从Nginx快速认知到LVS+Nginx实现高可用集群
从Nginx快速认知到LVS+Nginx实现高可用集群
文章目录
- 从Nginx快速认知到LVS+Nginx实现高可用集群
-
- 第1章 Nginx快速认知
-
- 1-1 集群阶段开篇概述
-
- 项目演变历程
- 单体初期
- 单体后续
- 单体架构的优点
- 单体架构面临的挑战
- 集群概念
- 举例集群概念
- 举例电商项目中使用集群
- 使用集群的优势
- 使用集群注意点
- 1-2 什么是Nginx?常用的web服务器有哪些?
-
- 什么是Nginx
- 常见的服务器
- 1-3 什么是反向代理?
-
- 什么是正向代理
- 什么是反向代理
- 反向代理之路由
- 正向代理和反向代理的区别
- 1-4 安装Nginx与运行
-
- 注意事项:
- 1-5 Nginx显示默认首页过程解析
-
- 请求Nginx默认页面
- Nginx默认配置文件`conf/nginx.conf`解读
- 1-6 Nginx进程模型解析
-
- Nginx的进程模型
- 1-7 Nginx处理Web请求机制解析
-
- worker抢占机制
- 传统服务器事件处理
-
- 同步阻塞(最早期)
- 后期改进
- 存在的问题
- Nginx事件处理
- 总结nginx为啥能达到如此高的并发
- 1-8 nginx.conf 配置结构与指令语法
-
- nginx.conf配置结构
- 1-9 附:同步与异步,阻塞与非阻塞
- 1-10 附:nginx.conf 核心配置文件
- 1-11 nginx.pid打开失败以及失效的解决方案
-
- 问题
- 解决方案
- 1-12 Nginx常用命令解析
- 1-13 Nginx日志切割 - 手动
-
- 操作步骤
- 结果
- 1-14 Nginx日志切割 - 定时
-
- 使用定时任务
- 定时任务表达式
- 常用表达式
- 1-15 虚拟主机 - 使用Nginx为静态资源提供服务
-
- 静态资源分类
- 操作步骤
- 配置静态资源映射存在的问题
- 1-16 使用Gzip压缩提升请求效率
- 1-17 root 与 alias
- 1-18 location的匹配规则解析
- 1-19 DNS域名解析
-
- DNS域名解析
- 1-20 使用SwitchHosts 模拟本地域名解析访问
- 第2章 Nginx进阶与实战
-
- 2-1 在Nginx中解决跨域问题
-
- 什么是跨域
- 同源策略
- 跨域问题常见解决方式
-
- 1、JSONP
- 2、CORS
- 3、nginx 转发
- Nginx的跨域
- CORS跨域资源共享
- nginx解决跨域问题
-
- 问题描述
- 解决方法
- 访问
- 2-2 在Nginx中配置静态资源防盗链
-
- nginx配置
- 访问
- 2-3 Nginx的模块化设计
-
- nginx的模块化体系
- nginx安装目录介绍
- 2-4 Nginx的集群负载均衡解析
-
- 单节点
- 集群
- nginx集群负载均衡
- 2-5 四层、七层与DNS负载均衡
-
- 四层负载均衡
- 七层负载均衡
- DNS地域负载均衡
- 2-6 OSI 网络模型
- 2-7 使用Nginx搭建3台Tomcat集群
-
- Nginx搭建Tomcat集群
- Nginx配置
- 访问
- 2-8 使用JMeter测试单节点与集群的并发异常率
-
- 官网
- 2-9 负载均衡之轮询
-
- 负载均衡默认策略 - 轮询
- 2-10 负载均衡之权重
-
- 负载均衡 - 加权轮询
- nginx配置
- 2-11 upstream的指令参数之max_conns
-
- upstream的指令参数
- 官方地址
- nginx配置
- 测试结果
- 2-12 upstream的指令参数之slow_start
-
- 官方解释
- nginx配置
- 2-13 upstream的指令参数之down与backup
-
- down官方解释
- backup官方解释
- 2-14 upstream的指令参数之max_fails与fail_timeout
-
- max_fails官方解释
- fail_timeout官方解释
- 同时设置解释
- 2-15 使用Keepalived提高吞吐量
-
- 官方地址
- 作用解释
- 2-16 负载均衡原理 - ip_hash
-
- 负载均衡 之 ip_hash
- hash算法
- 使用ip_hash的注意点
- nginx配置
- nginx默认ip_hash算法原则
- 2-17 一致性hash算法
-
- hash算法带来的问题
- 一致性hash算法(解决hash算法带来的问题)
- 一致性hash算法 减少服务器
- 一致性hash算法 新增服务器
- nginx使用一致性哈希算法
- 2-18 负载均衡原理 - url hash 与 least_conn
-
- 负载均衡 之 url hash
- 测试url hash
-
- Java代码
- nginx配置
- 访问测试
- 负载均衡 之 least_conn
-
- nginx配置
- 2-19 Nginx控制浏览器缓存
-
- 缓存介绍
- 缓存
- expires指令
- 测试expires指令控制浏览器端缓存
-
- 测试一:默认expires off;
- 测试二:默认expires 10s;
- 2-20 Nginx的反向代理缓存
- 2-21 使用Nginx配置SSL证书提供HTTPS访问
-
- 前言
- 使用Nginx配置ssl证书
-
- 1. 安装SSL模块
- 2. 配置HTTPS
- 3. reload nginx
- 附:
- 2-22 动静分离的那些事儿
-
- 动静分离的特点
- 动静分离
- 动静分离的实现方式 - CDN
- 动静分离的实现方式 - Nginx
- 动静分离的问题
- 2-23 部署Nginx到云端 - 安装Nginx
-
- 现阶段部署架构
- Nginx部署架构
- 第3章 Keepalived原理与实战
-
- 3-1 高可用集群架构Keepalived双机主备原理
-
- Nginx高可用HA
- Keepalived概念
- 虚拟路由冗余协议 VRRP
- Keepalived双机主备原理
- 3-2 Keepalived安装部署
-
- Keepalived安装图解
- Keepalived安装部署
- 3-4 Keepalived核心配置文件
- 3-5 配置 Keepalived - 主
-
- 1. 通过命令 `vim keepalived.conf` 打开配置文件
- 2. 启动 Keepalived
- 3. 查看进程
- 4. 查看vip
- 3-6 把Keepalived注册为系统服务
-
- 把Keepalived注册为系统服务
- 3-7 配置 Keepalived - 备
-
- 1. 通过命令 `vim keepalived.conf` 打开配置文件
- 2. 启动 Keepalived
- 3. 查看进程
- 3-8 Keepalived配置Nginx自动重启,实现7*24小时不间断服务
-
- 1. 增加Nginx重启检测脚本
- 2. 配置keepalived监听nginx脚本
- 3. 在`vrrp_instance`中新增监控的脚本
- 4. 重启Keepalived使得配置文件生效
- 5. 备用节点也可以用同样的方式配置Nginx自动重启
- 3-9 高可用集群架构keepalived双主备热原理
-
- keepalived实现双机主备高可用存在的问题
- Keepalived双主热备
- 云服务的DNS解析配置与负载均衡
- 3-10 配置Keepalived双主热备
-
- 主节点配置
- 备用节点配置
- 分别重启两条Keepalived
- 第4章 搭建高可用集群负载均衡
-
- 4-1 LVS简介
-
- LVS负载均衡
- 官网
- LVS网络拓扑图
- 4-2 为什么要使用 LVS + Nginx?
-
- 为什么要使用 LVS + Nginx
- Nginx网络拓扑图
- LVS网络拓扑图
- 4-3 LVS的三种模式
-
- LVS模式之NAT
- LVS模式之TUN
- LVS模式之DR
- 4-4 搭建LVS-DR模式- 配置LVS节点与ipvsadm
-
- 服务器与IP约定
- 搭建LVS-DR模式- 配置LVS节点与ipvsadm
-
- 前期准备
- 创建子接口
- 创建子接口 - 方式2(不推荐)
- 安装ipvsadm
- 安装成功后,可以检测一下:
- 图中显示目前版本为1.2.1,此外是一个空列表,啥都没。
- 4-5 搭建LVS-DR模式-为两台RS配置虚拟IP
-
- 配置虚拟网络子接口(回环接口)
- 4-6 搭建LVS-DR模式-为两台RS配置arp
-
- ARP响应级别与通告行为 的概念
-
- arp-ignore:ARP响应级别(处理请求)
- arp-announce:ARP通告行为(返回响应)
- 配置ARP
- 4-7 搭建LVS-DR模式-使用ipvsadm配置集群规则
- 4-8 搭建LVS-DR模式-验证DR模式,探讨LVS持久化机制
- 4-9 搭建Keepalived+Lvs+Nginx高可用集群负载均衡 - 配置Master
-
- Keepalived+LVS高可用
- 前期Keepalived安装准备
- Keepalived配置文件配置
- 4-10 搭建Keepalived+Lvs+Nginx高可用集群负载均衡 - 配置Backup
- 4-11 附:LVS的负载均衡算法
-
- 静态算法
- 动态算法
- 总结:
- 附1:
- 附2:
- 4-12 阶段复习
-
- 先来说说第一个部分 - Nginx入门基础
- 再来说说第二个部分 - Nginx进阶
- 高可用集群 LVS + Keepalived
- 总结
第1章 Nginx快速认知
1-1 集群阶段开篇概述
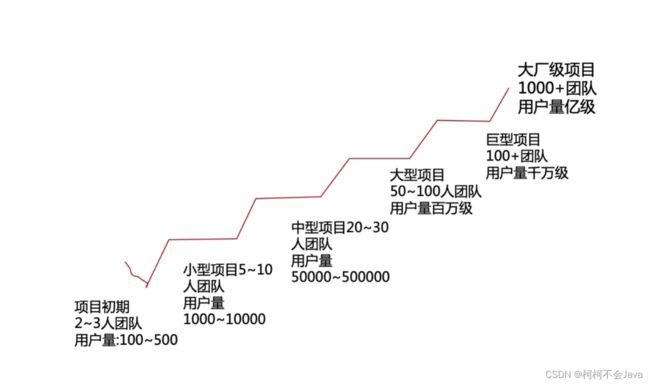
项目演变历程
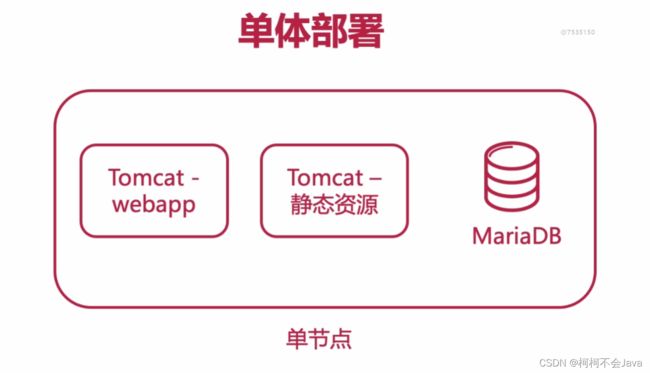
单体初期
前端后及数据库都部署在同一台服务器上(阶段一)
单体后续
有条件可以使用三台服务器分别部署前端、后端、数据库

单体架构的优点
- 小团队成型即可完成开发-测试-上线
- 迭代周期短,速度快
- 打包方便,运维省事
单体架构面临的挑战
- 单节点宕机造成所有服务不可用
- 耦合度太高(迭代,测试,部署)
- 单节点并发能力有限
集群概念
- 计算机‘群体’构成整个系统
- 这个‘群体’构成一个整体,不能独立存在
- ‘人多力量大’,群体提高并发与可用性
举例集群概念
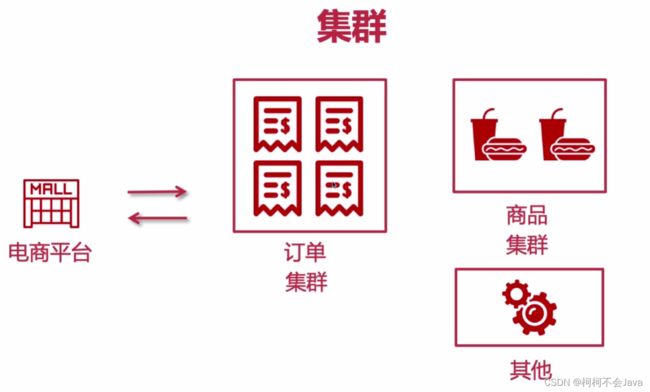
举例电商项目中使用集群
使用集群的优势
- 提高系统性能
- 提高系统可用性
- 可扩展性高
使用集群注意点
- 用户会话
- 定时任务(或多或少会有,可以单独部署成一个项目)
- 内网互通
1-2 什么是Nginx?常用的web服务器有哪些?
什么是Nginx
- Nginx (engine x) 是一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。
- 主要功能是反向代理
- 通过配置文件可以实现集群和负载均衡
- 静态资源虚拟化
- 热加载,不需要重启服务器,避免用户请求丢失
常见的服务器
- MS IIS asp.net
- Weblogic、Jboss 传统行业 ERP/物流/电信/金融
- Tomcat、Jetty J2EE
- Apache、Nginx 静态服务、反向代理
- Netty 高性能服务器编程
1-3 什么是反向代理?
什么是正向代理
- 客户端请求目标服务器之间的一个代理服务器
- 请求会先经过代理服务器,然后再转发请求到目标服务器,获得内容最后响应给客户端

什么是反向代理
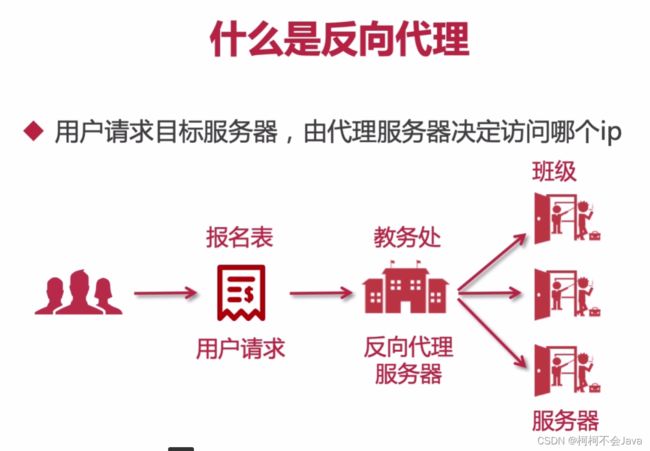
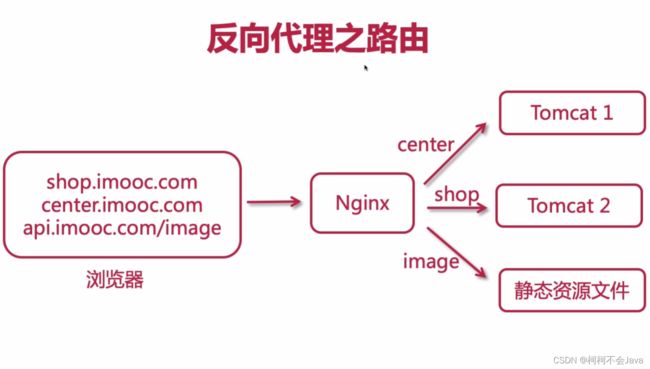
反向代理之路由
正向代理和反向代理的区别
虽然正向代理服务器和反向代理服务器所处的位置都是客户端和真实服务器之间,所做的事情也都是把客户端的请求转发给服务器,再把服务器的响应转发给客户端,但是二者之间还是有一定的差异的。
1、正向代理其实是客户端的代理,帮助客户端访问其无法访问的服务器资源。反向代理则是服务器的代理,帮助服务器做负载均衡,安全防护等。
2、正向代理一般是客户端架设的,比如在自己的机器上安装一个代理软件。而反向代理一般是服务器架设的,比如在自己的机器集群中部署一个反向代理服务器。
3、正向代理中,服务器不知道真正的客户端到底是谁,以为访问自己的就是真实的客户端。而在反向代理中,客户端不知道真正的服务器是谁,以为自己访问的就是真实的服务器。
4、正向代理和反向代理的作用和目的不同。正向代理主要是用来解决访问限制问题。而反向代理则是提供负载均衡、安全防护等作用。
1-4 安装Nginx与运行
-
去官网https://nginx.org/下载对应的nginx包,推荐使用稳定版本
-
上传nginx到linux系统
-
安装依赖环境
(1)安装gcc环境
yum install gcc-c++(2)安装PCRE库,用于解析正则表达式
yum install -y pcre pcre-devel(3)zlib压缩和解压缩依赖,
yum install -y zlib zlib-devel(4)SSL 安全的加密的套接字协议层,用于HTTP安全传输,也就是https
yum install -y openssl openssl-devel -
解压,需要注意,解压后得到的是源码,源码需要编译后才能安装
tar -zxvf nginx-1.16.1.tar.gz -
编译之前,先创建nginx临时目录,如果不创建,在启动nginx的过程中会报错
mkdir /var/temp/nginx -p -
在nginx目录,输入如下命令进行配置,目的是为了创建makefile文件
./configure \n --prefix=/usr/local/nginx \n --pid-path=/var/run/nginx/nginx.pid \n --lock-path=/var/lock/nginx.lock \n --error-log-path=/var/log/nginx/error.log \n --http-log-path=/var/log/nginx/access.log \n --with-http_gzip_static_module \n --http-client-body-temp-path=/var/temp/nginx/client \n --http-proxy-temp-path=/var/temp/nginx/proxy \n --http-fastcgi-temp-path=/var/temp/nginx/fastcgi \n --http-uwsgi-temp-path=/var/temp/nginx/uwsgi \n --http-scgi-temp-path=/var/temp/nginx/scgi注意:linux命令太长换行使用:
\+Enter分开按,提高可读性换行后命令变为:
./configure \ > --prefix=/usr/local/nginx \ > --pid-path=/var/run/nginx/nginx.pid \ > --lock-path=/var/lock/nginx.lock \ > --error-log-path=/var/log/nginx/error.log \ > --http-log-path=/var/log/nginx/access.log \ > --with-http_gzip_static_module \ > --http-client-body-temp-path=/var/temp/nginx/client \ > --http-proxy-temp-path=/var/temp/nginx/proxy \ > --http-fastcgi-temp-path=/var/temp/nginx/fastcgi \ > --http-uwsgi-temp-path=/var/temp/nginx/uwsgi \ > --http-scgi-temp-path=/var/temp/nginx/scgi \-
配置命令解释:
命令 解释 –prefix 指定nginx安装目录 –pid-path 指向nginx的pid –lock-path 锁定安装文件,防止被恶意篡改或误操作 –error-log 错误日志 –http-log-path http日志 –with-http_gzip_static_module 启用gzip模块,在线实时压缩输出数据流 –http-client-body-temp-path 设定客户端请求的临时目录 –http-proxy-temp-path 设定http代理临时目录 –http-fastcgi-temp-path 设定fastcgi临时目录 –http-uwsgi-temp-path 设定uwsgi临时目录 –http-scgi-temp-path 设定scgi临时目录
-
-
make编译
make -
安装
make install -
进入sbin目录
-
启动
./nginx -
停止
./nginx -s stop -
重新加载
./nginx -s reload
- 打开浏览器,访问虚拟机所处内网ip即可打开nginx默认页面
注意事项:
- 如果在云服务器安装,需要开启默认的nginx端口:80
- 如果在虚拟机安装,需要关闭防火墙
- 本地win或mac需要关闭防火墙
1-5 Nginx显示默认首页过程解析
请求Nginx默认页面
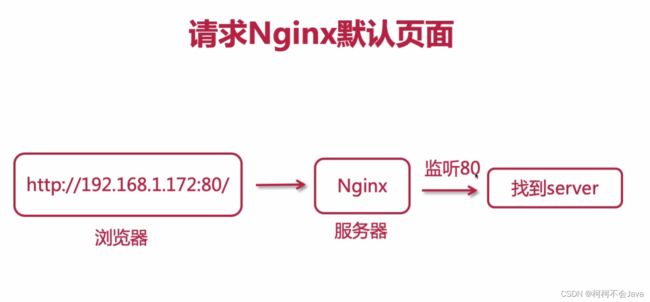
Nginx默认配置文件conf/nginx.conf解读
server { // server代表构建了一台服务器
listen 80; // 代表监听80端口
server_name localhost; // 一般配成localhost/127.0.0.1、服务器内网ip/域名。配完重启访问,如果在本linux系统访问就是localhost,外部访问就是该linux系统ip
location / { // location代表映射
root html; // root代表根,html是是相对路径,和conf在同一级目录
index index.html index.htm; // 首页,表示找到这台服务器后默认打开html/index.html
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
注意:server_name后配置的文本其实并没有实际意义,如果随意配置一串文本,但我们需要用这串文本访问到nginx服务器,就需要保证这串文本解析成的ip对应为nginx服务器的ip,比如这串文本配置为nginx服务器的域名。但我们如果随意配置,我们请求nginx服务器都是用ip或者域名+listen配置的监听端口请求,仍然是可以请求到的。
1-6 Nginx进程模型解析
Nginx的进程模型
- mater进程:主进程,管理、传递指令、监控worker进程,比如信号:./nginx -s stop,./nginx -s quit,./nginx -s reload,./nginx -t,都是mater进程接收信号后交给worker进程去做的
- worker进程:工作进程

修改conf/nginx.conf中的
worker_processes 2;
重启nginx可以设置worker进程工作数

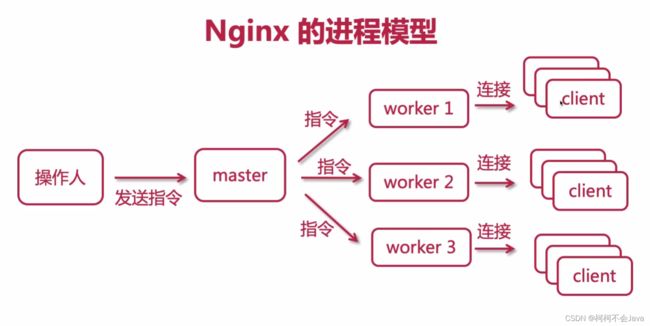
操作人发送指令给master进程,master进程再将指令一个个分发给worker进程,对于用户(客户端)来说,客户端会发送大量请求,每一个worker进程都会和客户端之间建立连接,处理请求 。假设操作人发送停止的信号,此时worker1和work2没有连接客户端处理请求,work3正在处理请求,work1和work2会直接关闭,work3会等到请求处理完成后才关闭。虽然多线程的开销小于进程,但是它们会共用一个内存,而且线程之间会相互影响,需要开发人员自行维护内存管理,并且增加了一定的风险,nginx这种多进程处理的方式是相互独立的,保证相互之间是安全的。如果一个worker进程异常退出,其他的worker进程会正常运转,master进程只需要重新创建一个新的进程即可,可以避免黑客的攻击。
1-7 Nginx处理Web请求机制解析
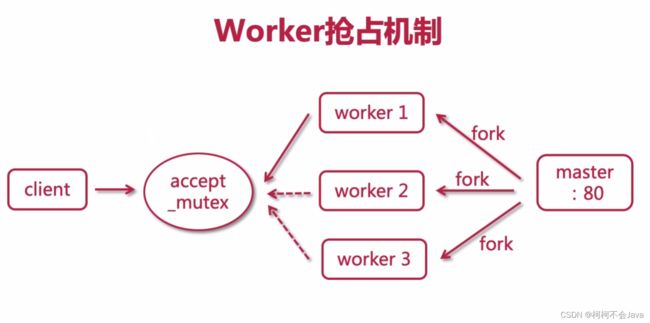
worker抢占机制
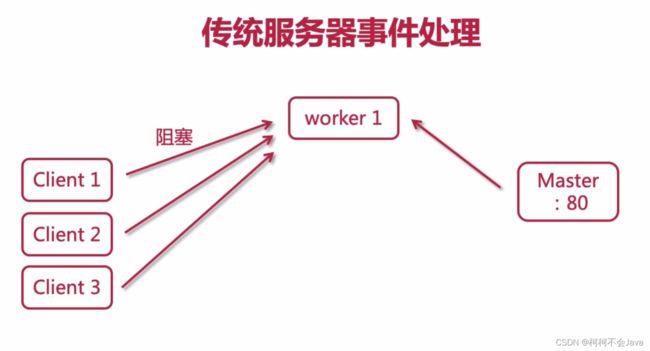
传统服务器事件处理
同步阻塞(最早期)
后期改进
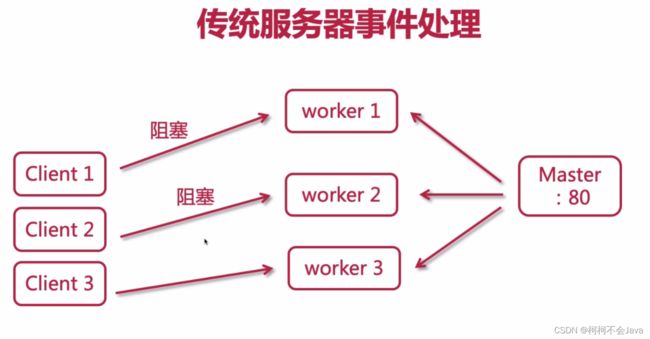
存在的问题
假设有很多客户端,存在阻塞的情况也就会有很多,服务器就会开很多的进程去处理客户端,导致服务器的开销过大,成本增高。
Nginx事件处理
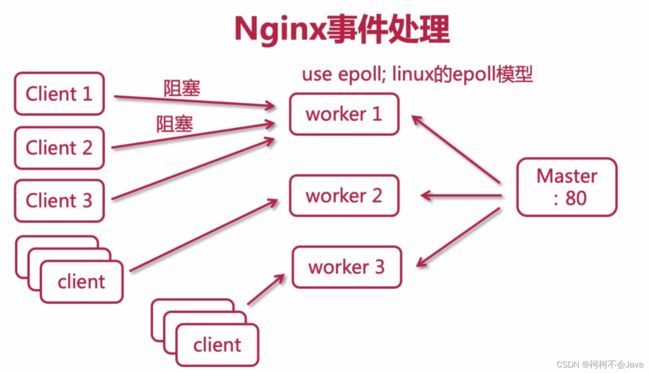
Nginx是异步非阻塞的,但worker1进程在处理Client1时阻塞了,仍然会处理Client2、Client3等,Client2阻塞仍然会处理Client3等,worker进程在linux系统中采用epoll模型(默认,windows和mac需要更改),单个worker进程一般可以同时处理6万到8万个请求,且跟服务器的cpu相关,假设有一万个请求,传统服务器就需要一万个worker,但是nginx只需要3到4个甚至更少的worker。当然可以限制单个worker进程的最大连接数(默认为1024,配置根据硬件来)
在conf\nginx.conf文件中更改
events {
# 默认使用epoll
use epoll;
# 每个worker允许连接的客户端最大连接数
worker_connections 10240;
}
总结nginx为啥能达到如此高的并发
- worker进程的抢占式机制
- worker进程的异步非阻塞的,类似多路复用器(Netty会涉及,是一种高效的通信模式,websocket、聊天也可使用这种模式开发)
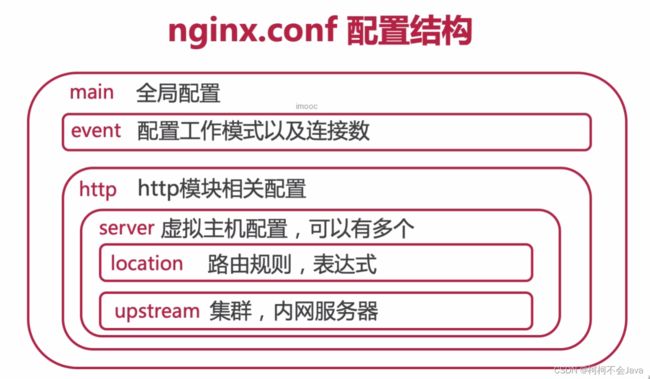
1-8 nginx.conf 配置结构与指令语法
nginx.conf配置结构
1-9 附:同步与异步,阻塞与非阻塞
上面提到了阻塞与非阻塞、同步与异步,很多人可能会认为同步就是阻塞,异步就是非阻塞,非也非也,下面聊一聊他们的概念,有啥区别,这些概念往往在面试过程中有可能会被面试官问到。
这四个概念两两组合,会形成4个新的概念,如下:
1. 同步阻塞: 客户端发送请求给服务端,此时服务端处理任务时间很久,则客户端则被服务端堵塞了,所以客户端会一直等待服务端的响应,此时客户端不能做其他任何事,服务端也不会接受其他客户端的请求。这种通信机制比较简单粗暴,但是效率不高。
2. 同步非阻塞: 客户端发送请求给服务端,此时服务端处理任务时间很久,这个时候虽然客户端会一直等待响应,但是服务端可以处理其他的请求,过一会回来处理原先的。这种方式很高效,一个服务端可以处理很多请求,不会在因为任务没有处理完而堵着,所以这是非阻塞的。
3. 异步阻塞: 客户端发送请求给服务端,此时服务端处理任务时间很久,但是客户端不会等待服务器响应,它可以做其他的任务,等服务器处理完毕后再把结果响应给客户端,客户端得到回调后再处理服务端的响应。这种方式可以避免客户端一直处于等待的状态,优化了用户体验,其实就是类似于网页里发起的ajax异步请求。
4. 异步非阻塞: 客户端发送请求给服务端,此时服务端处理任务时间很久,这个时候的任务虽然处理时间会很久,但是客户端可以做其他的任务,因为他是异步的,可以在回调函数里处理响应;同时服务端是非阻塞的,所以服务端可以去处理其他的任务,如此,这个模式就显得非常的高效了。
以上四点,除了第三点,其余的分别为BIO/NIO/AIO,面试官如果问你“请简述一下BIO/NIO/AIO之间的概念与区别”,那么你就可以组织一下语言来回答,或者通过如下生活实例来阐述也是可以的:
1. BIO: 我去上厕所,这个时候坑位都满了,我必须等待坑位释放了,我才能上吧?!此时我啥都不干,站在厕所里盯着,过了一会有人出来了,我就赶紧蹲上去。
2. NIO: 我去上厕所,这个时候坑位都满了,没关系,哥不急,我出去抽根烟,过会回来看看有没有空位,如果有我就蹲,如果没有我出去接着抽烟或者玩会手机。
3. 异步阻塞: 我去上厕所,这个时候坑位都满了,没事我等着,等有了新的空位,让他通知我就行,通知了我,我就蹲上去。
4. AIO: 我去上厕所,这个时候坑位都满了,没事,我一点也不急,我去厕所外面抽根烟再玩玩手机,等有新的坑位释放了,会有人通知我的,通知我了,我就可以进去蹲了。
从这个生活实例中能可以看得出来:
同步就是我需要自己每隔一段时间,以轮询的方式去看看有没有空的坑位;异步则是有人拉完茅坑会通知你,通知你后你再回去蹲;阻塞就是在等待的过程中,你不去做其他任何事情,干等着;非阻塞就是你再等待的过程中可以去做其他的事,比如抽烟、喝酒、烫头、玩手机。
小结:异步的优势显而易见,大大优化用户体验,非阻塞使得系统资源开销远远小于阻塞模式,因为系统不需要创建新的进程(或线程),大大地节省了系统的资源,如此多出来的系统资源可以给其他的中间件去服务了。
1-10 附:nginx.conf 核心配置文件
-
设置worker进程的用户,指的linux中的用户,会涉及到nginx操作目录或文件的一些权限,默认为
nobodyuser root;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2ExpSB5K-1668673278343)(.\picture\微信图片_20211126172230.png)]
-
worker进程工作数设置,一般来说CPU有几个,就设置几个,或者设置为N-1也行
worker_processes 1; -
nginx 日志级别
debug | info | notice | warn | error | crit | alert | emerg,错误级别从左到右越来越大,之前安装nginx时,有配置--error-log-path=/var/log/nginx/error.log,可以查看 -
设置nginx进程 pid,之前安装nginx时,有配置
--pid-path=/var/run/nginx/nginx.pid,可以查看pid logs/nginx.pid; -
设置工作模式
events { # 默认使用epoll,linux使用默认epoll,其他不同的操作系统需要更改 use epoll; # 每个worker允许连接的客户端最大连接数 worker_connections 10240; } -
http 是指令块,针对http网络传输的一些指令配置
http { } -
include 引入外部配置,提高可读性,避免单个配置文件过大
include mime.types; -
设定日志格式,
main为定义的格式名称,如此 access_log 就可以直接使用这个变量了,用户请求时通过http协议传输,只要接收到请求都会放入access_log文件中,--http-log-path=/var/log/nginx/access.log是安装时设置的地址。log_format后面是默认的日志格式,自定义可放开修改

参数名 参数意义 $remote_addr 客户端ip $remote_user 远程客户端用户名,一般为:’-’ $time_local 时间和时区 $request 请求的url以及method $status 响应状态码 $body_bytes_send 响应客户端内容字节数 $http_referer 记录用户从哪个链接跳转过来的 $http_user_agent 用户所使用的代理,一般来时都是浏览器 $http_x_forwarded_for 通过代理服务器来记录客户端的ip -
sendfile使用高效文件传输,提升传输性能。启用后才能使用tcp_nopush,tcp_nopush是指当数据表累积一定大小后才发送,提高了效率。否则是一次一次发送sendfile on; tcp_nopush on; -
keepalive_timeout设置客户端与服务端请求的超时时间,单位为秒(s),保证客户端多次请求的时候不会重复建立新的连接,节约资源损耗。#keepalive_timeout 0; keepalive_timeout 65; -
gzip启用压缩,html/js/css压缩后传输会更快gzip on; -
server可以在http指令块中设置多个虚拟主机
-
listen 监听端口
-
server_name localhost、ip、域名
-
location 请求路由映射,匹配拦截
-
root 请求位置
-
index 首页设置
server { listen 88; server_name localhost; location / { root html; index index.html index.htm; } }
- 可以使用
include标签引入外部配置文件,如下
nginx.conf配置文件中
include imooc.conf;
imooc.conf配置文件中
server {
listen 89;
server_name localhost;
location / {
root html;
index imooc.html index.htm;
}
}
测试配置
./nginx -t
1-11 nginx.pid打开失败以及失效的解决方案
问题
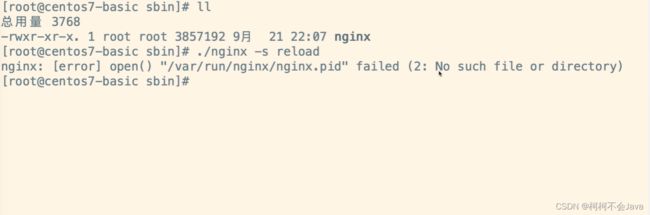
解决方案
第一种方式:创建默认目录 /var/run/nginx/ ,重启nginx即可。(不推荐,这种方式只能临时解决,后续虚拟机重启再次启动nginx仍然回报错,因为每次虚拟机重启后,var/run/nginx,nginx这个文件夹都会被删除,搞得每一次都要去建立nginx这个文件夹)
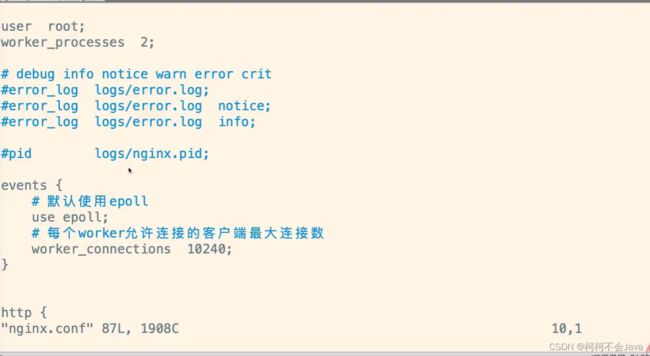
第二种方式:修改nginx.conf文件,指定 **pid文件 **所在目录
步骤一:进入cd /usr/local/nginx/conf/目录,编辑配置文件nginx.conf;将配置文件中有个注释的地方:#pid logs/nginx.pid;修改为:pid /usr/local/nginx/logs/nginx.pid;。
步骤二:nginx.pid默认位置在logs下在该/usr/local/nginx下创建logs文件夹,重启nginx即可。(推荐)
1-12 Nginx常用命令解析
./nginx -s stop:暴力关闭nginx,如果此时服务器有用户请求,也会直接关闭,慎用。
./nginx -s quit:优雅关闭nginx,只针对http请求,如果此时服务器有用户请求,不会直接关闭,等用户请求完毕才会关闭。
./nginx -t:修改配置文件后,检测配置文件是否正确。
./nginx -v:查看当前nginx版本号。
./nginx -V:查看当前nginx版本号,更加具体。
./nginx -?/./nginx -h:帮助,提供命令列表。
./nginx -c 文件名:手动切换nginx配置文件
1-13 Nginx日志切割 - 手动
Nginx的所有日志都配置在/var/log/nginx目录下,错误日志在error.log中,请求日志在access.log中,但是随着时间的推移,当用户量变大,请求过多时,这两个日志文件会很大,不易做日志分析,不便于运维人员查看,所以我们可以把这个大的日志文件切割为多份不同的小文件,切割规则可以以天为单位,如果每天有几百G或者几个T的日志的话,则可以按需以每半天或者每小时对日志切割一下。这种方式叫做日志切割。
操作步骤
-
在
/usr/local/nginx/sbin创建一个shell可执行文件:cut_my_log.sh,内容为:#!/bin/bash LOG_PATH="/var/log/nginx/" RECORD_TIME=$(date -d "yesterday" +%Y-%m-%d+%H:%M) PID=/var/run/nginx/nginx.pid mv ${LOG_PATH}/access.log ${LOG_PATH}/access.${RECORD_TIME}.log mv ${LOG_PATH}/error.log ${LOG_PATH}/error.${RECORD_TIME}.log #向Nginx主进程发送信号,用于重新打开日志文件 kill -USR1 `cat $PID` -
为
cut_my_log.sh添加可执行的权限:chmod +x cut_my_log.sh -
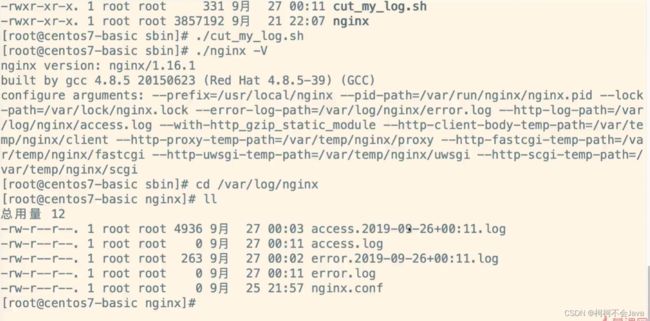
测试日志切割后的结果:
./cut_my_log.sh
结果
1-14 Nginx日志切割 - 定时
使用定时任务
-
安装定时任务:
yum install crontabs -
crontab -l查看当前定时任务列表 -
crontab -e编辑并且添加一行新的任务:*/1 * * * * /usr/local/nginx/sbin/cut_my_log.sh -
重启定时任务:
service crond restart
-
附:常用定时任务命令:
service crond start //启动服务 service crond stop //关闭服务 service crond restart //重启服务 service crond reload //重新载入配置 crontab -e // 编辑任务 crontab -l // 查看任务列表
定时任务表达式
Cron表达式是,分为5或6个域,每个域代表一个含义,如下所示:
| 分 | 时 | 日 | 月 | 星期几 | 年(可选) | |
|---|---|---|---|---|---|---|
| 取值范围 | 0-59 | 0-23 | 1-31 | 1-12 | 1-7 | 2019/2020/2021/… |
常用表达式
-
每分钟执行:
*/1 * * * * -
每日凌晨(每天晚上23:59)执行:
59 23 * * * -
每日凌晨1点执行:
0 1 * * *
参考文献:
- 每天定时为数据库备份:https://www.cnblogs.com/leechenxiang/p/7110382.html
1-15 虚拟主机 - 使用Nginx为静态资源提供服务
静态资源分类
- 代码页面:html、css、js
- 音频、视频、图片
操作步骤
1、将我们的前端项目foodie-shop放入服务器的/home文件夹下
2、在imooc.conf配置文件中配置
server {
listen 90;
server_name localhost;
location / { ## foodie-shop项目的映射配置,请求路径ip:90
root /home/foodie-shop;
index index.html;
}
}
3、重启访问即可
4、配置图片的访问地址
server {
listen 90;
server_name localhost;
location / { ## foodie-shop项目的映射配置,请求路径ip:90
root /home/foodie-shop;
index index.html;
}
location /imooc { ## 静态资源的映射配置,请求路径ip:90/imooc/图片目录
root /home;
}
}
配置静态资源映射存在的问题
因为/imooc这个文件夹是服务器中的,对于用你用户来说是不友好,可以使用别名
server {
listen 90;
server_name localhost;
location / { ## foodie-shop项目的映射配置,请求路径ip:90
root /home/foodie-shop;
index index.html;
}
location /imooc { ## 静态资源的映射配置,请求路径ip:90/imooc/图片目录
root /home;
}
location /static { ## 此时当访问ip:90/static都会映射成/home/imooc
alias /home/imooc;
}
}
1-16 使用Gzip压缩提升请求效率
#开启gzip压缩功能,目的:提高传输效率,节约带宽
gzip on;
#限制最小压缩,小于1字节文件不会压缩
gzip_min_length 1;
#定义压缩的级别(压缩比,文件越大,压缩越多,但是cpu使用会越多) 范围1-9
gzip_comp_level 3;
#定义压缩文件类型
gzip_types
1-17 root 与 alias
假如服务器路径为:/home/imooc/files/img/face.png
-
root 路径完全匹配访问
配置的时候为:location /imooc { root /home }
用户访问的时候请求为:url:port/imooc/files/img/face.png
-
alias 可以为你的路径做一个别名,对用户透明
配置的时候为:
location /static { alias /home/imooc }用户访问的时候请求为:
url:port/static/files/img/face.png,如此相当于为目录imooc做一个自定义的别名。
总结:root指令配置会将location后面配置的文本带到root配置的路径后面,alias指令配置则相当于为目录创建一个自定义的别名。
1-18 location的匹配规则解析
空格:默认匹配,普通匹配
location / {
root /home;
}
用户访问的时候请求为:url:port/face1.png,就会去/home下找face1.png文件
=:精确匹配
location = /imooc/img/face1.png {
root /home;
}
用户访问的时候请求为:url:port/imooc/img/face1.png,就会访问/home/imooc/img/face1.png文件,无法访问face2.png
~:~代表正则表达式,匹配正则表达式,区分大小写
location ~ \.(GIF|PNG|bmp|jpg|jpeg) {
root /home;
}
表示静态资源格式只要是GIF|png|bmp|jpg|jpeg中一个且区分大小写都会去/home文件夹下找,用户访问的时候请求为:url:port/imooc/img/face1.png,即使有但也是不会显示
~*:匹配正则表达式,不区分大小写
location ~* \.(GIF|png|bmp|jpg|jpeg) {
root /home;
}
表示静态资源格式只要是GIF|png|bmp|jpg|jpeg中一个且不区分大小写都会去/home文件夹下找,用户访问的时候请求为:url:port/imooc/img/1001.gif,有也会显示
^~:^代表非,~代表正则表达式,整体代表以某个字符路径开头请求
location ^~ /imooc/img {
root /home;
}
用户访问的时候请求为:url:port/imooc/img/1001.gif,有会显示,但是用户无法访问/home/imooc/img/文件夹之外的静态资源
1-19 DNS域名解析
DNS域名解析

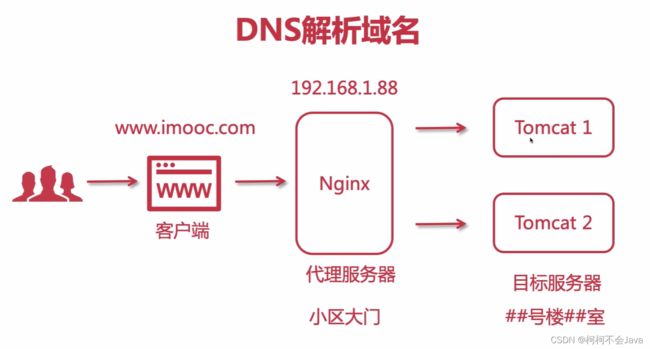
注意:nginx是暴露在公网可以被访问的,tomcat是在内网基于nginx去访问的
1-20 使用SwitchHosts 模拟本地域名解析访问
在SwitchHosts内配置如下

第2章 Nginx进阶与实战
2-1 在Nginx中解决跨域问题
什么是跨域
CORS全称Cross-Origin Resource Sharing,意为跨域资源共享。当一个资源去访问另一个不同域名或者同域名不同端口的资源时,就会发出跨域请求。如果此时另一个资源不允许其进行跨域资源访问,那么访问就会遇到跨域问题。
跨域指的是浏览器不能执行其它网站的脚本。是由浏览器的同源策略造成的,是浏览器对JavaScript 施加的安全限制。
同源策略
同源策略,是由 Netscape 提出的一个安全策略,它是浏览器最核心也是最基本的安全功能,如果缺少同源策略,则浏览器的正常功能可能都会受到影响,现在所有支持JavaScript的浏览器都会使用这个策略。
规定:浏览器要求,在解析Ajax请求时,要求浏览器的路径与Ajax的请求的路径必须满足三个要求,则满足同源策略,可以访问服务器。
要求:协议、域名、端口号都相同,只要有一个不相同,那么都是非同源。
跨域问题常见解决方式
1、JSONP
利用script标签没有跨域的限制,网页可以从其他来源动态的获取JSON数据,从而实现跨域。是通过script标签的src属性实现的,只支持get请求,并且兼容性好,几乎所有浏览器都支持。JSONP是非同源策略,AJAX属于同源策略。
2、CORS
前端浏览器在IE9以上,后端在响应报头添加Access-Control-Allow-Origin标签,从而允许指定域的站点访问当前域上的资源。
res.setHeader("Access-Control-Allow-Origin","*");
不过CORS默认只支持GET/POST这两种http请求类型,如果要开启PUT/DELETE之类的方式,需要在服务端在添加一个"Access-Control-Allow-Methods"报头标签。
3、nginx 转发
nginx的作用相当于是个传话筒,用来做分发转发的作用,通过nginx转发实现请求同一个服务器同一个端口转发到任意服务器任意端口。
Nginx的跨域
两个站点域名不同存在跨域问题
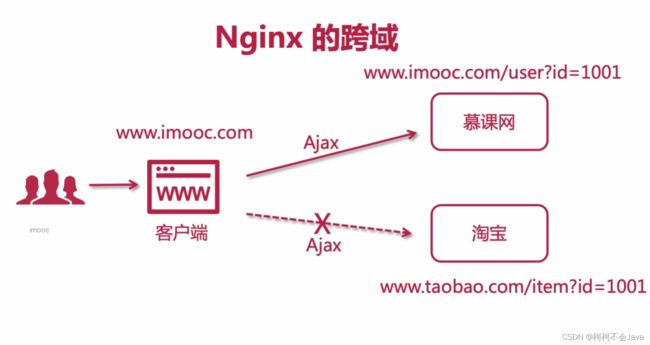
CORS跨域资源共享

nginx解决跨域问题
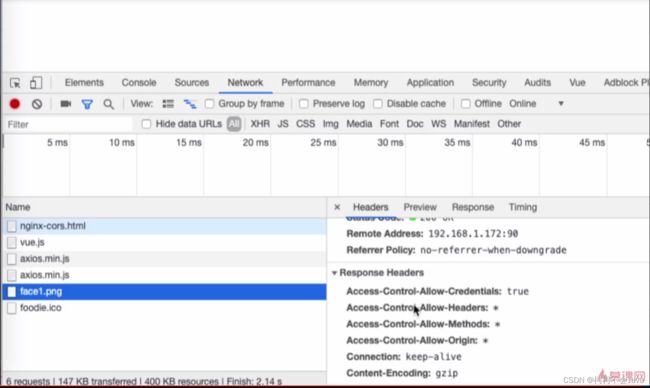
问题描述
比如本地存在一个nginx-cors.html文件如下,serverUrl=“http://192.168.1.172:90/static/img/face1.png”
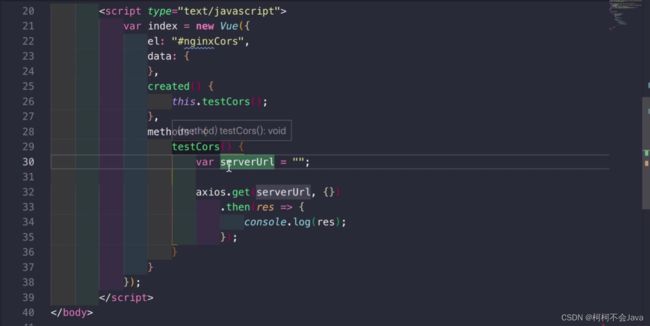
直接访问这个文件地址:“http://localhost:8080/foodie-shop/nginx-cors.html”,控制台报错跨域问题

解决方法
修改nginx配置如下

这样本地90端口的nginx服务器就可以被跨域访问
附:
#允许跨域请求的域,*代表所有
add_header 'Access-Control-Allow-Origin' *;
#允许带上cookie请求
add_header 'Access-Control-Allow-Credentials' 'true';
#允许请求的方法,比如 GET/POST/PUT/DELETE
add_header 'Access-Control-Allow-Methods' *;
#允许请求的header
add_header 'Access-Control-Allow-Headers' *;
访问
2-2 在Nginx中配置静态资源防盗链
当在当前站点引用其它站点的图片时,比如这里的localhost站点访问192.168.1.172站点,对于其它站点来说,请求可以做防盗链措施。
nginx配置
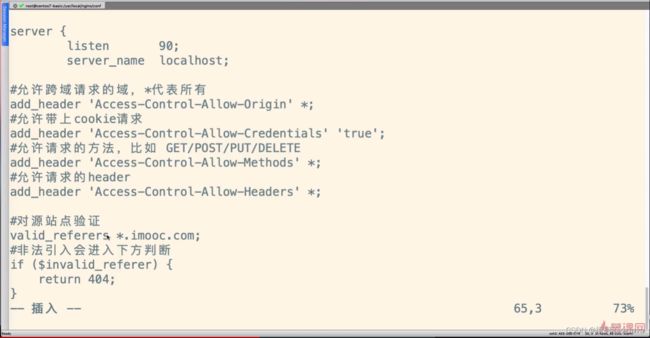
附:
#对源站点验证,判断请求的域名是否在imooc.com之下
valid_referers *.imooc.com;
#非法引入会进入下方判断
if ($invalid_referer) {
return 404;
}
访问
2-3 Nginx的模块化设计
nginx的模块化体系

nginx安装目录介绍
2-4 Nginx的集群负载均衡解析
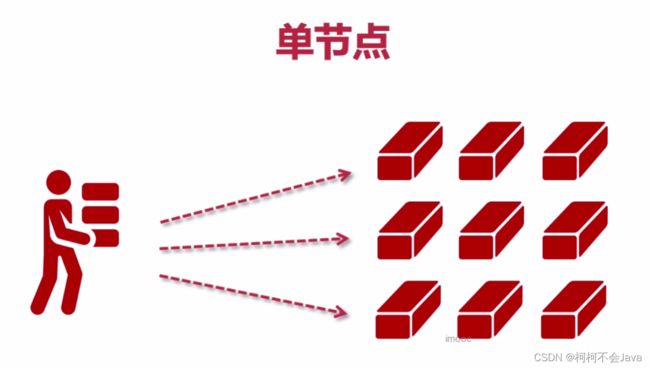
单节点
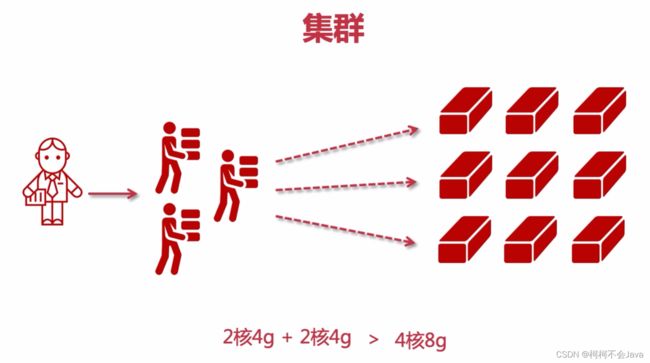
集群
nginx集群负载均衡

2-5 四层、七层与DNS负载均衡
四层负载均衡
基于ip加端口的负载均衡,原理是通过转发请求到后台服务器,它只负责转发,不处理请求,并且会记录当前连接是由哪个服务器处理的,后续这个连接的请求就会由同一台服务器处理,相当于长连接(这个连接一旦打开就会处于连接的状态),性能很高,四层是指传输层,主要基于TCP和HTTP。四层负载均衡一般使用LVS,具体见第4章。

七层负载均衡
基于url或ip的负载均衡,是基于应用层的,是针对HTTP协议的,适用于web服务器(像tomcat、apache、nginx)会处理请求,像js、css、文本等,可以进行压缩或者缓存,七层负载均衡一般使用nginx,具体见2-7。

DNS地域负载均衡

2-6 OSI 网络模型
在讲到Nginx负载均衡的时候,其实Nginx是七层负载均衡,后续我们还会涉及到LVS,是四层负载均衡,七层和四层是什么概念呢?这就必须提到网络模型。网络模型是计算机网络基础的一部分内容,一般大学计算机系都会讲到此知识点,并且会作为考点;其实在面试过程中有时候也会被问到。所以我们还是有必要来复习或学习一下这块的一些重要知识的。
网络模型就是 OSI(Open System Interconnect),意思为开放网络互联,是由国际标准化组织(ISO)和国际电报电话咨询委员会(CCITT)共同出版的,他是一种网络互联模型,也是一种规范。
网络模型分为七层,也就是当用户发起请求到服务器接收,会历经七道工序,或者说用户利用互联网发送消息给另一个用户,也会历经七道工序。这七层可以分为如下:
| 层级 | 名称 | 说明 |
|---|---|---|
| 第七层 | 应用层 | 与用户行为交互 |
| 第六层 | 表示层 | 定义数据格式以及数据加密 |
| 第五层 | 会话层 | 创建、管理以及销毁会话 |
| 第四层 | 传输层 | 创建、管理请求端到响应端(端到端)的连接 |
| 第三层 | 网络层 | 请求端的IP地址 |
| 第二层 | 数据链路层 | 提供介质访问与链路管理 |
| 第一层 | 物理层 | 传输介质,物理媒介 |
以上七层每层可以与上下相邻层进行通信。每一层都是非常复杂的,我们不在这里深究,我们以举例的形式来阐述每一层是干嘛的。
- 应用层: 这是面向用户的,最靠近用户,为了让用户和计算机交互,在计算机里会有很多软件,比如eclipse,idea,qq,nginx等,这些都是应用软件,用户可以通过这些应用软件和计算机交互,交互的过程其实就是接口的调用,应用层为用户提供了交互的接口,以此为用户提供交互服务。那么在这一层最常见的协议有:HTTP,HTTPS,FTP,SMTP,POP3等。Nginx在本层,为七层负载均衡。
举例:我要寄一封信给远在天边的老外LiLei,我会打开快递软件下单,这个时候我是用户,快递软件就是应用服务,是建立在计算机上的,提供给用户交互的一种服务或称之为手段。 - 表示层: 该层提供数据格式编码以及加密功能,确保
请求端的数据能被响应端的应用层识别。
举例:我写中文给LiLei,他看不懂,这个时候我就会使用翻译软件把中文翻译成英文,随后信中涉及到一些比较隐私的信息我会加密一下,这个时候翻译软件和加密器就充当了表示层的作用,他用于显示用户能够识别的内容。 - 会话层: 会话可以理解为session,请求发送到接受响应的这个过程之间存在会话,会话层就充当了这一过程的管理者,从创建会话到维护会话最后销毁会话。
举例:我每次写信给LiLei都会记录在一个小本本上,寄信时间日期,收信时间日期,这本小本本上存有每次通信记录,这个小本本就相当于是一个会话的管理者。又或者说,我们平时在打电话,首先需要拨打电话,这是建立会话,对方接听电话,此时正在通话(维持并管理会话),通话结束后会话销毁,那么这也是一次会话的生命周期。 - 传输层: 该层建立端到端的连接,他提供了数据传输服务,在传输层通信会涉及到端口号,本层常见的协议为TCP、UDP,LVS就是在传输层,也就是四层负载均衡。
举例:我和LiLei通信过程中会借助快递公司,快递公司会分配快递员取件和寄件,那么这个快递员则充当传输层的作用。 - 网络层: 网络通信的时候必须要有本机IP和对方的IP,请求端和响应端都会有自己的IP的,IP就相当于你家地址门牌号,在网络上云服务器有固定的公网IP,普通计算机也有,只不过是动态IP,运营商每天会分配不同的IP给你的计算机。所以网络层也能称之为IP层,IP是互联网的基础根本。能提供IP分配的设备则为路由器或交换机。
举例:对于拥有固定IP的云服务来说,他们都是由腾讯云、阿里云等这样的供应商提供的,他们为云服务器提供固定ip;电信、移动、联调等运营商为你的计算机动态分配ip,每天都不同;则这些供应商和运营商都是网络层。同理,快递员由物流公司分配和管理,那么物流公司就是网络层咯。 - 数据链路层: 这一层会提供计算机MAC地址,通信的时候会携带,为了确保请求投递正确,所以他会验证检测MAC地址,以确保请求响应的可靠性。
举例:快递员在投递派送的时候,他(或客服)会预先提前打电话给你,确认你家地址对不对、有没有人、货到付款有没有准备好钱等等,这个时候快递员(或客服)就充当了数据链路层的职责。 - 物理层: 端到端请求响应过程中的媒介,物理介质,比如网线、中继器等等设备,都是你在端到端交互过程中不可缺少的基础设备。
举例:快递员在投递的过程中,你写的信会历经一些交通运输工具,比如首先通过飞机运输到国外,在海关统一拿到信以后会通过汽车运输到LiLei所在城市的物流集散地,最后快递员通过三轮电频车寄到LiLei家里,这个时候,飞机、汽车、三轮电瓶车都是物理层的媒介。
以上就是七层网络模型,大家理解其意义即可。需要注意的是Nginx存在于第七层,属于七层负载均衡;而第四层会有LVS,属于四层负载均衡。而关于七层和四层的区别我会在下一节来说一说。
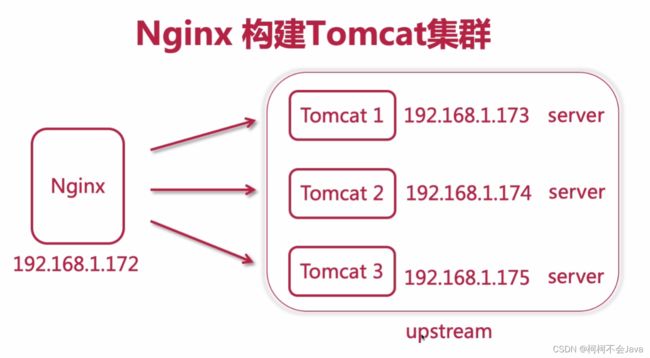
2-7 使用Nginx搭建3台Tomcat集群
Nginx搭建Tomcat集群
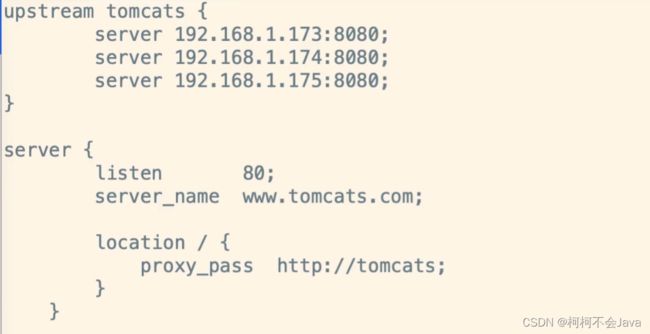
Nginx配置
访问
2-8 使用JMeter测试单节点与集群的并发异常率
官网
https://jmeter.apache.org/
JMeter用于测试单节点与集群的并发异常率
2-9 负载均衡之轮询
负载均衡默认策略 - 轮询
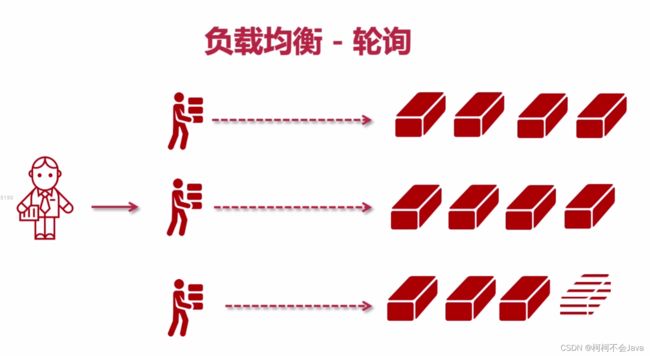
可以通过修改tomcat的默认显示页面,再在浏览器点击访问测试
2-10 负载均衡之权重
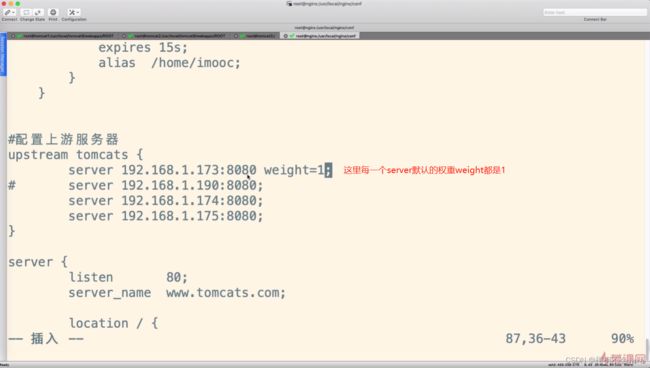
负载均衡 - 加权轮询

nginx配置
默认每一个server的权重都是1
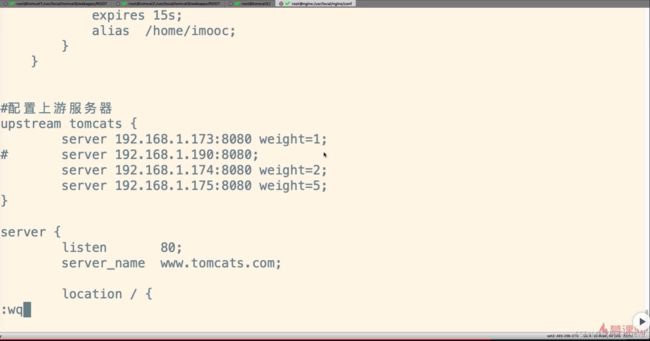
假设173这台服务器性能低,权重分配为1,174服务器性能一般,权重分配为2,175服务器性能很强,权重分配为5,这样大部分请求都会被分配到175这台服务器上
2-11 upstream的指令参数之max_conns
upstream的指令参数

官方地址
https://nginx.org/en/docs/stream/ngx_stream_upstream_module.html
max_conns:限制到代理服务器的最大同时连接数。默认值为零,表示没有限制。如果服务器组不驻留在共享内存中,则限制对每个工作进程有效。在版本1.11.5之前,此参数作为我们商业订阅的一部分提供。
nginx配置
限制每台server的连接数,用于保护避免过载,可起到限流作用。
配置每台服务器的最大连接数为2,测试参考配置如下:
# worker进程设置1个,便于测试观察成功的连接数
worker_processes 1;
upstream tomcats {
server 192.168.1.173:8080 max_conns=2;
server 192.168.1.174:8080 max_conns=2;
server 192.168.1.175:8080 max_conns=2;
}
server {
listen 80;
server_name www.tomcat.com;
location / {
proxy_pass http://tomcats;
}
}
测试结果
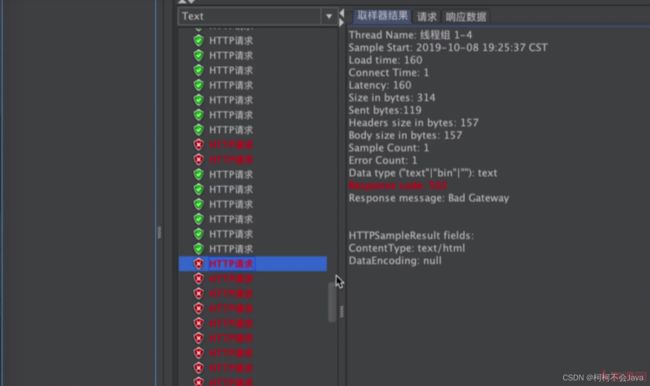
当nginx服务器的并发连接数超过6时,就会拒绝连接,报错502 Bad Gateway
2-12 upstream的指令参数之slow_start
配置该参数可以使得server服务器慢慢的加入集群,而不是一下子启动起来,让用户的所有的流量都能访问到server集群,因为有时候有些server服务器有很多额外的配置,需要慢慢的被启动,然后被用户访问,而且便于运维人员启动监听观察它流量从少到多的过程。
官方解释
设置服务器将其权重从零恢复到标称值的时间,当不正常服务器变为正常状态时,或当服务器在一段时间后被视为不可用时变得可用。默认值为零,即禁用慢启动。
该参数不能与哈希和随机负载平衡方法一起使用。
如果一个组中只有一台服务器,即upstream的server只有一台服务器,则不适用max_fails、fail_timeout和slow_start参数。
nginx配置
注意:商业版,需要付费,这里只做配置演示
2-13 upstream的指令参数之down与backup
down官方解释
将服务器标记为永久不可用。
upstream tomcats {
server 192.168.1.173:8080 down;
server 192.168.1.174:8080 weight=1;
server 192.168.1.175:8080 weight=1;
}
backup官方解释
将服务器标记为备份服务器。当主服务器不可用时,将传递到备份服务器的连接,加入到集群中,被用户访问到。
该参数不能与哈希和随机负载平衡方法一起使用。
upstream tomcats {
server 192.168.1.173:8080 backup;
server 192.168.1.174:8080 weight=1;
server 192.168.1.175:8080 weight=1;
}
2-14 upstream的指令参数之max_fails与fail_timeout
max_fails官方解释
设置与服务器通信的不成功尝试的次数,这些错误在由RealStimeToUT参数设置的持续时间内发生,以考虑服务器也不可用,该故障持续时间也由RealStimeTimeUT参数设置。默认情况下,不成功的尝试次数设置为1。零值将禁用尝试计数。在这里,不成功的尝试是与服务器建立连接时出现的错误或超时。
fail_timeout官方解释
设置与服务器通信的尝试失败的指定次数应该发生在考虑服务器不可用时;
服务器将被视为不可用的时间段。
默认情况下,该参数设置为10秒。
同时设置解释
假设设置max_fail为2,设置fail_timeout为15秒,则如果在15秒内该台server失败两次,就认为该台server是宕机的,随后会等待15秒,在这15秒之内不会有新的请求发送到这台宕机的server里,会把请求发送到正常运作的服务器,等到15秒过后才会有新的请求尝试请求这台宕机的server,如果失败,则会循环这个操作,直到这台宕机的server恢复正常。
2-15 使用Keepalived提高吞吐量
官方地址
https://nginx.org/en/docs/http/ngx_http_upstream_module.html#keepalive
作用解释
keepalived: 设置长连接处理的数量,长连接就可以减少连接创建和关闭的损耗。
proxy_http_version:设置长连接http版本为1.1,默认是1.0,不是长连接
proxy_set_header:对于HTTP,应清除 connection header 信息
upstream tomcats {
# server 192.168.1.173:8080 max_fails=2 fail_timeout=1s;
server 192.168.1.190:8080;
# server 192.168.1.174:8080 weight=1;
# server 192.168.1.175:8080 weight=1;
keepalive 32;
}
server {
listen 80;
server_name www.tomcats.com;
location / {
proxy_pass http://tomcats;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
2-16 负载均衡原理 - ip_hash
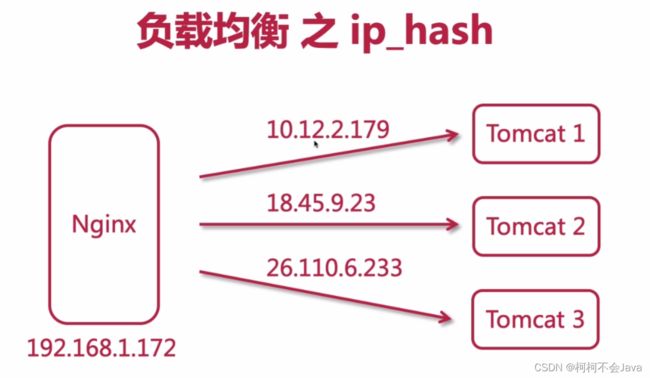
负载均衡 之 ip_hash
hash算法
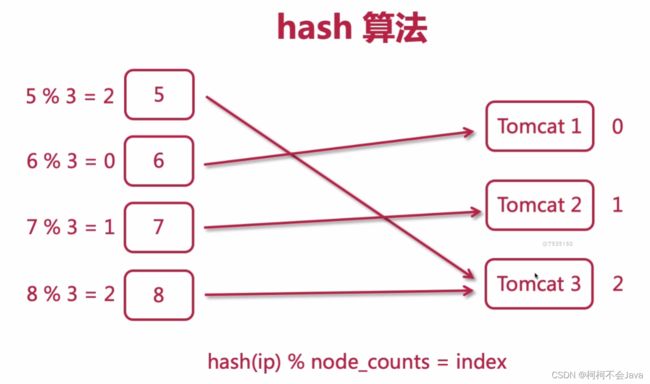
通过hash算法可以保证只要用户的ip不更改,所有的会话会处于同一个tomcat里,这样可以保证同一个ip的相同请求过来服务器的缓存也是可以拿到。同理,数据库也能进行这样的操作,比如数据库中有一张表的数据量庞大,如何把这张表切分成三张表,可以使用hash算法,可以把这张表的主键进行hash再求模,node_counts代表表数量,得到的值放入不同的表中。这样数据的id一般是不会发生改变的,通过这个算法得到的值对应哪个表就查哪个表。
使用ip_hash的注意点
不能把后台服务器直接移除,只能标记down。如果删除,会使得hash算法重算,用户的所有缓存都会失效。
If one of the servers needs to be temporarily removed, it should be marked with the down parameter in order to preserve the current hashing of client IP addresses.
nginx配置
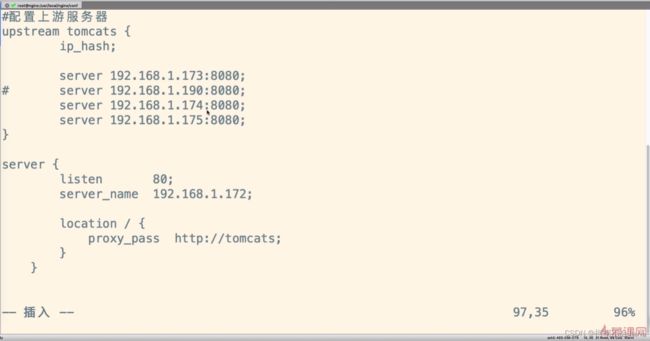
nginx默认ip_hash算法原则

ps:只对ip的前三位进行hash
2-17 一致性hash算法
hash算法带来的问题

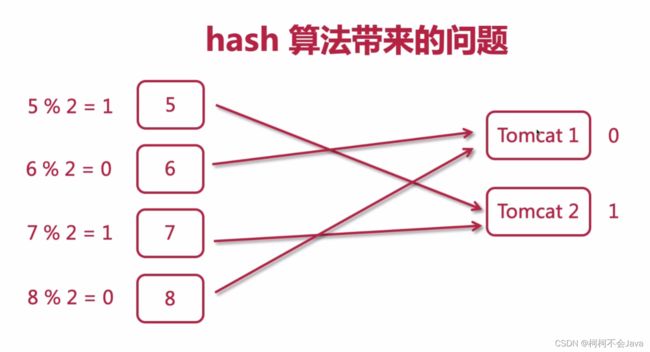
假如tomcat 3这台服务器宕机了,或者新增了一台服务器,hash算法就会重新计算,这样用户在原来服务器里的会话就会丢失,并且在服务器里的缓存也会请求不到,这样用户请求响应的时间就会增加。
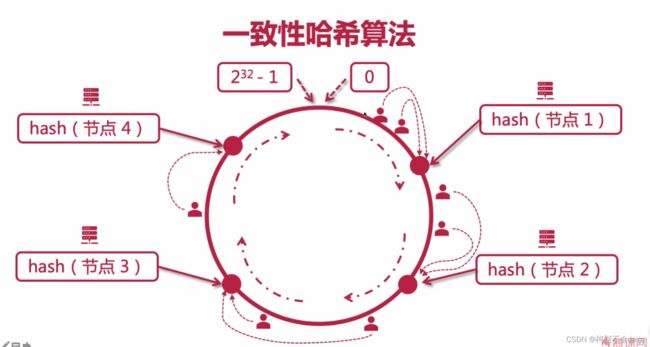
一致性hash算法(解决hash算法带来的问题)
假设存在0->2的32次方-1这样一个闭环,存在节点1到4这四台服务器,通过它们的ip/主机名进行hash计算得到一个值,肯定处于这个闭环上,现在存在用户访问这个项目,通过用户访问的ip计算得到的hash值也会存在这个闭环上,他们所访问的服务器就采用顺时针就近原则。
一致性hash算法 减少服务器
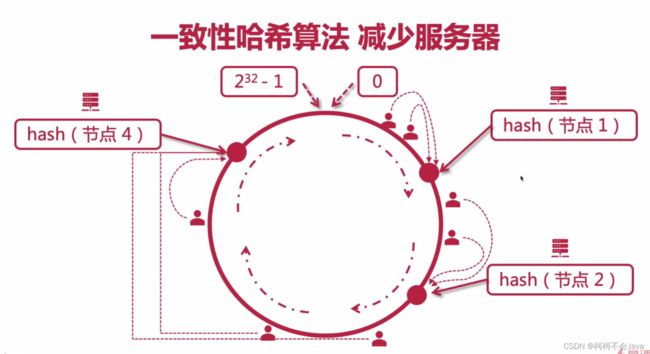
如果节点3宕机,原先请求节点3的用户就会请求节点4,但只有这两个用户的请求的会话会丢失,其他用户请求得会话不会。
一致性hash算法 新增服务器
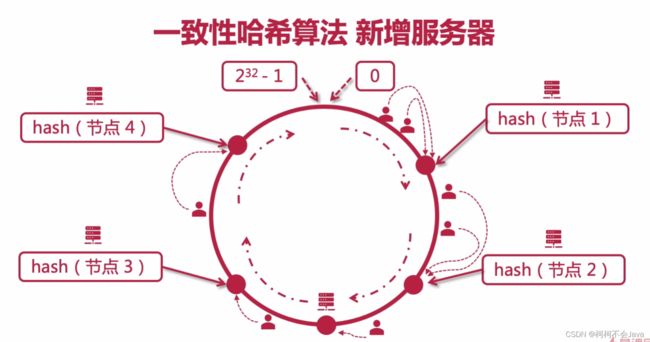
新增一个节点如上,也会产生同样的效果
nginx使用一致性哈希算法
需要下载Nginx一致性hash模块
地址:https://github.com/replay/ngx_http_consistent_hash
2-18 负载均衡原理 - url hash 与 least_conn
负载均衡 之 url hash
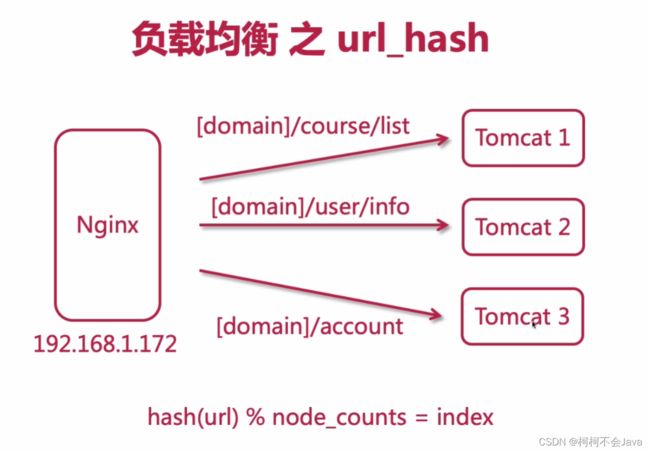
假设[domain]/account账户的请求较多,可以将tomcat3转换为一台nginx,在请求[domain]/account账户时,通过nginx再次转发到不同的服务器。
测试url hash
Java代码

nginx配置
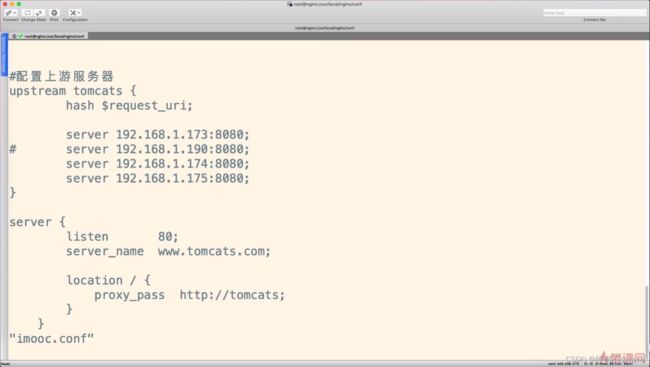
访问测试
修改路由地址可进行测试
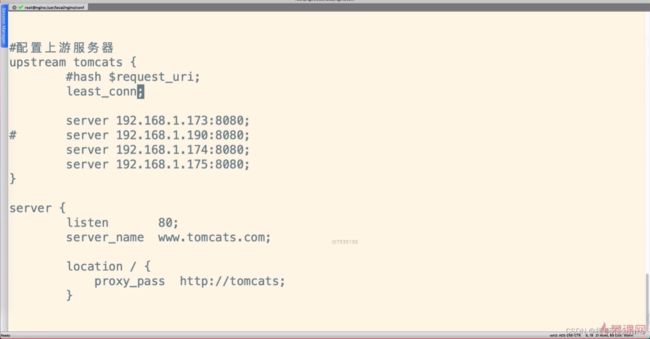
负载均衡 之 least_conn

表示新来的请求会寻找最少的连接数的服务器去请求
nginx配置
2-19 Nginx控制浏览器缓存
缓存介绍
-
服务器缓存
- 使用redis、memcache等缓存中间件缓存在服务器端
-
浏览器缓存:
- 加速用户访问,提升单个用户(浏览器访问者)体验,缓存在本地
-
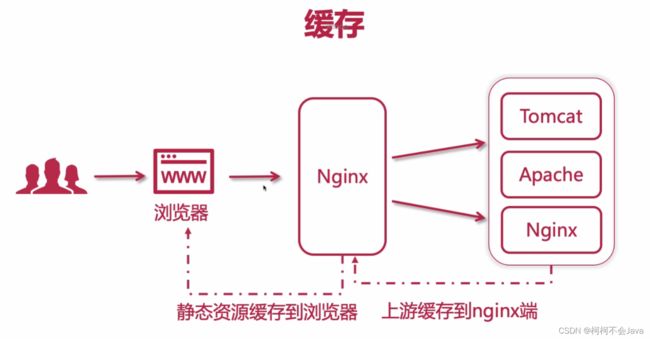
代理缓存(如:nginx缓存)
- 缓存在nginx端,提升所有访问到nginx这一端的用户体验
- 提升访问上游(upstream)服务器的速度
- 用户访问仍然会产生请求流量
缓存
expires指令
expires指令用于控制浏览器端缓存静态资源,如果用户对浏览器强制刷新或者清除缓存,则expires的设置会失效,浏览器本地的缓存文件就会清空。expires指令可以控制HTTP应答中的“Expires”和“Cache-Control”的头标,起到控制页面缓存的作用。
location /files {
alias /home/imooc;
# expires 10s; # 设置缓存的过期时间为10秒
# expires @22h30m; # 设置缓存的过期时间为每天22点30分
# expires -1h; # 表示现在时间的一个小时之前缓存就过期了,即无缓存
# expires epoch; # 表示不使用nginx缓存机制,并提醒浏览器,不设置缓存
# expires off; # 默认配置,不使用nginx缓存机制,会默认使用浏览器的缓存机制
expires max; # 设置最大的缓存过期时间,永不过期
}
测试expires指令控制浏览器端缓存
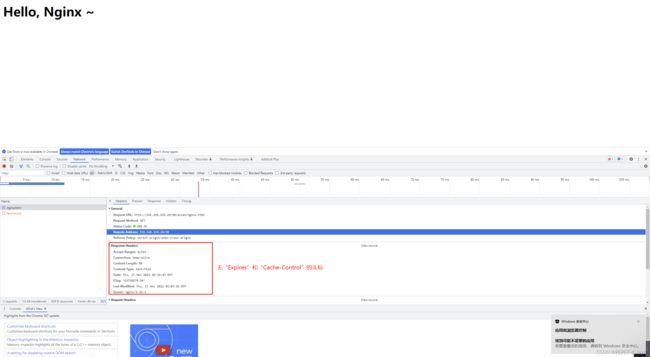
测试一:默认expires off;
第一次访问
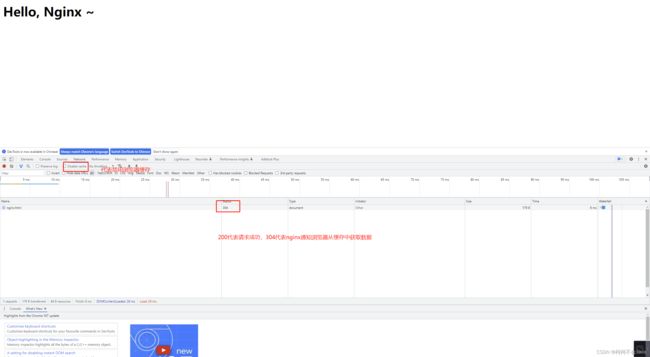
后续访问
修改文件后再次访问
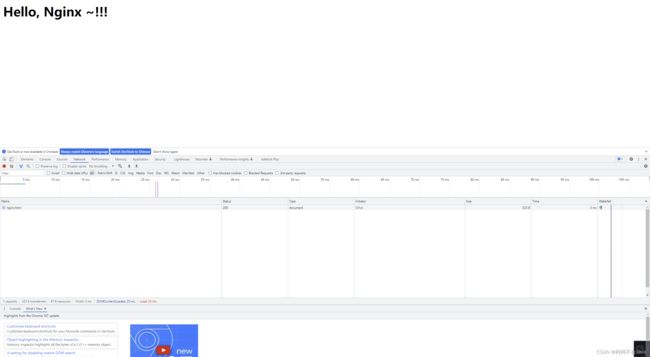
结论:第一次访问是200,从服务器中获取静态资源,后续访问304代表nginx告诉浏览器,访问的静态文件没有发生修改,从浏览器缓存中读取。但当访问的静态文件发生修改时,nginx会监听到静态文件发生改变,重新请求静态文件,此时的状态码就是200
测试二:默认expires 10s;
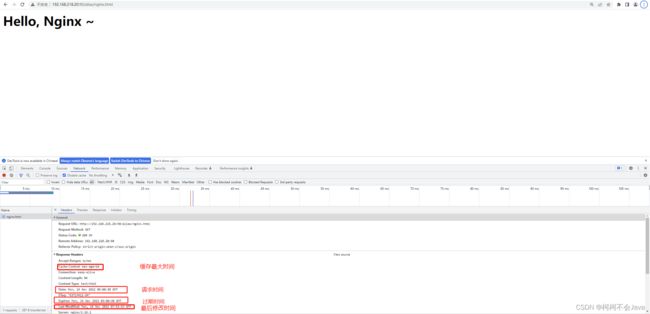
结论:可以看到过期时间和请求时间之间相差10s,即为缓存最大时间,最后修改时间为静态文件最后改动时间。且每次请求都会刷新请求时间和过期时间,但相差一直为10s。
2-20 Nginx的反向代理缓存
nginx也可以为上游服务器的静态文件缓存,如项目部署的服务器tomcat,可以加速用户请求的访问,提高用户体验。
官方文档地址:https://nginx.org/en/docs/http/ngx_http_proxy_module.html
# proxy_cache_path 设置缓存目录
# keys_zone 设置共享内存名称以及占用空间大小,下方location配置中可用共享内存名称
# max_size 设置缓存大小
# inactive 超过此时间则被清理
# use_temp_path 临时目录,使用后会影响nginx性能,off关闭即可
proxy_cache_path /usr/local/nginx/upstream_cache keys_zone=mycache:5m max_size=1g inactive=1m use_temp_path=off;
location / {
proxy_pass http://tomcats;
# 开启并且使用缓存,和keys_zone一致
proxy_cache mycache;
# 针对响应200和304状态码的缓存设置过期时间为8小时
proxy_cache_valid 200 304 8h;
}
2-21 使用Nginx配置SSL证书提供HTTPS访问
前言
一般项目发布后,默认的域名是http,但是http是不安全的,而https是安全的,https是基于现有的服务器,在配置https后,即符合苹果商店审核app的必备条件,应用接口请求不是https,则审核不会通过。首先需要一个域名,且该域名需要备案再解析到服务器,再申请一个ssl证书,证书支持apache、IIS、nginx、tomcat,下载后通过nginx配置即可。
使用Nginx配置ssl证书
1. 安装SSL模块
要在nginx中配置https,就必须安装ssl模块,也就是: http_ssl_module。
-
进入到nginx的解压目录:
/home/software/nginx-1.16.1 -
新增ssl模块(原来的那些模块需要保留)
./configure \ --prefix=/usr/local/nginx \ --pid-path=/var/run/nginx/nginx.pid \ --lock-path=/var/lock/nginx.lock \ --error-log-path=/var/log/nginx/error.log \ --http-log-path=/var/log/nginx/access.log \ --with-http_gzip_static_module \ --http-client-body-temp-path=/var/temp/nginx/client \ --http-proxy-temp-path=/var/temp/nginx/proxy \ --http-fastcgi-temp-path=/var/temp/nginx/fastcgi \ --http-uwsgi-temp-path=/var/temp/nginx/uwsgi \ --http-scgi-temp-path=/var/temp/nginx/scgi \ --with-http_ssl_module -
编译和安装
make make install
2. 配置HTTPS
-
把ssl证书
*.crt和 私钥*.key拷贝到/usr/local/nginx/conf目录中。 -
新增 server 监听 443 端口:
server { listen 443; server_name www.imoocdsp.com; # 开启ssl ssl on; # 配置ssl证书 ssl_certificate 1_www.imoocdsp.com_bundle.crt; # 配置证书秘钥 ssl_certificate_key 2_www.imoocdsp.com.key; # ssl会话cache ssl_session_cache shared:SSL:1m; # ssl会话超时时间 ssl_session_timeout 5m; # 配置加密套件,写法遵循 openssl 标准 ssl_protocols TLSv1 TLSv1.1 TLSv1.2; ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:HIGH:!aNULL:!MD5:!RC4:!DHE; ssl_prefer_server_ciphers on; location / { proxy_pass http://tomcats/; index index.html index.htm; } }
3. reload nginx
./nginx -s reload
附:
腾讯云Nginx配置https文档地址:https://cloud.tencent.com/document/product/400/35244
2-22 动静分离的那些事儿
动静分离的特点
- 本质是分布式,将静态资源和动态的API接口进行分离,提高静态资源访问的请求速度,因为静态资源可以被缓存
- 前后端解耦,前后端开发和部署都是分开的
- 静态归nginx,比如html、JavaScript、css样式、图片、视频、音频等都交由nginx管理,用户请求是从nginx加载读取的
- 接口服务化,后端单独部署,为多个跨平台的服务提供对接,比如安卓、ios、小程序等
动静分离
- 静态数据:css/js/html/images/audios/videos/…
- 动态数据:得到的响应可能和上一次不同的数据
动静分离的实现方式 - CDN

CDN是针对静态资源的,静态资源是部署在第三方服务器(比如阿里云等),不会放到企业内部的服务器里,根据用户请求的来源地请求最近的机房,可以提高用户的访问速度和服务器带宽的损耗。
动静分离的实现方式 - Nginx
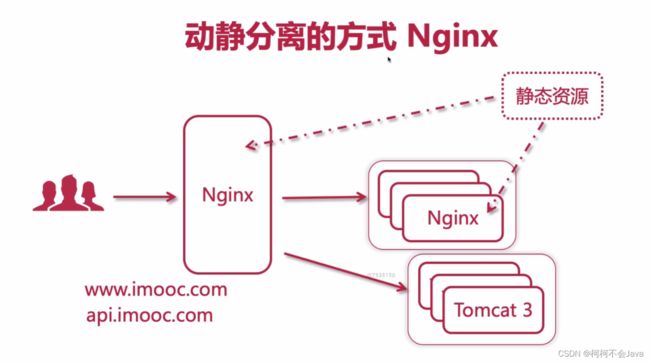
www.imooc.com是一级域名,首页都是通过一级域名访问,一般是拿到一些静态资源,当我们首页或者其他页面需要调用接口获取动态资源,一般是通过像api.imooc.com这样的二级域名。直接通过一级域名去访问获取静态资源数据,静态资源数据可以直接放入nginx中,也可以在nginx里挂一些上游服务器(upstream),如果需要请求一些动态的资源数据,则可以通过nginx转发到tomcat集群
动静分离的问题

2-23 部署Nginx到云端 - 安装Nginx
现阶段部署架构
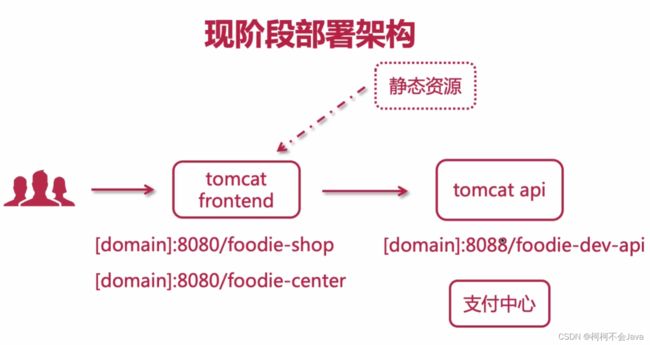
Nginx部署架构
第3章 Keepalived原理与实战
3-1 高可用集群架构Keepalived双机主备原理
Nginx高可用HA
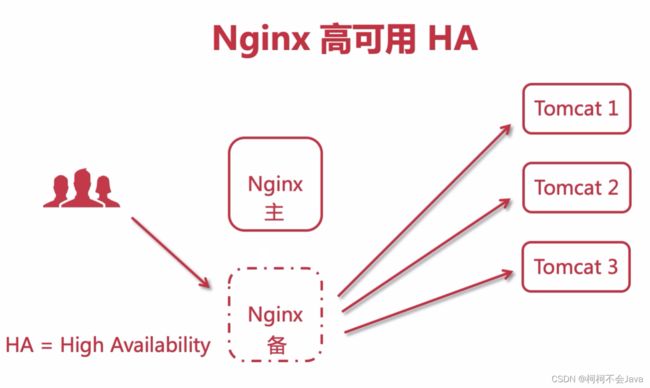
注意:Nginx存在主备服务器,当主服务器宕机,所有请求就会走备用服务器,不同于tomcat集群,Nginx集群同一个时间点内只能有一台服务器被请求。
Keepalived概念

总结Keepalived的作用:当单台nginx服务器承受不了巨大的流量,可以将nginx 做成分布式+ keepalived 的方式,Keepalived 起初是为 LVS 设计的,专门用来监控集群系统中各个服务节点的状态,它根据 TCP/IP 参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived 将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
虚拟路由冗余协议 VRRP
- Virtual Router Redundancy Protocol
- 解决内网单机故障的路由协议
- 构建有多个路由器(即nginx节点) MASTER(主) BACKUP(备)
- 每一个nginx节点启动都可以绑定一个虚拟IP - VIP(Virtual IP Address)
Keepalived双机主备原理
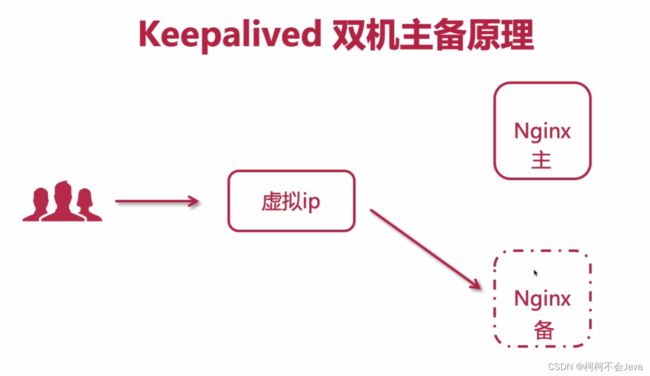
注意:主服务器和备服务器的配置要保持一致,避免主服务器宕机,备服务器处理不了主服务器的请求。
主节点会不停定时的向备用节点发送心跳,如果主节点发生故障,备用机就接收不到心跳,此时备用机就会接管主节点的工作。当主节点恢复后,会心跳通知备用机,此时备用机就不再工作,由主节点接管。
3-2 Keepalived安装部署
Keepalived安装图解
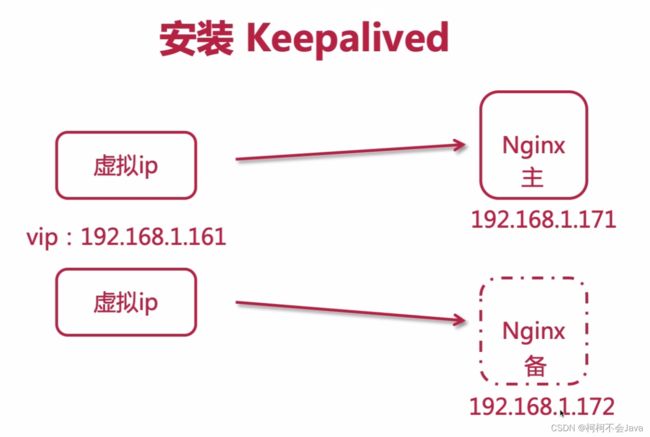
Keepalived安装部署
-
下载地址:
https://www.keepalived.org/download.html -
通过ftp工具上传到linux中,/home/software

-
解压
tar -zxvf keepalived-2.0.18.tar.gz -
解压后进入到解压出来的目录,看到会有
configure,那么就可以做配置了(配置安装和nginx一模一样)

-
使用
configure命令配置安装目录与核心配置文件所在位置:./configure --prefix=/usr/local/keepalived --sysconf=/etc- prefix:keepalived安装的位置
- sysconf:keepalived核心配置文件所在位置,固定位置,改成其他位置则keepalived启动不了,/var/log/messages中会报错
5.1. 配置过程中可能会出现警告信息,如下所示:
*** WARNING - this build will not support IPVS with IPv6. Please install libnl/libnl-3 dev libraries to support IPv6 with IPVS.5.2. 安装
libnl/libnl-3依赖yum -y install libnl libnl-devel5.3. 重新
configure一下,此时OK。 -
安装keepalived
make && make install -
进入到
/etc/keepalived,该目录下为keepalived核心配置文件

如果忘记安装配置的目录,则通过如下命令找到:

3-4 Keepalived核心配置文件
3-5 配置 Keepalived - 主
1. 通过命令 vim keepalived.conf 打开配置文件
global_defs {
# 路由id:当前安装keepalived的节点主机标识符,保证全局唯一
router_id keep_171
}
# 可以看成一个计算机节点
vrrp_instance VI_1 {
# 表示状态是MASTER主机还是备用机BACKUP
state MASTER
# 该实例绑定的网卡,通过ip addr命令查看
interface ens33
# 虚拟路由id,保证主备节点一致即可
virtual_router_id 51
# 权重,master权重一般高于backup,如果有多个,那就是选举,谁的权重高,谁就当选
priority 100
# 主备之间同步检查时间间隔,单位秒,默认1秒
advert_int 2
# 认证权限密码,防止非法节点进入
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟出来的ip,可以有多个(vip)
virtual_ipaddress {
192.168.1.161
}
}
附:查看网卡名称
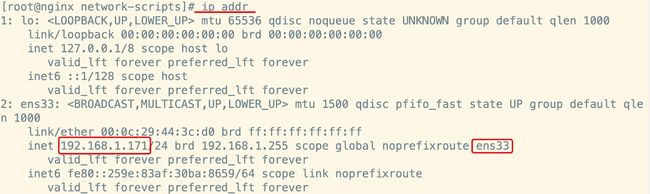
2. 启动 Keepalived
在sbin目录中进行启动(同nginx),如下图:

3. 查看进程
ps -ef|grep keepalived

4. 查看vip
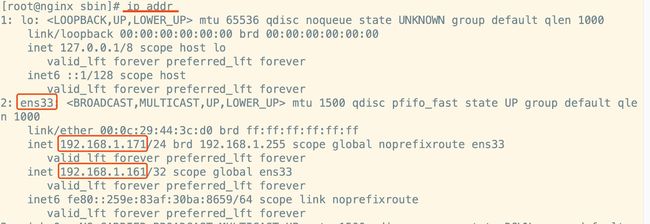
在网卡ens33下,多了一个192.168.1.161,这个就是虚拟ip
3-6 把Keepalived注册为系统服务
把Keepalived注册为系统服务

ps:启动命令:systemctl start keepalived.service,重启命令systemctl restart keepalived.service,停止命令systemctl stop keepalived.service
3-7 配置 Keepalived - 备
1. 通过命令 vim keepalived.conf 打开配置文件
global_defs {
router_id keep_172
}
vrrp_instance VI_1 {
# 备用机设置为BACKUP
state BACKUP
interface ens33
virtual_router_id 51
# 权重低于MASTER
priority 80
advert_int 2
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
# 注意:主备两台的vip都是一样的,绑定到同一个vip
# 主节点宕机,使用虚拟ip即访问该台服务器
192.168.1.161
}
}
2. 启动 Keepalived
# 启动keepalived
systemctl start keepalived
# 停止keepalived
systemctl stop keepalived
# 重启keepalived
systemctl restart keepalived
3. 查看进程
ps -ef|grep keepalived

3-8 Keepalived配置Nginx自动重启,实现7*24小时不间断服务
当主服务器没有宕机,只是nginx宕机的情况下,需要尝试重启nginx,如果nginx无法启动,再进行切换,使用脚本实现。
1. 增加Nginx重启检测脚本
vim /etc/keepalived/check_nginx_alive_or_not.sh
#!/bin/bash
A=`ps -C nginx --no-header |wc -l`
# 判断nginx是否宕机,如果宕机了,尝试重启
if [ $A -eq 0 ];then
/usr/local/nginx/sbin/nginx
# 等待一小会再次检查nginx,如果没有启动成功,则停止keepalived,使其启动备用机
sleep 3
if [ `ps -C nginx --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
-
增加运行权限
chmod +x /etc/keepalived/check_nginx_alive_or_not.sh
2. 配置keepalived监听nginx脚本
vrrp_script check_nginx_alive {
script "/etc/keepalived/check_nginx_alive_or_not.sh"
interval 2 # 每隔两秒运行上一行脚本
weight 10 # 如果脚本运行成功,则升级权重+10
# weight -10 # 如果脚本运行失败,则升级权重-10
}
3. 在vrrp_instance中新增监控的脚本
track_script {
check_nginx_alive # 追踪 nginx 脚本,当当前vrrp_instance实例化后,就会运行check_nginx_alive脚本
}
4. 重启Keepalived使得配置文件生效
systemctl restart keepalived
5. 备用节点也可以用同样的方式配置Nginx自动重启
略
3-9 高可用集群架构keepalived双主备热原理
keepalived实现双机主备高可用存在的问题
当主节点一直不宕机,备用节点就会一直闲置,这样就存在资源浪费、成功的问题
Keepalived双主热备

ps:DNS轮循是指将相同的域名解析到不同的IP,随机使用其中某台主机的技术
云服务的DNS解析配置与负载均衡
通过云服务器配置可以实现,一个域名解析两台服务器ip,两台服务器可以配置权重。
3-10 配置Keepalived双主热备
规则:以一个虚拟ip分组归为同一个路由
主节点配置
global_defs {
router_id keep_171
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.161
}
}
vrrp_instance VI_2 {
state BACKUP
interface ens33
virtual_router_id 52
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.162
}
}
备用节点配置
global_defs {
router_id keep_172
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 80
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.161
}
}
vrrp_instance VI_2 {
state MASTER
interface ens33
virtual_router_id 52
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.1.162
}
}
分别重启两条Keepalived
# 重启Keepalived
systemctl restart keepalived
第4章 搭建高可用集群负载均衡
4-1 LVS简介
LVS负载均衡
- Linux Virtual Server
- 章文嵩博士主导的开源的负载均衡项目
- LVS(ipvs)已被集成到Linux内核中
- 负载均衡调度器(四层)
官网
http://www.linuxvirtualserver.org/
LVS网络拓扑图

4-2 为什么要使用 LVS + Nginx?
为什么要使用 LVS + Nginx
- LVS基于四层,即传输层,接收到请求直接转发,相对了nginx,需要对请求进行处理,故有网络损耗,工作效率高
- 单个Nginx承受不了压力,需要集群,LVS充当Nginx集群的调度者
- Nginx接收请求来回,LVS可以只接收不响应
Nginx网络拓扑图

LVS网络拓扑图

4-3 LVS的三种模式
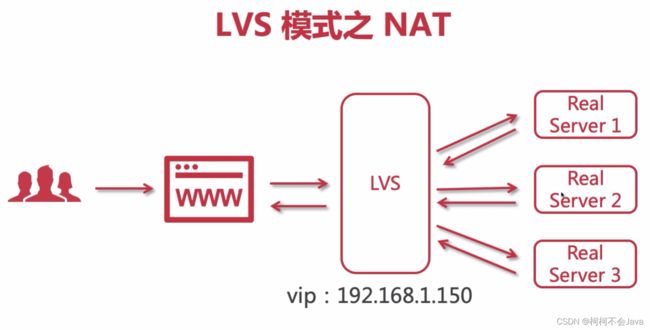
LVS模式之NAT
在处理并发量适中的项目时,NAT这种模式比较合适,但不适合并发量过高的项目。并且注意LVS这个IP是公网的,但是后面的Real Server属于企业内部(私网)
LVS模式之TUN
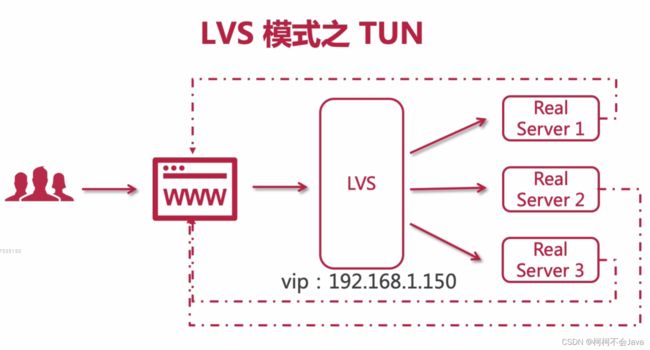
TUN模式有一个硬性的要求,所有的计算机节点必须要有一个网卡,作用就是建立隧道,计算机之间彼此的通信都是通过隧道。
好处:TUN模式相比于NAT模式,用户响应直接是Real Server,不通过LVS,大大地降低了LVS的压力。上行即浏览器到LVS,数据量可以比较小,下行即Real Server到用户,数据量可以很大,可以大大提高并发量。
坏处:需要一个硬性的要求,所有的计算机节点必须要有一个网卡,而且我们的Real Server必须要暴露在公网。
LVS模式之DR
DR模式中,Real Server还是部署在私网服务器,返回给用户的数据会包装在一起再经过一个Router路由,这个路由有一个虚拟IP,这样就将Real Server的信息隐藏起来了。
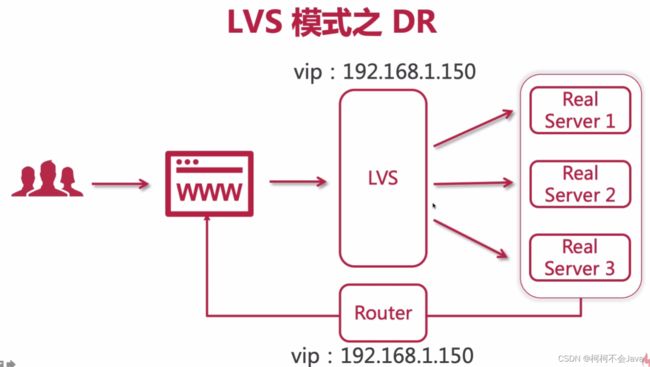
4-4 搭建LVS-DR模式- 配置LVS节点与ipvsadm
服务器与IP约定
注意:DIP和RIP都是指内网的真实IP,为了区分服务器功能

搭建LVS-DR模式- 配置LVS节点与ipvsadm
前期准备
-
服务器与ip规划:
- LVS - 1台
- VIP(虚拟IP):192.168.1.150
- DIP(转发者IP/内网IP):192.168.1.151
- Nginx - 2台(RealServer)
- RIP(真实IP/内网IP):192.168.1.171
- RIP(真实IP/内网IP):192.168.1.172
- LVS - 1台
-
所有计算机节点关闭网络配置管理器,因为有可能会和网络接口冲突:
systemctl stop NetworkManager systemctl disable NetworkManager
创建子接口
- 进入到网卡配置目录,找到咱们的ens33:

- 拷贝并且创建子接口:
cp ifcfg-ens33 ifcfg-ens33:1
* 注:`数字1`为别名,可以任取其他数字都行
- 修改子接口配置:
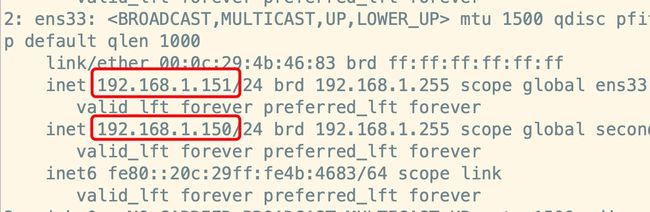
vim ifcfg-ens33:1 - 配置参考如下:

- 注:配置中的 192.168.1.150 就是咱们的vip,是提供给外网用户访问的ip地址,道理和nginx+keepalived那时讲的vip是一样的。
- 重启网络服务,或者重启linux:

- 重启成功后,ip addr 查看一下,你会发现多了一个ip,也就是虚拟ip(vip)
创建子接口 - 方式2(不推荐)
-
创建网络接口并且绑定虚拟ip:
ifconfig ens33:1 192.168.1.150/24- 配置规则如下:
配置成功后,查看ip会发现新增一个192.168.1.150:

- 配置规则如下:
- 通过此方式创建的虚拟ip在重启后会自动消失
安装ipvsadm
现如今的centos都是集成了LVS,所以ipvs是自带的,相当于苹果手机自带ios,我们只需要安装ipvsadm即可(ipvsadm是管理集群的工具,通过ipvs可以管理集群,查看集群等操作),命令如下:
yum install ipvsadm
安装成功后,可以检测一下:
图中显示目前版本为1.2.1,此外是一个空列表,啥都没。
- 注:关于虚拟ip在云上的事儿
- 阿里云不支持虚拟IP,需要购买他的负载均衡服务
- 腾讯云支持虚拟IP,但是需要额外购买,一台节点最大支持10个虚拟ip
4-5 搭建LVS-DR模式-为两台RS配置虚拟IP
配置虚拟网络子接口(回环接口)
- 进入到网卡配置目录,找到lo(本地环回接口,用户构建虚拟网络子接口),拷贝一份新的随后进行修改:
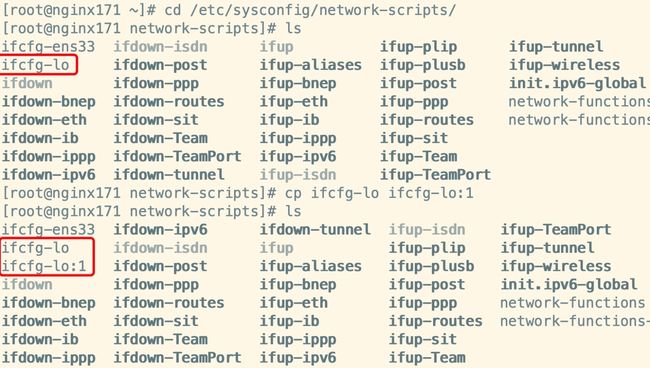
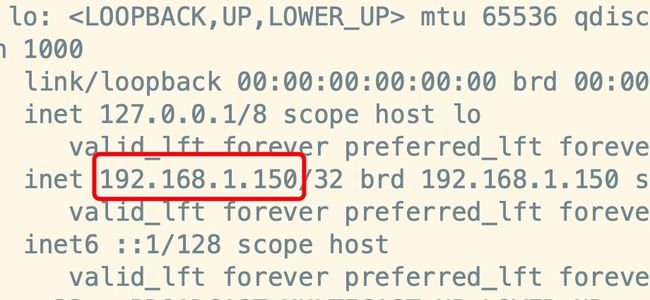
- 修改内容如下:
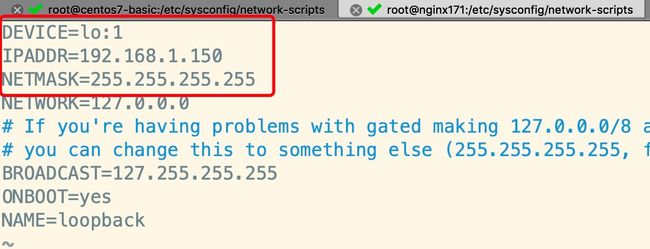
- 重启后通过ip addr 查看如下,表示ok:
4-6 搭建LVS-DR模式-为两台RS配置arp
ARP响应级别与通告行为 的概念
arp-ignore:ARP响应级别(处理请求)
- 0:只要本机配置了ip,就能响应请求,即Real server的192.168.1.171和192.168.1.150等都可以响应请求
- 1:请求的目标地址到达对应的网络接口,才会响应请求,即目标请求为192.168.1.150,那只有192.168.1.150才能响应请求 *
arp-announce:ARP通告行为(返回响应)
- 0:本机上任何网络接口都向外通告,所有的网卡都能接受到通告
- 1:尽可能避免本网卡和不匹配的目标进行通告
- 2:只在本网卡通告 *
配置ARP
-
打开sysctl.conf:
vim /etc/sysctl.conf -
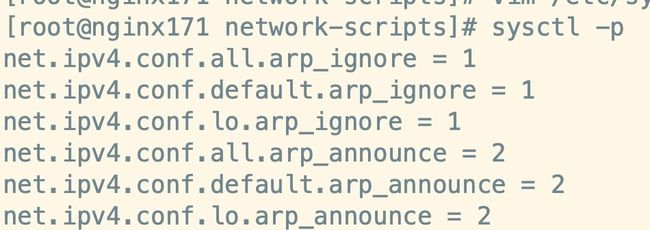
配置
所有网卡、默认网卡以及虚拟网卡的arp响应级别和通告行为,分别对应:all,default,lo:# configration for lvs net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.default.arp_ignore = 1 net.ipv4.conf.lo.arp_ignore = 1 net.ipv4.conf.all.arp_announce = 2 net.ipv4.conf.default.arp_announce = 2 net.ipv4.conf.lo.arp_announce = 2 -
刷新配置文件:
-
增加一个网关,用于接收数据报文,当有请求到本机后,会交给lo去处理:
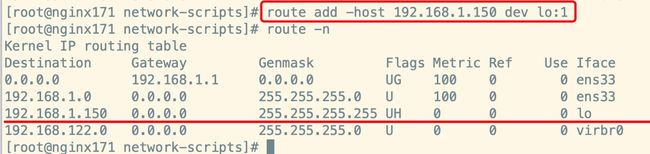
-
防止重启失效,做如下处理,用于开机自启动:
echo "route add -host 192.168.1.150 dev lo:1" >> /etc/rc.local
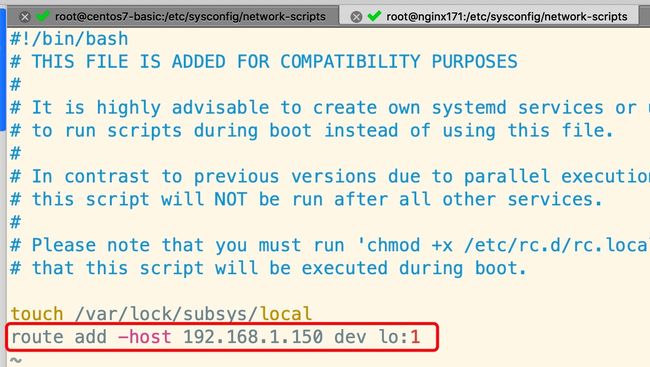
4-7 搭建LVS-DR模式-使用ipvsadm配置集群规则
-
创建LVS节点,用户访问的集群调度者
ipvsadm -A -t 192.168.1.150:80 -s rr -p 5- -A:添加集群
- -t:tcp协议
- ip地址:设定集群的访问ip,也就是LVS的虚拟ip
- -s:设置负载均衡的算法,rr表示轮询
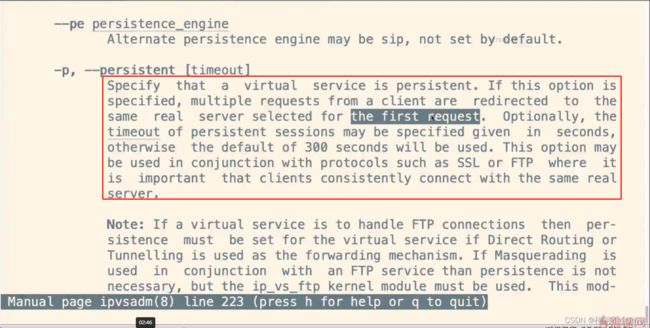
- -p:设置连接持久化的时间
-
创建2台RS真实服务器
ipvsadm -a -t 192.168.1.150:80 -r 192.168.1.171:80 -g ipvsadm -a -t 192.168.1.150:80 -r 192.168.1.172:80 -g- -a:添加真实服务器
- -t:tcp协议
- -r:真实服务器的ip地址
- -g:设定DR模式
-
保存到规则库,否则重启失效
ipvsadm -S -
检查集群
-
查看集群列表
ipvsadm -Ln -
查看集群状态
ipvsadm -Ln --stats
-
-
其他命令:
# 重启ipvsadm,重启后需要重新配置
service ipvsadm restart
# 查看持久化连接
ipvsadm -Ln --persistent-conn
# 查看连接请求过期时间以及请求源ip和目标ip
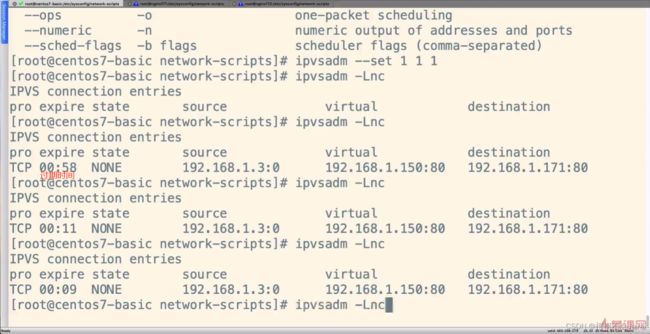
ipvsadm -Lnc
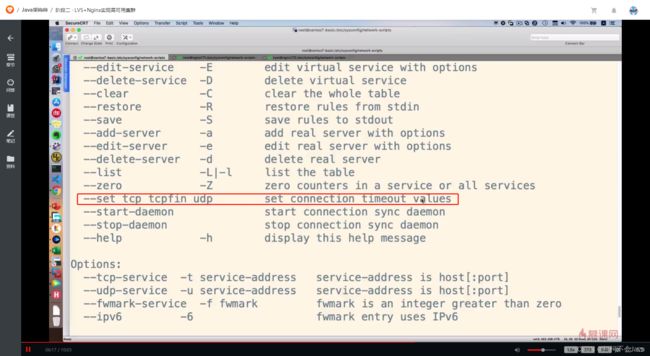
# 设置tcp tcpfin udp 的过期时间(一般保持默认)
ipvsadm --set 1 1 1
# 查看过期时间
ipvsadm -Ln --timeout
- 更详细的帮助文档:
ipvsadm -h
man ipvsadm
4-8 搭建LVS-DR模式-验证DR模式,探讨LVS持久化机制
下行是0,即响应请求不会经过171和172,这样就验证了当前是DR模式

刷新页面后一直访问同一台服务器的原因,因为会有一个默认300秒的持久化,都是访问第一次请求的服务器,可以通过-p命令修改

这样设置后刷新页面后还是一直访问同一台服务器,因为还有另外一个超时时间,可以通过–set命令设置和–Lnc命令查看
4-9 搭建Keepalived+Lvs+Nginx高可用集群负载均衡 - 配置Master
Keepalived+LVS高可用
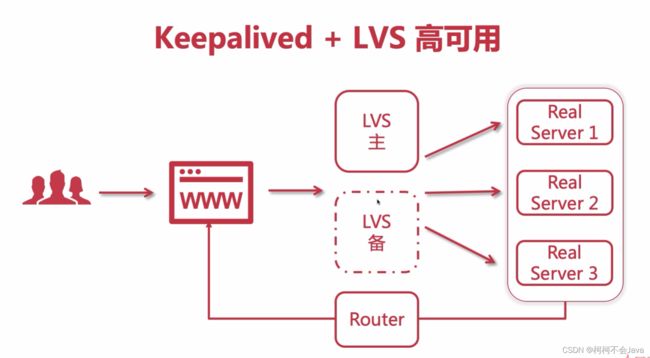
前期Keepalived安装准备

Keepalived配置文件配置


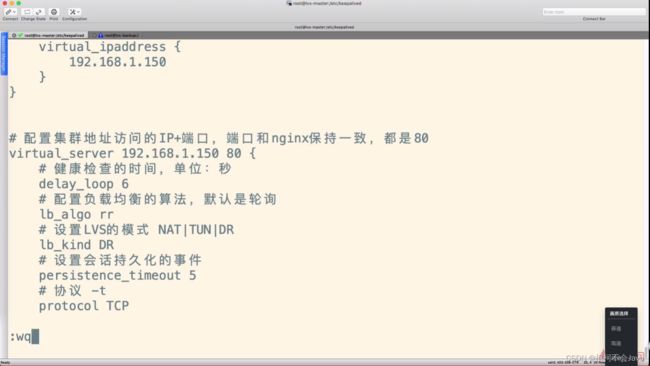
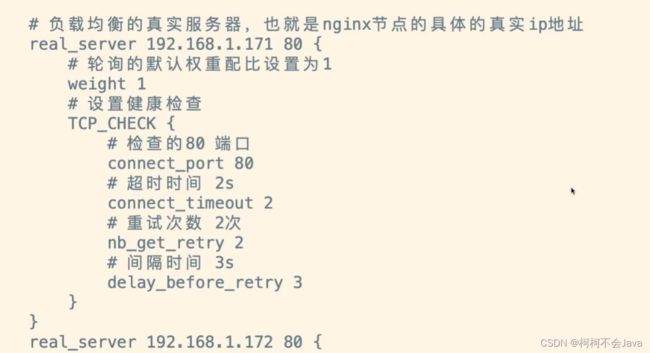
4-10 搭建Keepalived+Lvs+Nginx高可用集群负载均衡 - 配置Backup
配置方式基本和Master一样,具体也配置可参考上方Keepalived的Backup节点配置
测试Keepalived可以通过关闭Keepalived,测试健康检查可以通过关闭nginx再次访问或者命令查看ipvsadm -Ln
4-11 附:LVS的负载均衡算法
静态算法
静态:根据LVS本身自由的固定的算法分发用户请求。
- 轮询(Round Robin 简写’rr’):轮询算法假设所有的服务器处理请求的能力都一样的,调度器会把所有的请求平均分配给每个真实服务器。(同Nginx的轮询)
- 加权轮询(Weight Round Robin 简写’wrr’):安装权重比例分配用户请求。权重越高,被分配到处理的请求越多。(同Nginx的权重)
- 源地址散列(Source Hash 简写’sh’):同一个用户ip的请求,会由同一个RS来处理。(同Nginx的ip_hash)
- 目标地址散列(Destination Hash 简写’dh’):根据url的不同,请求到不同的RS。(同Nginx的url_hash)
动态算法
动态:会根据流量的不同,或者服务器的压力不同来分配用户请求,这是动态计算的。
- 最小连接数(Least Connections 简写’lc’):把新的连接请求分配到当前连接数最小的服务器。
- 加权最少连接数(Weight Least Connections 简写’wlc’):服务器的处理性能用数值来代表,权重越大处理的请求越多。Real Server 有可能会存在性能上的差异,wlc动态获取不同服务器的负载状况,把请求分发到性能好并且比较空闲的服务器。
- 最短期望延迟(Shortest Expected Delay 简写’sed’):特殊的wlc算法。举例阐述,假设有ABC三台服务器,权重分别为1、2、3 。如果使用wlc算法的话,当一个新请求进来,它可能会分给ABC中的任意一个。使用sed算法后会进行如下运算:
- A:(1+1)/1=2
- B:(1+2)/2=3/2
- C:(1+3)/3=4/3
最终结果,会把这个请求交给得出运算结果最小的服务器。
- 最少队列调度(Never Queue 简写’nq’):永不使用队列。如果有Real Server的连接数等于0,则直接把这个请求分配过去,不需要在排队等待运算了(sed运算)。
总结:
LVS在实际使用过程中,负载均衡算法用的较多的分别为wlc或wrr,简单易用。
附1:
参考文献:http://www.linuxvirtualserver.org/zh/lvs4.html
附2:
作为架构师,对lvs集群的负载算法有一定的了解即可,因为你要和运维人员进行有效沟通;但是如果作为运维的话那么是要深入钻研LVS了,一个企业如果发展并且使用到LVS了,那么业务量是十分巨大的,并且也会有专门的运维团队来负责网络架构的。
4-12 阶段复习
那么到这里,Nginx集群部分全部讲完,咱们针对本阶段的学习做个简短的总结。咱们来看一下下方思维导图来梳理内容:
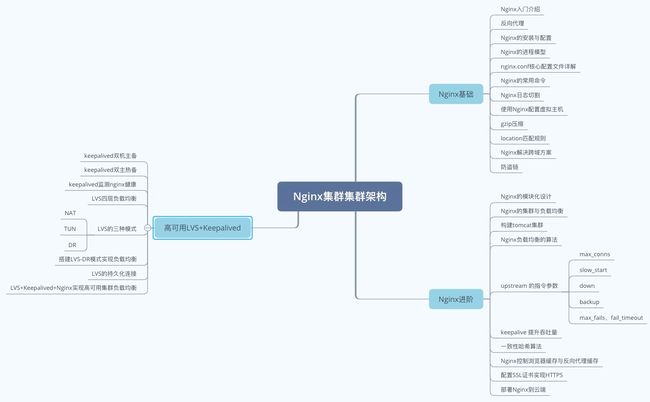
本阶段主要分为了三个部分:
- Nginx入门基础
- Nginx进阶
- 高可用集群LVS+Keepalived
先来说说第一个部分 - Nginx入门基础
本阶段开篇讲了Nginx介绍,啥是Nginx,有啥作用,啥叫反向代理,和正向代理有啥区别,并且也举例说明了。随后就进行了Nginx的安装和配置,讲解了Nginx的进程模型以及核心配置文件的内容。当nginx运行后,可以通过一些常用的命令去操作nginx。此外日志是一种生产服务器上调试的手段,可以通过日志来排查问题,但是日志需要人工切割,否则就是一份大文件,所以我们讲解了如何定时的自动进行日志切割,可以按照时间日期进行切分。随后我们讲解了如何通过nginx的虚拟主机功能映射不同的域名,这种场景就是当有多个域名但是只有一个服务器的时候,可以用nginx来构建虚拟主机。
当网站里有css、js、html、图片等文件,可以通过gzip来压缩内容,这样可以节省网络带宽,提高用户的访问效率,减少交互时间。
location匹配规则也是用的比较多,其实也就是路由功能,根据不同的请求url来分配不同的访问。
除了JSONP和SpringBoot解决跨域问题外,也能通过Nginx来解决,所以我们也讲解了如何进行配置,虽然是在nginx.conf中配置,但是原理和springboot配置都是一样的。
对于静态资源,尤其是图片,往往我们可以设置防盗链,避免被其他网站的引用,这也是平日里用的比较多的。
再来说说第二个部分 - Nginx进阶
这一部分主要涉及到Nginx构建集群与负载均衡,首先讲了模块化设计,因为反向代理是属于其中的一个模块的。
随后就简介了集群与负载均衡的原理,并且构建了tomcat集群。集群涉及到相应的负载均衡算法,默认为轮询,当然我们也讲了其他的算法,包括加权轮询、ip_hash、url_hash等。
此外upstream还提供了一些额外的指令,比如有:max_conns、slow_start、down、backup、max_fails、fail_timeout。当然还能通过keepalive来提升系统的吞吐量。
在讲到ip_hash、url_hash的时候,我们讲了一致性哈希算法的原理,这个在面试过程中可能会被问到,所以需要理解。
在使用nginx的时候,我们往往会设置缓存,一个是浏览器缓存,通过nginx可以控制,另外一个则是反向代理缓存,可以把其他节点的内容缓存到Nginx这一点,以此来提高用户请求效率。
最后呢我们通过云服务器来演示了ssl的配置,因为https在现如今是非常重要的。并且呢我们也吧Nginx部署到了云端,规避了tomcat的端口暴露。
高可用集群 LVS + Keepalived
这一部分主要是针对高可用,为了解决nginx的高可用,我们结合了keepalived来配置双机主备或者双主热备,要理解这两者区别,核心是VIP,用户通过VIP来访问的。另外为了保证nginx自动重启,提供7x24的不间断服务,需要自行添加脚本使得keepalived对nginx进行检测。
当然,单个nginx往往是不够的,因为他的并发量还是有限,所以很多企业会采用LVS,LVS是四层负载,LVS涉及到NAT|TUN|DR这三种模式,我们也讲了他们之间的区别和原理,并且实现了DR模式,当然,为了保证LVS的高可用,咱们也配合使用了Keepalived,因为Keepalived可以说就是为lvs量身打造的。需要注意,当keepalived和lvs结合以后,nginx作为lvs的集群,就无需和keepalived结合了。
那么这一部分可以说是精华部分,如果能够在面试过程中聊到这一块内容,并且有条不紊,那么有很大的几率会得到青睐收到offer噢~~
总结
集群架构是在单体架构后必经的一个演变过程,而且也是最简单的提高并发能力的架构。课程中我们演示了Nginx的集群、反向代理以及负载均衡,这些必须掌握,要去操练。
此外,LVS+Keepalived+Nginx是主流的高可用高性能的集群负载均衡解决方案,搭建这样的架构需要用到多台服务器,所以我们并没有在生产环境上去配置,一方面服务器成本比较大,另一方面VIP也是要额外付费的,不过我们在虚拟机上也是手把手的演示了,大家一定要跟着做。
当一个企业业务发展到需要使用LVS的时候,这个一般都会有运维团队去把控,架构师负责监督,但是作为架构师需要懂原理,因为你要和各团队去沟通的。