智能指针指向堆上的同一块地址,来维护引用计数。
默认情况下,一个用来初始化智能指针的普通指针必须指向动态内存,即 new 出来的内存(在堆上而非栈里)。因为智能指针默认的删除器是 delete。如果不是 new 出来的(比如malloc),需要显式传递删除器。make_shared 会使用其参数来构造一个相应类型的对象,这个也是动态的。
(一)基本操作
1.1 初始化
shared_ptr<string> p1; //初始化没有赋初值,则p1里面真正的指针被初始化为nullptr
shared_ptr<string> pint1 = make_shared<string>("safe uage!"); //安全的初始化方式
【重点】能用make_shared 就不用其它的。
1.2 改变计数的操作:赋值、拷贝、reset
① 赋值:
// #case 1
auto sp1 = make_shared<string>("obj1"); //sp1.use_count() = 1,本质是obj1的引用计数为1
auto sp2 = make_shared<string>("obj2"); //sp2.use_count() = 1,本质是obj2的引用计数为1
auto sp1 = sp2; //sp1指向obj2,obj2的引用计数为2,sp1和sp2的count都是2,obj1引用计数为0被释放
// #case 2
shared_ptr<int> sp3 (new int, [](int* p){delete p;}, std::allocator<int>());
shared_ptr<int> sp4 (sp3); //sp3 和 sp4 的 count 都是2
shared_ptr<int> sp5 (std::move(sp4)); //sp5 偷走了 sp4 指向那块内存的指针,sp4 的 count 变为 0,其余两个为 2
注:1. 获取一根智能指针 count 值的函数:use_count()
2. 一根智能指针语义上是指针,语法上是对象,因此访问成员用 " . " 而非 " -> "
3. std::move 会将 sp4 强制转换为相应的右值,调用 move-ctor ,sp4 失效
4. sp1 = sp2 修改智能指针的指向,并不是一个原子操作
② 拷贝:
auto sp1 = make_shared<string>("obj");
auto sp2(sp1); //sp1和sp2指向同一个对象,二者的count都是2
func(sp2); //※
对于func(sp2),需要分情况讨论:
- 当 func 的参数是一个
shared_ptr对象时,由于传参过程中发生值拷贝,则 func 执行过程中,有 sp1 和 sp2 以及 pass by value 生成的 sp2’ 三根智能指针 指向 obj ,因此三者的 count 都是3。func 结束后,由于 sp2’ 是 auto 生命期的变量,会被自动释放,因此 sp1 和 sp2 两根指针指向obj,二者的 count 恢复为2。 - 当 func 的参数是一个
shared_ptr对象的引用时,传参过程中发生 pass by reference,没有 sp2’ 生成,二者的 count 一直是 2。
1.3 reset()
所谓 reset,就是“重置”。断开这根智能指针与当前内存的连接,把它连接到括号里那个对象的内存上。
【例 1】
int main(){
shared_ptr<test> p1(new test(1));
shared_ptr<test> p2 = make_shared<test>(2);
cout << "p1的count = " << p1.use_count() << endl;
cout << "p2的count = " << p2.use_count() << endl;
p1.reset(new test(3)); //*1
cout << "重置后p1的count = " << p1.use_count() << endl;
shared_ptr<test> p3 = p1;
cout << "p3的count = " << p1.use_count() << endl;
p1.reset();
cout << "置空后p1的count = " << p1.use_count() << endl;
p2.reset();
cout << "置空后p2的count = " << p2.use_count() << endl;
cout << "此时p3的count = " << p3.use_count() << endl;
}
结果如下:
构造test对象 1
构造test对象 2
p1的count = 1
p2的count = 1
构造test对象 3
析构test对象 1
重置后p1的count = 1
p3的count = 2
置空后p1的count = 0
析构test对象 2
置空后p2的count = 0
此时p3的count = 1
析构test对象 3
p1.reset(new test(3));,可以看到该行代码做了两件事:构造对象 3,并析构对象 1。p1 现在不再指向 test1 了,count 减少后,发现 test1 的引用计数变为 0 了,所以析构掉它。此时 p1 指向 test3。p1.reset();和p2.reset();,可以理解为把这个指针指向 nullptr 了,它们原本指向的 test3 和 test2 因为 count 都没了,也随之被释放。一切智能指针调用没有参数的 reset() 后,它们都不再连接对象了,因此“它们的”引用计数全是0。- 注意,reset() 只和智能指针关联的对象有关,这个智能指针现在什么都不指了,但是自身还存在,还可以接着指别的。
- 最后一行 test3 的析构,是由于函数结束,变量生命周期结束,由系统释放。每个函数与生俱来带有一个堆,函数结束,堆被释放,堆中数据清空。
【例 2】
//有一个自定义类型 Zoo,里面有一个int a
auto sp1 = make_shared<string>(new Zoo);
auto sp2(sp1); //此时二者的count都是2
sp1.reset();
//sp1->a = 10;
sp2.reset();
- sp1.reset() 后:sp1 的 count 变成0,sp2 的 count 变成1。很好理解,sp1 断开了与 Zoo 的连接,Zoo 只有 sp2 了,因此 sp2 的计数为1。sp1 调用 reset(),连接到 nullptr ,引用计数变为 0。
- sp2.reset() 后:sp1 和 sp2 的 count 全部变成 0。并且 Zoo 被释放。
- 在 sp1.reset() 之后通过 sp1 访问地址里面的值,这是未定义的行为,不同编译器处理结果不同,反正都不是好结果。
1.4 析构函数
引用计数为 0 的时候自动释放内存,这件事是由析构函数去做的。一个 shared_ptr 的 ptr 从 Foo 上指开时,ref 还并未解绑。首先将控制块中的引用计数减 1,之后判断引用计数是不是 0。
“销毁对象,并释放它占用的内存”是所有析构函数的功能。
智能指针的析构函数会在某种情况下自动释放指针所指的内存,作为对照,看一下 vector:
int a[3] = {0, 1, 2};
vector<int*> v;
v.push_back(a);
v.push_back(a+1);
v.push_back(a+2);
v.~vector();
这个 vector 析构后,对指针所指向的内存是没有影响的。
因此智能指针析构函数的功能可以描述为:“销毁对象,并释放它占用、及其关联的内存”。但并不是只有最后一个指针销毁自身前才会释放内存,1.3 中的例子说明,只要这个内存上最后一个智能指针离开,他就被释放。这个离开可能是因为那个指针被 reset 了。
时刻牢记,但凡会改变引用计数的操作都有可能导致指向的内存被释放:赋值、拷贝、reset!
1.5 智能指针与普通指针
① 不要用普通指针直接给智能指针赋值,智能指针重载的 operator= 不认识普通指针;
② 不要用同一普通指针初始化多个 shared_ptr 对象;
③ 智能指针缺少 +,-,++,-- 和 [ ] 运算符,只有 *,->,=,<
1.6 owner_before
首先明确,shared_ptr 根据其所指对象的属性可分为两种:
① owner pointer:所有权拥有指针,指向整个自定义数据类型的对象
② stored pointer:指向数据成员
struct A{int a; double b;};
auto p1 = make_shared<A>(); //owner pointer
shared_ptr<int> p2(pA, &pA->a); //stored pointer
有一个 shared_ptr 的规则,如果智能指针是 stored pointer 的,那 get() 会获得这个数据成员所属对象的地址。owner_before 的作用是:判断两个东西的地址,A 地址靠前返回 1,相同或 B 靠前返回 0。
【例 1】
struct A{
int age;
double mark;
};
int main(){
shared_ptr<A> ptr = make_shared<A>();
shared_ptr<int> ptr1(ptr, &ptr->age);
shared_ptr<double> ptr2(ptr, &ptr->mark);
cout << "ptr指向的地址为" << ptr.get() << endl;
cout << "ptr1指向的地址为" << ptr1.get() << endl;
cout << "ptr2指向的地址为" << ptr1.get() << endl;
cout << "ptr1.owner_before(ptr) = " << ptr1.owner_before(ptr) << endl;
cout << "ptr1.owner_before(ptr2) = " << ptr1.owner_before(ptr2) << endl;
cout << "ptr.owner_before(ptr1) = " << ptr.owner_before(ptr1) << endl;
cout << "ptr.owner_before(ptr2) = " << ptr.owner_before(ptr2) << endl;
}
输出结果:
ptr指向的地址为0xb02440
ptr1指向的地址为0xb02440
ptr2指向的地址为0xb02440
ptr1.owner_before(ptr) = 0
ptr1.owner_before(ptr2) = 0
ptr.owner_before(ptr1) = 0
ptr.owner_before(ptr2) = 0
- 尽管 ptr1 和 ptr2 的地址应该是不同的,但是这里依然输出相同的地址,就是 ptr 的地址。
- 只要指向的对象相同,owner-based 就返回 0,但绝非只要返回 0 就说明指向相同对象,当前仅当双向 owner-based 都返回 0,才说明指向对象相同。
【例 2】
struct A{ int a; };
struct B{ int b; };
struct C : public A, public B{};
int main()
{
shared_ptr<A> pA = make_shared<A>();
shared_ptr<B> pB = make_shared<B>();
shared_ptr<C> pC = make_shared<C>();
cout << "pA指向的地址为" << pA.get() << endl;
cout << "pB指向的地址为" << pB.get() << endl;
cout << "pC指向的地址为" << pC.get() << endl;
cout << "ptrA.owner_before(ptrB) = " << pA.owner_before(pB) << endl;
cout << "ptrB.owner_before(ptrA) = " << pB.owner_before(pA) << endl;
cout << "ptrA.owner_before(ptrC) = " << pA.owner_before(pC) << endl;
cout << "ptrC.owner_before(ptrA) = " << pC.owner_before(pA) << endl;
cout << "ptrB.owner_before(ptrC) = " << pB.owner_before(pC) << endl;
cout << "ptrC.owner_before(ptrB) = " << pC.owner_before(pB) << endl;
}
输出结果:
pA指向的地址为0xe02440
pB指向的地址为0xe02460
pC指向的地址为0xe025c0
ptrA.owner_before(ptrB) = 1
ptrB.owner_before(ptrA) = 0
ptrA.owner_before(ptrC) = 1
ptrC.owner_before(ptrA) = 0
ptrB.owner_before(ptrC) = 1
ptrC.owner_before(ptrB) = 0
- A 和 B 相比:A、B 根本不是一个东西,A 的地址在前,因此 A owner B 是 1, B owner A 是 0;
- 有的说法认为这个东西与继承有关,其实这和继不继承没关系,当这两个对象所指的根本就不是一个东西的时候,那 owner_before 的结果只和这两个对象本身的地址有关。由于使用了 make_shared,因此它们尽管存在继承关系,地址上却没有重合,全是 owner pointer。那么 owner_before 就是正常比地址。
【例 3】
class A { int a; };
class B { double b; };
class C: public A, public B {};
int main(){
std::shared_ptr<C> pc(new C);
std::shared_ptr<A> pa(pc);
std::shared_ptr<B> pb(pc);
cout << pa.get() << ' '<< pb.get() << ' '<< pc.get() << endl;
printf("%d %d\n", pc < pb, pb < pc); // 0 0
printf("%d %d\n", pc.owner_before(pb), pb.owner_before(pc)); // 0 0
//printf("%d %d\n", pa < pb, pb < pa); Error!
std::shared_ptr<void> p0(pc), p1(pb);
printf("%p %p\n", p0.get(), p1.get());
printf("%d %d\n", p0 < p1, p1 < p0); // 1 0
printf("%d %d\n", p0.owner_before(p1), p1.owner_before(p0)); // 0 0
}
输出结果:
0xb52430 0xb52438 0xb52430
0 0
0 0
0000000000b52430 0000000000b52438
1 0
0 0
- 看地址,pa 和 pc 指向同一个地方,pb 照它们多了 8 字节,正好是一个 int 的长度。说明在这个 C 类型的内存上,pa 依旧指向 C 里属于 A 的部分,而 pb 依旧指向 C 里属于 B 的部分。即 pc 是 owner pointer,pa、pb 是 stored pointer;
- 请注意本例和例 2 的区别,例 2 使用 make_shared 去生成对象,所以例 2 的所有指针都是 owner pointer;
- 尽管如此,pc 和 pb 依旧指向的是一个东西,因此双向的 owner_before 都是 0;
- 智能指针重载的 operator<(operator= 是一样的道理) ,会先判断运算符两侧的智能指针是否是同一类型、或能否进行类型转换,通过 common_type 类型转换后,对二者分别 get(),调用 less 比较 get() 的大小;
- pa 与 pb 调用 operator< 报错,因为二者间无法类型转换;
- 那么,p0 和 p1 间的比较就很好理解了,而 pb 和 pc ,明明具有不同的 get(),调用 operator< 却双向为 0,说明在类型转换的时候发生了一些事情。
【例 4】
class A { int a; };
class B { double b; };
class C: public A, public B {};
int main(){
std::shared_ptr<C> pc(new C);
std::shared_ptr<B> pb(pc);
std::shared_ptr<B> pc_ = static_pointer_cast<B>(pc);
cout << pb.get() << ' '<< pc.get() << ' '<< pc_.get() << endl;
}
输出结果:
0x1d2438 0x1d2430 0x1d2438
- 派生类 is-a 基类,即 class C is-a class B,故使用 static_pointer_cast 对 pc 强转;
- pc 强转为 shared_ptr 类型的 pc_后,其地址发生了改变,pc_ 和 pb get() 的结果是一样的,因此 operator< 双向为 0。智能指针的强转会改变其 get()。
我们使用 owner_before,本质上就是判断两个智能指针的 “所指” 是否 “属于” 同一个对象。这个问题的深层含义是:一个智能指针有可能指向了另一个智能指针中的某一部分,但又要保证这两个智能指针销毁时,只对那个被指的对象完整地析构一次,而不是两个指针分别析构一次,比如就是给出的基类指针指向派生类对象的情况。
最后,所谓 “继承体系内指针的比较” ,这个问题其实在上面已经描述得很详尽,总结如下:
- 当两个指针的静态类型相同时,比较运算符比较的是他们所保存的地址的值;
- 当两个指针的静态类型以及所指对象的类型都属于同一个继承层次结构中,并且其中一个指针类型是所指对象的静态类型的时候,指针的比较,实际上比较的是两个指针是否指向同一个对象【3.6】
- 当两个指针的静态类型以及所指对象类型都属于同一个继承层次结构,但是它们的的静态类型都不是所指对象的类型时,编译错误【3.5】
其实上述规则都是废话,总结就是:指针/智能指针的比较运算符,需要两边的对象类型相同或可以类型转换。
最后的最后:boost 中 owner_before 跟 operator< 等价,跟 std::shared_ptr 不一样。
1.7 注意事项
① 存放于容器中的shared_ptr
正常情况下,如果 shared_ptr 无用了,那它自身以及它指向的内存会自动释放。然而,如果容器的class T是一个shared_ptr,那么一旦后面的程序不再需要某个元素时,需要用 erase 主动删除。否则由于引用计数一直存在,这个智能指针类型的元素将直至容器被析构的时候才会被销毁。
② shared_ptr作为unordered容器的key导致hash退化为链表
在一些老版本的编译环境中,如果把 boost::shared_ptr 放到 unordered_set 中,或者用于 unordered_map 的 key,hash table 可能会退化为链表(这是一个bug)。Boost 1.46.0 之前,unordered_set 虽然可以编译通过,但是其 hash_value 是 shared_ptr 隐式转换为 bool 的结果。也就是说,如果不自定义hash函数,那么 unordered_set/map 会退化为链表。
③ 避免用一个裸指针初始化多个shared_ptr
int* p = new int;
shared_ptr<int> p1(p);
shared_ptr<int> p2(p); //此时 p1 和 p2 的 count 都是 1,而非 2
//shared_ptr p2(p1.get()); //使用 get 方法和上面是一样的
//shared_ptr p3(new int);
//p3.reset(p); //reset 也不行
如果两个 shared_ptr 由同一根裸指针初始化,那么它们不知道自己在和其它的shared_ptr共享内存。这个时候无论是 p2 还是 p1 调用 reset(),都会使另一个变为悬空指针。
本质是 p1 和 p2 各自创建了一个独立的控制块,因此 p 这块内存实际上是有两块控制块的,所以就出错了。
④ 删除器
和其它大多数标准库模板类一样,shared_ptr 也有两个隐藏的参数:删除器和分配器。
// with deleter
template <class U, class D> shared_ptr (U* p, D del);
template <class D> shared_ptr (nullptr_t p, D del);
// with allocator
template <class U, class D, class Alloc> shared_ptr (U* p, D del, Alloc alloc);
template <class D, class Alloc> shared_ptr (nullptr_t p, D del, Alloc alloc);
//functor
//使用标准库中自带的 default_delete
shared_ptr<int> p(new int[10], std::default_delete<int[]>());
//自定义删除器
void deleteInt(int*p) { delete []p; } //functor
shared_ptr<int> p(new int[10], deleteInt);
//lambda
shared_ptr<int> p (new int, [](int* p){delete p;}, allocator<int>());
- 如果不显式传递删除器,其默认值就是
default_delete,这个也是定义在里的,专门用于智能指针的删除 - 如果处理数组,则必须显式传递删除器 delete[],当然,动态数组不好用,不如直接用vector
- 可以使用 lambda 表达式传递删除器,也可以使用仿函数
e.g. 显式传递删除器
void myClose(int *fd){
close(*fd);
}
int main()
{
int socketFd = 10;
std::shared_ptr<int> up(&socketFd, myClose); //传递函数指针作为删除器
std::shared_ptr<int> sp1(new int[10],[](int *p){delete[] p;}); //传递delete[]处理数组,用到了lambda表达式
}
⑤ 一个指向nullptr的智能指针,无论被拷贝多少次,count都是0
很好理解,一个 nullptr 连控制块都没有,不过多少个人指向它,计数都是 0。
⑥ 如果使用get()返回的指针,记住当最后一个对应的智能指针销毁后,这个get到的指针就无效了
(二) 数据结构
该部分转载自 陈硕的blog:为什么多线程读写 shared_ptr 要加锁?,有改动
2.1 基本数据结构
shared_ptr 是引用计数型智能指针,几乎所有的实现都采用在堆上放个计数值的办法(除此之外理论上还有用循环链表的办法,不过没有实例)。具体来说,shared_ptr 包含两个指针,一个是指向 Foo 的指针 ptr,另一个是指向控制块 ref_count 指针(其类型不一定是原始指针,有可能是 class 类型,但不影响这里的讨论),指向堆上的 ref_count 对象。ref_count 对象有多个成员,其中 deleter 和 allocator 是可选的。
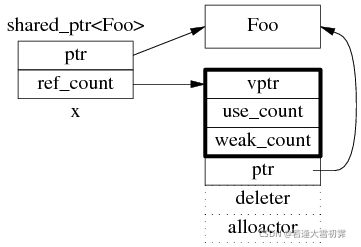
(1)为什么 ref_count 中也有指向 Foo 的指针?
shared_ptr 在构造 sp 的时候捕获了 Foo 的析构行为。实际上 shared_ptr.ptr 和 ref_count.ptr 可以是不同的类型(只要它们之间存在隐式转换),这是 shared_ptr 的一大功能。分三点来说:
- 无需虚析构:假设 Bar 是 Foo 的基类,但是 Bar 和 Foo 都没有虚析构。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的类型是 Foo*
shared_ptr<Bar> sp2 = sp1; // 可以赋值,自动向上转型(up-cast),Foo 的 count 变为 2
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,因为其 ref_count 记住了 Foo 的实际类型。其实这个例子和上文 case 2 是一样的,sp1.reset(); 调用前,二者的 count 都是2;调用后,sp1 的 count 变为 0,而 sp2 的是 1。
shared_ptr可以指向并安全地管理(析构或防止析构)任何对象:muduo::net::Channel class的 tie() 函数就使用了这一特性,防止对象过早析构。
shared_ptr<Foo> sp1(new Foo); // ref_count.ptr 的类型是 Foo*
shared_ptr<void> sp2 = sp1; // 可以赋值,Foo* 向 void* 自动转型
sp1.reset(); // 这时 Foo 对象的引用计数降为 1
此后 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo,不会出现 delete void* 的情况,因为 delete 的是 ref_count.ptr,不是 sp2.ptr。
- 多继承:假设 Bar 是 Foo 的多个基类之一。
shared_ptr<Foo> sp1(new Foo);
shared_ptr<Bar> sp2 = sp1; // 这时 sp1.ptr 和 sp2.ptr 可能指向不同的地址
// 因为 Bar subobject 在 Foo object 中的 offset 可能不为0
sp1.reset(); // 此时 Foo 对象的引用计数降为 1
但是 sp2 仍然能安全地管理 Foo 对象的生命期,并安全完整地释放 Foo。因为 delete 的不是 Bar*,而是原来的 Foo*。换句话说,sp2.ptr 和 ref_count.ptr 可能具有不同的值(当然它们的类型也不同)。
(2)为什么使用make_shared?
最直观的一个理由:shared_ptr 里面有两根指针,如果采用shared_ptr 赋值,就是上面的那张图,需要分配两次内存,一块由 ptr 指向,另一块由 ref 指向。而 make_shared 可以节省一次内存分配,即一次性分配一块足够大的内存同时容纳两块地址。并且数据结构就变成了这样:
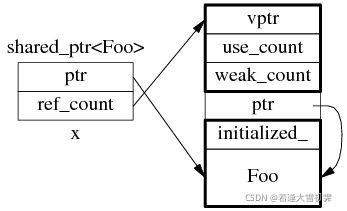
不过 Foo 的构造函数参数要传给 make_shared(),后者再传给 Foo::Foo(),其中需要 perfect forwarding。
2.2 shared_ptr对象赋值过程中的race condition
shared_ptr x(new Foo); 对应的内存数据结构如下(后文只画出 use_count 的值):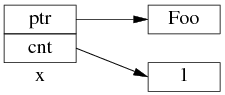
再执行 shared_ptr y = x; 那么对应的数据结构如下:
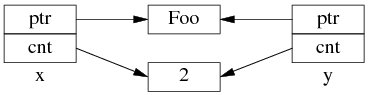
但是 y=x 涉及两个成员的复制,这两步拷贝不会同时(原子)发生,需要两个中间步骤——复制 ptr 指针和复制 ref_count 指针,实现顺序不一定,通常先 ptr 后 ref,复制ref后,use_count增加1:


既然 y=x 有两个步骤,如果没有 mutex 保护,那么在多线程里就有 race condition(竞争):
考虑一种最简单的场景(有更复杂的),三个shared_ptr 对象 x、g、n:
shared_ptr<Foo> g(new Foo); // 线程 A、B 共享的 shared_ptr
shared_ptr<Foo> x; // 线程 A 的局部变量(未被赋值)
shared_ptr<Foo> n(new Foo); // 线程 B 的局部变量(已被赋值)
(1)一开始,各安其事

(2)线程 A 执行 x = g; (即 read g),但完成了 ptr 的拷贝,还没来得及拷贝 ref,就切换到了 B 线程

(3)同时让 B 执行 g = n; (即 write g),ptr 和 ref 的拷贝一起完成了,此时 Foo1 对象已经销毁,x.ptr 成了悬空指针


(4)最后回到线程 A,完成 ref 的拷贝,线程 A 结束,程序出错

多线程无保护地读写 g(A 没读完,B 就写),造成了 x 是悬空指针的后果。因此多线程读写同一个 shared_ptr 必须加锁!
最后,不单是赋值操作,shared_ptr 的拷贝构造函数也是非原子化的。为了避免引用计数引起的 race condition,因此在多线程环境中使用共享指针的代价非常大。
2.3 引用计数的线程安全
多线程环境下,shared_ptr 对引用计数的增减操作是原子化 / 线程安全的吗?——分情况讨论。这里更关注引用计数减少的情况,因为引用计数减少时可能会产生副作用——释放内存,
【case 1】当多线程操作同一个 shared_ptr 对象
多线程操作非原子对象,那一定不是原子操作,肯定会出现问题。考虑一种情况:
线程 A、B 同时接收了一个 shared_ptr 对象的【引用】,即多线程同时操作一个对象。假如这个智能指针指向的内存目前只有它一个人在访问,即计数为 1。现在 A 要读数据,B 要释放内存,如果 A 的指令先于 B 到达,好,无事发生。如果 B 的指令先于 A 到达,即这个引用计数变 0,内存提前释放,坏了。
也就是说这种情况下是非原子化的。标准里规定 shared_ptr 可以线程不安全,use_count 增加时允许引入竞争条件。或者说,多个线程读写同一个非原子变量本来就不是线程安全的。
C++ 的原则是不为未使用的功能付出代价。若多线程操作同一个shared_ptr,要么加锁,要么使用 atomic 版本的 load 和 store ( atomic_load, atomic_store )。即,调用对应的原子化成员函数可以实现引用计数增减的原子化,默认情况下,那就不是原子化的。
【case 2】当多线程操作不同的 shared_ptr 对象
线程 A、B 通过值传递同时接收了一个 shared_ptr 对象,那算上原来那个,这块地址的引用计数就变成 3 了,这时候就很安全了。很多人说的所谓计数引用是原子化的,大概都指的是这一种情况,毕竟很少有接口把形参写成引用的形式,但实际上是需要分成两种情况讨论的。
但是注意,这里所说的线程安全指的是什么?指的是:不同线程按值捕获的 shared_ptr 对象是线程安全的。上面讨论的内容都是“shared_ptr 对象的线程安全”,那么这个对象指向的内存是不是线程安全的呢?
2.4 读写操作的线程安全
多线程同时管理一块内存,在没有什么额外设计的情况下肯定不安全(非原子),case 1 本质就是这个事,智能指针的析构也涉及到读写。其实这已经不属于 shaerd_ptr 讨论的范畴了。只需要注意一点:C++ 效率至上,锁并不是好东西。
(三) make_shared
3.1 为什么使用make_shared?
- make_shared 会根据参数的类型为其在堆中 new 一个相应的对象(如果构造函数是 pravite 就坏了);
- 一次性分配一整块内存,可以减少碎片化内存, 减少使用临时变量, 也减少了和内核的交流;
- 异常安全。
3.2 异常安全——Effictive C++ : 17th
假如现在有这两个函数:
void subFunc();
void mainFunc(shared_ptr<type> x, void func);
main 函数的第一个参数是一个智能指针,第二个参数是一个返回值为 void 类型的函数指针。现在把 sub 函数作为参数传给 main 函数,调用 main。
mainFunc(shared_ptr<type>(new type), subFunc){ /.../ };
编译器产出一个函数的调用码之前,需要对其实参进行核算,mainFunc 的核算需要经历三个步骤:① new 一个 type 类型的对象;② 把这个对象放进智能指针里;③ 调用一次 subFunc。JAVA 和 C# 会采用特定的顺序完成实参校验,而 C++ 没有顺序,那就出现问题了:
如果校验顺序为 ① ③ ②,一旦调用 subFunc 的过程中出现异常,那 ① new 出来的指针就遗失了,没办法放进智能指针了,换句话说,本来智能指针是用来避免内存泄漏的,但是在初始化智能指针的过程中,内存泄漏了。
书中给出的解决办法是:以独立语句将 newed 对象置入智能指针。理由是:编译器对于跨越语句的各项操作没有重新排序的自由。
shared_ptr<type> p(new type)
mainFunc(p, subFunc){ /.../ };
当然,更推荐的是使用 make_shared,一用解千愁。
mainFunc(make_shared<type>(), subFunc){ /.../ };
3.3 源码速览
//make_shared
template<typename T, typename... Args>
inline shared_ptr<T>
make_shared(Args&&... args)
{
typedef typename std::remove_cv<T>::type Tp;
return std::allocate_shared<T>(std::allocator<Tp>(),std::forward<Args>(args)...);
}
//allocate_shared
template<typename T, typename Alloc, typename... Args>
inline shared_ptr<T>
allocate_shared(const Alloc& a, Args&&... args)
{
return shared_ptr<T>(_Sp_alloc_shared_tag<Alloc>{a},std::forward<Args>(args)...);
}
分析:
- make_shared 使用了可变长度模板参数,这样调用 make_shared 的时候,实参可以是任意长度、任意类型。这么做的原因是,T 类型可能有好多种构造函数,每种构造函数都不相同,而 make_shared 的实参就可以是 T 类型这很多种构造函数的实参,它接收实参,调用 T 类型相应的构造函数动态分配一个对象。
- 函数实参是右值,因为需要隐式调用 T 类型相应的(移动)构造函数,包括调用 allocate_shared,需要完美转发。
- std::forward 实参中的 “…”,是C++11 中引入的包扩展。args 就是一个参数包,编译器会根据 std::forward 这个函数的需要,自动扩展参数包里参数的数量。