JMM-有序性
JMM-有序性
文章目录
- JMM-有序性
-
- 1.概念
- 2.指令重排原理
-
- 2.1 关于CPU的几个概念
- 2.2 指令重排优化
- 2.3 支持流水线的处理器
- 2.4指令重排导致的问题
- 3.volatile原理
-
- 3.1如何保证可见性?
- 3.2 如何保证有序性?
- 4.double-checked locking 问题
- 5.double-checked locking 解决方法
1.概念
JVM 会在不影响正确性的前提下,可以调整语句的执行顺序,思考下面一段代码。

可以看到,至于是先执行 i 还是 先执行 j ,对最终的结果不会产生影响。所以,上面代码真正执行时,既可以是
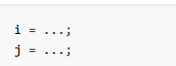
或者
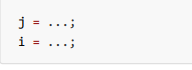
这种特性称之为『指令重排』。
多线程下『指令重排』会影响正确性
2.指令重排原理
2.1 关于CPU的几个概念
-
Clock Cycle Time
主频的概念大家接触的比较多,而 CPU 的 Clock Cycle Time(时钟周期时间),等于主频的倒数,意思是 CPU 能够识别的最小时间单位,比如说 4G 主频的 CPU 的 Clock Cycle Time 就是 0.25 ns,作为对比,我们墙上挂钟的Cycle Time 是 1s。
例如,运行一条加法指令一般需要一个时钟周期时间 -
CPI
有的指令需要更多的时钟周期时间,所以引出了 CPI (Cycles Per Instruction)指令平均时钟周期数 -
IPC
IPC(Instruction Per Clock Cycle) 即 CPI 的倒数,表示每个时钟周期能够运行的指令数 -
CPU 执行时间
程序的 CPU 执行时间,即我们前面提到的 user + system 时间,可以用下面的公式来表示:
程序 CPU 执行时间 = 指令数 * CPI * Clock Cycle Time
2.2 指令重排优化
事实上,现代处理器会设计为一个时钟周期完成一条执行时间最长的 CPU 指令。为什么这么做呢?可以想到指令还可以再划分成一个个更小的阶段,例如,每条指令都可以分为:
【取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回】
这 5 个阶段
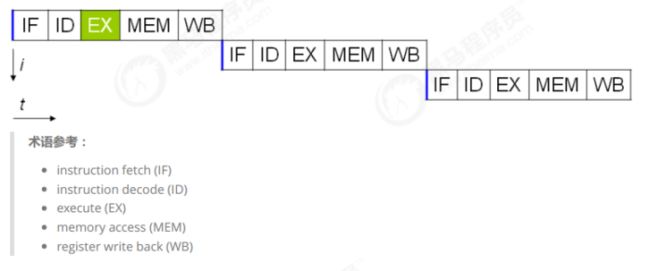
在不改变程序结果的前提下,这些指令的各个阶段可以通过重排序和组合来实现指令级并行。指令重排的前提是,重排指令不能影响结果,例如

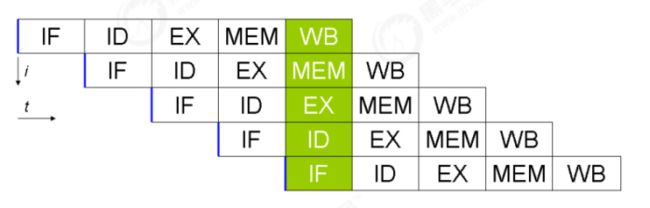
2.3 支持流水线的处理器
现代 CPU 支持多级指令流水线,例如支持同时执行 取指令 - 指令译码 - 执行指令 - 内存访问 - 数据写回 的处理器,就可以称之为五级指令流水线。
这时 CPU 可以在一个时钟周期内,同时运行五条指令的不同阶段(相当于一条执行时间最长的复杂指令),IPC = 1,
本质上,流水线技术并不能缩短单条指令的执行时间,但它变相地提高了指令地吞吐率。
2.4指令重排导致的问题

【情况1】先执行线程1,再执行线程2,r1=1
【情况2】先执行线程2,再执行线程1,r1=4
【情况3】先执行2,但发生指令重排,先执行ready=true,r1=0
情况3可以使用并发压测工具复现:
借助 java 并发压测工具 jcstress
https://wiki.openjdk.java.net/display/CodeTools/jcstress
mvn archetype:generate -DinteractiveMode=false -DarchetypeGroupId=org.openjdk.jcstress -
DarchetypeArtifactId=jcstress-java-test-archetype -DarchetypeVersion=0.5 -DgroupId=cn.itcast -
DartifactId=ordering -Dversion=1.0
3.volatile原理
volatile 的底层实现原理是内存屏障,Memory Barrier(Memory Fence)
- 对 volatile 变量的写指令后会加入写屏障
- 对 volatile 变量的读指令前会加入读屏障
3.1如何保证可见性?
写屏障(sfence)保证在该屏障之前的,对共享变量的改动,都同步到主存当中。

读屏障(lfence)保证在该屏障之后,对共享变量的读取,加载的是主存中最新数据。


3.2 如何保证有序性?
写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后。
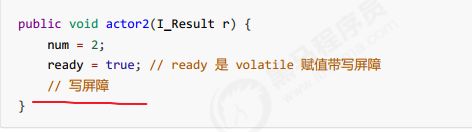
读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前。


还是那句话,volatile不能解决指令交错:
写屏障仅仅是保证之后的读能够读到最新的结果,但不能保证读跑到它前面去
而有序性的保证也只是保证了本线程内相关代码不被重排序。

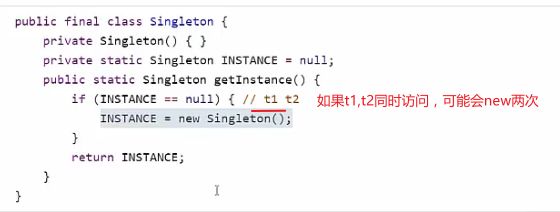
4.double-checked locking 问题
1.不加synchronized(不安全!)
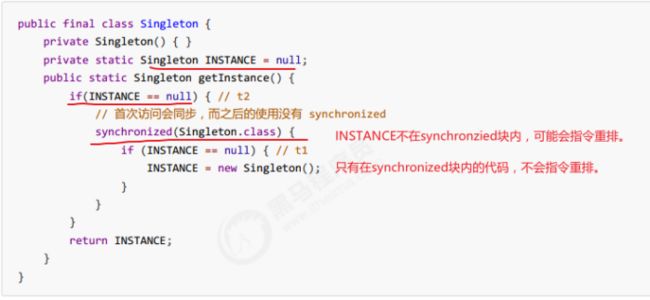
2.单次判断:每调用1次,就进入1次synchronized,效率低!

3.双判断:首次可以创建,进入synchronized块;其他线程在调用的时候,会在第一个判断处结束,不会进入synchronized。

以上的实现特点是:
- 懒惰实例化
- 首次使用 getInstance() 才使用 synchronized 加锁,后续使用时无需加锁
- 有隐含的,但很关键的一点:第一个 if 使用了 INSTANCE 变量,是在同步块之外
double-checked locking 在多线程下存在指令重排的问题!!!
 但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
但在多线程环境下,上面的代码是有问题的,getInstance 方法对应的字节码为:
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 获取静态变量INSTANCE
3: ifnonnull 37 判断静态对象是否为空,如果不为空跳转到37行
6: ldc #3 // class cn/itcast/n5/Singleton 开始加锁,获取类对象
8: dup 复制类对象的引用
9: astore_0 把类对象的指针临时存储一份,将来解锁用
10: monitorenter 创建monitor,加锁
11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 获取静态变量
14: ifnonnull 27 判断不为空
17: new #3 // class cn/itcast/n5/Singleton 创建Singleton实例
20: dup 复制一份实例
21: invokespecial #4 // Method "":()V 调用构造方法
24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 赋值操作,将对象赋值给静态变量
27: aload_0 获取Singleton.class类对象引用
28: monitorexit Monitor解锁
29: goto 37 进到37行
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton; 获取静态变量
40: areturn 返回静态对象
其中
17 表示创建对象,将对象引用入栈 // new Singleton
20 表示复制一份对象引用 // 引用地址
21 表示利用一个对象引用,调用构造方法
24 表示利用一个对象引用,赋值给 static INSTANCE
INSTANCE = new Singleton(); 正常是先调用无参构造再进行赋值;但是这不是一个原子操作,可能会先赋值,再调用无参构造。导致原来的值被new 出来的新对象覆盖。
也许 jvm 会优化为:先执行 24,再执行 21。如果两个线程 t1,t2 按如下时间序列执行:



- 关键在于 0: getstatic 这行代码在 monitor 控制之外,它就像之前举例中不守规则的人,可以越过 monitor 读取INSTANCE 变量的值。
- 这时 t1 还未完全将构造方法执行完毕,如果在构造方法中要执行很多初始化操作,那么 t2 拿到的是将是一个未初始化完毕的单例。
- 对 INSTANCE 使用 volatile 修饰即可,可以禁用指令重排,但要注意在 JDK 5 以上的版本的 volatile 才会真正有效。
synchronized不能阻止重排序,volatile可以阻止重排序。
但是如果共享变量完全包含在synchronzied中,则是可以保证可见性、原子性、禁止指令重排的。能一部分在synchronized之外,脱离synchronzied的管理。
5.double-checked locking 解决方法

// -------------------------------------> 加入对 INSTANCE 变量的读屏障
0: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
3: ifnonnull 37
6: ldc #3 // class cn/itcast/n5/Singleton
8: dup
9: astore_0
10: monitorenter -----------------------> 保证原子性、可见性
11: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
14: ifnonnull 27
17: new #3 // class cn/itcast/n5/Singleton
20: dup
21: invokespecial #4 // Method "":()V
24: putstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
// -------------------------------------> 加入对 INSTANCE 变量的写屏障
27: aload_0
28: monitorexit ------------------------> 保证原子性、可见性
29: goto 37
32: astore_1
33: aload_0
34: monitorexit
35: aload_1
36: athrow
37: getstatic #2 // Field INSTANCE:Lcn/itcast/n5/Singleton;
40: areturn

即使t2线程的getstatic发生在t1线程putstatic之前也可以保证正确性。因为此时t2获取到的是空静态变量,还是会进入synchronized同步块等待。

如上面的注释内容所示,读写 volatile 变量时会加入内存屏障(Memory Barrier(Memory Fence)),保证下面两点:
【1】可见性
- 写屏障(sfence)保证在该屏障之前的 t1 对共享变量的改动,都同步到主存当中。
- 读屏障(lfence)保证在该屏障之后 t2 对共享变量的读取,加载的是主存中最新数据。
【2】有序性 - 写屏障会确保指令重排序时,不会将写屏障之前的代码排在写屏障之后
- 读屏障会确保指令重排序时,不会将读屏障之后的代码排在读屏障之前
更底层是读写变量时使用 lock 指令来多核 CPU 之间的可见性与有序性。