【ChatGPT】大模型协作系统 HuggingGPT 深度解析
欢迎关注【youcans的AGI学习笔记】原创作品
【ChatGPT】大模型协作系统 HuggingGPT 深度解析
-
- 1. 摘要
- 2. 前言
- 3. HugginGPT 大模型协作系统
-
- 3.1 任务规划
- 3.2 模型选择
- 3.3 任务执行
- 3.4 响应生成
- 4. HugginGPT 测试案例
-
- 4.1 实验条件的设置
- 4.2 定性的实验结果
-
- 4.2.1 任务之间存在资源依赖关系的情况
- 4.2.2 在音频和视频模式上的对话能力
- 4.2.3 集成多个用户输入资源
- 4.3 简单任务案例研究
-
- 4.3.1 文生图
- 4.3.2 图生文
- 4.3.3 视觉问答
- 4.3.4 文生视频
- 4.4 复杂任务案例研究
-
- 4.4.1 多轮对话场景复杂任务
- 4.4.2 多任务扩展
- 4.4.3 多个专家模型并行协作
- 5. 问题与总结
-
- 5.1 存在的问题
- 5.2 结论
- 6. 【HuggingGPT】使用指南
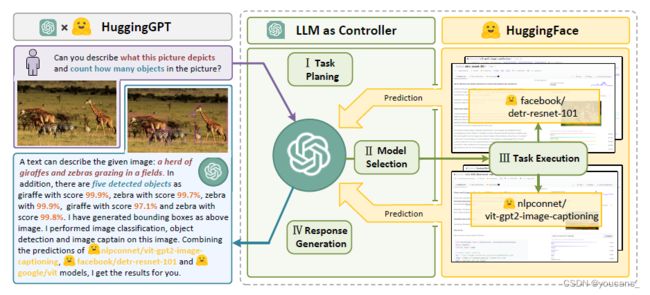
3 月 30日,浙江大学、微软亚洲研究院合作发布了基于 ChatGPT的大模型协作系统HuggingGPT,并在 Github 开源了基础代码。
- HuggingGPT 将语言作为通用接口、将 LLM 作为控制器,管理现有的人工智能模型。
- HuggingGPT 通过 ChatGPT 管理 HuggingFace 上集成的数百个模型,覆盖文本分类、目标检测、语义分割、图像生成、问答、文本到语音、文本到视频等不同模态和领域的任务。
- HuggingGPT 的工作流程:
- 在收到用户请求时使用 ChatGPT 进行任务规划。
- 根据 HuggingFace 中可用的功能描述选择模型。
- 使用所选的 AI 模型执行每个子任务。
- 根据 AI 模型执行结果进行总结和输出。
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HugingFace
下载地址:【Arxiv:https://arxiv.org/pdf/2303.17580.pdf】
本文介绍该论文的主要内容。
1. 摘要
解决不同领域和多模态的复杂人工智能任务是迈向人工通用智能(AGI)的关键步骤。
现有的人工智能模型可以用于不同的领域和模态,但还无法处理复杂的人工智能任务。鉴于大型语言模型(LLM)在语言理解、生成、交互和推理方面已经表现了强大的能力,我们认为可以将语言作为通用接口、将 LLM 作为控制器,来管理现有的人工智能模型,以解决复杂的人工智能任务。
基于这一理念,我们提出了HuggingGPT,这是一个利用 LLM(例如 ChatGPT)连接机器学习社区中的各种人工智能模型(例如 HuggingFace)来解决人工智能任务的系统。具体步骤如下:
- 在收到用户请求时使用 ChatGPT 进行任务规划。
- 根据 HuggingFace 中可用的功能描述选择模型。
- 使用所选的 AI 模型执行每个子任务。
- 根据执行结果总结响应。
通过利用 ChatGPT 强大的语言能力和 HuggingFace 丰富的人工智能模型,HuggingGPT 能够覆盖不同模态和领域的众多复杂人工智能任务,在语言、视觉、语音和其他具有挑战性的任务方面取得令人印象深刻的成果,这为 AGI 铺平了新的道路。
2. 前言
大型语言模型(如ChatGPT)在各种自然语言处理(NLP)任务中的出色表现,吸引了学术界和工业界的极大关注。基于对大量文本语料库的大规模预训练和来自人类反馈的强化学习(RLHF),LLM可以在语言理解、生成、交互和推理方面产生卓越的能力。LLM强大的能力也推动了许多新兴的研究课题(如上下文学习、指令学习和思维链提示)进一步研究 LLM 的巨大潜力,并为我们构建人工通用智能(AGI)系统带来了无限的可能性。
目前的LLM技术仍然不完善,在构建 AGI 系统的过程中面临着一些紧迫的挑战:
-
受限于文本生成的输入和输出形式,当前的 LLM 缺乏处理视觉和语音等复杂信息的能力。
-
在现实世界的场景中,一些复杂的任务通常由多个子任务组成,因此需要多个模型的调度和协作。
-
对于一些具有挑战性的任务,LLM 仍然比一些专家(例如,微调模型)弱。
如何解决这些问题,可能是 LLM 迈向 AGI 系统的第一步,也是关键一步。
我们指出:**为了处理复杂的人工智能任务,LLM 应该能够与外部模型协调,以利用它们的能力。**因此,关键是如何选择合适的中间件来建立 LLM 和 AI 模型之间的连接。
我们注意到,每个人工智能模型都可以通过总结其模型功能来表示为一种语言形式。因此,我们引入了一个概念:**“语言是 LLM 连接人工智能模型的通用接口”。**换句话说,通过将这些模型描述结合到提示中,LLM 可以被认为是管理人工智能模型(如计划、调度和合作)的大脑。
因此,这种策略使 LLM 能够调用外部模型来解决人工智能任务。但如果我们想将多个人工智能模型集成到 LLM 中,另一个挑战将出现:解决大量人工智能任务需要收集大量高质量的模型描述,这需要大量的即时工程。不过,一些 ML 社区通常提供各种各样的适用模型,这些模型具有定义明确的模型描述,用于解决特定的人工智能任务,如语言、视觉和语音。这些观察结果给我们带来了一些启发:
我们能否将 LLM(如 ChatGPT)与机器学习社区(如 GitHub、HuggingFace3、Azure)联系起来,通过基于语言的界面解决复杂的人工智能任务?
因此,我们提出 HuggingGPT 的系统来连接LLM(ChatGPT)和ML社区(HuggingFace),它可以处理来自不同模式的输入并解决许多复杂的人工智能任务。更具体地说,对于 HuggingFace中 的每个 AI 模型,我们使用库中对应的模型描述,并将其融合到提示中,以建立与 ChatGPT 的连接。之后,在我们的系统中,LLM(即ChatGPT)将充当大脑来确定用户问题的答案。
如图 1 所示,HuggingGPT 的工作可以分为四个阶段:
-
任务规划:使用 ChatGPT 分析用户请求,将其分解为多个子任务,规划任务顺序和依赖关系。
-
模型选择:对于子任务,ChatGPT 将根据模型描述来调用 HuggingFace 上的专家模型。
-
任务执行:每个专家模型执行所分配的子任务,返回执行结果。
-
响应生成:最后由 ChatGPT 集成所有专家模型的结果,并为用户生成答案。
这种设计使 HuggingGPT 能够使用外部模型,从而可以集成多模态感知能力并处理多个复杂的人工智能任务。此外,这种架构还使 HuggingGPT 能够不断加入特定任务专家的力量,实现可增长和可扩展的人工智能能力。
截至目前,HuggingGPT 已经基于 ChatGPT 在 HuggingFace 上集成了数百个模型,涵盖了文本分类、对象检测、语义分割、图像生成、问答、文本到语音、文本到视频等 24 项任务。并通过实验证明了 HuggingGPT 在处理多模态信息和复杂人工智能任务方面的能力。
我们的贡献如下:
-
为了补充大型语言模型和专家模型的优势,我们提出了模型之间交互的协议。大型语言模型(LLM)充当规划和决策的大脑,专家模型充当每个特定任务的执行者,这为设计通用人工智能模型提供了新的方法。
-
我们构建了 HuggingGPT,基于 ChatGPT 集成了 HuggingFace 上的 400 多个特定任务模型,来解决通用人工智能任务。通过模型的开放协作,HuggingGPT 为用户提供多模式、可靠的对话服务。
-
在语言、视觉、语音和跨模态的多个具有挑战性的人工智能任务上进行的大量实验,证明 HuggingGPT 在理解和解决多个模态和领域的复杂任务方面的能力。
3. HugginGPT 大模型协作系统
HuggingGPT 是一个协作系统,由作为控制器的大型语言模型(LLM)和作为协作执行器的众多专家模型组成。
HuggingGPT 的工作流程由四个阶段组成:任务规划、模型选择、任务执行和响应生成,如图2所示。
- LLM(如ChatGPT)首先解析用户请求,将其分解为多个任务,并根据其知识规划任务顺序和依赖关系。
- LLM 根据 HuggingFace 中的模型描述,将解析后的任务分配给专家模型。
- 专家模型在推理端点上执行分配的任务,并将执行信息和推理结果记录到 LLM。
- 最后,LLM 总结执行过程日志和推理结果,并将摘要返回给用户。

3.1 任务规划
HuggingGPT 的第一阶段,大型语言模型接受用户的请求,将其分解为一系列结构化任务。
复杂的请求通常涉及多个任务,并且大型语言模型需要确定这些任务的依赖关系和执行顺序。为了提示大型语言模型进行有效的任务规划,HuggingGPT 在其提示设计中采用了基于规范的指令和基于演示的解析。
基于规范的指令任务规范为任务提供了统一的模板,并允许大型语言模型通过槽位归档进行任务解析。HuggingGPT 为任务解析设计了四个接口,分别是任务类型、任务ID、任务依赖项和任务参数:
- 任务 ID 为任务规划提供了一个唯一的标识符,用于引用相关任务及其生成的资源。
- 任务类型涵盖语言、视觉、视频、音频等不同任务。HuggingGPT当前支持的任务列表如下表所示。
- 任务相关性定义了执行所需的先决条件任务。只有在完成所有先决条件相关任务后,才会启动该任务。
- 任务参数包含执行任务所需的参数列表。它包含三个子字段,根据任务类型填充文本、图像和音频资源。它们是从用户的请求或相关任务的生成资源中解析的。不同任务类型的相应参数类型如下表所示。

得益于指令调整和来自人类反馈的强化学习,大型语言模型具有遵循指令的能力。HuggingGPT 将这些任务规范作为高级指令提供给大型语言模型,用于分析用户的请求并相应地解析任务。
HuggingGPT 引入了上下文学习,以实现更有效的任务解析和规划。通过在提示中注入几个 Demo,HuggingGPT 允许大型语言模型更好地理解任务规划的意图和标准。
每个Demo 都是一组关于任务规划的输入和输出——用户的请求和要解析的预期任务序列。此外,这些 Demo 由从用户请求解析的任务之间的依赖关系组成,有效地帮助 HuggingGPT 理解任务之间的逻辑关系,并确定执行顺序和资源依赖关系。
3.2 模型选择
解析任务列表后,HuggingGPT 接下来需要匹配任务和模型,即为任务列表中的每个任务选择合适的模型。
为此,我们首先从 HuggingFace Hub 获得专家模型的描述,然后通过上下文中的任务模型分配机制为任务动态选择模型。这种做法允许增量模型访问(简单地提供专家模型的描述),并且更加开放和灵活。
HuggingFace Hub 上托管的专家模型附有全面的模型描述,这些描述通常由开发人员提供。这些描述包含有关模型的功能、体系结构、支持的语言和域、许可等方面的信息。这些信息有效地支持 HuggingGPT 根据用户请求和模型描述的相关性为任务选择正确模型的决定。
在上下文任务模型分配中,我们将任务和模型的分配视为单选问题,其中潜在模型作为给定上下文中的选项呈现。通过在提示中包括用户查询和解析的任务,HuggingGPT 可以为手头的任务选择最合适的模型。然而,由于最大上下文长度的限制,不可能总是在提示中包含所有相关的模型信息。为了解决这个问题,我们根据模型的任务类型筛选模型,只保留与当前任务类型匹配的模型。
3.3 任务执行
任务被分配给特定的模型后,接下来就是执行任务,即执行模型推理。
为了加速和计算稳定性,HuggingGPT 在混合推理端点上运行这些模型。通过将任务参数作为输入,模型计算推理结果,然后将其发送回大型语言模型。为了进一步提高推理效率,可以对不具有资源依赖性的模型进行并行化。这意味着可以同时启动满足先决条件依赖关系的多个任务。
混合端点:
理想的场景是我们只在 HuggingFace 上使用推理端点。为了保持系统的稳定和高效,HuggingGPT 在本地提取并运行一些常见或耗时的模型。局部推理端点很快,但覆盖的模型较少,而HuggingFace 的推理端点则相反。因此,本地端点比 HuggingFace 的推理端点具有更高的优先级。只有在匹配的模型未在本地部署的情况下,HuggingGPT 才会在 HuggingFace 端点上运行该模型。
资源依赖性:
尽管HuggingGPT能够通过任务规划来开发任务顺序,但在任务执行阶段有效管理任务之间的资源依赖性仍然具有挑战性。原因是HuggingGPT无法在任务规划阶段为任务指定未来生成的资源。
为了解决这个问题,我们使用一个唯一的符号“<resource>”来管理资源依赖关系。具体来说,HuggingGPT将先决任务生成的资源标识为
在任务规划阶段,如果存在依赖于task_id任务生成的资源的任务,则HuggingGPT将此符号设置为任务参数中相应的资源子字段。然后在任务执行阶段,HuggingGPT将此符号动态替换为先决任务生成的资源。此策略使HuggingGPT能够在任务执行期间有效地处理资源依赖关系。
3.4 响应生成
在所有任务执行完成后,HuggingGPT 进入响应生成阶段。
在这个阶段,HuggingGPT 将前三个阶段(任务规划、模型选择和任务执行)的所有信息集成到一个简洁的摘要中,包括计划任务的列表、为任务选择的模型以及模型的推理结果。其中最重要的是推理结果,这是 HuggingGPT 做出最终决策的支持。
这些推理结果以结构化格式出现,例如对象检测模型中具有检测概率的边界框、问答模型中的答案分布等。HuggingGPT 允许 LLM 接收这些推理结果作为输入,并将具有置信度的最终响应汇总回用户。
4. HugginGPT 测试案例
4.1 实验条件的设置
我们使用了 GPT 模型的 GPT-3.5-turbo 和 text-davinci-003作为大型语言模型,这些模型可以通过 OpenAI API 公开访问。
为了使 LLM 输出更加稳定,我们将解码温度 temperature设置为 0。此外,为了调节 LLM 输出以符合预期格式,我们将 logit_bias 设置为 0.1。表 5 提供了为任务规划、模型选择和响应生成阶段设计的详细提示。

4.2 定性的实验结果
我们展示了几个对话演示。在每个演示中,用户输入一个可能包含多个任务或多模式资源的请求。然后HuggingGPT依靠LLM来组织多个专家模型的合作,以生成对用户的响应。
为了明确 HuggingGPT 的工作流程,我们提供了任务规划和任务执行阶段的结果。
4.2.1 任务之间存在资源依赖关系的情况
图3 显示了 HuggingGPT 在任务之间存在资源依赖关系的情况下工作的过程。在这种情况下,HuggingGPT 可以根据用户的抽象请求解析出具体任务,包括姿势检测、图像字幕和姿势条件图像生成任务。此外,HuggingGPT 成功地识别了任务3 与任务1 和任务2 之间的依赖关系,并在依赖关系任务完成后将任务1 和任务2 的推断结果注入到任务3 的输入参数中。

4.2.2 在音频和视频模式上的对话能力
图4 展示了 HuggingGPT 在音频和视频模式上的对话能力。
在这两种情况下,HuggingGPT 分别通过专家模型完成用户请求的文本到音频和文本到视频任务。
在顶部的模型中,两个模型并行执行(同时生成音频和视频),在底部的模型中两个模型串行执行(首先从图像生成文本,然后基于文本生成音频)。这进一步验证了 HuggingGPT 可以组织模型之间的合作以及任务之间的资源依赖关系。

4.2.3 集成多个用户输入资源
图5 显示了 HuggingGPT 集成多个用户输入资源以执行简单推理。
即使使用多个资源,HuggingGPT 也可以将主要任务分解为多个基本任务,并最终将多个模型的多次推断结果整合在一起,得到正确的答案。

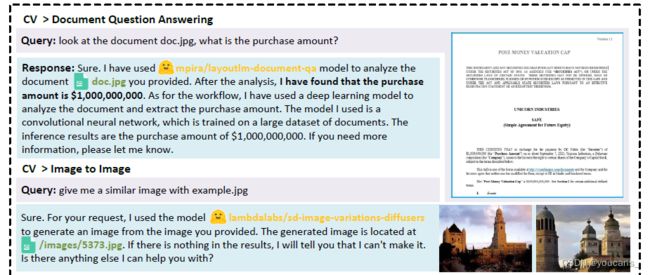
4.3 简单任务案例研究
HuggingGPT是一个多模型协作系统,它依靠任务规划和模型选择为LLM提供了更广泛的功能。我们在各种多模式任务上测试了HuggingGPT,一些选定的案例如图6 和图7 所示。
在大型语言模型和专家模型的合作下,HuggingGPT 可以解决语言、图像、音频和视频等多种模式的任务,包括检测、生成、分类和问答等多种形式的任务。尽管这些任务看起来很简单,但掌握HuggingGPT的基本能力是解决复杂任务的先决条件。
4.3.1 文生图
4.3.2 图生文

4.3.3 视觉问答

4.3.4 文生视频

4.4 复杂任务案例研究
用户请求可能包含多个隐式任务或需要多方面的信息,在这种情况下不能依靠调用单个专家模型来解决它们,HuggingGPT 通过任务规划组织多个模型的协作。
我们测试了 HuggingGPT 在复杂任务情况下的有效性。
4.4.1 多轮对话场景复杂任务
图8 展示了 HuggingGPT 在多轮对话场景中处理复杂任务的能力。
用户将复杂的请求分为多个步骤,并通过多轮请求达到最终目标。HuggingGPT 可以在任务规划阶段通过对话上下文管理来跟踪用户请求的上下文状态,并且可以很好地处理用户提到的资源以及任务规划。

4.4.2 多任务扩展
图9 显示,对于“简单”的“尽可能详细地描述图像”请求,HuggingGPT 将其扩展为五个相关任务,即图像说明、图像分类、对象检测、分割和视觉问答任务。
HuggingGPT 为每个任务分配专家模型,这些模型从LLM的不同方面提供与图像相关的信息。最后,LLM 对这些信息进行了整合,做出了全面而详细的描述。

4.4.3 多个专家模型并行协作
图10 显示了一个用户请求中可能明确包含多个任务。
HuggingGPT 组织多个专家模型并行协作,以满足用户的所有需求,然后让 LLM 聚合模型推理结果以响应用户。

总之,HuggingGPT依赖于LLM与外部专家模型的协作,并在各种形式的复杂任务上表现出了良好的性能。
5. 问题与总结
5.1 存在的问题
HuggingGPT 目前存在一些不足:
-
效率。
效率的瓶颈在于对大型语言模型的推理。对于每一轮用户请求,HuggingGPT 都需要在任务规划、模型选择和响应生成阶段至少与大型语言模型进行一次交互,大大增加了响应延迟,并导致用户体验下降。 -
最大上下文长度的限制。
受 LLM 可以接受的最大令牌数量的限制,HuggingGPT 面临着最大上下文长度的限制。我们使用了会话窗口,在任务规划阶段只跟踪了会话上下文来缓解它。 -
系统稳定性。
一是在大型语言模型的推理过程中发生的“反叛行为”。大型语言模型在推理时偶尔会不符合指令,并且输出格式可能会超出预期,从而导致程序工作流中出现异常。
二是 HuggingFace 的推理端点上托管的专家模型的状态不可控。HuggingFace 上的专家模型可能会受到网络延迟或服务状态的影响,导致任务执行阶段出现错误。
5.2 结论
我们提出了 HuggingGPT 系统来解决人工智能任务,该系统以语言为接口将 LLM 与人工智能模型连接起来。
HuggingGPT 系统的原理是,LLM 可以被视为管理人工智能模型的控制器,并且可以利用HuggingFace 等机器学习社区的模型来解决用户的不同请求。
通过利用 LLM 在理解和推理方面的优势来剖析用户的意图,并将任务分解为多个子任务。然后,基于专家模型描述,HuggingGPT 为每个任务分配最合适的模型,并集成不同模型的结果。通过利用来自机器学习社区的众多人工智能模型的能力,HuggingGPT 在解决具有挑战性的人工智能任务方面展现了巨大的潜力。
LLM 的快速发展给学术界和工业界带来了巨大的影响。我们希望 HuggingGPT 模型的设计能够促进 LLM 的发展,为迈向 AGI 提供新的道路。
6. 【HuggingGPT】使用指南
【HuggingGPT】试用版已经部署到 GitHub,地址如下。有趣的是,项目名称不是 HuggingGPT,而是钢铁侠里的 AI管家贾维斯(JARVIS)。
开源代码:【GitHub:https://github.com/microsoft/JARVIS】

从服务器下载和运行 HuggingGPT 的方法如下:
# setup env
cd server
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch
pip install git+https://github.com/huggingface/diffusers.git
pip install git+https://github.com/huggingface/transformers
pip install -r requirements.txt
# download models
cd models
sh download.sh
# run server
cd ..
python bot_server.py
python model_server.py
从 web 运行 HuggingGPT 的方法如下:
cd web
npm install
npm run dev
参考资料:

Zhejiang University, Microsoft Research Asia
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HugingFace
下载地址:【Arxiv:https://arxiv.org/pdf/2303.17580.pdf】
开源代码:【GitHub:https://github.com/microsoft/JARVIS】
版权声明:
欢迎关注【youcans的AGI学习笔记】,转发请注明原文链接:【ChatGPT】大模型协作系统 HuggingGPT 深度解析
Copyright 2023 youcans, XUPT
Crated:2023-04-03