python数据分析-pandas-读取文件
文章目录
- python数据分析-pandas-读取文件
-
- csv文件读取
- excel文件读取
- json文件读取
csv文件读取
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=',', delimiter=None,
header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None,
keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False,
infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True,
iterator=False, chunksize=None, compression='infer', thousands=None, decimal: str = '.', lineterminator=None,
quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None,
dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)
- filepath_or_buffer:字符串或路径对象
Valid URL schemes include http, ftp, s3, and file.
- sep:str, default ‘,’
分隔符,默认是逗号
- delimiter:sep的别名,也是分隔符
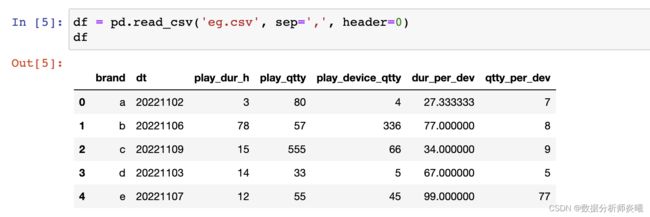
- header:int, list of int, default ‘infer’
数据的表头,如果没有传入该值,则默认header=0,并推断数据的第一行为表头,header=0 表示数据的第一行,不是文件的第一行。还可以是数字的列表。下面三个图体会下不同参数的差别。


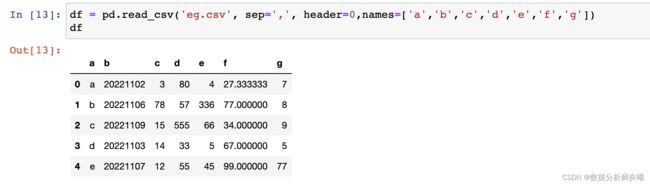
- names:array-like, optional
如果想更改名称,可通过传入表头的列表,但如果已经存在表头,需要指定header=0。
- index_col:int, str, sequence of int / str, or False, default None
False代表不让列成为索引,0代表让数据第一列为索引。

- usecols:list-like or callable, optional
选择要用的列,可以是数字[0,1,2],也可以是列名[a,c,b],不指定则代表解析所有列。

- squeeze:bool, default False
如果解析的数据只包含一列,则返回一个系列。
- prefix:str, optional
前缀,没有header的时候,比如x0,x1,x2.
- mangle_dupe_cols:bool, default True
重复的列将被指定为“X”、“X.1”、……“X.N”,而不是“X”……“X”。如果列中存在重复名称, 设为False 将导致数据被覆盖。

- dtype: Type name or dict of column -> type, optional
指定某列的数据类型,{‘a’: np.float64, ‘b’: np.int32, ‘c’: ‘Int64’}
- engine:{‘c’, ‘python’}, optional
要使用的解析器引擎。C 引擎更快,而 python 引擎目前功能更完整。
- converters:dict, optional
- nrows:int, optional
只读取文件的前几行,文件太大的时候使用。
- na_values:scalar, str, list-like, or dict, optional
设定哪些值为空值,默认以下将被识别为空值,‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null‘
- na_filter:bool, default True
在没有任何 NA 的数据中,传递 na_filter=False 可以提高读取大文件的性能。
- skip_blank_lines:bool, default True
设置为true则跳过空行。
- parse_dates:bool or list of int or names or list of lists or dict, default False
日期解析,list of int or names. e.g. If [1, 2, 3] ,将这几列解析为日期格式,list of lists. e.g. If [[1, 3]] ,将这两列结合为一列日期,dict, e.g. {‘foo’ : [1, 3]},合并1和3列,并命名为foo。

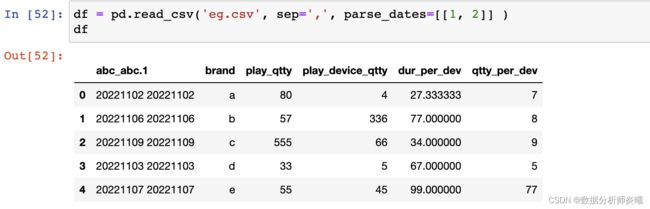
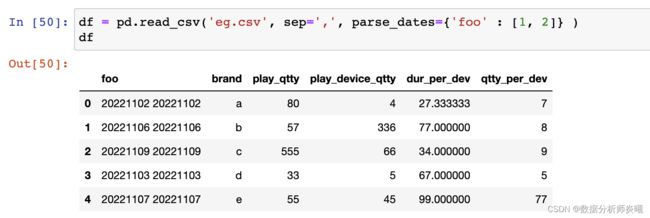
- keep_date_col:bool, default False
设置为true,那么当parse_dates结合多个字段的时候,会保留原字段。
- compression:{‘infer’, ‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}, default ‘infer’
压缩,用于磁盘数据的即时解压缩,默认下,则从以下扩展名检测压缩:‘.gz’、‘.bz2’、‘.zip’ 或 ‘.xz’(否则不解压缩)。如果使用“zip”,则 ZIP 文件必须只包含一个要读入的数据文件。设置为 None 表示不解压缩。
- comment: str, optional
设定注释行的标识,比如设定 comment=‘#’,如果某一行是以#开头,则会被忽略。
- encoding:str, optional
指定编码,比如’utf-8’。
excel文件读取
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None,
squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None,
skiprows=None, nrows=None, na_values=None, keep_default_na=True, verbose=False, parse_dates=False,
date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True,
mangle_dupe_cols=True, **kwds)
- io:路径
- sheet_name:str, int, list, or None, default 0
None会拿到所有sheet;默认是0,第一页,1为第二页;‘sheet名称’;[0, 1, “Sheet5”],前两页和Sheet5这一页。
- 其他参数都与csv重复。
json文件读取
pandas.read_json(path_or_buf=None, orient=None, typ='frame', dtype=None,
convert_axes=None, convert_dates=True, keep_default_dates=True, numpy=False,
precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None,
compression='infer')
- path_or_buf:a valid JSON str, path object or file-like object
json串,或者路径,Valid URL schemes include http, ftp, s3, and file.
- typ:{‘frame’, ‘series’}, default ‘frame’
设置解析成的对象类型。frame就是解析为dataframe,series就是解析为series格式。
- orient:str
如果typ == ‘series’ ,allowed orients are {‘split’,‘records’,‘index’},default is ‘index’;
如果typ == ‘frame’, allowed orients are {‘split’,‘records’,‘index’, ‘columns’,‘values’, ‘table’},default is ‘columns’

- dtype:bool or dict, default None
指定数据格式。
- convert_dates:bool or list of str, default True
如果列名类似日期,则转为日期,it ends with ‘_at’,it ends with ‘_time’,it begins with ‘timestamp’,it is ‘modified’, or it is ‘date’.


